Limbajul de programare Rust
de Steve Klabnik și Carol Nichols, cu contribuții din partea comunității Rust
Această versiune a textului presupune că utilizezi Rust 1.67.1 (lansat pe 2023-02-09) sau o versiune mai nouă. Pentru a instala sau actualiza Rust, accesează secțiunea "Instalare" din Capitolul 1.
Varianta HTML este disponibilă online la https://rust-lang.ro/ și offline (în engleză) în instalațiile Rust realizate cu rustup; executați rustup docs --book pentru a o deschide.
Câteva traduceri realizate de comunitate sunt de asemenea disponibile.
Textul (în engleză) este de asemenea disponibil în format paperback și ebook de la No Starch Press.
🚨 Îți dorești o experiență de învățare mai interactivă? Încearcă o versiune diferită a Cărții Rust, disponibilă cu: chestionare, funcții de evidențiere, vizualizări și multe altele (în engleză): https://rust-book.cs.brown.edu
Cuvânt înainte
Nu a fost mereu atât de clar, dar limbajul de programare Rust este fundamental despre împuternicire: indiferent de ce tip de cod ești obișnuit să scrii acum, Rust te împuternicește să ajungi mai departe, să programezi cu încredere într-o gamă mai largă de domenii decât ai făcut-o până acum.
De exemplu, să luăm activitățile la nivel de „sistem”, care implică detalii de nivel jos legate de managementul memoriei, reprezentarea datelor și concurență. În mod tradițional, această sferă a programării este percepută ca fiind obscură, accesibilă numai pentru câțiva aleși ce și-au dedicat ani de zile pentru a învăța cum să ocolească capcanele infame ale acesteia. Chiar și cei care lucrează în acest domeniu o fac cu mare precauție, pentru a nu-și expune codul la exploatări, căderi sau erori de corupere.
Rust dărâmă aceste bariere, eliminând vechile capcane și oferă un set de instrumente rafinat și prietenos care să te sprijine pe drumul tău. Programatorii care simt nevoia să coboare în straturile inferioare ale controlului pot face acest lucru cu Rust, fără a prelua riscurile obișnuite legate de crash-uri sau vulnerabilități de securitate și fără a fi nevoiți să stăpânească subtilitățile unui toolchain capricios. Mai mult de atât, limbajul este conceput să te îndrume natural către un cod fiabil, eficient din punct de vedere al vitezei și utilizării memoriei.
Programatorii care lucrează deja cu cod de nivel jos pot adopta Rust pentru a-și extinde orizonturile. De pildă, integrarea paralelismului în Rust presupune un risc relativ mic: erorile clasice sunt detectate de către compilator. Și poți încerca optimizări mai îndrăznețe în codul tău fiind încrezător că nu vei insera accidental crash-uri sau breșe de securitate.
Și totuși, Rust nu se limitează la programarea sistemică de nivel jos. Este destul de expresiv și ergonomic, astfel încât să facă scrierea aplicațiilor de consolă, a serverelor web, și a multor altor tipuri de programe o experiență plăcută - vei descoperi exemple simple ale acestor aspecte mai târziu în carte. Lucrând cu Rust, îți dezvolți competențe transferabile de la un domeniu la altul; poți învăța Rust prin scrierea unei aplicații web, apoi aplicând aceleași cunoștințe pentru a programa pe un Raspberry Pi.
Această carte adoptă deplin capacitățile Rust de a-și împuternici utilizatorii. Este un text prietenos și accesibil, menit să te ajute să avansezi nu doar în cunoașterea Rust, ci și în extinderea ambițiilor și încrederii tale ca programator în general. Deci, scufundă-te în lectură, pregătește-te să înveți - și bun venit în comunitatea Rust!
— Nicholas Matsakis și Aaron Turon
Introducere
Notă: Această ediție a cărții este la fel ca The Rust Programming Language disponibilă în format print și ebook de la No Starch Press.
Bine ai venit la The Rust Programming Language, o carte introductivă despre limbajul de programare Rust. Rust te ajută să dezvolți software mai rapid și mai fiabil. Ergonomia avansată și controlul fin al detaliilor sunt adesea văzute ca fiind în contradicție în design-ul limbajelor de programare; Rust își propune să armonizeze aceste aspecte. Echilibrând puterea tehnică avansată cu o experiență de dezvoltare agreabilă, Rust te lasă să gestionezi detalii precise ale utilizării memoriei și alte aspecte la nivel scăzut, fără dificultățile obișnuit asociate cu acest tip de control.
Pentru cine este destinat Rust
Rust este ideal pentru numeroase persoane, din diverse motive. Să vedem câteva dintre cele mai importante categorii.
Echipe de dezvoltatori
Rust se afirmă drept un instrument eficient pentru colaborarea în cadrul echipelor mari de dezvoltatori cu nivel diferit de experiență în programarea sistemelor. Codul low-level este susceptibil la o multitudine de bug-uri subtile, care în majoritatea celorlalte limbaje pot fi identificate doar prin teste riguroase și recenzii meticuloase ale codului efectuate de dezvoltatori experimentați. În Rust, compilatorul acționează ca o santinelă, refuzând să compileze codul care conține aceste erori subtile, inclusiv erorile de concurență. Colaborând îndeaproape cu compilatorul, echipa poate folosi timpul mai eficient pentru a se concentra pe logica programului decât pe urmărirea defectelor.
Rust contribuie la lumea programării de sistem cu setul său de instrumente de dezvoltare de ultimă oră:
- Cargo, managerul de dependențe și instrumentul de build încorporat, simplifică adăugarea, compilarea și coordonarea dependențelor într-un mod fără dureri de cap și omogen pe tot ecosistemul Rust.
- Instrumentul de formatare Rustfmt asigură un stil unic de codificare dintre dezvoltatori.
- Rust Language Server potențează integrarea în Integrated Development Environment (IDE) pentru auto-completarea codului și mesajele de eroare contextualizate.
Utilizând aceste facilități și altele din ecosistemul Rust, dezvoltatorii pot fi foarte eficienți în timpul scrierii codului la nivel de sistem.
Studenți
Rust se adresează studenților și tuturor celor interesați să învețe despre conceptele de sistem. Prin Rust, mulți au aprofundat teme legate de dezvoltarea sistemelor de operare. Comunitatea este extrem de primitoare și dornică să răspundă la întrebările studenților. Prin intermediul acestei cărți și alte inițiative, echipele Rust își propun să faciliteze accesul la conceptele de sistem unui număr și mai mare de persoane, în special celor care sunt la începutul drumului în programare.
Companii
Sute de companii, atât mari, cât și mici, folosesc Rust în producție pentru diverse activități, precum crearea de unelte pentru linia de comandă, servicii web, unelte pentru DevOps, dispozitive embedded, analiza și transcodarea audio-video, criptomonede, bioinformatică, motoare de căutare, aplicații pentru Internet of Things, machine learning și chiar componente esențiale ale browserului web Firefox.
Dezvoltatori open source
Rust este dedicat celor care vor să contribuie la dezvoltarea limbajului de programare Rust, a comunității, uneltelor pentru dezvoltatori și a bibliotecilor. Te așteptăm cu brațele deschise să contribui la dezvoltarea limbajului Rust.
Persoanele care prețuiesc viteza și stabilitatea
Rust se adresează celor care tânjesc după viteză și stabilitate într-un limbaj de programare. Prin viteză, ne referim atât la cât de repede poate rula codul Rust, cât și la rapiditatea cu care Rust te ajută să elaborezi programe. Verificările făcute de compilatorul Rust asigură stabilitatea prin introducerea de noi funcționalități și refactorizarea. Această abordare contrastează cu codul legacy fragil din limbaje fără aceste verificări, cod pe care dezvoltatorii adeseori se tem să-l modifice. Prin urmărirea abstracțiilor cu zero supra-cost, funcții de nivel înalt care se compilează la cod de nivel jos la fel de rapid ca și codul scris manual, Rust își propune să asigure că codul sigur este și cod rapid.
Limbajul Rust își propune să sprijine și alți utilizatori, pe lângă cei menționați; aceștia sunt doar unii dintre cei mai importanți. Per ansamblu, cea mai mare ambiție a Rust este să elimine compromisurile la care programatorii au consimțit de decenii, oferind în același timp siguranță și productivitate, viteză și ergonomie. Încearcă Rust și vezi dacă deciziile sale se potrivesc cu nevoile tale.
Pentru cine este această carte
Această carte presupune că ai deja experiență în scrierea de cod într-un alt limbaj de programare, dar nu se bazează pe presupunerea că ai folosit unul anume. Am adaptat materialul pentru a fi accesibil persoanelor cu experiențe diverse în programare. Nu ne-am concentrat în detaliu asupra discuției despre natura programării sau despre abordarea gândirii în termeni de programare. Dacă ești începător în domeniul programării, ai beneficia mai mult de pe urma unei cărți care oferă o introducere specifică în acest domeniu.
Cum să folosești această carte
De regulă, această carte este concepută să fie citită în ordine, de la prima pagină până la ultima. Capitolul următor se bazează pe conceptele prezentate în capitolele anterioare, și capitolele anterioare pot să nu abordeze în detalii un anumit subiect, ci să revină asupra lui într-un capitol mai înaintat.
Vei găsi două tipuri de capitole în această carte: capitole de concepte și capitole de proiecte. În capitolele de concepte, vei afla detalii despre un aspect al limbajului Rust. În capitolele de proiecte, vom dezvolta împreună programe mici, aplicând ceea ce ai învățat până în momentul acela. Capitolele 2, 12 și 20 sunt capitole de proiecte; celelalte sunt capitole de concepte.
Capitolul 1 explică cum să instalezi Rust, cum să scrii un program „Hello, world!” și cum să folosești Cargo, managerul de pachete și uneltele de construire din Rust. Capitolul 2 oferă o introducere practică în scrierea unui program Rust prin construirea unui joc de ghicit numere. Acolo tratăm conceptele la un nivel mai general, iar capitolele viitoare vor intra în mai multe detalii. Dacă ești nerăbdător să începi practic, Capitolul 2 este ideal pentru acest lucru. Capitolul 3 tratează facilitățile din Rust comune cu alte limbaje de programare, iar în Capitolul 4 vei învăța despre sistemul specific Rust de posesiune. Dacă ești o persoană extrem de meticuloasă și preferi să cunoști fiecare detaliu înainte de a avansa, ai putea să sari peste Capitolul 2 și să treci direct la Capitolul 3, revenind la Capitolul 2 când vrei să exersezi pe un proiect, aplicând detaliile învățate.
Capitolul 5 discută structurile și metodele, iar Capitolul 6 prezintă enumerările, expresiile match și structura de control if let. În Rust, vei folosi structurile și enumerările pentru a defini tipuri de date personalizate.
În Capitolul 7, vei învăța despre sistemul de module al Rust și despre regulile de confidențialitate pentru structurarea codului tău și a Interfeței de Programare a Aplicațiilor (API) publice. Capitolul 8 abordează unele structuri de date de colecții uzuale pe care le furnizează biblioteca standard, cum ar fi vectorii, string-urile și hashmap-urile. Capitolul 9 tratează filosofia și tehnicile de gestionare a erorilor în Rust.
Capitolul 10 aprofundează conceptele de generici, trăsături și durate de viață, ce îți oferă capacitatea de a defini cod util pentru diferite tipuri. Capitolul 11 are în centrul atenției testarea, necesară pentru a verifica corectitudinea raționamentului logic al programului tău, chiar dacă Rust oferă garanții de siguranță. În Capitolul 12, vom crea propria variantă a unei părți din funcționalitățile comenzii grep, care permite căutarea textului în fișiere, folosind multe din conceptele prezentate în capitolele precedente.
Capitolul 13 introduce închiderile și iteratorii, elemente din Rust influențate de limbajele de programare funcționale. Capitolul 14 este dedicat unei analize detaliate a Cargo și discuții despre practicile ideale pentru distribuirea bibliotecilor tale către alții. Capitolul 15 prezintă pointerii inteligenți disponibili în biblioteca standard și trăsăturile care le susțin funcționalitatea.
Capitolul 16 te va ghida prin diferitele paradigme de programare concurentă și va explora cum Rust facilitează programarea pe multe fire de execuție fără temeri. Capitolul 17 compară expresiile Rust cu principiile familiale ale programării orientate-obiect.
Capitolul 18 servește drept ghid pentru pattern-uri și potrivirea pattern-urilor, metode eficace de comunicare a ideilor în cadrul programelor Rust. Capitolul 19 oferă o gamă largă de subiecte avansate captivante, printre care Rust-ul nesigur, macrocomenzile, precum și aspecte suplimentare despre duratele de viață, trăsăturile, tipurile, funcțiile și închiderile.
În Capitolul 20, vom completa un proiect în care vom implementa un server web de nivel scăzut cu fire de execuție multiple!
În final, unele anexe conțin informații utile despre limbaj într-un format mai apropiat de cel de referință. Anexa A este despre cuvintele cheie din Rust, Anexa B despre operatorii și simbolurile din Rust, Anexa C despre trăsăturile derivabile oferite de biblioteca standard, Anexa D despre unele instrumente de dezvoltare utile și Anexa E explică edițiile Rust. În Anexa F poți găsi traduceri ale cărții, iar în Anexa G vom explica cum este dezvoltat Rust și ce înseamnă Nightly Rust.
Nu e nicio metodă greșită de a citi această carte: dacă dorești să sari peste unele părți, fă-o! Poate fi nevoie să te întorci la capitolele anterioare dacă întâmpini greutăți. Dar fă ceea ce ți se potrivește.
O parte importantă a procesului de învățare Rust este să înveți cum să citești mesajele de eroare afișate de compilator: acestea te vor îndruma către un cod funcțional. Prin urmare, vom prezenta multe exemple care nu se compilează, alături de mesajul de eroare pe care compilatorul îl va afișa în fiecare situație. Înainte de a introduce și rula un exemplu la întâmplare, ține cont că s-ar putea să nu se compileze! Asigură-te că ai citit textul înconjurător pentru a vedea dacă exemplul pe care încerci să îl execuți este menit să genereze o eroare. Ferris te va ajuta să distingi și codul care nu este destinat să funcționeze:
| Ferris | Semnificație |
|---|---|
 | Codul nu se compilează! |
 | Codul generează panică! |
 | Codul nu are comportamentul așteptat. |
În majoritatea situațiilor, te vom îndruma către versiunea corectă a oricărui cod care nu compilează.
Codul sursă
Fișierele sursă din care această carte a fost generată pot fi găsite pe GitHub.
Să începem
Să începem aventura noastră în Rust! Avem multe de învățat, dar orice călătorie începe cu un punct de pornire. În acest capitol, vom acoperi:
- Instalarea Rust pe sistemele de operare Linux, macOS și Windows.
- Crearea unui program care afișează
Salut, lume! - Utilizarea
cargo, managerul de pachete și sistemul de build specific Rust.
Instalare
Primul pas este să instalezi Rust. Vom descărca Rust folosind rustup, un instrument de linie de comandă pentru gestionarea versiunilor Rust și a uneltelor asociate. Vei avea nevoie de o conexiune la internet pentru descărcare.
Notă: Dacă preferi să nu folosești
rustupdintr-un motiv oarecare, te rugăm să consulți pagina cu Alte metode de instalare Rust pentru mai multe opțiuni.
Următorii pași instalează cea mai recentă versiune stabilă a compilatorului Rust. Rust oferă garanții de stabilitate care asigură că toate exemplele din carte compatibile cu versiuni anterioare vor rămâne funcționale și pe versiunile Rust ulterioare. Ieșirea s-ar putea să difere ușor între versiuni deoarece Rust îmbunătățește adesea mesajele de eroare și avertismentele. Cu alte cuvinte, orice versiune stabilă mai nouă de Rust pe care o instalezi folosind acești pași ar trebui să funcționeze așa cum este de așteptat cu conținutul acestei cărți.
Notația pentru linia de comandă
De-a lungul acestui capitol și a cărții, vom indica diferite comenzi utilizate în terminal. Liniile ce urmează să le tastezi într-un terminal încep cu
$. Nu trebuie să tastezi caracterul$; acesta semnalizează începutul unei comenzi în terminal. Liniile care nu încep cu$reprezintă în mod obișnuit output-ul comenzii anterioare. În plus, exemplele destinate PowerShell vor utiliza>în loc de$.
Instalarea rustup pe Linux sau macOS
Dacă folosești Linux sau macOS, deschide un terminal și introduce următoarea comandă:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
Comanda descarcă un script și începe instalarea instrumentului rustup, care instalează cea mai recentă versiune stabilă a Rust. S-ar putea să ți se ceară parola. Dacă instalarea este reușită, va apărea următoarea linie:
Rust is installed now. Great!
De asemenea, va trebui să ai un linker, care este un program pe care Rust îl folosește pentru a uni toate afișajele sale compilate într-un singur fișier. Probabil deja ai unul. Dacă primești erori legate de linker, ar trebui să instalezi un compilator C, acesta include de obicei un linker. Un compilator C este util și pentru că unele pachete comune din Rust depind de codul C și vor avea nevoie de un compilator C.
Pe macOS, poți obține un compilator C cu următoarea comandă:
$ xcode-select --install
Utilizatorii de Linux ar trebui să instaleze, în general, GCC sau Clang, conform documentației distribuției lor. De exemplu, dacă folosești Ubuntu, poți instala pachetul build-essential.
Instalarea rustup pe Windows
Pe Windows, accesează https://www.rust-lang.org/tools/install și urmează instrucțiunile pentru instalarea Rust. La un moment dat în procesul de instalare, vei primi un mesaj care îți explică faptul că este necesar să ai și instrumentele de compilare MSVC pentru Visual Studio 2013 sau mai târziu.
Pentru a obține instrumentele de compilare, trebuie să instalezi Visual Studio 2022. Când îți va fi solicitat să alegi ce utilități de lucru să instalezi, asigură-te că incluzi:
- „Desktop Development with C++”
- SDK-ul pentru Windows 10 sau 11
- Componenta pachetului de limbă engleză, împreună cu orice alte pachete de limbă după preferință
Restul acestei cărți utilizează comenzi compatibile atât cu cmd.exe, cât și cu PowerShell. Dacă există diferențe specifice între acestea, noi vom explica care versiune trebuie utilizată.
Depanare
Pentru a verifica dacă ai instalat corect Rust, deschide o consolă și introdu această linie:
$ rustc --version
Ar trebui să vezi numărul versiunii, hash-ul commit-ului și data commit-ului pentru cea mai recent lansată versiune stabilă, în următorul format:
rustc x.y.z (abcabcabc yyyy-mm-dd)
Dacă vezi aceste informații, ai instalat cu succes Rust! Dacă nu vezi aceste informații, verifică dacă Rust se află în variabila de sistem %PATH%` în felul următor.
În CMD Windows, folosește:
> echo %PATH%
În PowerShell, folosește:
> echo $env:Path
În Linux și macOS, folosește:
$ echo $PATH
Dacă totul este corect și Rust tot nu funcționează, există mai multe locuri în care poți obține ajutor. Află cum să iei legătura cu alți Rustaceani (un pseudonim amuzant pe care noi îl folosim) pe pagina comunității.
Actualizare și dezinstalare
Odată ce Rust este instalat prin intermediul rustup, actualizarea la o versiune nou lansată este ușoară. Din terminalul tău, rulează următorul script de actualizare:
$ rustup update
Pentru a dezinstala Rust și rustup, rulează următorul script de dezinstalare din terminal:
$ rustup self uninstall
Documentație locală
Instalarea Rust include și o copie locală a documentației, astfel încât să o poți citi offline. Rulează rustup doc pentru a deschide documentația locală în browserul tău.
De fiecare dată când un tip sau o funcție este furnizată de biblioteca standard și nu ești sigur ce face sau cum să o folosești, apelează la documentația interfeței de programare a aplicațiilor (API) pentru a afla!
Salut, lume!
Acum că ai instalat Rust, este timpul să scrii primul tău program în Rust. Tradițional, când învățăm un limbaj nou, scriem un mic program care afișează textul Salut, lume! pe ecran. Așadar, vom face la fel și aici!
Notă: Această carte presupune cunoștințe de bază a liniei de comandă. Rust nu are cerințe specifice despre editarea, uneltele tale sau locul unde se află codul tău, așa că dacă preferi să folosești un mediu de dezvoltare integrat (IDE) în locul liniei de comandă, nu ezita să folosești IDE-ul tău preferat. Multe IDE-uri au acum un anumit grad de suport Rust; verifică documentația IDE-ului pentru detalii. Echipa Rust s-a concentrat pe facilitarea unui suport IDE excelent prin
rust-analyzer. Vezi Anexa D pentru mai multe detalii.
Crearea unui directoriu pentru proiect
O să începem prin a crea un directoriu unde să îți stochezi codul Rust. Pentru Rust nu contează unde este situat codul tău, însă pentru exercițiile și proiectele din această carte, recomandăm crearea unui directoriu projects în directoriu tău home și să menții toate proiectele acolo.
Deschide un terminal și execută următoarele comenzi pentru a crea un directoriu projects și un directoriu pentru proiectul "Hello, world!" în cadrul directoriu projects.
Pentru Linux, macOS și PowerShell pe Windows, execută acestea:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
Pentru CMD pe Windows, introdu asta:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
Scrierea și rularea unui program Rust
În continuare, creează un nou fișier sursă și numește-l main.rs. Fișierele Rust se termină întotdeauna cu extensiunea .rs. Dacă folosești mai mult de un cuvânt în numele fișierului tău, convenția este să folosești un underscore pentru a le separa. De exemplu, folosește hello_world.rs în loc de helloworld.rs.
Acum deschide fișierul main.rs pe care tocmai l-ai creat și introdu codul din Listarea 1-1.
Numele fișierului: main.rs
fn main() { println!("Salut, lume!"); }
Listarea 1-1: Un program care afișează Salut, lume!
Salvează fișierul și întoarce-te la fereastra terminalului în directorul ~/projects/hello_world. Pe Linux sau macOS, introdu următoarele comenzi pentru a compila și a rula fișierul:
$ rustc main.rs
$ ./main
Salut, lume!
Pe Windows, introdu comanda .\main.exe în loc de ./main:
> rustc main.rs
> .\main.exe
Salut, lume!
Indiferent de sistemul tău de operare, Salut, lume! ar trebui să fie afișat în terminal. Dacă nu vezi acest rezultat, verifică din nou partea de „Depanare” a secțiunii de instalare pentru a obține ajutor.
Dacă Salut, lume! a apărut, felicitări! Ai scris oficial un program Rust. Asta te face un programator Rust - bun venit!
Anatomia unui program Rust
Să revizuim în detaliu acest program "Salut, lume!". Iată prima piesă a puzzle-ului:
fn main() { }
Aceste linii definesc o funcție numită main. Funcția main este specială: este întotdeauna primul cod care rulează în fiecare program Rust executabil. Aici, prima linie declară o funcție numită main care nu are parametri și nu returnează nimic. Dacă ar fi existat parametri, aceștia ar fi fost specificați între parantezele ().
Corpul funcției este înconjurat de {}. Rust necesită acolade în jurul tuturor corpurilor de funcție. Este considerat un stil bun să plasezi acolada de deschidere pe aceeași linie cu declarația funcției, adăugând un spațiu între acestea.
Notă: Dacă vrei să urmezi un stil standard în toate proiectele tale Rust, poți folosi un utilitar de formatare automată denumit
rustfmtpentru a-ți formata codul într-o manieră specifică (vei găsi mai multe detalii desprerustfmtîn Anexa D). Acest utilitar este inclus de echipa Rust în distribuția standard de Rust, la fel carustc, așa că cel mai probabil este deja instalat pe computerul tău!
Corpul funcției main conține următorul cod:
#![allow(unused)] fn main() { println!("Salut, lume!"); }
Această linie efectuează toată munca în acest program simplu: tipărește textul pe ecran. Sunt patru detalii importante de observat aici.
În primul rând, stilul Rust este de a indenta cu patru spații, nu cu un tab.
În al doilea rând, println! apelează un macro Rust. Dacă ar fi apelat o funcție în loc, ar fi fost introdus ca println (fără !). Vom discuta macrourile Rust în detaliu în Capitolul 19. Deocamdată, trebuie doar să știi că utilizarea unui ! înseamnă că apelezi un macro în locul unei funcții normale și că macrourile nu urmează întotdeauna aceleași reguli ca funcțiile.
În al treilea rând, observăm string-ul "Salut, lume!". Noi trecem acest string ca un argument către println!, iar string-ul este tipărit pe ecran.
În al patrulea rând, încheiem linia cu un punct și virgulă (;), care indică faptul că această expresie s-a încheiat și următoarea este gata să înceapă. Cele mai multe linii de cod Rust se încheie cu un punct și virgulă.
Compilarea și rularea sunt etape separate
Tocmai ai rulat un program nou creat, așadar să examinăm fiecare pas în proces.
Înainte de a rula un program Rust, trebuie să îl compilezi folosind compilatorul Rust, introducând comanda rustc în consolă și trecând numele fișierului tău sursă, astfel:
$ rustc main.rs
Dacă ai experiență cu C sau C++, vei observa că acest lucru este similar cu gcc sau clang. După o compilare reușită, Rust generează un executabil binar.
Pe Linux, macOS, și în PowerShell pe Windows, poți vedea executabilul introducând comanda ls în consolă:
$ ls
main main.rs
Pe Linux și macOS, vei vedea două fișiere: 'main' și 'main.rs'. Pe Windows, folosind PowerShell sau CMD, vei vedea, de asemenea, fișierul 'main.exe' și un fișier de depanare cu extensia .pdb, alături de main.rs. Cu CMD pe Windows, ai introduce următoarea comandă:
> dir /B %= opțiunea /B indică doar numele fișierelor =%
main.exe
main.pdb
main.rs
Aceasta afişează fișierul sursă cu extensia .rs, fișierul executabil (main.exe pe Windows, dar main pe toate celelalte platforme), și, atunci când folosești Windows, un fișier care conține informații de depanare cu extensia .pdb. De aici, rulezi fișierul main sau main.exe, astfel:
$ ./main # sau .\main.exe pe Windows
Dacă main.rs este programul tău „Salut, lume!”, această linie va afișa în consolă Salut, lume!.
Dacă ai început cu un limbaj dinamic, așa cum sunt Ruby, Python sau JavaScript, este posibil să nu-ți fie clar faptul de a compila și rula un program în pași separați. Rust este un limbaj compilat înainte de execuție, ceea ce înseamnă că poți să compilezi un program și să dai executabilul cuiva altcuiva, și aceștia vor putea să îl ruleze chiar și fără să aibă Rust instalat. În schimb, dacă dai cuiva un fișier .rb, .py, sau .js, persoana respectivă trebuie să aibă instalată o variantă corespunzătoare de Ruby, Python sau JavaScript. Cu toate acestea, în limbaje precum Ruby, Python sau JavaScript, compilezi și rulezi programul tău folosind o singură comandă. Fiecare decizie în designul limbajului de programare reprezintă un compromis.
Compilarea doar cu rustc este adecvată pentru programele simple, dar pe măsură ce proiectul tău se extinde, vei dori să controlezi toate opțiunile și să îți facilitezi partajarea codului. În continuare, vom explora utilizarea utilitarului Cargo, care ne va sprijini în scrierea programelor Rust pentru scenarii din lumea reală.
Salut, Cargo!
Cargo este sistemul de construcție și managerul de pachete al lui Rust. Majoritatea programatorilor Rust folosesc acest instrument pentru a-și gestiona proiectele Rust deoarece Cargo se ocupă de o mulțime de sarcini pentru tine, precum compilarea codului, descărcarea librăriilor de care depinde el și compilarea acestor librării. (Noi, de regulă, numim librăriile dependențe.)
Cele mai simple programe Rust, ca cel pe care l-am scris până acum, nu au nicio dependență. Dacă am fi compilat proiectul „Salut, lume!” cu Cargo, atunci doar partea responsabilă de compilare din Cargo ar fi fost utilizată. Pe măsură ce proiectele tale Rust devin mai complexe, este probabil să adaugi mai multe dependențe și dacă începi un proiect folosind Cargo, adăugarea dependențelor va fi mult mai ușor de făcut.
Deoarece majoritatea covârșitoare a proiectelor Rust folosesc Cargo, în restul acestei cărți vom presupune că și tu folosești Cargo. Cargo vine instalat cu Rust dacă ai folosit instalatoarele oficiale discutate în secțiunea „Instalare”. Dacă ai instalat Rust prin alte mijloace, poți verifica dacă Cargo este instalat prin introducerea următoarei comenzi în terminal:
$ cargo --version
Dacă vezi un număr de versiune, îl ai! Dacă vezi o eroare, cum ar fi command not found, uită-te la documentația metodei tale de instalare pentru a determina cum să instalezi Cargo separat.
Crearea unui proiect cu Cargo
Să creăm un proiect nou folosind Cargo și să vedem cum se deosebește de proiectul nostru original „Salut, lume!”. Navighează înapoi în directoriul tău proiecte (sau oriunde ai ales să-ți stochezi codul). Apoi, pe orice sistem de operare, rulează următoarele:
$ cargo new hello_cargo
$ cd hello_cargo
Prima comandă creează un directoriu și un proiect nou numit hello_cargo. Noi am numit proiectul nostru hello_cargo, iar Cargo creează fișierele sale într-un directoriu cu același nume.
Du-te în directoriul hello_cargo și listează fișierele. Vei vedea că Cargo a generat două fișiere și un directoriu: un fișier Cargo.toml și un directoriu src cu un fișier main.rs în interior.
A creat de asemenea un nou repozitoriu Git împreună cu un fișier .gitignore. Cargo nu va iniția un nou repozitoriu Git dacă comanda cargo new este rulată în interiorul unui repozitoriu Git existent; poți anula această comportare folosind cargo new --vcs=git.
Notă: Git este un sistem popular de control al versiunilor. Poți modifica
cargo newpentru a folosi un alt sistem de control al versiunilor sau niciun sistem de control al versiunilor folosind comutația--vcs. Ruleazăcargo new --helppentru a vedea opțiunile disponibile.
Deschide Cargo.toml în editorul tău de text preferat. Ar trebui să arate similar cu codul din Listarea 1-2.
Numele fișierului: Cargo.toml
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
Listarea 1-2: Conținutul lui Cargo.toml generat de cargo new
Acest fișier este în formatul TOML (Tom’s Obvious, Minimal Language), care este formatul de configurare al lui Cargo.
Prima linie, [package], este o rubrică de secțiune care indică faptul că declarațiile următoare configurează un pachet. Pe măsură ce adăugăm mai multe informații la acest fișier, vom adăuga și alte secțiuni.
Următoarele trei linii setează informațiile de configurare de care Cargo are nevoie pentru a compila programul tău: numele, versiunea și ediția Rust pe care să o folosească. Vom vorbi despre cheia edition în Anexa E.
Ultima linie, [dependencies], este începutul unei secțiuni în care poți enumera orice dependențe ale proiectului tău. În Rust, pachetele de cod sunt numite crates. Nu vom avea nevoie de alte crate-uri pentru acest proiect, dar vom avea în primul proiect din Capitolul 2, deci vom folosi această secțiune de dependențe atunci.
Acum deschide src/main.rs și aruncă o privire:
Numele fișierului: src/main.rs
fn main() { println!("Salut, lume!"); }
Cargo tocmai a generat un program „Salut, lume!”, identic cu cel pe care l-am realizat noi în Listarea 1-1! Până acum, principalele diferențe dintre proiectul nostru și cel creat de Cargo sunt așezarea codului în directoriul src și existența unui fișier de configurare Cargo.toml în directoriul rădăcină.
Cargo așteaptă ca fișierele sursă să fie poziționate în interiorul directoriului src. Directoriul rădăcină al proiectului este destinat doar pentru fișierele README, informațiile despre licență, fișiere de configurare și orice altceva care nu este direct legat de cod. Utilizarea Cargo contribuie la organizarea eficientă a proiectelor tale, având un loc bine definit pentru fiecare componentă și asigurându-se că toate componentele sunt la locul potrivit.
Dacă ai început un proiect fără să folosești Cargo, așa cum am procedat noi cu proiectul „Salut, lume!”, poți să îl transformi într-un proiect care utilizează Cargo. Trebuie să muti codul în directoriul src și să creezi un fișier Cargo.toml adecvat.
Compilarea și rularea unui proiect Cargo
Acum să ne uităm la ce e diferit când compilăm și rulăm programul „Salut, lume!” cu Cargo! Din directoriul tău hello_cargo, compilează proiectul prin introducerea următoarei comenzi:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
Această comandă creează un fișier executabil în target/debug/hello_cargo (sau target\debug\hello_cargo.exe pe Windows) mai degrabă decât în directoriul tău curent. Pentru că build-ul implicit este un build de depanare, Cargo pune binarul într-un directoriu numit debug. Poți rula executabilul cu această comandă:
$ ./target/debug/hello_cargo # sau .\target\debug\hello_cargo.exe pe Windows
Salut, lume!
Dacă totul merge conform planului, Hello, world! ar trebui să fie afișat în terminal. Folosirea comenzii cargo build pentru prima oară, de asemenea, determină Cargo să creeze un fișier nou la nivelul cel mai de sus: Cargo.lock. Acest fișier ține evidența versiunilor exacte ale dependențelor din proiectul tău. Proiectul acesta nu are dependențe, așadar fișierul este destul de simplu. Nu va fi necesar să intervenim manual asupra acestui fișier; Cargo va gestiona conținutul pentru noi.
Am compilat un proiect folosind cargo build și l-am executat cu ./target/debug/hello_cargo, însă putem de asemenea să utilizăm comanda cargo run pentru a compila codul și apoi a executa fișierul rezultat, totul printr-o singură comandă:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Salut, lume!
Utilizarea cargo run este mai convenabilă decât să trebuiască să ne amintim să executăm cargo build și apoi să accedem toată calea către executabil, așa că majoritatea dezvoltatorilor preferă cargo run.
Observă că de această dată nu am văzut un afișaj care să indice dacă Cargo a compilat hello_cargo. Cargo a înțeles că fișierele nu au suferit modificări, și prin urmare, nu a necesitat o recompilare ci doar a executat binarul. Dacă ai modificat codul sursă, Cargo ar fi recompilat proiectul înainte de a-l executa, și ai fi observat acest afișaj:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Salut, lume!
Cargo oferă de asemenea o comandă numită cargo check. Această comandă verifică rapid codul tău pentru a se asigura că se compilează, dar nu produce un executabil:
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
De ce nu ai vrea un executabil? Adesea, cargo check este mult mai rapidă decât cargo build pentru că omite pasul de producere a unui executabil. Dacă verifici în continuu ce lucrezi în timp ce scrii codul, folosirea cargo check va accelera procesul de a te informa dacă proiectul tău încă se compilează! Astfel, mulți Rustaceani rulează cargo check periodic în timp ce scriu programul lor pentru a se asigura că se compilează. Apoi ei rulează cargo build când sunt gata să folosească executabilul.
Să recapitulăm ce am învățat până acum despre Cargo:
- Putem crea un proiect folosind
cargo new. - Putem compila un proiect folosind
cargo build. - Putem compila și rula un proiect într-un singur pas folosind
cargo run. - Putem compila un proiect fără a produce un binar pentru a verifica erorile folosind
cargo check. - În loc sa salvăm rezultatul build-ului in același directoriu cu codul nostru, Cargo il stocheaza in directoriul target/debug.
Un avantaj suplimentar al folosirii lui Cargo este că comenzile sunt la fel, indiferent de sistemul de operare pe care lucrezi. Așadar, de la acest punct nu vom mai oferi instrucțiuni specifice pentru Linux și macOS versus Windows.
Compilarea pentru lansare
Când proiectul tău este în sfârșit gata de lansare, poți utiliza cargo build --release pentru a-l compila cu optimizări. Această comandă va crea un executabil în target/release în loc de target/debug. Optimizările fac codul tău Rust să ruleze mai rapid, dar activarea lor mărește timpul necesar pentru compilarea programului. Din acest motiv există două profiluri diferite: unul pentru dezvoltare, când vrei să recompilezi repede și des, și altul pentru compilarea programului final pe care îl vei oferi unui utilizator care nu va fi recompilat în mod repetat și care va rula cât mai rapid posibil. Dacă îți evaluezi timpul de rulare al codului, nu uita să folosești comanda cargo build --release și să realizezi evaluarea cu executabilul din target/release
Cargo în calitate de convenție
Pentru proiecte simple, Cargo nu oferă multă valoare peste utilizarea directă a lui rustc, dar își va demonstra valoarea pe măsură ce programele tale devin mai complexe. Odată ce programele cresc la mai multe fișiere sau au nevoie de o dependență, este mult mai ușor să lași Cargo să coordoneze compilarea.
Deși proiectul hello_cargo este simplu, acum folosește o mare parte din instrumentele reale pe care le vei folosi în restul carierei tale Rust. De fapt, pentru a lucra la orice proiecte existente, poți folosi următoarele comenzi pentru a verifica codul folosind Git, pentru a schimba directoriul către acel proiect și pentru a compila:
$ git clone example.org/someproject
$ cd someproject
$ cargo build
Pentru mai multe informații despre Cargo, vezi documentația sa.
Sumar
Ești deja pe drumul cel bun în călătoria ta cu Rust! În acest capitol, ai învățat să:
- Instalezi cea mai recentă versiune stabilă a Rust folosind
rustup - Actualizezi la o versiune mai nouă a Rust
- Deschizi documentația instalată local
- Scrii și rulezi un program „Salut, lume!” folosind
rustcdirect - Creezi și rulezi un proiect nou folosind convențiile Cargo
Acesta este momentul perfect pentru a crea un program mai substanțial pentru a te familiariza cu citirea și scrierea codului Rust. Așadar, în Capitolul 2, vom scrie un program de joc de ghicit. Dacă ai prefera mai degrabă să începi prin a învăța cum funcționează conceptele comune de programare în Rust, vezi Capitolul 3 și apoi întoarce-te la Capitolul 2.
Programarea unui joc de ghicit
Să ne avântăm în Rust lucrând împreună la un proiect direct aplicabil! În acest capitol o să te familiarizezi cu câteva concepte uzitate în Rust, arătându-ți cum să le aplici într-un program concret. Îți vei însuși cunoștințe despre let, match, metode, funcții asociate, crate-uri externe și mai mult! În capitolele ce urmează, vom aprofunda aceste idei. Pentru moment, ne vom concentra pe exersarea noțiunilor fundamentale.
Vom pune în aplicare o problemă emblematică pentru începătorii în programare: un joc de ghicit. Iată în ce constă: programul va genera un număr întreg aleatoriu între 1 și 100. Va solicita apoi jucătorului să introducă o ghicire. După ce un număr a fost introdus, programul va specifica dacă acesta este prea mic sau prea mare. Dacă răspunsul este corect, jocul va afișa un mesaj de felicitare și se va închide.
Formarea unui proiect nou
Pentru a forma un proiect nou, mergi la directoriul proiecte pe care l-ai creat în Capitolul 1 și fă un proiect nou folosind Cargo, astfel:
$ cargo new guessing_game
$ cd guessing_game
Prima comandă, cargo new, ia numele proiectului (guessing_game) ca prim argument. A doua comandă trece la directoriul noului proiect.
Aruncă o privire la fișierul Cargo.toml generat:
Numele fișierului: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
După cum ai văzut în Capitolul 1, cargo new generează un program “Salut, lume!” pentru tine. Verifică fișierul src/main.rs:
Numele fișierului: src/main.rs
fn main() { println!("Hello, world!"); }
Acum să compilăm acest program „Salut, lume!" și să îl rulăm în același pas folosind comanda cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 1.50s
Running `target/debug/guessing_game`
Hello, world!
Comanda run este utilă când ai nevoie să iterezi rapid pe un proiect, așa cum vom face în acest joc, testând rapid fiecare iterație înainte de a trece la următoarea.
Deschide din nou fișierul src/main.rs. Vei scrie tot codul în acest fișier.
Procesarea unei ghiciri
Prima parte a programului de ghicit va cere intrarea utilizatorului, va procesa acea intrare și va verifica dacă intrarea este în forma așteptată. Pentru început, vom permite jucătorului să introducă o ghicire. Introdu codul din Listare 2-1 în src/main.rs.
Numele fișierului: src/main.rs
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Lstarea 2-1: Cod care obține o ghicire de la utilizator și o tipărește
Acest cod conține o mulțime de informații, deci să-l parcurgem linie cu linie. Pentru a obține intrarea utilizatorului și apoi a printa rezultatul ca ieșire, avem nevoie să aducem biblioteca io de intrare/ieșire în scopul nostru. Biblioteca io vine din biblioteca standard, cunoscută sub numele de std:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}În mod implicit, Rust are un set de elemente definite în librăria standard pe care le introduce în domeniul de vizibilitatea al fiecărui program. Acest set se numește prelude, și poți vedea tot ce se află în el în documentația librăriei standard.
Dacă un tip pe care dorești să-l folosești nu se află în prelude, trebuie să introduci acel tip explicit în domeniu cu o instrucțiune use. Utilizarea librăriei std::io îți oferă un număr de caracteristici utile, inclusiv capacitatea de a accepta intrarea utilizatorului.
După cum ai văzut în Capitolul 1, funcția main este punctul de intrare în program:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Sintaxa fn declară o nouă funcție; parantezele, (), indică faptul că nu există parametri; iar paranteza rotundă, {, începe corpul funcției.
Așa cum ai învățat și în Capitolul 1, println! este o macrocomandă care tipărește un string pe ecran:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Acest cod afișează un prompt care indică ce joc este și solicită intrare de la utilizator.
Păstrarea valorilor cu variabile
În continuare, vom crea o variabilă pentru a stoca input-ul utilizatorului, astfel:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Acum programul devine interesant! Se întâmplă multe în această mică linie. Folosim declarația let pentru a crea variabila. Iată un alt exemplu:
let apples = 5;Această linie de cod creează o nouă variabilă numită apples și o leagă de valoarea 5. În Rust, variabilele sunt imutabile în mod implicit, ceea ce înseamnă că odată ce dăm variabilei o valoare, valoarea nu se va schimba. Vom discuta acest concept în detaliu în secțiunea „Variabile și mutabilitate” din Capitolul 3. Pentru a face o variabilă mutabilă, adăugăm mut înainte de numele variabilei:
let apples = 5; // imutabil
let mut bananas = 5; // mutabilNotă: Sintaxa
//începe un comentariu care continuă până la sfârșitul liniei. Rust ignoră totul în comentarii. Vom discuta comentariile în mai multe detalii în Capitolul 3.
Revenind la programul de ghicit, acum știi că let mut guess va introduce o variabilă mutabilă denumită guess. Semnul egal (=) spune lui Rust că dorim să legăm ceva la variabilă acum. Pe dreapta semnului egal se află valoarea la care guess este legată, care este rezultatul apelării functiei String::new, o funcție care returnează o nouă instanță a unui String. String este un tip de string furnizat de librăria standard care este un text codificat UTF-8 care poate să crească.
Sintaxa :: din linia ::new indică că new este o funcție asociată tipului String. O funcție asociată este o funcție care este implementată pe un tip, în acest caz String. Această funcție new creează un string nou și gol. Vei găsi o funcție new în multe tipuri deoarece este un nume obișnuit pentru o funcție care face o valoare nouă de un anume fel.
În întregime, linia let mut guess = String::new(); a creat o variabilă mutabilă care este în prezent legată de o nouă instanță goală a unui String. Uf!
Primirea datelor introduse de utilizator
Ține minte că am inclus funcționalitatea de intrare/ieșire din biblioteca standard cu use std::io; pe prima linie a programului. Acum vom apela funcția stdin din modulul io, care ne va permite să gestionăm datele introduse de utilizator:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Dacă nu am fi importat biblioteca io cu use std::io; la începutul programului, am putea totuși să folosim funcția scriind acest apel de funcție ca std::io::stdin. Funcția stdin returnează o instanță a std::io::Stdin, care este un tip care reprezintă un handle la intrarea standard pentru terminalul tău.
Următoarea linie, .read_line(&mut guess) apelează metoda read_line pe handle-ul de intrare standard pentru a primi datele introduse de utilizator. De asemenea, trimitem &mut guess ca argument pentru read_line, pentru a-i spune în ce string să stocheze datele introduse de utilizator. Rolul principal al read_line este de a prelua tot ceea ce tapează utilizatorul în intrarea standard și de a adăuga aceste date într-un string (fără a-i suprascrie conținutul), deci vom trimite acest string ca argument. String-ul de argument trebuie să fie mutabil pentru ca metoda să poată schimba conținutul lui.
Simbolul & indică faptul că acest argument este o referință, care îți oferă o modalitate de a permite mai multor părți ale codului tău să acceseze o singură piesă de date fără a avea nevoie să copiezi acele date în memorie de mai multe ori. Referințele sunt o caracteristică complexă, iar unul dintre principalele avantaje ale Rust este cât de sigur și ușor e de utilizat referințele. Nu ai nevoie să știi o mulțime de acele detalii pentru a termina acest program. Deocamdată, tot ce trebuie să știi este că, la fel ca variabilele, referințele sunt imutabile în mod implicit. De aceea, trebuie să scrii &mut guess în loc de &guess pentru a-l face mutabil. (Capitolul 4 va explica referințele mai detaliat.)
Gestionarea potențialelor eșecuri cu Result
Încă lucrăm la această linie de cod. Acum discutăm despre a treia linie de text, dar reține că aceasta face încă parte dintr-o singură linie logică de cod. Partea următoare este această metodă:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Am fi putut scrie acest cod astfel:
io::stdin().read_line(&mut guess).expect("Failed to read line");Cu toate acestea, o linie lungă este dificil de citit, deci este cel mai bine să o împărțim. Este adesea înțelept să introduci o linie nouă și alte spații albe pentru a ajuta la divizarea liniilor lungi atunci când apelezi o metodă cu sintaxa .nume_metoda(). Acum să discutăm ce face această linie.
După cum am menționat mai devreme, read_line introduce ceea ce introduce utilizatorul în string-ul pe care îl transmitem, dar returnează și o valoare de tip Result. Result este o enumerare, adesea numită și enum, care este un tip care poate fi într-una din multiple stări posibile. Fiecare stare posibilă o numim variantă.
Capitolul 6 va acoperi enumerările în mai mult detaliu. Scopul acestor tipuri Result este de a codifica informațiile de gestionare a erorilor.
Variantele Result sunt Ok și Err. Varianta Ok indică faptul că operațiunea a fost reușită, iar în interiorul Ok se află valoarea generată cu succes. Varianta Err înseamnă că operațiunea a eșuat, iar Err conține informații despre cum sau de ce a eșuat operațiunea.
Valorile de tip Result, ca și valorile de orice alt tip, au metode definite asupra lor. O instanță a Result are o metodă expect pe care o poți apela. Dacă această instanță a Result este o valoare Err, expect va provoca căderea programului și afișarea mesajului pe care l-ai transmis ca argument către expect. Dacă metoda read_line întoarce o Err, ar fi probabil rezultatul unei erori provenite de la sistemul de operare de baza. Dacă această instanță a Result este o valoare Ok, expect va prelua valoarea de return pe care Ok o deține și îți va returna doar acea valoare pentru a o putea folosi. În acest caz, acea valoare este numărul de octeți în intrarea utilizatorului.
Dacă nu apelezi expect, programul se va compila, dar vei primi un avertisment:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
Rust avertizează că nu ai folosit valoarea Result returnată de read_line, indicând faptul că programul nu a gestionat o posibilă eroare.
Modul corect de a suprima avertismentul este de a scrie într-adevăr cod de gestionare a erorilor, dar în cazul nostru dorim doar să prăbușim acest program atunci când apare o problemă, așa că putem folosi expect. Vei învăța despre recuperarea din erori în Capitolul 9.
Afișarea valorilor cu substituții println!
Afară de acolada de închidere, nu ne-a mai rămas decât un singur rând de discutat din codul de până acum:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Acest rând afișează șirul de caractere care conține acum intrarea utilizatorului. Setul de acolade {} este un substituent: consideră {} ca fiind niște clești de crab care țin o valoare pe loc. La afișarea valorii unei variabile, numele variabilei poate intra în acolade. La afișarea rezultatului evaluării unei expresii, plasați acoladele goale în string-ul de format, apoi urmați string-ul de format cu o listă separată prin virgulă cu expresii care trebuie afișate în fiecare substituent de acolade goale, în aceeași ordine. Afișarea unei variabile și a rezultatului unei expresii într-un singur apel către println! ar arăta astfel:
#![allow(unused)] fn main() { let x = 5; let y = 10; println!("x = {x} and y + 2 = {}", y + 2); }
Acest cod ar afișa x = 5 and y + 2 = 12.
Testarea primei părți
Să testăm prima parte a jocului de ghicit. Rulează-l folosind cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/guessing_game`
Guess the number!
Please input your guess.
6
You guessed: 6
Până în acest punct, prima parte a jocului este gata: noi primim input de la tastatură și apoi îl afișăm.
Generarea unui număr secret
În continuare, trebuie să generăm un număr secret pe care utilizatorul va încerca să îl ghicească. Numărul secret ar trebui să fie diferit de fiecare dată pentru ca jocul să fie distractiv de jucat de mai multe ori. Vom folosi un număr aleatoriu între 1 și 100 astfel încât jocul să nu fie prea dificil. Rust nu include încă funcționalitatea numerelor aleatorii în biblioteca sa standard. Cu toate acestea, echipa Rust oferă un rand crate cu această funcționalitate.
Utilizarea unui crate pentru a obține mai multă funcționalitate
Este important să ținem minte că un crate este o colecție de fișiere sursă Rust. Proiectul nostru este un crate binar, adică un executabil. În contrast, crate-ul rand este un crate de bibliotecă, conținând cod destinat să fie utilizat în cadrul altor programe și care nu poate fi executat de sine stătător.
Capacitatea lui Cargo de a coordona crate-uri externe este aspectul în care Cargo se evidențiază cu adevărat. Pentru a putea scrie cod ce folosește rand, este necesar să facem o ajustare în fișierul Cargo.toml, incluzând crate-ul rand între dependențe. Deschide fișierul chiar acum și adaugă la partea de jos următoarea linie, dedesubtul secțiunii [dependencies] pe care Cargo a generat-o automat pentru tine. E vital să specifici rand exact cum e indicat aici, cu această versiune, deoarece în caz contrar exemplele de cod din acest tutorial pot să nu funcționeze normal:
Numele fișierului: Cargo.toml
[dependencies]
rand = "0.8.5"
În fișierul Cargo.toml, tot ce se află după un antet aparține acelei secțiuni care continuă până când o altă secțiune începe. În [dependencies] indicăm lui Cargo care crate-uri externe sunt necesare proiectului tău și ce versiuni ale acestor crate-uri trebuie utilizate. În acest caz, specificăm crate-ul rand cu specificatorul de versiune semantică 0.8.5. Cargo cunoaște Versionarea semantică (adesea numit SemVer), care e un standard pentru a scrie numerele de versiune. Specificantul 0.8.5 este de fapt o scurtătură pentru ^0.8.5, ceea ce înseamnă orice versiune cel puțin 0.8.5 dar mai mică de 0.9.0.
Cargo consideră aceste versiuni ca având API-uri publice compatibile cu versiunea 0.8.5, iar această specificare garantează că vei obține cea mai recentă versiune cu patch-uri compatibile care vor compila corect cu codul din acest capitol. Nu este garantat ca versiunile 0.9.0 sau mai mari să păstreze același API ca exemplele utilizate aici.
Acum, fără a modifica vreun cod, să construim proiectul, așa cum este ilustrat în Listarea 2-2.
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
Downloaded libc v0.2.127
Downloaded getrandom v0.2.7
Downloaded cfg-if v1.0.0
Downloaded ppv-lite86 v0.2.16
Downloaded rand_chacha v0.3.1
Downloaded rand_core v0.6.3
Compiling libc v0.2.127
Compiling getrandom v0.2.7
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.16
Compiling rand_core v0.6.3
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 2.53s
Listarea 2-2: Afișajul rezultat după executarea cargo build în urma adăugării crate-ului rand ca dependență
Poți întâlni numere de versiuni diferite (dar toate vor fi compatibile cu codul, datorită SemVer!) și linii diferite (care vor varia în funcție de sistemul de operare), iar ordinea liniilor poate fi diferită.
Atunci când introducem o dependență externă, Cargo caută și descarcă versiunile cele mai recente ale tuturor elementelor necesare acelei dependențe din registru, o copie a datelor de pe Crates.io. Crates.io este platforma unde comunitatea Rust își publică proiectele Rust open source, disponibile pentru folosirea de către toți.
Cargo verifică secțiunea [dependencies] după ce actualizează registrul și descarcă crate-urile enumerate ce nu au fost încă descărcate. Deși am specificat doar rand ca dependență, Cargo a descărcat și alte crate-uri de care rand are nevoie pentru funcționarea sa. Odată ce crate-urile sunt descărcate, Rust le compilează, și apoi compilarea proiectului nostru are loc cu aceste dependențe incluse.
Dacă rulezi cargo build din nou imediat, fără a modifica ceva, nu vei obține niciun afișaj în afară de linia Finished. Cargo știe că a descărcat și compilat deja dependențele și că tu nu ai modificat nimic în fișierul Cargo.toml. De asemenea, Cargo înțelege că nici codul tău nu a fost schimbat, așadar nu recompilează nimic. Neavând ce să facă, se închide simplu.
Dacă ești în src/main.rs, faci o mică schimbare, salvezi și compilezi din nou, vei observa doar două linii de afișaj:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 2.53 secs
Aceste linii arată că Cargo actualizează build-ul doar cu micuța ta modificare la fișierul src/main.rs. Dependențele tale nu s-au schimbat, așa că Cargo știe că poate reutiliza ceea ce deja a descărcat și compilat pentru acestea.
Asigurarea compilărilor reproductibile cu fișierul Cargo.lock
Cargo are un mecanism care garantează că poți reconstrui același artefact de fiecare dată când tu sau altcineva compilați codul: Cargo va utiliza doar versiunile specificate de dependențe, până nu decizi altceva. De exemplu, presupunem că săptămâna viitoare va fi lansată versiunea 0.8.6 a crate-ului rand și că aceasta include o reparație critică de bug, dar totodată și o regresie care îți va afecta codul. Pentru a gestiona aceasta, Rust generează fișierul Cargo.lock prima oară când execuți cargo build, deci acum îl avem în directoriul guessing_game.
La prima compilare a proiectului, Cargo determină toate versiunile compatibile pentru dependențe și le înscrie în fișierul Cargo.lock. La compilările ulterioare, Cargo va recunoaște prezența fișierului Cargo.lock și va folosi versiunile înregistrate acolo, evitând astfel munca repetitivă de selecție a versiunilor. Astfel, construcția proiectului tău devine reproductibilă automat. În alte cuvinte, proiectul va rămâne la versiunea 0.8.5 până când alegi explicit să faci o actualizare, datorită existenței fișierului Cargo.lock. Fiind esențial pentru reproduceri consecvente, fișierul Cargo.lock este adesea inclus în controlul de versiune alături de restul codului proiectului tău.
Actualizarea unui crate pentru a obține o versiune nouă
Atunci când dorești să actualizezi un crate, Cargo pune la dispoziție comanda update, care va ignora fișierul Cargo.lock și va determina cele mai recente versiuni ce se potrivesc specificațiilor din Cargo.toml. Cargo va înregistra aceste versiuni în fișierul Cargo.lock. Implicit, Cargo caută versiuni care sunt mai mari decât 0.8.5 și mai mici de 0.9.0. Dacă crate-ul rand a introdus două noi versiuni, 0.8.6 și 0.9.0, ai vedea următorul rezultat dacă ai executa cargo update:
$ cargo update
Updating crates.io index
Updating rand v0.8.5 -> v0.8.6
Cargo va ignora lansarea versiunii 0.9.0. De asemenea, ai remarca o modificare în fișierul tău Cargo.lock, care arată că acum folosești versiunea 0.8.6 a crate-ului rand. Pentru a utiliza versiunea rand 0.9.0 sau orice altă versiune din seria 0.9.x, trebuie să actualizezi fisierul Cargo.toml astfel:
[dependencies]
rand = "0.9.0"
Data următoare când rulezi cargo build, Cargo va actualiza lista de crate-uri disponibile și va reevalua cerința ta pentru rand în funcție de noua versiune pe care ai specificat-o.
Există multe alte lucruri de spus despre Cargo și ecosistemul său, pe care le vom discuta în Capitolul 14. Până acum, aceste informații sunt tot ce trebuie să știi. Cargo facilitează în mare măsură reutilizarea bibliotecilor, ceea ce permite programatorilor Rust să creeze proiecte mai compacte, compuse din diverse pachete.
Generarea unui număr aleatoriu
Să începem folosirea bibliotecii rand pentru a genera un număr de ghicit. Următorul pas este să actualizăm fișierul src/main.rs, așa cum se arată în Listarea 2-3.
Numele fișierului: src/main.rs
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Listarea 2-3: Adăugarea de cod pentru a genera un număr aleatoriu
În primul rând, adăugăm linia use rand::Rng;. Trăsătura Rng definește metodele pe care le implementează generatorii de numere aleatorii și trebuie să fie în domeniul de vizibilitate pentru a folosi acele metode. Trăsăturile vor fi explicate în detaliu în Capitolul 10.
Următoarea parte implică adăugarea a două linii noi în cod. În prima linie apelăm funcția rand::thread_rng, care ne oferă generatorul de numere aleatorii specific firului de execuție curent și care este inițiat de sistemul de operare. Apoi utilizăm metoda gen_range de la acel generator de numere. Metoda gen_range, definită de trăsătura Rng adusă în context cu instrucțiunea use rand::Rng;, primește o expresie de diapazon și generează un număr aleatoriu în interiorul acelui diapazon. Expresia de diapazon pe care o utilizăm este start..=end, care este inclusivă pentru ambele limite, deci specificăm 1..=100 pentru a obține un număr între 1 și 100.
Notă: Nu vei cunoaște întotdeauna care trăsături trebuie utilizate și ce metode și funcții să apelezi de la un crate, prin urmare, fiecare crate vine echipat cu propria documentație și instrucțiuni pentru a te ghida în utilizarea sa. O funcționalitate practică a Cargo este că executarea comenzii
cargo doc --openva genera documentația furnizată de toate dependențele tale local și o va deschide în navigatorul web. Dacă ai curiozitatea de a explora alte funcții ale crate-uluirand, de exemplu, executăcargo doc --openși selecteazăranddin bara laterală din partea stângă.
Cea de-a doua linie nouă afișează numărul secret, ceea ce este util pe durata dezvoltării programului pentru a-l putea testa, însă o vom șterge în versiunea finală. Nu se poate spune că este un joc prea incitant dacă programul dezvăluie soluția imediat ce este lansat.
Încearcă să rulezi programul de câteva ori:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 2.53s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 7
Please input your guess.
4
You guessed: 4
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 83
Please input your guess.
5
You guessed: 5
Ar trebui să obții numere aleatorii diferite, iar toate ar trebui să fie numere între 1 și 100. Excelentă treabă!
Compararea ghicirii cu numărul secret
Acum că avem o intrare de la utilizator și un număr aleator, le putem compara. Acest pas este arătat în Listarea 2-4. Reține că acest cod nu se va compila încă, așa cum vom explica.
Numele fișierului: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
// --snip--
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Listarea 2-4: Gestionarea posibilelor rezultate ale comparării a două numere
Mai întâi, adăugăm o altă declarație use, introducând în scopul nostru un tip numit std::cmp::Ordering din biblioteca standard. Tipul Ordering este o altă enumerare și are variantele Less, Greater și Equal. Acestea sunt cele trei rezultate posibile când compari două valori.
Apoi, adăugăm cinci linii noi la final care utilizează tipul Ordering. Metoda cmp compară două valori și poate fi apelată pe orice tip de valori comprabile. E primește o referință la ce se dorește de a fi comparat: aici se face compararea între guess și secret_number. Apoi returnează o variantă a enumerației Ordering pe care am adus-o în scop cu declarația use. Folosim o expresie match pentru a decide ce să facem în continuare bazat pe ce variantă a Ordering a fost returnată de apelul la cmp cu valorile din guess și secret_number.
O expresie match este compusă din brațe. Un braț constă dintr-un model (numit și pattern) pentru care se face potrivirea, și din codul care ar trebui să ruleze dacă valoarea dată lui match se potrivește cu modelul acelui braț. Rust ia valoarea dată lui match și o compară cu modelul fiecărui braț pe rând. Modelele și constructul match reprezintă caracteristici forte ale lui Rust: îți permit să exprimi o varietate de situații pe care codul tău le-ar putea întâlni și se asigură că le gestionezi pe toate. Aceste caracteristici vor fi acoperite în detaliu în Capitolul 6 și Capitolul 18, respectiv.
Acum să trecem printr-un exemplu cu expresia match pe care o folosim aici. Să presupunem că utilizatorul a ghicit numărul 50 și de data aceasta numărul secret generat aleator este 38.
Atunci când codul compară numărul 50 cu 38, metoda cmp va returna Ordering::Greater, deoarece 50 este mai mare decât 38. Expresia match primește valoarea Ordering::Greater și începe să verifice modelul pentru fiecare braț. Analizează primul tipar de braț, Ordering::Less, și vede că valoarea Ordering::Greater nu se potrivește cu Ordering::Less, deci ignoră codul din acel braț și trece la brațul următor. Modelul următorului braț este Ordering::Greater, care se potrivește cu Ordering::Greater! Codul asociat acestui braț va fi executat și va imrima pe ecran Too big!. Expresia match se încheie după prima potrivire reușită, deci nu se va uita la ultimul braț în acest scenariu.
Totuși, codul din Listarea 2-4 încă nu se va compila. Să încercăm:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
error[E0308]: mismatched types
--> src/main.rs:22:21
|
22 | match guess.cmp(&secret_number) {
| --- ^^^^^^^^^^^^^^ expected struct `String`, found integer
| |
| arguments to this function are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: associated function defined here
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/cmp.rs:783:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `guessing_game` due to previous error
Esența erorii indică existența unor tipuri incompatibile. Rust se bazează pe un sistem de tipuri puternic și tipizat static. În același timp, Rust suportă inferență de tipuri. Atunci când am scris let mut guess = String::new(), Rust a inferat că guess ar trebui să fie un String fără să fie necesar să specificăm tipul. Pe de altă parte, secret_number este de un tip numeric. Există mai multe tipuri numerice în Rust care pot avea valori între 1 și 100: i32, un număr pe 32 de biți; u32, un număr nesemnat pe 32 de biți; i64, un număr pe 64 de biți; printre altele. Dacă nu se indică altfel, Rust alege i32 în mod implicit, care este tipul pentru secret_number dacă nu adăugăm informații despre tip în altă parte care ar determina Rust să infereze un alt tip numeric. Eroarea apare pentru că Rust nu poate face comparație între un string și un tip numeric.
Pentru a o rezolva, intenționăm să convertim String-ul primit ca input într-un tip numeric real, astfel încât să putem face comparația numerică cu numărul secret. Acest lucru se realizează adăugând următoarea linie în corpul funcției main:
Numele fișierului: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Linia este:
let guess: u32 = guess.trim().parse().expect("Please type a number!");Creăm o variabilă numită guess. Dar așteaptă, nu există deja o variabilă cu numele guess în program? Da, dar, convenabil, Rust ne permite să umbrim precedentul guess cu unul nou. Umbrirea ne permite să reutilizăm numele variabilei guess în loc să fim obligați să creăm două variabile diferite, cum ar fi guess_str și guess, de exemplu. Vom detalia acest concept în Capitolul 3, dar pentru moment, să știi că această funcționalitate este adesea folosită când vrei să convertești o valoare dintr-un tip în altul.
Noua variabilă este asociată expresiei guess.trim().parse(). Partea guess din cadrul expresiei se referă la variabila originală guess care conținea input-ul ca un string. Metoda trim pe o instanță String va elimina orice spațiu alb (whitespace) de la început și sfârșitul string-ului, lucru necesar pentru a putea compara string-ul cu un u32, ce poate conține doar date numerice. Utilizatorul trebuie să apese enter pentru a completa read_line și așa să introducă ghicirea sa, adăugând prin asta un caracter de linie nouă la string. De exemplu, dacă utilizatorul scrie 5 și apasă enter, guess arată așa: 5\n. \n reprezintă „newline” (linie nouă). (Pe Windows, apăsarea enter aduce un carriage return și un newline, \r\n.) Metoda trim înlătură \n sau \r\n, lăsând doar 5.
Metoda parse de pe string-uri transformă un string într-un alt tip. În acest caz, o utilizăm pentru a converti un string într-un număr. Trebuie să specificăm în Rust tipul exact de număr pe care îl dorim, utilizând let guess: u32. Două puncte (:) care urmează după guess indică faptul că vom adnota tipul variabilei. Rust include diferite tipuri de numere; u32, pe care îl vedem aici, reprezintă un întreg pozitiv fără semn și de 32 de biți. Este o opțiune predilectă pentru reprezentarea unui număr mic și pozitiv. Despre alte tipuri de numere vei afla în Capitolul 3.
De asemenea, prin folosirea adnotării u32 în acest exemplu și prin comparația cu secret_number, Rust va înțelege că și secret_number trebuie să fie u32. Astfel, comparația se va face între două valori de același tip!
Metoda parse este aplicabilă doar caracterelor ce pot fi convertite în mod logic către numere și, prin urmare, este susceptibilă de erori. Dacă, spre exemplu, string-ul ar conţine A👍%, nu ar exista nicio modalitate de a-l converti într-un număr. Fiind posibil să eșueze, metoda parse returnează un tip Result, într-un mod similar cu metoda read_line (abordată anterior în „Tratarea eșecurilor potențiale cu Result”). Vom reacționa în fața acestui Result în același mod, utilizând din nou metoda expect. Dacă parse întoarce o variantă de Err a tipului Result, deoarece nu a putut transforma string-ul într-un număr, apelul expect va opri jocul și va tipări mesajul specificat de noi. În situația în care parse reușește să convertească string-ul într-un număr cu succes, va returna varianta Ok a Result, iar metoda expect va extrage numărul dorit din valoarea Ok.
Să rulăm acum programul:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 58
Please input your guess.
76
You guessed: 76
Too big!
Foarte bine! Deși au fost adăugate spații înainte de ghicire, programul a reușit totuși să-și dea seama că utilizatorul a ghicit numărul 76. Rulează programul de câteva ori pentru a verifica comportamentul diferit cu diferite tipuri de input: ghicește numărul corect, ghicește un număr care este prea mare sau ghicește un număr care este prea mic.
Acum avem majoritatea jocului funcțional, dar utilizatorul poate face doar o singură ghicire. Să schimbăm asta adăugând o buclă!
Permiterea multiplelor ghiciri cu bucle
Cuvântul cheie loop creează o buclă infinită. Vom adăuga o buclă pentru a oferi utilizatorilor mai multe încercări de a ghici numărul:
Numele fișierului: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
}După cum se poate observa, am mutat tot de la promptul de introducere a ghicirii într-o buclă. Asigură-te că liniile din interiorul buclei sunt indentate cu patru spații suplimentare fiecare și rulează din nou programul. Acum programul va solicita o nouă ghicire la nesfârșit, ceea ce introduce efectiv o nouă problemă: pare că utilizatorul nu are posibilitatea să părăsească programul!
Utilizatorul poate întrerupe întotdeauna programul utilizând combinația de taste ctrl-c. Există însă și o altă cale de a se elibera de acest ciclu infinit, așa cum am menționat în discuția despre parse din secțiunea “Compararea ghicirii cu numărul secret”: dacă utilizatorul scrie ceva ce nu este un număr, atunci programul va da eroare și se va opri. Putem folosi acest comportament ca o metodă prin care utilizatorul poate opri programul, după cum urmează:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 1.50s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 59
Please input your guess.
45
You guessed: 45
Too small!
Please input your guess.
60
You guessed: 60
Too big!
Please input your guess.
59
You guessed: 59
You win!
Please input your guess.
adio
thread 'main' panicked at 'Please type a number!: ParseIntError { kind: InvalidDigit }', src/main.rs:28:47
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Dacă introduci adio, jocul se va opri, însă vei observa că se va întâmpla același lucru dacă introduci orice alt input care nu e un număr. Aceasta este departe de a fi ideal; ne dorim ca jocul să se încheie și atunci când numărul ghicit este cel corect.
Terminarea jocului la o ghicire corectă
Să programăm jocul să se termine atunci când utilizatorul câștigă, prin adăugarea unei instrucțiuni break:
Numele fișierului: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Introducerea liniei break imediat după You win! determină programul să părăsească bucla atunci când utilizatorul ghicește numărul secret în mod corect. Părăsirea buclei înseamnă de asemenea finalizarea programului, deoarece bucla reprezintă ultima secțiune a funcției main.
Procesarea intrărilor non-valide
Pentru a îmbunătăți comportamentul jocului, în loc de a opri programul când utilizatorul introduce ceva ce nu este un număr, putem configura jocul să ignore acest tip de input, permițând utilizatorului să continue să ghicească. Acest lucru poate fi realizat modificând linia în care valoarea guess este convertită din String în u32, așa cum este ilustrat în Listarea 2-5.
Numele fișierului: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Listarea 2-5: Ignorarea unui input care nu este un număr și solicitarea unei noi încercări în locul oprii programului
Trecem de la o funcție expect la o expresie match pentru a gestiona erorile în locul oprii programului. Este important să ne amintim că parse returnează un tip Result și că Result este o enumerare cu variantele Ok și Err. Folosim o expresie match, la fel ca atunci când lucrăm cu Ordering rezultatul metodei cmp.
Când parse poate să convertească în mod eficient string-ul într-un număr, ne întoarce o valoare Ok care include numărul rezultat. Această valoare Ok se va potrivi cu modelul din primul caz al expresiei match, iar ca rezultat, vom primi numărul creat de parse și inclus în Ok. Numărul va fi pus exact unde trebuie în noua variabilă guess pe care o definim.
Dacă parse nu poate să convertească string-ul într-un număr, ne va da o valoare Err care deține detalii despre eroare. Valoarea Err nu se potrivește cu modelul Ok(num) din primul caz al match, dar se potrivește cu Err(_) din cel de-al doilea caz. Folosind _ ca wildcard, spunem că dorim să captăm orice fel de valoare Err, fără a ne preocupa de conținutul acesteia. Programul va rula codul corespunzător celui de-al doilea caz, adică continue, care comandă programului să treacă la următoarea iterație a buclei loop și să solicite o încercare nouă. Astfel, ignorăm orice posibilă eroare care ar putea apărea în timpul funcției parse.
Acum totul în program ar trebui să funcționeze conform așteptărilor. Să încercăm:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 4.45s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 61
Please input your guess.
10
You guessed: 10
Too small!
Please input your guess.
99
You guessed: 99
Too big!
Please input your guess.
foo
Please input your guess.
61
You guessed: 61
You win!
Minunat! Cu o mică ultimă ajustare, vom termina jocul de ghicit. Amintește-ți că programul încă afișează numărul secret. Acest lucru a funcționat bine pentru testare, dar strică jocul. Să ștergem println! care afișează numărul secret. Listarea 2-6 arată codul final.
Filename: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Listarea 2-6: Codul complet al jocului de ghicire
La acest moment, ai reușit să construiești cu succes jocul de ghicire. Felicitări!
Sumar
Acest proiect a fost o modalitate practică de a face cunoștință cu multe concepte noi din Rust: let, match, funcții, utilizarea crate-urilor externe, și multe altele. În următoarele câteva capitole, vei învăța despre aceste concepte în mai multe detalii. Capitolul 3 acoperă funcționalități pe care majoritatea limbajelor de programare le au, cum ar fi variabile, tipuri de date și funcții, și arată cum să le folosești în Rust. Capitolul 4 explorează posesiunea (ownership), o caracteristică ce distinge Rust de alte limbaje. Capitolul 5 discută despre structuri și sintaxa metodelor, iar Capitolul 6 explică cum funcționează enumerările.
Concepte comune de programare
Acest capitol descrie concepte care apar în aproape fiecare limbaj de programare și cum funcționează ele în Rust. Multe limbaje de programare au foarte multe în comun la baza lor. Niciunul dintre conceptele prezentate în acest capitol nu sunt unice pentru Rust, dar le vom discuta în contextul Rust și vom explica convențiile legate de utilizarea acestor concepte.
În mod specific, vei învăța despre variabile, tipuri de bază, funcții, comentarii, și fluxul de control. Aceste fundamente vor fi în fiecare program Rust, iar învățarea lor devreme îți va oferi un nucleu solid de pornire.
Cuvinte cheie
Limbajul Rust are un set de cuvinte cheie care sunt rezervate pentru utilizarea de către limbajul în sine, la fel ca în alte limbaje. Reține că nu poți folosi aceste cuvinte ca nume de variabile sau funcții. Majoritatea cuvintelor cheie au semnificații speciale, iar tu le vei folosi pentru a realiza diverse sarcini în programele tale Rust; câteva nu au nicio funcționalitate actuală asociată cu ele, dar au fost rezervate pentru funcționalități care ar putea fi adăugate în Rust în viitor. Poți găsi lista cuvintelor cheie în Anexa A.
Variabile și mutabilitate
Așa cum am menționat în secțiunea „Păstrarea valorilor cu variabile”, în mod implicit, variabilele sunt imutabile. Acesta este unul dintre numeroasele stimulente pe care Rust ți le oferă pentru a scrie codul tău într-un mod care să profite de siguranța și concurența ușoară pe care Rust le oferă. Cu toate acestea, ai încă opțiunea de a-ți face variabilele mutabile. Să explorăm cum și de ce Rust încurajează preferința pentru imutabilitate și de ce uneori ai putea vrea să alegi variabilele mutabile.
Când o variabilă este imutabilă, odată ce o valoare este atribuită unui nume, nu poți schimba acea valoare. Pentru a ilustra acest lucru, generează un nou proiect numit variables în directoriul tău projects utilizând cargo new variables.
Apoi, în noul tău directoriu variables, deschide src/main.rs și înlocuiește codul său cu următorul cod, care încă nu se va compila:
Numele fișierului: src/main.rs
fn main() {
let x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}Salvează și rulează programul folosind cargo run. Ar trebui să primești un mesaj de eroare privind o eroare de imutabilitate, așa cum se arată în această ieșire:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| -
| |
| first assignment to `x`
| help: consider making this binding mutable: `mut x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` due to previous error
Acest exemplu arată cum compilatorul te ajută să găsești erorile din programele tale. Erorile de compilare pot fi frustrante, dar în realitate ele înseamnă doar că programul tău nu face încă în siguranță ceea ce vrei să facă; ele nu înseamnă că nu ești un bun programator! Rustaceanii cu experiență tot primesc erori de compilare.
Ai primit mesajul de eroare cannot assign twice to immutable variable `x` pentru că ai încercat să atribui o a doua valoare variabilei imutabile x.
Este important să primim erori la timpul compilării când încercăm să schimbăm o valoare care este desemnată ca imutabilă, deoarece această situație poate duce la bug-uri. Dacă o parte a codului nostru funcționează pe presupunerea că o valoare nu se va schimba niciodată și o altă parte a codului nostru schimbă acea valoare, este posibil ca prima parte a codului să nu facă ceea ce a fost proiectat să facă. Cauza acestui tip de bug poate fi dificil de urmărit ulterior, mai ales când a doua parte a codului schimbă valoarea doar uneori. Compilatorul Rust garantează că atunci când declari că o valoare nu se va schimba, ea cu adevărat nu se va schimba, astfel încât nu trebuie să urmărești asta singur. Astfel, codul tău este mai ușor de înțeles.
Dar mutabilitatea poate fi foarte utilă și poate face codul mai convenabil de scris. Deși variabilele sunt imutabile în mod implicit, le poți face mutabile adăugând mut în fața numelui variabilei, așa cum ai făcut în Capitolul 2. Adăugarea mut transmite și intenția cititorilor viitori ai codului, indicând că alte părți ale codului vor schimba această valoare a variabilei.
De exemplu, să schimbăm src/main.rs în următorul mod:
Numele fișierului: src/main.rs
fn main() { let mut x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); }
Când rulăm acum programul, obținem asta:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished dev [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
The value of x is: 5
The value of x is: 6
Ni se permite să modificăm valoarea legată la x de la 5 la 6 când este utilizat mut. În cele din urmă, decizia de a utiliza sau nu mutabilitatea depinde de tine și de ceea ce crezi că este cel mai evident în acea situație particulară.
Constante
La fel ca variabilele imutabile, constantele sunt valori care sunt legate de un nume și nu li se permite să se schimbe, dar există câteva diferențe între constante și variabile.
În primul rând, nu ai voie să folosești mut cu constante. Constantele nu sunt doar imutabile în mod implicit - sunt întotdeauna imutabile. Declari constante folosind cuvântul cheie const, în loc de cuvântul cheie let, iar tipul valorii trebuie să fie adnotat. Vom acoperi tipurile și adnotările de tip în următoarea secțiune, „Tipuri de date”, așa că nu-ți face griji despre aceste detalii acum. Trebuie doar să știi că trebuie întotdeauna să adnotezi tipul.
Constantele pot fi declarate în orice domeniul de vizibilitatea, inclusiv în cel global, ceea ce le face utile pentru valorile de care multe părți ale codului au nevoie să știe.
Ultima diferență este că constantele pot fi setate numai la o expresie constantă, nu la rezultatul unei valori care ar putea fi calculate doar în timpul rulării.
Iată un exemplu de declarare a unei constante:
#![allow(unused)] fn main() { const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3; }
Numele constantei este THREE_HOURS_IN_SECONDS și valoarea sa este setată la rezultatul înmulțirii cu 60 (numărul de secunde într-un minut) cu 60 (numărul de minute într-o oră) cu 3 (numărul de ore pe care dorim să le numărăm în acest program). Convenția de denumire a Rust pentru constante este să folosească doar majuscule cu subliniere între cuvinte. Compilatorul este capabil să evalueze un set limitat de operațiuni la momentul compilării, ceea ce ne permite să alegem să scriem această valoare într-un mod mai ușor de înțeles și de verificat, decât să setăm această constantă la valoarea 10,800. Vezi secțiunea Rust Reference privind evaluarea constantă pentru mai multe informații despre ce operațiuni pot fi utilizate la declararea constantelor.
Constantele sunt valabile pentru întreaga durată a rulării unui program, în cadrul în care au fost declarate. Această proprietate face ca constantele să fie utile pentru valorile din domeniul aplicației tale despre care multe părți ale programului ar putea avea nevoie să știe, cum ar fi numărul maxim de puncte pe care orice participant al unui joc are voie să le câștige, sau viteza luminii.
Specificând valorile particulare folosite într-un program ca fiind constante este util în a transmite semnificația acelei valori către viitorii întreținători ai codului. De asemenea, este util să avem doar un singur loc în codul nostru unde ar trebui să modificăm dacă eventual valoarea codificată ar trebui să fie actualizată în viitor.
Umbrirea
Cum am văzut în tutorialul jocului de ghicit în capitolul 2, putem declara o nouă variabilă cu același nume ca o variabilă anterioară. Rustacenii spun că prima variabilă este umbrită de a doua, ceea ce înseamnă că a doua variabilă este cea pe care compilatorul o va vedea atunci când folosești numele variabilei. Practic, a doua variabilă eclipsează prima, preluând orice utilizări ale numelui variabilei până când este la rândul său umbrită sau până când se termină contextul. Putem umbri o variabilă folosind același nume de variabilă și repetând utilizarea cuvântului cheie let astfel:
Numele fișierului: src/main.rs
fn main() { let x = 5; let x = x + 1; { let x = x * 2; println!("The value of x in the inner scope is: {x}"); } println!("The value of x is: {x}"); }
Acest program leagă întâi x la o valoare de 5. Apoi creează o nouă variabilă x repetând let x =, luând valoarea originală și adăugând 1, astfel încât valoarea x este apoi 6. Apoi, într-un context intern creat cu acolade, a treia declarație let umbrește, de asemenea, x și creează o nouă variabilă, înmulțind valoarea anterioară cu 2, pentru a da x o valoare de 12. Când acest context se termină, umbrirea internă se termină și x revine la a fi 6. Când rulăm acest program, va afișa următoarele:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
The value of x in the inner scope is: 12
The value of x is: 6
Umbrirea este diferită de marcarea unei variabile ca mut, deoarece vom obține o eroare la compilare dacă încercăm accidental să realocăm această variabilă fără a folosi cuvântul cheie let. Folosind let, putem efectua câteva transformări pe o valoare, dar avem variabila imutabilă după ce aceste transformări au fost finalizate.
Cea de-a doua diferență între mut și umbrire este că, deoarece creăm efectiv o nouă variabilă atunci când folosim din nou cuvântul cheie let, putem schimba tipul valorii, dar refolosim același nume. De exemplu, spunem că programul nostru cere unui utilizator să arate câte spații dorește între un text prin introducerea de caractere spațiu și apoi dorim să stocăm această intrare ca număr:
fn main() { let spaces = " "; let spaces = spaces.len(); }
Prima variabilă spaces este de tip string și a doua variabilă spaces este de tip număr. Astfel, umbrirea ne scutește să găsim nume diferite, cum ar fi spaces_str și spaces_num; în schimb, putem reutiliza numele mai simplu spaces. Cu toate acestea, dacă încercăm să folosim mut pentru acest lucru, așa cum se arată aici, vom obține o eroare la timpul de compilare:
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}Eroarea spune că nu avem voie să modificăm tipul unei variabile:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut spaces = " ";
| ----- expected due to this value
3 | spaces = spaces.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` due to previous error
Acum că am explorat cum funcționează variabilele, să examinăm mai multe tipuri de date pe care le pot avea.
Tipuri de date
Fiecare valoare în Rust este de un anumit tip de date, care indică Rust ce fel de date sunt specificate pentru a ști cum să lucreze cu acele date. Vom analiza două subansamble de tipuri de date: scalar și compus.
Amintiți-vă că Rust este un limbaj cu tipizare statică, ceea ce înseamnă că trebuie
să cunoaște tipurile tuturor variabilelor la momentul compilării. În general, compilatorul poate
infera ce tip dorim să folosim în funcție de valoare și cum o utilizăm. În cazurile
când sunt posibile mai multe tipuri, cum ar fi atunci când am convertit un String într-un
tip numeric folosind parse în secțiunea „Comparând guess-ul cu numărul secret”
din Capitolul 2, trebuie să adăugăm o adnotare de tip, astfel:
#![allow(unused)] fn main() { let guess: u32 = "42".parse().expect("Nu este un număr!"); }
Dacă nu adăugăm adnotarea de tip : u32 arătată în codul precedent, Rust va afișa următoarea eroare, ceea ce înseamnă că compilatorul are nevoie de mai multe informații de la noi pentru a ști ce tip dorim să folosim:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0282]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^
|
help: consider giving `guess` an explicit type
|
2 | let guess: _ = "42".parse().expect("Not a number!");
| +++
For more information about this error, try `rustc --explain E0282`.
error: could not compile `no_type_annotations` due to previous error
Vei vedea adnotări de tip diferite pentru alte tipuri de date.
Tipuri scalare
Un tip scalar reprezintă o singură valoare. Rust are patru tipuri scalare principale: numere întregi, numere în virgulă mobilă, Booleani și caractere. S-ar putea ca acestea să ți se pară familiare din alte limbaje de programare. Să trecem la modul în care funcționează tipurile scalabile în Rust.
Tipuri de întregi
Un întreg este un număr fără componentă fracționară. Am folosit un tip de întreg în Capitolul 2, tipul u32. Această declarație de tip indică faptul că valoarea cu care este asociată ar trebui să fie un întreg fără semn (tipurile de întregi cu semn încep cu i în loc de u) care ocupă 32 de biți de spațiu. Tabelul 3-1 arată tipurile de întregi integrate în Rust. Putem folosi fiecare dintre aceste variante pentru a declara tipul unei valori întregi.
Tabelul 3-1: Tipuri de întregi în Rust
| Lungime | Cu semn | Fără semn |
|---|---|---|
| 8-biți | i8 | u8 |
| 16-biți | i16 | u16 |
| 32-biți | i32 | u32 |
| 64-biți | i64 | u64 |
| 128-biți | i128 | u128 |
| arhitect. | isize | usize |
Fiecare variantă poate fi fie cu semn, fie fără semn, și are o dimensiune explicită. Cu semn și fără semn se referă la faptul dacă este posibil ca numărul să fie negativ - cu alte cuvinte, dacă numărul are nevoie să aibă un semn asociat (signed) sau dacă va fi mereu pozitiv și deci poate fi reprezentat fără un semn (unsigned). Este similar cu scrierea numerelor pe hârtie: când semnul contează, un număr este prezentat cu un semn plus sau un semn minus; totuși, când este sigur că numărul este pozitiv, acesta este prezentat fără semn. Numerele cu semn sunt stocate folosind reprezentarea de complement față de doi .
Fiecare variantă cu semn poate stoca numere de la -(2n - 1) la 2n - 1 - 1 inclusiv, unde n este numărul de biți pe care îl folosește acea variantă. Așadar un i8 poate stoca numere de la -(27) la 27 - 1, care este egal cu -128 până la 127. Variantele fără semn pot stoca numere de la 0 la 2n - 1, așadar un u8 poate stoca numere de la 0 la 28 - 1, care este egal cu 0 până la 255.
În plus, tipurile isize si usize depind de arhitectura computerului pe care rulează programul, care este notată în tabelul de mai sus ca „arhitectura sistemului”: 64 de biți dacă te afli pe o arhitectură de 64-biți și 32 de biți dacă te afli pe o arhitectură de 32-biți.
Poți scrie literali întregi în oricare dintre formele prezentate în Tabelul 3-2. Observă că literali numerici care pot fi de mai multe tipuri numerice permit un sufix de tip, cum ar fi 57u8, pentru a desemna tipul. Literalii numerici pot de asemenea folosi _ ca separator vizual pentru a face numărul mai ușor de citit, precum 1_000, care va avea aceeași valoare ca și cum ai fi specificat 1000.
Tabelul 3-2: Literali întregi în Rust
| Literali numerici | Exemplu |
|---|---|
| Zecimal | 98_222 |
| Hexadecimal | 0xff |
| Octal | 0o77 |
| Binar | 0b1111_0000 |
Byte (doar u8) | b'A' |
Deci, cum să știi ce tip de întreg să folosești? Dacă nu ești sigur, valorile setate inițial de Rust sunt în general un punct bun de plecare: tipurile întregi au implicit setat i32. Principala situație în care ai folosi isize sau usize este atunci când indexezi o colecție de elemente.
Depășirea întregilor
Să presupunem că ai o variabilă de tip
u8care poate stoca valori între 0 și 255. Dacă încerci să schimbi valoarea variabilei în afara acestui interval, cum ar fi 256, va apărea o depășire a întregilor (integer overflow), care poate produce unul dintre două comportamente. Atunci când compilezi în modul de depanare, Rust include verificări pentru depășirea întregilor care cauzează panica programului la runtime dacă acest comportament apare. Rust utilizează termenul de panică când un program se închide cu o eroare; vom discuta despre panici în profunzime în secțiunea „Erorile irecuperabile cupanic!” în Capitolul 9.Când compilezi în modul de release cu opțiunea
--release, Rust nu include verificări pentru depășirea întregilor care cauzează panici. În schimb, dacă apare o depășire, Rust efectuează împachetarea complementul lui doi. Pe scurt, valorile mai mari decât valoarea maximă pe care o poate deține tipul „este împachetat” la minimul valorilor pe care tipul le poate deţine. În cazul unuiu8, valoarea 256 devine 0, valoarea 257 devine 1 și așa mai departe. Programul nu va genera panică, dar variabila va avea o valoare care probabil nu este ceea ce te așteptai să aibă. Să te bazezi pe comportamentul de împachetare a întregilor depășiți este considerat greșit.Pentru a gestiona în mod explicit posibilitatea de depășire, poți folosi aceste familii de metode oferite de biblioteca standard pentru tipurile numerice primitive:
- Împachetează toate operațiunile cu metodele
wrapping_*, cum ar fiwrapping_add.- Întoarce valoarea
Nonedacă există depășire cu metodelechecked_*.- Întoarce valoarea și un boolean care indică dacă a existat depășire cu metodele
overflowing_*.- Saturează la valorile minime sau maxime ale valorii cu metodele
saturating_*.
Tipurile cu virgulă mobilă
Rust are, de asemenea, două tipuri primitive pentru numerele în virgulă mobilă, care sunt numerele cu puncte zecimale. Tipurile Rust cu virgulă mobilă sunt f32 și f64, care au 32 de biți și 64 de biți în dimensiune, respectiv. Tipul implicit este f64 deoarece pe procesoarele moderne este aproximativ la fel de rapid ca f32, dar este capabil de mai multă precizie. Toate tipurile cu virgulă mobilă sunt semnate.
Iată un exemplu care arată numerele cu virgulă mobilă în acțiune:
Numele fișierului: src/main.rs
fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 }
Numerele cu virgulă mobilă sunt reprezentate conform standardului IEEE-754. Tipul f32 este un număr cu precizie simplă, iar f64 are precizie dublă.
Operațiuni numerice
Rust suportă operațiunile matematice de bază pe care le-ai aștepta pentru toate tipurile de numere: adunare, scădere, înmulțire, împărțire și rest. Împărțirea întreagă trunchiază spre zero la cel mai apropiat număr întreg. Următorul cod arată cum ai folosi fiecare operațiune numerică într-o declarație let:
Numele fișierului: src/main.rs
fn main() { // addition let sum = 5 + 10; // subtraction let difference = 95.5 - 4.3; // multiplication let product = 4 * 30; // division let quotient = 56.7 / 32.2; let truncated = -5 / 3; // Results in -1 // remainder let remainder = 43 % 5; }
Fiecare expresie în aceste declarații folosește un operator matematic și evaluează la o singură valoare, care este apoi legată la o variabilă. Anexa B conține o listă cu toți operatorii pe care Rust îi pune la dispoziție.
Tipul Boolean
Ca în majoritatea celorlalte limbaje de programare, un tip Boolean în Rust are două posibile valori: true și false. Booleanii au dimensiunea de un octet. Tipul Boolean în Rust este specificat folosind bool. De exemplu:
Numele fișierului: src/main.rs
fn main() { let t = true; let f: bool = false; // with explicit type annotation }
Principalul mod de a folosi valorile Boolean este prin condiționale, cum ar fi o expresie if. Vom discuta cum funcționează expresiile if în Rust în secțiunea „Fluxul de control”.
Tipul caracter
Tipul char al lui Rust este cel mai primitiv tip alfabetic al limbajului. Aici avem câteva exemple de declarare a valorilor char:
Numele fișierului: src/main.rs
fn main() { let c = 'z'; let z: char = 'ℤ'; // with explicit type annotation let heart_eyed_cat = '😻'; }
Observați că specificăm constantele de tip char cu ghilimele simple, spre deosebire de sirurile de caractere, care utilizează ghilimele duble. Tipul char al lui Rust este de patru octeți și reprezintă o valoare scalară Unicode, ceea ce înseamnă că poate reprezenta mult mai mult decât doar ASCII. Litere accentuate; caractere chinezești, japoneze și coreene; emoji și spații de lățime zero sunt toate valori char valide în Rust. Valorile scalare Unicode variază de la U+0000 la U+D7FF și U+E000 la U+10FFFF inclusiv. Totuși, un „caracter” nu este chiar un concept în Unicode, așa că intuiția ta umană pentru ceea ce este un „caracter” s-ar putea să nu se potrivească cu ceea ce este un char în Rust. Vom discuta acest subiect în detaliu în „Stocarea textului codificat UTF-8 cu string-uri” în Capitolul 8.
Tipuri compuse
Tipurile compuse pot grupa mai multe valori într-un singur tip. Rust are două tipuri compuse primitive: tuple și array-uri.
Tipul tuplă
O tuplă este o modalitate generală de a grupa împreună un număr de valori cu o varietate de tipuri într-un singur tip compus. Tuplele au o lungime fixă: odată declarate, nu pot crește sau scădea în dimensiune.
Creăm o tuplă scriind o listă de valori separate prin virgulă între paranteze. Fiecare poziție din tuplă are un tip, și tipurile diferitelor valori din tuplă nu trebuie să fie aceleași. Am adăugat în acest exemplu opțional adnotări de tip:
Numele fișierului: src/main.rs
fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); }
Variabila tup se leagă de întreaga tuplă pentru că o tuplă este considerată un singur element compus. Pentru a obține valorile individuale dintr-o tuplă, putem folosi potrivirea de modele pentru a destrucura o valoare a tuplei, așa cum este arătat aici:
Numele fișierului: src/main.rs
fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; println!("The value of y is: {y}"); }
Acest program creează mai întâi o tuplă și o leagă la variabila tup. Apoi folosește un model cu let pentru a lua tup și a o transforma în trei variabile separate, x, y, și z. Acest lucru este numit destructurare pentru că descompune singura tuplă în trei părți. În final, programul afișează valoarea lui y, care este 6.4.
Putem accesa direct un element al tuplei folosind un punct (.) urmat de indexul valorii pe care dorim să o accesăm. De exemplu:
Numele fișierului: src/main.rs
fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let five_hundred = x.0; let six_point_four = x.1; let one = x.2; }
Acest program creează tupla x și apoi accesează fiecare element al tuplei folosind indicii lor respectivi. La fel ca în majoritatea limbajelor de programare, primul index într-o tuplă este 0.
Tupla fără nicio valoare are un nume special, unit. Această valoare și tipul său corespunzător sunt ambele scrise () și reprezintă o valoare goală sau un tip de returnare gol. Expresiile returnează implicit valoarea unit dacă nu returnează nicio altă valoare.
Tipul array
Un alt mod de a avea o colecție de valori multiple este cu un array. Spre deosebire de o tuplă, fiecare element al unui array trebuie să aibă același tip. Spre deosebire de array-urile din alte limbaje, array-urile din Rust au o lungime fixă.
Scriem valorile într-un array ca o listă separată prin virgule în interiorul parantezelor pătrate:
Numele fișierului: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; }
Array-urile sunt utile când vrem ca datele să fie alocate pe stivă, nu pe heap (vom discuta mai mult despre stivă și heap în Capitolul 4) sau când dorim să ne asigurăm că avem întotdeauna un număr fix de elemente. Un array nu este la fel de flexibil precum tipul vector, totuși. Un vector este un tip de colecție similar oferit de biblioteca standard dar care are voie să crească sau să scadă în dimensiune. Dacă nu ești sigur dacă să folosești un array sau un vector, atunci probabil că ar trebui să folosești un vector. Capitolul 8 discută vectorii în mai multe detalii.
Totuși, array-urile sunt mai utile când știi că numărul de elemente nu va avea nevoie să se schimbe. De exemplu, dacă ai folosi numele lunilor într-un program, ai folosi probabil un array în loc de un vector, deoarece știi că acesta va conține întotdeauna 12 elemente:
#![allow(unused)] fn main() { let months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]; }
Scrii tipul unui array folosind paranteze pătrate cu tipul fiecărui element, un punct și virgulă, și apoi numărul de elemente din array, așa:
#![allow(unused)] fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; }
Aici, i32 este tipul fiecărui element. După punctul și virgula, numărul 5 indică faptul că array-ul conține cinci elemente.
Poți de asemenea inițializa un array pentru a conține aceeași valoare pentru fiecare element, specificând valoarea inițială, urmată de un punct și virgulă, și apoi lungimea array-ului în paranteze pătrate, așa cum este afișat aici:
#![allow(unused)] fn main() { let a = [3; 5]; }
Array-ul numit a va conține 5 elemente care vor fi inițializate toate cu valoarea 3. Acest lucru este la fel ca scrierea let a = [3, 3, 3, 3, 3];, dar într-un mod mai concis.
Accesarea elementelor unui array
Un array este un singur segment de memorie de o dimensiune cunoscută, fixă, care poate fi alocat pe stiva. Poți accesa elementele unui array folosind indexarea, în acest fel:
Numele fișierului: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; let first = a[0]; let second = a[1]; }
În acest exemplu, variabila numită first va primi valoarea 1 pentru că aceasta
este valoarea la indexul [0] în array. Variabila numită second va primi
valoarea 2 de la indexul [1] în array.
Acces invalid la un element al unui array
Să vedem ce se întâmplă dacă începi să accesezi un element al unui array care este după sfârșitul array-ului. Să zicem că rulezi acest cod, asemănător cu jocul de ghicit din Capitolul 2, pentru a obține un index de array de la utilizator:
Numele fișierului: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}Cod se compilează cu succes. Dacă rulezi acest cod folosind cargo run și introduci 0, 1, 2, 3, sau 4, programul va afișa valoarea corespunzătoare acelui index în array. Dacă introduci un număr după sfârșitul array-ului, cum ar fi 10, vei vedea o ieșire de acest gen:
thread 'main' panicked at 'index out of bounds: the len is 5 but the index is 10', src/main.rs:19:19
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Programul a rezultat într-o eroare de runtime în momentul utilizării unei valori invalide în operația de indexare. Programul se închide cu un mesaj de eroare și nu execută instrucțiunea finală println!. Când încerci să accesezi un element folosind indexarea, Rust va verifica dacă indexul specificat de tine este mai mic decât lungimea array-ului. Dacă indexul este mai mare sau egal cu lungimea, Rust va stopa cu panică. Verificarea dată trebuie să se întâmple la runtime, în special în așa caz, pentru că compilatorul nu poate ști cu siguranță ce valoare va introduce un utilizator când va rula codul mai târziu.
Acesta este un exemplu al principiilor de siguranță ale memoriei din Rust în acțiune. În multe limbaje de nivel scăzut, verificare de acces în array nu se face, și, când furnizezi un index incorect, poate fi accesată memorie invalidă. Rust te protejează împotriva acestui fel de erori prin ieșirea imediată în loc de a permitere accesul la memorie și continuare. Capitolul 9 discută mai multe despre gestionarea erorilor în Rust și cum poți să scrii un cod lizibil și sigur, care nu face niciun fel de panică nici nu permite acces la memorie invalidă.
Funcții
Funcțiile sunt omniprezente în codul Rust. Ai văzut deja una dintre cele mai importante funcții din limbaj: funcția main, care este punctul de intrare în multe programe. Ai văzut deja și cuvântul cheie fn, care îți permite să declari funcții noi.
Codul Rust folosește snake case ca stil convențional pentru numele funcțiilor și variabilelor, în care toate literele sunt minuscule și cuvintele sunt separate de caracterele de underscore. Iată un program care conține o definiție exemplară a unei funcții:
Numele fișierului: src/main.rs
fn main() { println!("Hello, world!"); another_function(); } fn another_function() { println!("Another function."); }
Definim o funcție în Rust prin introducerea fn urmată de un nume de funcție și un set de paranteze. Parantezele acolade indică compilatorului unde începe și se termină corpul funcției.
Putem apela orice funcție pe care am definit-o introducând numele său urmat de un set de paranteze. Deoarece another_function este definită în program, ea poate fi apelată din interiorul funcției main. Observă că am definit another_function după funcția main în codul sursă; am fi putut să o definim și înainte. Rust nu îi pasă unde definim funcțiile noastre, doar că sunt definite într-un loc vizibil pentru codul apelant.
Să începem un nou proiect binar denumit functions pentru a continua explorarea funcțiilore. Pune exemplul another_function în src/main.rs și rulează-l. Ar trebui să vezi următoarea ieșire:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Another function.
Liniile se execută în ordinea în care apar în funcția main. Mai întâi mesajul „Salut, lume!” este tipărit, apoi another_function este apelată și mesajul său este tipărit.
Parametri
Funcțiile pot fi definite cu parametri, aceștia fiind variabile speciale care fac parte din semnătura unei funcții. Când o funcție are parametri ea poate fi apelată cu valori concrete pentru acești parametri. Tehnic, aceste valori concrete se numesc argumente, dar în conversațiile de zi cu zi, oamenii tind să folosească termenii parametru și argument în mod interschimbabil atât pentru fiecare variabilă în definiția unei funcții, cât și pentru valorile concrete transmise când o funcție este apelată.
În această versiune a lui another_function, noi adăugăm un parametru:
Numele fișierului: src/main.rs
fn main() { another_function(5); } fn another_function(x: i32) { println!("The value of x is: {x}"); }
Încearcă să rulezi acest program; ar trebui să primești următoarea ieșire:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
The value of x is: 5
Declarația another_function are un parametru numit x. Tipul lui x este specificat ca fiind i32. Când transmitem 5 la another_function, macro println! plasează 5 acolo unde perechea de acolade cu x era în șirul de caractere format.
În semnăturile funcțiilor, trebuie să declari tipul fiecărui parametru. Acest lucru este o decizie deliberată în designul Rust: cererea de adnotații de tip în definițiile funcțiilor înseamnă că compilatorul aproape niciodată nu are nevoie de ele în alte părți din cod pentru a afla ce tip ai vrut să spui. De asemenea, compilatorul este capabil să ofere mesaje de eroare mult mai utile dacă știe ce tipuri așteaptă funcția.
Când definești mai mulți parametri, separă declarațiile de parametri cu virgule, în acest fel:
Numele fișierului: src/main.rs
fn main() { print_labeled_measurement(5, 'h'); } fn print_labeled_measurement(value: i32, unit_label: char) { println!("The measurement is: {value}{unit_label}"); }
Acest exemplu creează o funcție numită print_labeled_measurement cu doi parametri. Primul parametru se numește value și este i32. Al doilea se numește unit_label și este de tip char. Funcția apoi afișează text care conține atât value cât și unit_label.
Să încercăm să rulăm acest cod: înlocuiește programul curent din fișierul src/main.rs al proiectului tău functions cu exemplul de mai sus și rulează-l folosind cargo run:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
The measurement is: 5h
Deoarece am apelat funcția cu 5 ca valoare pentru value și 'h' ca valoare pentru unit_label, ieșirea programului conține anume aceste valori.
Instrucțiuni și expresii
Corpurile funcțiilor sunt compuse dintr-o serie de instrucțiuni, care se pot încheia opțional cu o expresie. Până acum, funcțiile pe care le-am discutat nu au inclus o expresie finală, însă ai observat expresii utilizate ca parte a instrucțiunilor. Spre deosebire de multe alte limbaje de programare, Rust este un limbaj bazat pe expresii - o distincție importantă de înțeles. În continuare, să analizăm ce reprezintă instrucțiunile și expresiile și cum această diferențiere influențează structura corpurilor funcțiilor.
- Instrucțiunile sunt directive care realizează o anumită acțiune și nu returnează o valoare.
- Expresiile evaluează o valoare rezultantă. Să vedem câteva exemple.
De fapt, am folosit deja instrucțiuni și expresii. Crearea unei variabile și atribuirea unei valori cu un cuvânt cheie let este o instrucțiune. În listarea 3-1, let y = 6; este o instrucțiune.
Numele fișierului: src/main.rs
fn main() { let y = 6; }
Listarea 3-1: O declarație a funcției main conținând o instrucțiune
Definițiile de funcții sunt, de asemenea, instrucțiuni; întregul exemplu precedent este o instrucțiune în sine.
Instrucțiunile nu returnează valori. Prin urmare, nu poți atribui o instrucțiune let unei alte variabile, așa cum încearcă să facă următorul cod; vei obține o eroare:
Numele fișierului: src/main.rs
fn main() {
let x = (let y = 6);
}Când rulezi acest program, eroarea pe care o obții arată așa:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
error: expected expression, found statement (`let`)
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^^^^^^^
|
= note: variable declaration using `let` is a statement
error[E0658]: `let` expressions in this position are unstable
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^^^^^^^
|
= note: see issue #53667 <https://github.com/rust-lang/rust/issues/53667> for more information
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
For more information about this error, try `rustc --explain E0658`.
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` due to 3 previous errors; 1 warning emitted
Instrucțiunea let y = 6 nu returnează o valoare, deci nu există nimic de atribuit lui x. Acest lucru este diferit față de ceea ce se întâmplă în alte limbaje, cum ar fi C și Ruby, unde atribuirea returnează valoarea atribuirii. În acele limbaje, poți scrie x = y = 6 și atât x, cât și y vor avea valoarea 6; însă nu în cazul lui Rust.
Expresiile evaluează o valoare și alcătuiesc majoritatea celorlalte coduri pe care le vei scrie în Rust. Consideră o operație matematică, cum ar fi 5 + 6, care este o expresie care evaluează la valoarea 11. Expresiile pot face parte din instrucțiuni: în Listarea 3-1, 6 în instrucțiunea let y = 6; este o expresie care evaluează valoarea 6. Apelarea unei funcții este o expresie. Apelarea unui macro este o expresie. Și un nou bloc de cod creat cu acolade este o expresie, spre exemplu:
Numele fișierului: src/main.rs
fn main() { let y = { let x = 3; x + 1 }; println!("The value of y is: {y}"); }
Expresia:
{
let x = 3;
x + 1
}este un bloc care, în acest caz, evaluează la 4. În continuare această valoare este atribuită lui y ca parte a instrucțiunii let. Reține că linia x + 1 nu are un punct și virgulă la sfârșit, spre deosebire de cele mai multe linii pe care le-ai văzut până acum. Cauza e că expresiile nu includ semicoalone la sfârșit. Dacă adaugi un punct și virgulă la sfârșitul unei expresii, o transformi într-o instrucțiune, și ea nu va mai returna o valoare. Ține acest lucru în minte pe măsură ce vom explora în continuare valorile de retur a funcțiilor și expresiile.
Funcții cu valori de retur
Funcțiile pot întoarce valori codului care le apelează. Noi nu dăm un nume valorilor de retur, dar trebuie să le declarăm tipul după o săgeată (->). În Rust, valoarea de retur a funcției este sinonimă cu valoarea ultimei expresii din blocul corpului acelei funcții. Poți returna mai devreme dintr-o funcție folosind cuvântul cheie return și specificând o valoare, dar majoritatea funcțiilor returnează ultima expresie în mod implicit. Iată un exemplu de funcție care returnează o valoare:
Numele fișierului: src/main.rs
fn five() -> i32 { 5 } fn main() { let x = five(); println!("The value of x is: {x}"); }
Nu sunt apeluri de funcții, macrouri sau chiar declarații let în funcția five - doar numărul 5 în sine. Aceasta este o funcție perfect valabilă în Rust. Observă că tipul de retur al funcției este specificat și el, ca -> i32. Încearcă să rulezi acest cod; rezultatul ar trebui să arate așa:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
The value of x is: 5
Numărul 5 în five este valoarea de retur a funcției, motiv pentru care tipul de retur este i32. Să examinăm acest lucru mai detaliat. Sunt două aspecte importante: În primul rând, linia let x = five(); arată că folosim valoarea de retur a unei funcții pentru a inițializa o variabilă. Deoarece funcția five returnează un 5, această linie ar fi echivalentă cu următoarea:
#![allow(unused)] fn main() { let x = 5; }
În al doilea rând, funcția five nu are parametri și definește tipul valorii de retur, dar corpul funcției este un singur 5, fără punct și virgulă, pentru că este anume expresia a cărei valoare vrem să o returnăm.
Să vedem un alt exemplu:
Numele fișierului: src/main.rs
fn main() { let x = plus_one(5); println!("The value of x is: {x}"); } fn plus_one(x: i32) -> i32 { x + 1 }
Rularea acestui cod va afișa Valoarea lui x este: 6. Dar dacă punem un punct și virgulă la finalul liniei care conține x + 1, schimbând-o dintr-o expresie într-o declarație, vom obține o eroare:
Numele fișierului: src/main.rs
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1;
}Compilarea acestui cod produce o eroare, astfel:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_one(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` due to previous error
Mesajul principal de eroare, mismatched types, relevă problema de bază cu acest cod. Definiția funcției plus_one spune că va returna un i32, dar declarațiile nu evaluează la o valoare, ceea ce este exprimat prin (), tipul unit. Prin urmare, nu se returnează nimic, ceea ce contrazice definiția funcției și duce la o eroare. În această ieșire Rust chiar oferă un mesaj care ar putea ajuta la corectarea problemei: sugerează eliminarea punctului și virgulei, care într-adevăr ar remedia eroarea.
Comentarii
Toți programatorii se străduiesc să facă codul lor ușor de înțeles, dar uneori este necesară o explicație suplimentară. În aceste cazuri, programatorii lasă comentarii în codul lor sursă pe care compilatorul îl va ignora, dar persoanele care citesc codul sursă le-ar considera utile.
Acesta este un comentariu simplu:
#![allow(unused)] fn main() { // salutare, lume }
În Rust, stilul idiomatic de a scrie comentarii începe cu două liniuțe, și comentariul continuă până la sfârșitul liniei. Pentru comentarii care se extind mai mult decât o linie, va trebui să includeți // pe fiecare linie, așa:
#![allow(unused)] fn main() { // Deci facem ceva complex aici, suficient de lung încât avem nevoie // de mai multe linii de comentarii pentru a face asta! Uff! Sperăm că acest comentariu va // clarifica ce se întâmplă. }
Comentariile pot fi, de asemenea, plasate la sfârșitul liniilor care conțin cod:
Numele fișierului: src/main.rs
fn main() { let lucky_number = 7; // I’m feeling lucky today }
Dar le vei vedea mai des utilizate în acest format, cu comentariul pe o linie separată, deasupra codului pe care îl comentează:
Numele fișierului: src/main.rs
fn main() { // I’m feeling lucky today let lucky_number = 7; }
Rust dispune și de un alt tip de comentariu, comentariile de documentare, despre care vom discuta în secțiunea „Publicarea unui crate la crates.io” a Capitolului 14.
Controlul fluxului
Abilitatea de a rula unele coduri în funcție dacă o condiție este true și de a rula un cod în mod repetat dacă o condiție este true sunt blocuri de bază în majoritatea limbajelor de programare. Cele mai comune constructe care îți permit să controlezi fluxul de execuție al codului Rust sunt expresiile if și buclele.
Expresiile if
O expresie if îți permite să amifici codul în funcție de condiții. Tu furnizezi o condiție și apoi afirmi: „Dacă această condiție este îndeplinită, rulează acest bloc de cod. Dacă condiția nu este îndeplinită, nu rula acest bloc de cod”.
Creează un proiect nou numit branches în directoriul tău projects pentru a explora expresia if. În fișierul src/main.rs, introdu următoarea linie:
Numele fișierului: src/main.rs
fn main() { let number = 3; if number < 5 { println!("condition was true"); } else { println!("condition was false"); } }
Toate expresiile if încep cu cuvântul cheie if, urmate de o condiție. În acest caz, condiția verifică dacă variabila number are o valoare mai mică de 5. Plasăm blocul de cod care urmează să se execute dacă condiția este true imediat după condiție între parantezele acolade. Blocurile de cod asociate cu condițiile din expresiile if sunt uneori numite arms (ramuri), la fel ca ramurile din expresiile match despre care am discutat în [secțiunea „Compararea supoziției cu numărul secret”][comparison-the supposition-the secret-number] a capitolului 2.
Opțional, putem include și o expresie else, pe care am ales să o facem aici, pentru a oferi programului un bloc alternativ de cod care să se execute în cazul în care condiția evaluatează la false. Dacă nu oferi o expresie else și condiția este false, programul va omite blocul if și va trece la următoarea parte de cod.
Încearcă să rulezi acest cod; ar trebui să vezi următoarea ieșire:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was true
Să încercăm să schimbăm valoarea lui number într-o valoare care face ca condiția să fie false pentru a vedea ce se întâmplă:
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}Rulează din nou programul și uită-te la ieșire:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was false
Este de asemenea important de menționat că în acest cod condiția trebuie să fie un bool. Dacă condiția nu este un bool, vom obține o eroare. De exemplu, încearcă să rulezi următorul cod:
Numele fișierului: src/main.rs
fn main() {
let number = 3;
if number {
println!("number was three");
}
}De această dată, condiția if evaluează valoarea 3 și Rust aruncă o eroare:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if number {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` due to previous error
Eroarea indică faptul că Rust se aștepta la un bool, dar a primit un integer. Spre deosebire de limbajele precum Ruby și JavaScript, Rust nu va încerca să convertească automat tipurile non-Boolean într-un Boolean. Trebuie să fii explicit și să furnizezi întotdeauna if cu un Boolean ca și condiție. Dacă vrem ca blocul de cod if să ruleze doar atunci când un număr nu este egal cu 0, de exemplu, putem schimba expresia if astfel:
Numele fișierului: src/main.rs
fn main() { let number = 3; if number != 0 { println!("number was something other than zero"); } }
Rulând acest cod se va afișa numărul a fost altceva decât zero.
Tratarea mai multor condiții cu else if
Poți utiliza mai multe condiții prin combinarea if și else într-o expresie else if. De exemplu:
Numele fișierului: src/main.rs
fn main() { let number = 6; if number % 4 == 0 { println!("number is divisible by 4"); } else if number % 3 == 0 { println!("number is divisible by 3"); } else if number % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } }
Acest program are patru căi posibile pe care le poate urma. După ce îl rulezi, ar trebui să vezi următoarea ieșire:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
number is divisible by 3
Când acest program este executat, el verifică fiecare expresie if pe rând și execută primul bloc pentru care condiția se evaluează la true. Reține că, deși 6 este divizibil cu 2, nu vedem ieșirea numărul este divizibil cu 2, nici nu vedem textul numărul nu este divizibil cu 4, 3 sau 2 din blocul else. Asta pentru că Rust execută doar blocul pentru prima condiție true, iar odată ce o găsește, nu mai verifică restul.
Folosirea prea multor expresii else if poate încărca codul tău, așa că dacă ai mai mult de una, s-ar putea să vrei să refactorizezi codul. Capitolul 6 descrie o structură avansată de instrucțiuni condiționale în Rust numită match pentru aceste cazuri.
Folosirea if într-o instrucțiune let
Deoarece if este o expresie, o putem folosi în partea dreaptă a unei instrucțiuni let pentru a atribui rezultatul unei variabile, așa cum se vede în Listarea 3-2.
Numele fișierului: src/main.rs
fn main() { let condition = true; let number = if condition { 5 } else { 6 }; println!("The value of number is: {number}"); }
Listarea 3-2: Atribuirea rezultatului unei expresii if unei variabile
Variabila number va fi legată de o valoare în funcție de rezultatul expresiei if. Rulează acest cod pentru a vedea ce se întâmplă:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
The value of number is: 5
Amintește-ți că blocurile de cod se evaluează până la ultima expresie din ele, iar numerele în sine sunt, de asemenea, expresii. În acest caz, valoarea întregii expresii if depinde de ce bloc de cod se execută. Acest lucru înseamnă că valorile care au potențialul de a fi rezultate din fiecare ramură a if trebuie să fie același tip; în Listarea 3-2, rezultatele atât ale ramurii if, cât și ale celei else erau numere întregi i32. Dacă tipurile nu se potrivesc, așa cum este cazul în următorul exemplu, vom primi o eroare:
Numele fișierului: src/main.rs
fn main() {
let condition = true;
let number = if condition { 5 } else { "six" };
println!("The value of number is: {number}");
}La compilarea acestui cod primim o eroare deoarece ramurile if și else au tipuri de valori incompatibile, și Rust indică exact unde să găsim problema în textul programului:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let number = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` due to previous error
Expresia în blocul if se evaluează ca un număr întreg, iar expresia din blocul else se evaluează ca un string. Acest lucru nu funcționează deoarece variabilele trebuie să aibă un singur tip, iar Rust trebuie să știe în timpul compilării care este tipul variabilei number, decisiv. Cunoașterea tipului number îi permite compilatorului să verifice dacă tipul este valid oriunde folosim number. Rust nu ar putea face asta dacă tipul number ar fi fost determinat doar la runtime; compilatorul ar fi fost mai complex sau ar fi făcut mai puține garanții despre cod, dacă ar fi trebuit să țină cont de mai multe tipuri ipotetice pentru orice variabilă.
Repetarea cu bucle
Este adesea util să execuți un bloc de cod de mai multe ori. Pentru acest lucru, Rust oferă mai multe bucle, care vor rula prin codul din interiorul corpului buclei până la sfârșit și apoi vor începe imediat de la început. Pentru a experimenta cu buclele, să facem un nou proiect numit loops.
Rust are trei tipuri de bucle: loop, while și for. Să încercăm fiecare.
Repetarea codului cu loop
Cuvântul cheie loop indică Rust să execute un bloc de cod iar și iar pentru totdeauna sau până când îi spunem explicit să se oprească.
Ca exemplu, modifică fișierul src/main.rs din directoriul tău loops pentru a arăta în felul următor:
Numele fișierului: src/main.rs
fn main() {
loop {
println!("again!");
}
}Când rulăm acest program, vom vedea din nou! afișat iar și iar continuu până când oprim manual programul. Majoritatea terminalelor suportă comanda rapidă ctrl-c pentru a întrerupe un program care
este blocat într-o buclă continuă. Încearcă:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished dev [unoptimized + debuginfo] target(s) in 0.29s
Running `target/debug/loops`
again!
again!
again!
again!
^Cagain!
Simbolul ^C reprezintă locul în care ai apăsat ctrl-c. Este posibil să vezi sau nu cuvântul din nou! afișat după ^C, în funcție de unde era codul în buclă când a primit semnalul de întrerupere.
Rust oferă de asemenea un mod prin care poți ieși dintr-o buclă folosind cod. Poți plasa cuvântul cheie break în interiorul buclei pentru a indica programului când să se oprească execuția buclei. Amintește-ți că am făcut asta în jocul de ghicire din secțiunea “Oprirea după o ghicire corectă” din Capitolul 2 pentru a opri programul când utilizatorul a câștigat jocul prin ghicirea numărului corect.
Am folosit de asemenea continue în jocul de ghicire, care într-o buclă indică programul să sară peste orice cod rămas în această iterație a buclei și să treacă la următoarea iterație.
Returnarea valorilor din bucle
Una dintre utilizările unei instrucțiuni loop este de a reîncerca o operație despre care știi că ar putea eșua, cum ar fi verificarea dacă un thread și-a terminat treaba. Probabil că vei avea nevoie și de a trece rezultatul acelei operațiuni în afara buclei către restul codului tău. Pentru a face asta, poți adăuga valoarea pe care vrei să o returnezi după expresia break pe care o folosești pentru a opri bucla; acea valoare va fi returnată din bucla astfel încât să o poți utiliza, așa cum se arată aici:
fn main() { let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; println!("The result is {result}"); }
Înainte de buclă, noi declarăm o variabilă numită counter și o inițializăm la
0. Apoi declaram o variabilă numită result pentru a deține valoarea returnată din
buclă. La fiecare iterație a buclei, adăugăm 1 la variabila counter, și apoi verificăm dacă counter este egal cu 10. Când este, folosim cuvântul cheie break cu valoarea counter * 2. După buclă, folosim un punct și virgulă pentru a încheia declarația care alocă valoarea pentru result. În final, noi afișăm valoarea în result, care în acest caz este 20.
Etichete de buclă pentru deosebirea între bucle multiple
Dacă ai bucle în interioarele altei bucle, break și continue se aplică buclei interne din acel punct. Poți specifica opțional o etichetă de buclă pe o buclă pe care o poți folosi apoi cu break sau continue pentru a specifica că acele cuvinte cheie se aplică buclei etichetate în locul celei mai interne bucle. Etichetele de buclă trebuie să înceapă cu un singur apostrof. Iată un exemplu cu două bucle îmbricate:
fn main() { let mut count = 0; 'counting_up: loop { println!("count = {count}"); let mut remaining = 10; loop { println!("remaining = {remaining}"); if remaining == 9 { break; } if count == 2 { break 'counting_up; } remaining -= 1; } count += 1; } println!("End count = {count}"); }
Bucla externă are eticheta 'counting_up, și va număra în sus de la 0 la 2. Bucla internă fără o etichetă numără în jos de la 10 la 9. Primul break care nu specifică o etichetă va ieși doar din bucla internă. Declarația break 'counting_up; va ieși din bucla externă. Acest cod afișează:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished dev [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
count = 0
remaining = 10
remaining = 9
count = 1
remaining = 10
remaining = 9
count = 2
remaining = 10
End count = 2
Buclele condiționale cu while
Un program va avea frecvent nevoie să verifice o condiție în timpul unei bucle. Cât timp condiția rămâne true, bucla se execută. Când condiția nu mai este true, programul apelează break, ceea ce oprește bucla. Comportamentul acesta poate fi realizat printr-o combinație de loop, if, else și break; poți să încerci chiar acum acest lucru într-un program, dacă vrei. Cu toate acestea, acest pattern este atât de frecvent încât Rust include o construcție specială pentru acesta, numită buclă while. În Listarea 3-3, utilizăm while pentru a rula bucla de trei ori, numărând în jos de fiecare dată, și după aceea, în afara buclei, afișăm un mesaj și ieșim din program.
Numele fișierului: src/main.rs
fn main() { let mut number = 3; while number != 0 { println!("{number}!"); number -= 1; } println!("LIFTOFF!!!"); }
Listarea 3-3: Utilizarea unei bucle while pentru a rula cod atât timp cât o condiție este adevărată
Această construcție reduce semnificativ imbricările care ar fi fost necesare dacă s-ar folosi loop, if, else și break, oferind în același timp o mai mare claritate. Atâta timp cât o condiție este evaluată ca fiind true, codul rulează; în caz contrar, acesta iese din buclă.
Parcurgerea unei colecții cu for
Ai opțiunea de a folosi structura while pentru a parcurge elementele unei colecții, cum ar fi un array. De exemplu, bucla din listarea 3-4 afișează fiecare element din array-ul a.
Numele fișierului: src/main.rs
fn main() { let a = [10, 20, 30, 40, 50]; let mut index = 0; while index < 5 { println!("the value is: {}", a[index]); index += 1; } }
Listarea 3-4: Parcurgerea fiecărui element al unei colecții
folosind o buclă while
Aici, codul numără elementele din array. Începe de la indexul 0, și apoi rulează până atinge indexul final din array (adică, când expresia index < 5 nu mai este true). Rularea acestui cod va afișa fiecare element din array:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished dev [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
the value is: 10
the value is: 20
the value is: 30
the value is: 40
the value is: 50
Toate cele cinci valori ale array-ului apar în terminal, după cum și ne așteptam. Deși index va atinge la un moment dat valoarea 5, bucla se oprește înainte de a încerca să extragă o a șasea valoare din array.
Cu toate acestea, această abordare este predispusă la erori; am putea provoca panică programului dacă valoarea indexului sau condiția de test este incorectă. De exemplu, dacă ai modificat definiția array-ului a pentru a avea patru elemente, dar ai uitat să actualizezi condiția la while index < 4, codul s-ar opri cu panică. De asemenea rularea este lentă, deoarece compilatorul adaugă cod de execuție pentru a efectua verificarea condițională a indexului în granițele array-ului la fiecare parcurgere a buclei.
O alternativă mai concisă ar fi o buclă for cu executarea unui cod pentru fiecare element din colecție. O buclă for arată ca în codul din listarea 3-5.
Numele fișierului: src/main.rs
fn main() { let a = [10, 20, 30, 40, 50]; for element in a { println!("the value is: {element}"); } }
Listarea 3-5: Parcurgerea fiecărui element al unei colecții
folosind o buclă for
Dacă vom rula acest cod vom vedea aceeași ieșire ca în listarea 3-4. Mai important, noi am îmbunătățit acum securitatea codului și am eliminat riscul de bug-uri care ar putea rezulta din depășirea sfârșitului array-ului sau din ne-parcurgerea integrală și omisiunea unor elemente.
Folosind bucla for, nu mai e nevoie să îți amintești să modifici orice alt cod dacă schimbi numărul de valori din array, cum ar fi cazul cu metoda folosită în listarea 3-4.
Siguranța și conciziunea buclelor for le fac cel mai des folosit concept de bucle în Rust. Chiar și în situații în care se dorește de rulat un anumit cod de un număr de ori, cum ar fi exemplul cu numărătoarea inversă care a folosit o buclă while în listarea 3-3, majoritatea programatorilor Rust ar folosi o buclă for utilizând un Range furnizat de biblioteca standard, care generează toate numerele în ordine începând de la un număr și terminând înainte de un alt număr.
Iată cum ar arăta numărătoarea inversă folosind o buclă for și o altă metodă despre care încă nu am vorbit, rev, pentru a inversa șirul:
Numele fișierului: src/main.rs
fn main() { for number in (1..4).rev() { println!("{number}!"); } println!("LIFTOFF!!!"); }
Acest cod pare mai elegant, nu-i așa?
Sumar
Ai reușit! Acesta a fost un capitol considerabil: ai învățat despre variabile, tipuri de date scalare și compuse, funcții, comentarii, expresii if și bucle! Pentru a te antrena cu conceptele discutate în acest capitol, încearcă să scrii programe care să facă următoarele lucruri:
- Convertarea temperaturilor între Fahrenheit și Celsius.
- Generearea unui al n-lea număr Fibonacci.
- Imprimarea versurile „Un elefant se legăna”, profitând de repetiția din cântec.
Când ești gata să continui, vom discuta despre un concept din Rust care nu există în mod obișnuit în alte limbaje de programare: posesiunea.
Înțelegerea posesiunii
Posesiunea este cea mai distinctă trăsătură a Rust și are implicații profunde pentru restul limbajului. Aceasta permite Rust să facă garanții de siguranță a memoriei fără a necesita un colector de gunoi (garbage collector, GC), deci este important să înțelegi cum funcționează posesiunea. În acest capitol, vom discuta despre posesiune, dar și despre câteva caractereistici conexe: împrumutarea, secționarea și cum Rust structurează datele în memorie.
Ce este posesiunea?
Posesiunea reprezintă un set de reguli care guvernează modul în care un program Rust gestionează memoria. Toate programele trebuie să gestioneze modul în care utilizează memoria unui calculator în timp ce rulează. Unele limbaje de programare dispun de colectare a gunoiului (garbage collector), care caută în mod regulat memoria care nu mai este utilizată pe măsură ce programul rulează; în alte limbaje de programare, programatorul trebuie să aloce și să elibereze explicit memoria. Rust folosește o a treia abordare: memoria este gestionată prin intermediul unui sistem de posesiune cu un set de reguli pe care compilatorul le verifică. Dacă oricare dintre reguli sunt încălcate, programul nu va fi compilat. Totuși nici o caracteristică a posesiunii nu va încetini viteza de rulare a programului.
Deoarece posesiunea este un concept nou pentru mulți programatori, este nevoie de ceva timp pentru a te obișnui cu acesta. Vestea bună este că cu cât devii mai experimentat cu Rust și cu regulile sistemului de posesiune, cu atât îți va fi mai ușor să dezvolți în mod natural cod care este sigur și eficient. Continuă să o faci!
Odată ce vei înțelege posesiunea, vei avea o bază solidă pentru înțelegerea caracteristicilor ce fac din Rust un limbaj unic. În acest capitol vei învăța despre posesiune prin câteva exemple care se concentrează asupra unei structuri de date foarte comune: string-urile.
Stiva și heap-ul
Multe limbaje de programare nu cer să te gândești prea mult la stivă și heap. Dar într-un limbaj de programare pentru sisteme ca Rust, în dependență dacă o valoare se află pe stivă sau heap afectează modul în care limbajul se comportă și necesită să iei anumite decizii. Părți din noțiunea de posesiune în raport cu stiva și heap-ul vor fi descrise mai târziu în acest capitol, așa că iată o scurtă explicație anticipată.
Atât stiva cât și heap-ul sunt părți ale memoriei disponibile codului tău pentru a fi folosite la runtime, dar care sunt structurate în moduri diferite. Stiva stochează valorile în ordinea în care le primește și elimină valorile în ordinea inversă. Acest lucru este menționat ca ultimul intrat, primul ieșit. Gândește-te la o stivă de farfurii: când adaugi mai multe farfurii, le pui în vârful grămezii, și când ai nevoie de o farfurie, o iei de pe vârful grămezii. Adăugarea sau eliminarea de farfurii de la mijloc sau de jos nu ar funcționa la fel de bine! Adăugarea de date se numește împingerea pe stivă și eliminarea de date se numește scoaterea de pe stivă. Toate datele stocate pe stivă trebuie să aibă o dimensiune cunoscută și fixă. Datele cu o dimensiune necunoscută în momentul compilării sau o dimensiune care s-ar putea schimba trebuie să fie stocate pe heap.
Heap-ul este mai puțin organizat: când pui date pe heap, ceri o anumită cantitate de spațiu. Alocatorul de memorie găsește un loc liber în heap care este suficient de mare, îl marchează ca fiind în uz și returnează un pointer, care este adresa acelui loc. Acest proces se numește alocare pe heap și este uneori abreviat drept doar alocare (împingerea valorilor pe stivă nu este considerată alocare). Deoarece pointer-ul către heap are o dimensiune cunoscută, fixă, poți stoca pointer-ul pe stivă, dar când vrei datele efective, trebuie să urmezi pointer-ul. Gândește-te că te-ai așezat la un restaurant. Când intri, precizezi numărul de persoane din grupul tău, iar gazda găsește o masă liberă care se potrivește tuturor și te conduce acolo. Dacă cineva din grupul tău vine târziu, poate întreba unde ai fost așezat să te găsească.
Împingerea pe stivă este mai rapidă decât alocarea pe heap deoarece alocatorul nu trebuie să caute niciodată un loc unde să stocheze date noi; acel loc este întotdeauna în partea de sus a stivei. Comparativ, alocarea spațiului pe heap necesită mai multă muncă deoarece alocatorul trebuie mai întâi să găsească un spațiu suficient de mare pentru a susține datele și apoi să efectueze o evidență a datelor acum alocate pentru a se pregăti pentru următoarea alocare.
Accesarea datelor în heap este mai lentă decât accesarea datelor pe stivă deoarece trebuie să urmezi un pointer pentru a ajunge acolo. Procesoarele contemporane sunt mai rapide dacă sar mai puțin prin memorie. Continuând analogia, ia în considerare un chelner la un restaurant care ia comenzi de la mai multe mese. Este mai eficient să obții toate comenzile de la o masă înainte de a trece la următoarea. Luând o comandă de la masa A, apoi o comandă de la masa B, apoi una de la A din nou, și apoi din nou una din B ar fi un proces mult mai lent. Din același motiv, un procesor își poate face treaba mai bine dacă lucrează pe date care sunt apropiate una de alta (așa cum este pe stivă) și mai lent când sunt răzlețite (așa cum poate fi pe heap).
Când codul tău apelează o funcție, valorile transmise în funcție (inclusiv, potențial, pointeri către date pe heap) și variabilele locale ale funcției sunt introduse pe stivă. Când funcția se încheie, aceste valori sunt eliminate de pe stivă.
Urmărirea care părți ale codului folosesc ce date pe heap, minimizarea cantității de date duplicate pe heap și eliberarea datelor neutilizate de pe heap astfel încât să nu rămâi fără spațiu sunt toate probleme pe care posesiunea le abordează. Odată ce înțelegi posesiunea, nu va trebui să te gândești prea des la stivă și la heap, dar știind că scopul principal al posesiunii este de a gestiona datele de pe heap poate ajuta la explicarea modului în care aceasta funcționează.
Regulile posesiunii
În primul rând, să aruncăm o privire asupra regulilor posesiunii. Ține minte aceste reguli în timp ce lucrăm la exemplele care le ilustrează:
- Fiecare valoare în Rust are un posesor.
- Poate exista doar un singur posesor la un moment dat.
- Când posesorul iese din domeniul de vizibilitate (eng. out of scope), valoarea va fi eliminată.
Domeniu de vizibilitate a variabilelor
Acum că am trecut de baza sintaxei Rust, nu vom include în toate exemplele codul fn main() {, astfel că în continuare asigură-te că introduci manual exemplele ce vor urma într-o funcție main. Ca rezultat exemplele noastre vor fi ceva mai concise, permițându-ne să ne concentrăm pe detaliile esențiale, fără prea mult cod de umplutură.
Ca prim exemplu de posesiune vom analiza domeniul de vizibilitate al unor variabile. Un domeniu de vizibilitate este intervalul în cadrul unui program în care un element este valid. Să luăm în considerare următoarea variabilă:
#![allow(unused)] fn main() { let s = "hello"; }
Variabila s se referă la un string literal, unde valoarea string-ului este inclusă direct în textul programului nostru. Variabila este validă de la punctul în care este declarată până la sfârșitul domeniului de vizibilitate curent. Listarea 4-1 arată un program cu comentarii care anunță unde ar fi validă variabila s.
fn main() { { // s is not valid here, it’s not yet declared let s = "hello"; // s is valid from this point forward // do stuff with s } // this scope is now over, and s is no longer valid }
Listarea 4-1: O variabilă și domeniul de vizibilitate în care este validă
Cu alte cuvinte, există două momente importante aici:
- Când
sintră în domeniul de vizibilitate, este validă. - Rămâne validă până când iese din domeniul de vizibilitate.
La acest moment, relația dintre domeniile de vizibilitate și momentele în care variabilele sunt valide este similară cu cea din alte limbaje de programare. Acum să continuăm studierea relațiilor de posesiune în Rust cu introducerea tipului String.
Tipul String
Pentru a ilustra regulile de posesiune, avem nevoie de un tip de date mai complex decât cele pe care le-am descris în secțiunea „Tipuri de date” a Capitolului 3. Tipurile menționate anterior sunt de dimensiune cunoscută, deci pot fi stocate în stivă și eliminate din stivă când domeniul lor de vizibilitate se termină, și pot fi copiate rapid și trivial pentru a crea o nouă instanță independentă în cazul în care o altă parte a codului are nevoie să folosească aceeași valoare, dar într-un alt domeniu de vizibilitate. Însă noi vrem să accesăm datele care sunt stocate în heap și să explorăm cum anume Rust știe când să elibereze acele date, iar tipul String este un exemplu excelent.
Acum ne vom concentra doar asupra aspectelor tipului String care sunt relevante posesiunii. Aceste aspecte se aplică și altor tipuri de date complexe, fie că sunt furnizate de biblioteca standard sau create de tine. Mai pe larg vom discuta despre String în Capitolul 8.
Am văzut deja literali ai tipului string, în care o valoare string este codificată direct în programul nostru. Literalii de string sunt convenabili, dar nu sunt potriviți pentru toate situațiile în care am dori să folosim text. Un motiv este că sunt imutabili. Altul este că nu fiecare valoare de string poate fi cunoscută din timp când scriem codul: de exemplu, ce se întâmplă dacă dorim să preluăm inputul de la utilizator și să îl stocăm? Pentru aceste situații Rust are un al doilea tip de string, String. Acest tip administrează date alocate în heap și astfel este capabil să stocheze un text care nu ne este cunoscut la momentul compilării. Poți crea un String dintr-un literal de string folosind funcția from, astfel:
#![allow(unused)] fn main() { let s = String::from("hello"); }
Operatorul cu dublu două puncte :: ne permite să definim această funcție from în spațiul de nume al tipului String în loc să o numim cumva cum ar fi string_from. Vom discuta mai mult această sintaxă în secțiunea „Sintaxa metodei” din Capitolul 5, și când vorbim despre spațiul de nume cu module în „Căi pentru referirea la un element în arborele modulelor” din Capitolul 7.
Acest tip de string poate fi mutat:
fn main() { let mut s = String::from("hello"); s.push_str(", world!"); // push_str() appends a literal to a String println!("{}", s); // This will print `hello, world!` }
Deci, care este diferența aici? De ce poate fi String mutat, dar literalii nu? Diferența o constituie felul în care aceste două tipuri sunt reprezentate în memorie.
Memorie și alocare
În cazul unui literal de string, cunoaștem conținutul în timpul compilării, astfel încât textul este codificat direct în executabilul final. Din acest motiv, literalele de string sunt rapide și eficiente. Dar aceste proprietăți provin doar din imutabilitatea literalului de string. Din păcate, nu putem pune un bloc de memorie în binar pentru fiecare fragment de text a cărui dimensiune este necunoscută în timpul compilării și a cărui mărime s-ar putea schimba în timpul rulării programului.
Cu tipul String, pentru a menține o bucată de text mutabilă, în creștere, trebuie să alocăm o cantitate de memorie pe heap, necunoscută în timpul compilării, pentru a deține conținutul. Aceasta înseamnă:
- Memoria trebuie solicitată de la alocatorul de memorie la runtime.
- Avem nevoie de o modalitate de a returna această memorie la alocator atunci când am terminat cu
String-ulnostru.
Prima parte este realizată de noi: când apelăm String::from, implementarea sa solicită memoria de care are nevoie. Aceasta parte este comună pentru mai toate limbajele de programare.
Cu toate acestea, a doua parte este diferită. În limbajele cu un colector de gunoi (garbage collector (GC)), GC ține evidența și eliberează memoria care nu mai este folosită, programatorul nu mai având necesitatea de a se gândi la asta. Pe când în majoritatea limbajelor fără un GC e responsabilitatea noastră să identificăm când memoria nu mai este folosită și să apelăm codul pentru a o elibera explicit, la fel cum am solicitat-o. A face acest lucru corect este, de obicei, o problemă dificilă de programare. Dacă uităm, vom irosi memorie. Dacă o facem prea devreme, vom avea o variabilă nevalidă. Dacă o facem de două ori tot este o problemă. Trebuie să menținem perechi de exact o alocare cu exact o dealocare.
Rust alege o cale diferită: memoria este returnată automat odată ce variabila care o deține iese din domeniu de vizibilitate. Iată o versiune a exemplului nostru despre domeniu de vizibilitate de la Listarea 4-1 folosind un String în loc de un literal de string:
fn main() { { let s = String::from("hello"); // s is valid from this point forward // do stuff with s } // this scope is now over, and s is no // longer valid }
Există un punct natural la care putem returna memoria ocupată de String-ul nostru la alocator: atunci când s iese din domeniu de vizibilitate. Când o variabilă iese din domeniu de vizibilitate, Rust apelează o funcție specială. Această funcție se numește drop, și este chiar locul unde autorul String-ului poate pune codul de returnare a memoriei. Rust apelează drop automat la închiderea acoladei.
Notă: În C++, acest model de dealocare a resurselor la sfârșitul duratei de viață a unui element se numește uneori Resource Acquisition Is Initialization (RAII). Funcția
dropdin Rust îți va fi familiară dacă ai folosit modele RAII.
Felul acesta de operare a memoriei are un impact profund asupra modului în care este scris codul Rust. Poate părea simplu acum, dar comportamentul codului poate fi destul de neașteptat în situații mai complicate, atunci când avem mai multe variabile care utilizează datele pe care le-am alocat pe heap. Să explorăm acum unele așa situații.
Variabile și interacționarea cu date folosind permutarea
Variabilele pot interacționa cu aceleași date în diferite moduri în Rust. Să privim la un exemplu utilizând un întreg în Lista 4-2.
fn main() { let x = 5; let y = x; }
Lista 4-2: Atribuirea valorii întregului de la variabila x
la y
Probabil putem ghici ce face acest cod: „atribuie valoarea 5 lui x; apoi face
o copie a valorii din x și o atribuie lui y.” Acum avem două variabile, x
și y, și ambele sunt egale cu 5. Așa și este, deoarece întregii în Rust sunt valori simple cu o mărime cunoscută, fixă, și aceste două valori 5 sunt împinse pe stivă.
Acum să ne uităm la versiunea cu un String:
fn main() { let s1 = String::from("hello"); let s2 = s1; }
Aceasta arată foarte asemănător, printr urmare s-ar putea presupune că modul în care funcționează ar fi la fel: adică, a doua linie ar face o copie a valorii din s1 și o atribuie lui s2. Doar că de data aceasta nu e chiar așa.
Priviți la Figura 4-1 pentru a vedea ce se întâmplă cu String în fundal. Un String este format din trei părți, arătate în stânga: un pointer spre memoria care deține conținutul string-ului, o lungime și o capacitate. Acest grup de date este stocat pe stivă. Pe dreapta e reprezentată memoria de pe heap care deține conținutul.

Figura 4-1: Reprezentare în memorie a unui String
care deține valoarea "hello" și este atribuită lui s1
Lungimea reprezintă câtă memorie, în octeți, folosește în prezent conținutul String-ului. Capacitatea este cantitatea totală de memorie, în octeți, pe care String-ul a primit-o de la alocator. Diferența între lungime și capacitate contează, dar nu în acest context, deci, pentru moment ignorăm capacitatea.
Când atribuim s1 la s2, datele din String sunt copiate, însemnând că noi copiem pointer-ul, lungimea și capacitatea care sunt pe stivă. Noi nu copiem
datele de pe heap pe care pointer-ul le referă. Cu alte cuvinte, reprezentarea datelor în memorie arată ca Figura 4-2.

Figura 4-2: Reprezentare în memorie a variabilei s2
care are o copie a pointer-ului, lungimii și capacității lui s1
Reprezentarea nu e ca în figura 4-3, ea prezintă cum ar fi arătat memoria dacă Rust copia și datele din heap. Dacă Rust ar face acest lucru, operațiunea s2 = s1 ar deveni foarte costisitoare în termeni de performanță la execuție, mai ales când datele de pe heap sunt mari.

Figura 4-3: O altă posibilitate pentru ce ar putea face s2 = s1
dacă Rust ar copia de asemenea datele de pe heap
Mai devreme, am spus că atunci când o variabilă iese din domeniul de vizibilitate, Rust apelează automat funcția drop și curăță memoria heap pentru acea variabilă. Dar Figura 4-2 arată ambele pointer-e de date adresând aceeași locație. Ar fi o problemă: când s2 și s1 ies din domeniul de vizibilitate, vor încerca amândouă să elibereze aceeași memorie. Acest lucru este cunoscut ca eroarea de eliberare dublă (double free) și este una dintre erorile de securitate a memoriei pe care le-am menționat anterior. Eliberarea memoriei de două ori poate duce la coruperea memoriei, ceea ce potențial poate provoca vulnerabilități de securitate.
Pentru a asigura securitatea memoriei, după linia let s2 = s1;, Rust consideră că s1 nu mai este valid. Prin urmare, Rust nu trebuie să elibereze nimic atunci când s1 iese din domeniul de vizibilitate. Să vedem ce se întâmplă când încercăm să folosim s1 după ce s2 este creat; nu va funcționa:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
}Vom primi o eroare similară, deoarece Rust ne împiedică să utilizăm referința invalidată:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:28
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}, world!", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` due to previous error
Dacă ai auzit termenii copiere superficială (shallow copy) și copiere profundă (deep copy) în timp ce lucrezi cu alte limbaje, conceptul de copiere a pointerului, lungimii și capacității fără a copia datele probabil sună ca făcând o copiere superficială. Dar deoarece Rust de asemenea invalidează prima variabilă, în loc să fie numită o copiere superficială, este cunoscută ca o permutare. În acest exemplu, am spune că s1 a fost permutată în s2. Deci, ceea ce se întâmplă de fapt este ilustrat în Figura 4-4.

Figura 4-4: Reprezentarea în memorie după ce s1 a fost
invalidat
Aceasta rezolvă problema noastră! Cu doar s2 validă, atunci când iese din domeniul de vizibilitate variabila va elibera singură memoria.
În plus, rezultă un fapt important pentru design-ul limbajului: Rust nu va crea niciodată automat o „copiere profundă” a datelor noastre. Prin urmare, orice copiere automată poate fi presupusă a fi ieftină în ceea ce privește performanța la runtime.
Variabile și interacționarea cu date folosind clonarea
Dacă vrem să copiem în profunzime datele unui String din heap, nu doar datele din stivă, putem folosi o metodă des întâlnită, numită clone. Vom discuta sintaxa metodelor în Capitolul 5, însă deoarece metodele sunt o caracteristică comună în multe limbaje de programare, probabil le-ai întâlnit deja.
Iată un exemplu al utilizării metodei clone:
fn main() { let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {}, s2 = {}", s1, s2); }
Acest lucru funcționează foarte bine și produce în mod explicit comportamentul prezentat în Figura 4-3, unde datele din heap sunt copiate.
Când vezi un apel către clone, știi că se execută un anumit cod arbitrar și că acest cod poate fi costisitor. Este un indicator vizual că se întâmplă ceva diferit.
Date doar pe stivă: trăsătura Copy
Există o altă nuanță despre care nu am discutat încă. Acest cod care folosește numere întregi, o parte din el a fost arătată în Listarea 4-2, funcționează și este valid:
fn main() { let x = 5; let y = x; println!("x = {}, y = {}", x, y); }
Dar acest cod pare să contrazică ceea ce tocmai am învățat: nu avem un apel la clone, dar x este încă valid și nu a fost permutat în y.
Motivul este că unele tipuri, cum ar fi numerele întregi care au o dimensiune cunoscută la compilare, sunt stocate în întregime pe stivă, astfel încât copierea valorilor lor este foarte rapidă. Astfel nu avem niciun motiv să vrem să prevenim x de a fi valid după ce am creat variabila y. Cu alte cuvinte, nu există nicio diferență între copierea profundă și cea superficială aici, deci apelarea la clone nu ar face nimic diferit de copierea superficială obișnuită, așa că o putem lăsa pentru alte cazuri.
Rust are o adnotare specială numită trăsătura Copy pe care o putem aplica la tipuri care sunt stocate pe stivă, la fel ca numerele întregi (vom vorbi mai multe despre trăsături în Capitolul 10). Dacă un tip implementează trăsătura Copy, variabilele care îl utilizează nu se permută, ci sunt copiate superficial, lucru care le păstrează valide după atribuirea lor altei variabile.
Rust nu ne va lăsa să adnotăm un tip cu Copy dacă tipul, sau oricare dintre părțile sale, a implementat trăsătura Drop. Dacă tipul are nevoie de ceva special să se întâmple când valoarea iese din domeniul de vizibilitate și adăugăm adnotarea Copy la acel tip, vom primi o eroare la compilare. Pentru a afla cum să adăugați adnotarea Copy la tipul tău pentru a implementa trăsătura, vedeți “Trăsături derivate” în Anexa C.
Deci, ce tipuri implementează trăsătura Copy? Puteți verifica documentația pentru
tipul dat pentru a fi sigur, dar ca o regulă generală, orice grup de valori scalare simple
poate implementa Copy, și nimic care necesită alocare sau este o formă de resursă nu poate implementa Copy. Iată câteva tipuri care
implementează Copy:
- Toate tipurile de numere întregi, cum ar fi
u32. - Tipul Boolean,
bool, cu valoriletrueșifalse. - Toate tipurile de numere în virgulă mobilă, cum ar fi
f64. - Tipul de caractere,
char. - Tuple, dacă acestea conțin numai tipuri care de asemenea implementează
Copy. De exemplu,(i32, i32)implementeazăCopy, dar(i32, String)nu.
Funcțiile și posesiunea
Transmiterea unei valori către o funcție e similară cu atribuirea acelei valori unei variabile. A transmite o variabilă către o funcție implică fie permutarea, fie copierea acelei valori, exact așa cum se întâmplă și la atribuire. În Lista 4-3, am pregătit un exemplu cu adnotări pentru a ilustra când intră și ies variabilele din domeniul de vizibilitate.
Numele fișierului: src/main.rs
fn main() { let s = String::from("hello"); // s comes into scope takes_ownership(s); // s's value moves into the function... // ... and so is no longer valid here let x = 5; // x comes into scope makes_copy(x); // x would move into the function, // but i32 is Copy, so it's okay to still // use x afterward } // Here, x goes out of scope, then s. But because s's value was moved, nothing // special happens. fn takes_ownership(some_string: String) { // some_string comes into scope println!("{}", some_string); } // Here, some_string goes out of scope and `drop` is called. The backing // memory is freed. fn makes_copy(some_integer: i32) { // some_integer comes into scope println!("{}", some_integer); } // Here, some_integer goes out of scope. Nothing special happens.
Listarea 4-3: Funcții cu posesiunea și domeniul de vizibilitate adnotat
Dacă am încercat să utilizăm s după apelul la takes_ownership, Rust ar genera o eroare la compilare. Aceste verificări statice ne protejează de greșeli. Încearcă să adaugi cod la main care folosește s și x pentru a vedea unde le poți folosi și unde regulile de posesiune te împiedică să faci asta.
Valorile returnate și domeniul de vizibilitate
Returul valorilor poate transmite, de asemenea, posesiunea. Listarea 4-4 ilustrează un exemplu de funcție care returnează o valoare, folosind adnotări similare cu cele din Listarea 4-3.
Numele fișierului: src/main.rs
fn main() { let s1 = gives_ownership(); // gives_ownership moves its return // value into s1 let s2 = String::from("hello"); // s2 comes into scope let s3 = takes_and_gives_back(s2); // s2 is moved into // takes_and_gives_back, which also // moves its return value into s3 } // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing // happens. s1 goes out of scope and is dropped. fn gives_ownership() -> String { // gives_ownership will move its // return value into the function // that calls it let some_string = String::from("yours"); // some_string comes into scope some_string // some_string is returned and // moves out to the calling // function } // This function takes a String and returns one fn takes_and_gives_back(a_string: String) -> String { // a_string comes into // scope a_string // a_string is returned and moves out to the calling function }
Listarea 4-4: Transferul posesiunii prin valorile returnate
Posesiunea unei variabile urmează același model de fiecare dată: atribuirea unei valori unei alte variabile determină permutarea acesteia. Când variabila, care include date pe heap, iese din domeniul de vizibilitate, valoarea este eliberată prin funcția drop, cu excepția situației în care posesiunea datelor a fost permutată către o altă variabilă.
Această abordare este funcțională, dar preluarea posesiunii și ulterior returnarea acesteia cu fiecare funcție se poate dovedi a fi un proces anevoios. Ce facem dacă vrem ca o funcție să utilizeze o valoare, fără a-i lua posesiunea? Este laborios faptul că tot ce trimitem în interiorul unei funcții trebuie să fie returnat înapoi dacă dorim să-l utilizăm din nou, în plus față de orice rezultate obținute în corpul funcției pe care am dori să le returnăm.
Rust ne oferă posibilitatea de a returna mai multe valori prin utilizarea unei tuple, așa cum este ilustrat în Listarea 4-5.
Numele fișierului: src/main.rs
fn main() { let s1 = String::from("hello"); let (s2, len) = calculate_length(s1); println!("The length of '{}' is {}.", s2, len); } fn calculate_length(s: String) -> (String, usize) { let length = s.len(); // len() returns the length of a String (s, length) }
Listarea 4-5: Returnarea posesiunii parametrilor
Însă acest proces este prea laborios și complex pentru un concept ce ar trebui să fie simplu. Din fericire pentru noi, Rust dispune de o funcționalitate ce ne permite să folosim o valoare fără a-i transfera posesiunea, funcționalitate cunoscută sub numele de referințe.
Referințe și procesul de împrumutare
Dificultatea pe care o întâmpinăm cu codul pentru tuplă, din Listarea 4-5, este că trebuie să returnăm String-ul către funcția apelantă pentru a putea utiliza în continuare String-ul după apelul funcției calculate_length. Aceasta se datorează faptului că String-ul a fost permutat în interiorul funcției calculate_length. O soluție alternativă ar fi să furnizăm o referință la valoarea String-ului. O referință funcționează similar unui pointer - ea reprezintă o adresă ce permite accesul la datele stocate la acea adresă; aceste date fiind deținute de o altă variabilă. Însă, spre deosebire de un pointer, o referință este garantată să indice o valoare validă a unui anumit tip, pe toată durata vieții acestei referințe.
Iată cum definim și utilizăm funcția calculate_length care are ca parametru o referință la un obiect, în loc să preia posesiunea valorii:
Numele fișierului: src/main.rs
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{}' is {}.", s1, len); } fn calculate_length(s: &String) -> usize { s.len() }
În primul rând, observăm că tot codul referitor la tuplă, din declarația variabilei și valoarea de return a funcției, a dispărut. În al doilea rând, remarcăm faptul că transmitem &s1 către funcția calculate_length și că, în definiția sa, preluăm &String și nu String. Aceste semne de ampersand reprezintă referințe și permit să te referi la o anumită valoare fără a-i prelua posesiunea. Conceptul este reprezentat în Figura 4-5.

Figura 4-5: Diagrama ilustrând &String s care direcționează spre String s1
Notă: Procesul invers referențierii prin utilizarea
&este dereferențierea, realizată cu ajutorul operatorului de dereferențiere,*. Vom explora câteva situații de utilizare a operatorului de dereferențiere în Capitolul 8 și vom discuta în detaliu despre dereferențiere în Capitolul 15.
Să examinăm mai în detaliu apelul funcției de aici:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{}' is {}.", s1, len); } fn calculate_length(s: &String) -> usize { s.len() }
Sintaxa &s1 ne permite să creăm o referință care indică valoarea s1 însă fără a o deține. Dat fiind faptul că nu o deține, valoarea la care face referire nu va fi abandonată (dropped) când referința nu mai este folosită.
În mod similar, semnătura funcției folosește & pentru a indica faptul că tipul parametrului s este o referință. Să adăugăm câteva adnotări care să clarifice aceste aspecte:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{}' is {}.", s1, len); } fn calculate_length(s: &String) -> usize { // s is a reference to a String s.len() } // Here, s goes out of scope. But because it does not have ownership of what // it refers to, it is not dropped.
Domeniul în care este validă variabila s coincide cu cel al oricărui parametru de funcție. Cu toate acestea, valoarea către care se referă nu este eliminată când nu mai folosim s. Motivul este simplu: s nu are posesiunea acestei valori. Dacă funcțiile noastre folosesc referințe ca parametri, în locul valorilor propriu-zise, nu trebuie să returnăm valorile pentru a restitui posesiunea, deoarece, de fapt, nu am avut niciodată posesiunea acestora.
Acest act de a crea o referință îl numim împrumutare. În mod similar cu viața de zi cu zi, dacă o persoană deține ceva, tu poți să îi împrumuți acel lucru. Odată ce ai terminat cu acel lucru, trebuie să îl restitui. Întrucât nu îți aparține.
Așadar, ce se întâmplă dacă încercăm să modificăm ceva ce doar împrumutăm? Încearcă codul din Listarea 4-6. Dar te previn: nu o să iasă exact cum te-ai așteptat!
Numele fișierului: src/main.rs
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}Listarea 4-6: Tentativa de a modifica o valoare împrumutată
Aceasta este eroarea întâlnită:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
7 | fn change(some_string: &String) {
| ------- help: consider changing this to be a mutable reference: `&mut String`
8 | some_string.push_str(", world");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` due to previous error
Exact așa cum sunt imutabile variabilele, în mod implicit, la fel sunt și referințele. Nu ne este permisă modificarea unei valori la care deținem doar o referință.
Referințe mutabile
Putem corecta codul din Listarea 4-6 pentru a ne oferi posibilitatea de a modifica o valoare împrumutată, prin câteva ajustări minore care implică utilizarea unei referințe mutabile:
Numele fișierului: src/main.rs
fn main() { let mut s = String::from("hello"); change(&mut s); } fn change(some_string: &mut String) { some_string.push_str(", world"); }
În primul rând, modificăm s pentru a fi mut. Apoi, creăm o referință mutabilă cu &mut s în momentul în care invocăm funcția change, și actualizăm semnătura funcției pentru a accepta o referință mutabilă cu some_string: &mut String. Astfel, devine foarte clar că funcția change va modifica valoarea pe care o împrumută.
Referințele mutabile vin însă cu o limitare importantă: dacă deții o referință mutabilă la o valoare, nu poți deține alte referințe către aceeași valoare. Acest cod, care încearcă să creeze două referințe mutabile la s, va da eroare:
Filename: src/main.rs
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
}Și eroarea:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` due to previous error
Această eroare ne informează că respectivul cod nu este valid, întrucât nu se poate împrumuta s în mod mutabil de mai multe ori concomitent. Primul împrumut mutabil se realizează în r1 și trebuie să continue până când este folosit în instrucțiunea println!. Cu toate acestea, între momentul creării acestei referințe mutabile și momentul utilizării sale, am încercat să generăm o altă referință mutabilă în r2, care împrumută aceleași date ca și r1.
Restricția care interzice mai multe referințe mutabile simultane la aceleași date ne permite să modificăm datele, dar într-un mod extrem de controlat. Aceasta este o provocare des întâlnită pentru cei nou-veniți în lumea Rust, deoarece majoritatea limbajelor de programare permit modificarea datelor oricând. Avantajul acestei restricții este faptul că Rust poate preveni apariția curselor de date în timpul compilării. O cursă de date este similară cu o condiție de cursă și se produce atunci când au loc următoarele trei evenimente:
- Două sau mai multe pointere accesează simultan aceleași date.
- Cel puțin un pointer este utilizat pentru a scrie date.
- Nu există niciun mecanism în vigoare care să sincronizeze accesul la date.
Cursele de date creează un comportament nedefinit și pot fi dificile de diagnosticat și remediat atunci când încerci să le detectezi în timpul execuției; Rust preîntâmpină acest gen de problemă prin faptul că refuză să compileze codul în care apar curse de date!
Ca de obicei, avem posibilitatea de a utiliza acolade pentru a iniția un nou domeniu de vizibilitate, astfel facilitând existența mai multor referințe mutabile; singura condiție este aceea de a nu fi simultane:
fn main() { let mut s = String::from("hello"); { let r1 = &mut s; } // r1 goes out of scope here, so we can make a new reference with no problems. let r2 = &mut s; }
Rust impune o regulă similară pentru combinarea referințelor mutabile și imutabile. Acest cod generează o eroare:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{}, {}, and {}", r1, r2, r3);
}Eroarea:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{}, {}, and {}", r1, r2, r3);
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` due to previous error
De asemenea, nu ne este permis să avem o referință mutabilă în același timp cu o referință imutabilă către aceeași valoare.
Cei ce folosesc o referință imutabilă nu se așteaptă ca valoarea să se schimbe brusc, fără un avertisment! Totuși, sunt permise multiple referințe imutabile, deoarece nicio persoană ce doar citește datele nu are abilitatea de a interfera cu lectura altcuiva a acelor date.
Trebuie să reții că domeniul de vizibilitate al unei referințe începe de unde este aceasta introdusă și continuă până la ultima utilizare a respectivei referințe. De pildă, acest cod se va compila deoarece ultima folosire a referințelor imutabile, și anume println!, are loc înainte de a fi introdusă referința mutabilă:
fn main() { let mut s = String::from("hello"); let r1 = &s; // no problem let r2 = &s; // no problem println!("{} and {}", r1, r2); // variables r1 and r2 will not be used after this point let r3 = &mut s; // no problem println!("{}", r3); }
Domeniile de vizibilitate pentru referințele imutabile r1 și r2 se încheie imediat după ce au fost utilizate pentru ultima dată în println!. Asta se întâmplă înainte ca referința mutabilă r3 să fie creată. Aceste domenii nu se intersectează, deci nu interferă unul cu celălalt, făcând acest cod valid. Compilatorul Rust este în stare să determine că referința nu mai este folosită înainte de sfârșitul domeniului de vizibilitate.
Știm că erorile legate de împrumutări pot fi frustrante uneori. Totuși, trebuie să înțelegem că acesta este un mecanism prin care compilatorul Rust ne avertizează asupra unui potențial bug în stadiul de compilare, nu în timpul rulării. În plus, ne indică exact locul unde apare problema. Aceasta îți va economisi timp deoarece nu va trebui să cauți motivul pentru care datele tale nu corespund cu ceea ce te așteptai.
Referințe fără destinație
În limbajele de programare ce utilizează pointeri, este foarte ușor să generăm, chiar și involuntar, un pointer în aer (dangling) - un pointer ce își pierde legătura cu o parte de memorie care poate fi atribuită altei operațiuni - prin simpla eliberare a unei părți din memoria alocate, în timp ce pointerul către acea memorie rămâne încă activ. În contrast, Rust, prin intermediul compilatorului, garantează că niciodată nu vor exista referințe fără destinație: dacă avem o referință la niște date, compilatorul se va asigura că acele date nu vor fi scoase din domeniul de vizibilitate înainte ca referința spre ele să o facă.
Acum, să încercăm să generăm o referință fără destinație, doar pentru a observa cum Rust previne acest lucru printr-o eroare la etapa de compilare:
Numele fișierului: src/main.rs
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}Vom primi eroarea:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
5 | fn dangle() -> &'static String {
| +++++++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` due to previous error
Acest mesaj de eroare face referire la un concept pe care încă nu l-am abordat: durate de viață. Vom aprofunda această temă în Capitolul 10. Cu toate acestea, chiar dacă nu ținem cont de porțiunile ce se referă la durate de viață, mesajul (tradus) ne oferă o pistă esențială pentru a intelege de ce acest fragment de cod nu funcționează:
tipul de retur al acestei funcții conține o valoare împrumutată, dar nu există nicio valoare pentru a fi împrumutată
Să examinăm mai atent ce se petrece la fiecare pas în codul nostru dangle:
Numele fișierului: src/main.rs
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // we return a reference to the String, s
} // Here, s goes out of scope, and is dropped. Its memory goes away.
// Danger!Dat fiind că s este generat în interiorul dangle, la finalizarea rulării codului din dangle, s va fi dezalocat. Cu toate acestea, noi am încercat să returnăm o referință către s. Aceasta presupune că referința noastră ar fi îndreptată către un String ce devine invalid. Situația nu este deloc favorabilă! Rust nu ne va permite să desfășurăm o astfel de acțiune.
Soluția în acest caz constă în returnarea directă a String:
fn main() { let string = no_dangle(); } fn no_dangle() -> String { let s = String::from("hello"); s }
Aceasta funcționează fără nici o problemă. Posesiunea este permutată și nimic nu este dezalocat.
Regulamentul referințelor
Să reamintim principiile pe care le-am discutat despre referințe:
- În orice clipă, ai voie să deții ori o singură referință mutabilă sau o cantitate nelimitată de referințe imutabile.
- Referințele trebuie să fie valide în permanență.
Următoarea etapă va fi examinarea unui alt tip de referință: slice-urile.
Tipul Slice
Secționarea (slicing) îți permite să referențiezi o secvență contiguă de elemente dintr-o colecție, fără a face referire la întreaga colecție. O secțiune este un fel de referință și, prin urmare, ea nu deține posesiunea.
Iată o problemă de programare interesantă: scrie o funcție care acceptă un string format din cuvinte separate de spații și care returnează primul cuvânt descoperit în acest string. Dacă funcția nu găsește vreun spațiu în string, atunci întregul string este un singur cuvânt, caz în care întregul string ar trebui returnat.
Să analizăm cum am formula semnătura acestei funcții fără a utiliza secționări, pentru a înțelege mai bine problema pe care secționarea o va soluționa:
fn first_word(s: &String) -> ?Funcția first_word utilizează un parametru de tip &String. Nu ne interesează posesiunea asupra valorii, deci acesta este modul corect de a proceda. Însă, ce valoare ar trebui să returneze funcția? În momentul de față, nu dispunem de un mijloc prin care să ne referim la o porțiune a unui string. Totuși, o soluție ar fi să returnăm indexul la care se încheie cuvântul, index care este marcat de un spațiu. Să încercăm această abordare, așa cum este prezentată în Listarea 4-7.
Numele fișierului: src/main.rs
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() {}
Listare 4-7: Funcția first_word care returnează un
index de byte în cadrul parametrului de tip String
Avem nevoie să parcurgem String-ul element cu element și să determinăm dacă
o valoare este un spațiu. Pentru aceasta, vom converti String într-un array de byte utilizând metoda as_bytes.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}În pasul următor, vom crea un iterator care să parcurgă array-ul de bytes, folosind metoda iter:
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Vom detalia mai mult despre iteratori în Capitolul 13. Până atunci, este important de ştiut că iter este o metodă care returnează fiecare element al unei colecții, iar enumerate este un înveliş peste rezultatul lui iter. Ea returnează fiecare element ca parte a unei tuple. Primul element al tuplei returnate de enumerate este indexul, iar al doilea este o referință la element. Acest lucru este mai practic decât să calculăm noi înșine indexul.
Faptul că metoda enumerate returnează o tuplă ne dă posibilitatea de a folosi anumite modele pentru a destrăma acea tuplă. Vom detalia mai mult despre aceste modele în Capitolul 6. În cadrul buclei for, folosim un model care plasează i pe postura de index în tuplă, și &item pentru unicul byte din tuplă. Din moment ce .iter().enumerate() ne furnizează o referință la element, folosim & în model.
În interiorul buclei for, căutăm byte-ul care semnifică spațiul, folosind sintaxa literală a byte-ului. Dacă găsim un spațiu, vom returna poziția acestuia. Dacă nu, returnăm lungimea string-ului prin utilizarea s.len().
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Avem acum o metodă prin care putem identifica indexul corespunzător sfârșitului primului cuvânt din string. Totuși, întâmpinăm o problemă. Valoarea pe care o returnăm este un usize care, luat izolat, este doar un număr cu semnificație în contextul &String. Altfel spus, dat fiind faptul că acesta este o valoare separată de String, nu putem garanta faptul că aceasta va rămâne validă în viitor. Ia în considerare programul din Listarea 4-8 care utilizează funcția first_word din Listarea 4-7.
Numele fișierului: src/main.rs
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() { let mut s = String::from("hello world"); let word = first_word(&s); // word will get the value 5 s.clear(); // this empties the String, making it equal to "" // word still has the value 5 here, but there's no more string that // we could meaningfully use the value 5 with. word is now totally invalid! }
Listarea 4-8: Stocarea rezultatului obținut în urma apelării funcției first_word, urmată de modificarea conținutului variabilei tip String
Acest program este compilat fără nicio eroare și ar continua să funcționeze corect chiar și dacă am folosi word după apelarea metodei s.clear(). Întrucât word nu este legat de starea lui s în nici un fel, word păstrează în continuare valoarea 5. Am putea utiliza valoarea 5 cu variabila s pentru a încerca să extragem primul cuvânt, însă am avea de-a face cu un bug, deoarece conținutul lui s s-a modificat de la momentul stocării valorii 5 în word.
Preocuparea constantă legată de faptul că indexul din word ar putea să nu mai fie în sincronizare cu datele din s este anevoioasă și ne expune erorilor! Administrarea acestor indici devine și mai fragilă dacă am scrie o funcție second_word. Semnătura acesteia ar trebui să arate în felul următor:
fn second_word(s: &String) -> (usize, usize) {Acum există doi indici pe care trebuie să-i urmărim: cel de început și cel de sfârșit. În plus, avem din ce în ce mai multe valori care rezultă din date procesate într-o anumită stare, dar nu se conectează cu acea stare. Suntem înconjurați de trei variabile nelegate care trebuie să rămână sincronizate.
Din fericire, Rust oferă o soluție eficientă la această problemă: secționarea string-urilor.
Secțiuni de string-uri
O secțiune de string reprezintă o referință la o porțiune dintr-un String, având următoarea formă:
fn main() { let s = String::from("hello world"); let hello = &s[0..5]; let world = &s[6..11]; }
hello nu este o referință la întregul String, ci la o secțiune din acesta, secțiune specificată prin adăugarea elementului [0..5]. Secțiunile sunt create utilizând un interval în cadrul parantezelor pătrate, prin specificarea formatului [indexul_de_start..indexul_de_sfârșit], unde indexul_de_start reprezintă prima poziție din secțiune, iar indexul_de_sfârșit este cu o unitate mai mare decât ultima poziție din secțiune. Intern, structura de date a secțiunii stochează poziția de start și lungimea secțiunii, lungime care corespunde cu diferența dintre indexul_de_sfârșit și indexul_de_start. Astfel, în cazul let world = &s[6..11];, world este o secțiune care conține un pointer către octetul din poziția 6 din s, având lungimea de 5.
Figura 4-6 ilustrează clar acest aspect.

Figura 4-6: Secțiune de string ce face referire la o parte a unui String
Folosind sintaxa specifică Rust pentru diapazoane, .., dacă vrei să începi de la indexul 0, poți omite valoarea înaintea celor două puncte. Altfel spus, cele două exemple de mai jos sunt echivalente:
#![allow(unused)] fn main() { let s = String::from("salut"); let slice = &s[0..2]; let slice = &s[..2]; }
La fel, dacă secțiunea ta include ultimul byte al string-ului, poți omite numărul de la final. Prin urmare, următoarele două exemple sunt echivalente:
#![allow(unused)] fn main() { let s = String::from("salut"); let len = s.len(); let slice = &s[3..len]; let slice = &s[3..]; }
De asemenea, poți renunța la ambele valori pentru a prelua o secțiune din întregul string. Acest fapt înseamnă că următoarele două exemple sunt identice:
#![allow(unused)] fn main() { let s = String::from("salut"); let len = s.len(); let slice = &s[0..len]; let slice = &s[..]; }
Notă: Indicii de interval pentru secțiunea de string-uri trebuie să corespundă la limitele caracterelor UTF-8 valide. Dacă încerci să creezi o secțiune de string în mijlocul unui caracter multi-byte, programul tău va ieși cu o eroare. Pentru a introduce conceptul de secțiuni de string-uri, presupunem că utilizăm doar ASCII în această secțiune. O discuție mai detaliată despre manipularea UTF-8 se găsește în secțiunea „Stocarea textului codificat UTF-8 cu String-uri” din Capitolul 8.
Cu toate aceste informații în minte, să rescriem funcția first_word pentru a returna o secțiune. Tipul ce denotă "secțiunea de string" se scrie ca &str.
Numele fișierului: src/main.rs
fn first_word(s: &String) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() {}
Obținem indexul corespunzător sfârșitului cuvântului într-un mod similar cu cel prezentat în Listarea 4-7, prin identificarea primei apariții a unui spațiu. În momentul în care identificăm un spațiu, returnăm o secțiune din string folosind punctul de început al string-ului și indexul spațiului ca indici de început și sfârșit.
Astfel, la apelul funcției first_word, primim o singură valoare, care este strâns legată de datele inițiale. Această valoare este constituită dintr-o referință către punctul de start al secțiunii și numărul de elemente ce se regăsesc în secțiune.
Similar, returnarea unei secțiuni ar funcționa și în cazul unei funcții numite second_word:
fn second_word(s: &String) -> &str {Acum dispunem de o interfață API simplificată, al cărei utilizare eronată este semnificativ redusă, deoarece compilatorul se va asigura că referințele din String rămân valide. Îți amintești de erorile din programul prezentat în Listarea 4-8? Acolo, am obținut indexul care indica sfârșitul primului cuvânt, dar ulterior am golit string-ul, ceea ce a făcut ca indexul nostru să devină inutilizabil. Deși acest cod era logic incorect, nu am întâmpinat nicio eroare imediată. Problemele ar fi devenit vizibile mai târziu, dacă am fi continuat să folosim indexul primului cuvânt cu un string gol. Utilizarea secțiunilor face această eroare imposibilă și ne avertizează mult mai devreme cu privire la problemele din codul nostru. Folosind versiunea de secțiune a first_word, vom întâmpina o eroare în timpul compilării:
Numele fișierului: src/main.rs
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}Avem următoarea eroare de compilare:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` due to previous error
Luați în considerare regulile de împrumutare: dacă avem o referință imutabilă la un anumit element, nu putem obține, în același timp, și o referință mutabilă la acel element. Funcția clear are nevoie să trunchieze o variabilă de tip String, deci trebuie să obțină o referință mutabilă la aceasta. Funcția println!, care urmează după apelul la clear, utilizează referința la variabila word. Deci, referința imutabilă utilizată de println! trebuie să fie încă activă la momentul acela. Cu toate acestea, limbajul Rust nu permite ca o referință mutabilă (utilizată în clear) și o referință imutabilă (utilizată în word) să existe simultan, fapt care conduce la eșecul compilării. Acesta este un exemplu de cum Rust nu doar că face API-ul nostru mai ușor de utilizat, dar elimină eficient și o întreagă clasă de erori chiar în timpul compilării!
Literalii de string ca secțiuni
Vă reamintim că am discutat anterior despre modul în care literalii de tip string sunt stocați în interiorul codului binar. Acum, având cunoștințe despre secțiuni, putem înțelege într-un mod mai profund literalii de tip string:
#![allow(unused)] fn main() { let s = "Salut, lume!"; }
Aici, tipul variabilei s este &str: reprezintă o secțiune care indică un anumit punct specific în codul binar. Acesta este, de asemenea, motivul pentru care literalii de tip string sunt imutabili; &str este o referință imutabilă.
Utilizarea secțiunilor de string ca parametri
Înțelegând faptul că putem prelua secțiuni din literale și valori String, acest lucru ne permite să facem o îmbunătățire suplimentară a funcției first_word, însemnând în special modificarea modului în care aceasta este semnată:
fn first_word(s: &String) -> &str {Un programator Rust mai experimentat ar opta pentru semnătura de tip prezentată în Listarea 4-9, deoarece aceasta ne permite să utilizăm aceeași funcție atât pentru valorile &String, cât și pentru cele &str.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or whole
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}Listare 4-9: Optimizarea funcției first_word prin folosirea unei secțiuni de string ca tip pentru parametrul s
Dacă dispunem de o secțiune de string, o putem transmite direct. Dacă avem un String, putem transmite fie o secțiune a String-ului, fie o referință la String. Această versatilitate profită de funcționalitatea deref coercions, un aspect pe care îl vom explora în secțiunea „Coerciții Deref implicite cu funcții și metode” din Capitolul 15.
Definind o funcție care să preia o secțiune de string în locul unei referințe la un String, API-ul nostru devine mai general și util, fără a compromite orice altă funcționalitate:
Numele fișierului: src/main.rs
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // `first_word` works on slices of `String`s, whether partial or whole let word = first_word(&my_string[0..6]); let word = first_word(&my_string[..]); // `first_word` also works on references to `String`s, which are equivalent // to whole slices of `String`s let word = first_word(&my_string); let my_string_literal = "hello world"; // `first_word` works on slices of string literals, whether partial or whole let word = first_word(&my_string_literal[0..6]); let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
Alte tipuri de secțiuni
Secțiunile de string-uri, așa cum probabil ți-ai imaginat deja, sunt specifice pentru string-uri. Totuși, există și un tip de secțiune cu o aplicabilitate mai largă. Gândește-te la următorul array:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; }
La fel cum am dori să facem referire la o anumită porțiune dintr-un string, ne-ar putea interesa să ne referim la o anumită parte a unui array. Am face-o astfel:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; let slice = &a[1..3]; assert_eq!(slice, &[2, 3]); }
Această secțiune are tipul &[i32]. Funcționează exact la fel ca secțiunile de string-uri, prin stocarea unei referințe la primul element și a lungimii acestuia. Vei utiliza acest tip de secțiune pentru o multitudine de alte categorii de colecții. Vom adresa aceste colecții în mod detaliat când vom discuta despre vectori în Capitolul 8.
Sumar
Conceptele de posesiune, împrumutare și utilizarea secțiunilor garantează siguranța memoriei în programele Rust la momentul compilării. Limbajul Rust îți oferă autonomie în gestionarea memoriei, asemenea altor limbaje de programare de sistem. Avantajul remarcabil al Rust constă în faptul că deținătorul datelor efectuează automat o curățenie a acestora atunci când iese din domeniul de vizibilitate. Astfel, nu este nevoie de scrierea și depanarea de cod adițional.
Posesiunea influențează modul în care funcționează multe alte componente ale limbajului Rust; de aceea, ne vom aprofunda în discutarea acestor concepte pe tot parcursul cărții. Să mergem mai departe la Capitolul 5, unde vom examina gruparea datelor în cadrul unei structuri.
Folosirea structurilor pentru organizarea datelor interconectate
O structură, sau mai simplu struct, este un tip de date personalizat care ne permite să grupăm împreună și să denumim valorile diferite, dar conexate, într-un ansamblu unitar și însemnat. Dacă ești familiarizat cu un limbaj de programare orientat pe obiecte, o structură ar putea fi similară cu atributele de date ale unui obiect. În acest capitol, vom face o analiză comparativă între tuple și structuri, bazându-ne pe ceea ce deja cunoști, și vom arăta când este mai avantajos să folosim structurile pentru a grupa datele.
Vom exemplifica cum se definesc și se inițializează structurile. Vom discuta cum se definesc funcțiile asociate, în special tipul de funcții asociate, cunoscute sub numele de metode, pentru a descrie comportamentul asociat cu un tip de structură. Structurile și enumerările (discutate în Capitolul 6) stau la baza creării de noi tipuri în domeniul propriului tău program, pentru a beneficia la maximum de verificarea tipurilor datelor în timpul compilării în limbajul Rust.
Definirea și crearea instanțelor de structuri
Structurile prezintă anumite asemănări cu tuplele, pe care le-am discutat în secțiunea “Tipul tuplă”. Ambele pot deține mai multe valori direct correlate. Similar tuplelor, elementele unei structuri pot avea tipuri diferite. Cu toate acestea, în cazul unei structuri vei atribui un nume fiecărui segment de date, astfel încât să fie evident ce semnifică aceste valori. Prin adăugarea acestor denumiri, structurile devin mai flexibile decât tuplele: nu va trebui să te bazezi pe ordinea datelor pentru a specifica sau accesa valorile unei instanțe.
Pentru a defini o structură, folosim cuvântul cheie struct și atribuim un nume întregii structuri. Numele unei structuri ar trebui să descrie întreaga semnificație a fragmentelor de date grupate împreună. Apoi, în interiorul acoladelor, definim numele și tipurile fragmentelor de date, pe care le numim câmpuri (fields). De exemplu, în Listarea 5-1 prezentăm o structură care stochează informații legate de un cont de utilizator.
Numele fișierului: src/main.rs
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() {}
Listarea 5-1: Definirea structurii User
Odată ce am definit o structură, pentru a o putea utiliza, trebuie să creăm o instanță a acesteia. Creăm o instanță stabilind valorile specifice pentru fiecare dintre câmpurile structurii. Acest lucru se realizează prin menționarea numelui structurii urmat de paranteze acolade, care includ perechi de tip cheie: valoare. 'Cheile' sunt denumirile câmpurilor, iar 'valorile' reprezintă informațiile pe care intenționăm să le stocăm în aceste câmpuri. Ordinea în care specificăm câmpurile nu trebuie să respecte neapărat ordinea în care acestea au fost declarate în structură. Cu alte cuvinte, putem privi definiția structurii ca pe un șablon general pentru tipul de date, iar instanțele completează acest șablon cu date specifice, formând astfel valori ale acelui tip. De exemplu, putem declara un utilizator specific conform exemplului din Listarea 5-2.
Numele fișierului: src/main.rs
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let user1 = User { active: true, username: String::from("someusername123"), email: String::from("someone@example.com"), sign_in_count: 1, }; }
Listing 5-2: Creating an instance of the User
struct
Pentru a extrage o anumită valoare dintr-o structură, apelăm la notația cu punct. De pildă, dacă dorim să accesăm adresa de email a acestui utilizator, utilizăm expresia user1.email. În cazul în care instanța noastră este mutabilă, avem posibilitatea de a modifica o valoare folosind aceeași notație cu punct, dar realizând o atribuire într-un câmp specific. În Listarea 5-3 este prezentată modalitatea de schimbare a valorii în câmpul email al unei instanțe mutabile de tip User.
Numele fișierului: src/main.rs
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let mut user1 = User { active: true, username: String::from("someusername123"), email: String::from("someone@example.com"), sign_in_count: 1, }; user1.email = String::from("anotheremail@example.com"); }
Listing 5-3: Changing the value in the email field of a
User instance
Listarea 5-3: Schimbarea valorii în câmpul email pentru o instanţă User
Este important de notat, că toată instanța trebuie să fie mutabilă; Rust nu ne oferă posibilitatea de a defini doar anumite câmpuri ca fiind mutabile. Similar cu alte expresii, putem crea o instanță nouă a structurii în calitate de ultimă expresie în corpul funcției, astfel încât noua instanță să fie returnată în mod implicit.
Listarea 5-4 prezintă o funcție build_user, care returnează o instanță User, în funcție de email-ul și numele de utilizator specificat. Câmpul active ia valoarea true, iar sign_in_count primește valoarea 1.
Numele fișierului: src/main.rs
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn build_user(email: String, username: String) -> User { User { active: true, username: username, email: email, sign_in_count: 1, } } fn main() { let user1 = build_user( String::from("someone@example.com"), String::from("someusername123"), ); }
Listarea 5-4: O funcție build_user care preia un email
și un nume de utilizator, returnând o instanță User
Este firesc să folosim aceleași denumiri pentru parametrii funcției precum cele ale câmpurilor din structură. Cu toate acestea, repetarea numelor câmpurilor email și username și a variabilelor poate deveni monotonă. Dacă structura ar conține mai multe câmpuri, repetarea fiecărui nume s-ar transforma într-o sarcină mai mult decât fastidioasă. Din fericire, există o prescurtare foarte convenabilă!
Aplicarea sintaxei de inițializare abreviată a câmpurilor
Dând luare de seama că în Listarea 5-4 numele parametrilor se potrivesc perfect cu denumirile câmpurilor din structură, avem posibilitatea de a utiliza sintaxa de inițializare abreviată a câmpurilor (field init shorthand). Acest lucru ne permite să rescriem funcția build_user astfel încât aceasta să funcționeze identic, însă eliminând repetarea neceasră a numelor username și email. Acest proces este ilustrat în Listarea 5-5.
Numele fișierului: src/main.rs
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn build_user(email: String, username: String) -> User { User { active: true, username, email, sign_in_count: 1, } } fn main() { let user1 = build_user( String::from("someone@example.com"), String::from("someusername123"), ); }
Listarea 5-5: O funcție build_user care utilizează sintaxa abreviată de inițializare a câmpurilor, având în vedere faptul că parametrii username și email corespund cu numele câmpurilor din structură
În acest caz, noi generăm o nouă instanță a structurii User, ce include un câmp denumit email. Intenția noastră este de a atribui valoarea câmpului email cu valoarea corespunzătoare parametrului email din funcția build_user. Grație faptului că numele câmpului email și cel al parametrului email sunt identice, este suficient să scriem o singură dată email, în loc de email: email.
Crearea de instanțe din alte instanțe utilizând sintaxa de actualizare a structurii
Adeseori este util să generezi o nouă instanță a unei structuri care păstrează majoritatea valorilor provenite din altă instanță, dar modifică câteva dintre ele. Aceasta se poate realiza utilizând sintaxa de actualizare a structurii.
Pentru început, în Listarea 5-6, ilustrăm cum să creăm o nouă instanță User în user2, fără a folosi sintaxa de actualizare. Atribuim o nouă valoare pentru email, dar pentru restul valorilor, le păstrăm pe cele din user1, pe care l-am creat în Listarea 5-2.
Numele fișierului: src/main.rs
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { // --snip-- let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { active: user1.active, username: user1.username, email: String::from("another@example.com"), sign_in_count: user1.sign_in_count, }; }
Listarea 5-6: Crearea unei noi instanțe de tip 'User', folosind o valoare din 'user1'
Utilizând sintaxa de actualizare a structurii, putem atinge același rezultat cu un cod mult mai concis, așa cum se arată în Listarea 5-7. Sintaxa .. indică faptul că toate celelalte câmpuri care nu au fost explicit stabilite trebuie să aibă valorile identice cu cele din instanța sursă.
Numele fișierului: src/main.rs
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { // --snip-- let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { email: String::from("another@example.com"), ..user1 }; }
Listing 5-7: Using struct update syntax to set a new
email value for a User instance but to use the rest of the values from
user1
Codul prezentat în Listarea 5-7 generează de asemenea o instanță în user2, care are o valoare distinctă pentru email, dar păstrează aceleași valori pentru câmpurile username, active și sign_in_count ca în user1. Elementul ..user1 trebuie poziționat la final pentru a indica faptul că orice alt câmp rămas ar trebui să își preia valorile de la câmpurile corespondente din user1. În același timp, ne este permis să stabilim valorile pentru oricâte câmpuri dorim, fără a fi impusă vreo ordine, indiferent de succesiunea câmpurilor în cadrul definiției structurii.
Este important de remarcat faptul că sintaxa de actualizare a structurilor utilizează = la fel ca într-o atribuire; acest lucru se produce deoarece datele sunt permutate, așa cum am observat în secțiunea “Variabile și interacționarea cu date folosind permutarea”. În acest exemplu, după ce am creat user2, nu mai putem folosi în totalitate user1 deoarece string-ul din câmpul username al user1 a fost permutat în user2. Dacă am fi atribuit user2 noi valori de string atât pentru email cât și pentru username, utilizând astfel doar valorile active și sign_in_count de la user1, atunci user1 ar fi rămas valid după crearea user2. Atât active cât și sign_in_count sunt tipuri care implementează trăsătura Copy, astfel comportamentul de care am discutat în secțiunea “Date doar pe stivă: trăsătura Copy” va fi aplicabil.
Utilizarea structurilor tuplă fără câmpuri denumite pentru a genera tipuri diferite
Rust suportă de asemenea structuri care se aseamănă cu tuplele, denumite structuri tuplă. Acestea îmbogățesc semnificația pe care o conferă numele structurii, deși nu dispun de nume asociate câmpurilor lor; în loc, acestea sunt definite doar prin tipurile câmpurilor. Structurile tuplă sunt utile atunci când dorești să atribui un nume întregii tuple, configurându-l ca un tip distinct față de alte tuple, precum și atunci când ar fi redundant să denumești fiecare câmp, așa cum s-ar întâmpla într-o structură obișnuită.
Pentru a defini o structură tuplă, începeți cu cuvântul-cheie struct, urmat de numele structurii și de tipurile componente ale tuplei. De exemplu, în continuare definim și folosim două structuri tuplă, denumite Color și Point:
Numele fișierului: src/main.rs
struct Color(i32, i32, i32); struct Point(i32, i32, i32); fn main() { let black = Color(0, 0, 0); let origin = Point(0, 0, 0); }
Observă că black și origin sunt de tipuri diferite, deoarece reprezintă instanțe ale unor structuri tuplă distincte. Fiecare structură pe care o definești în program constituie un tip inedit, chiar dacă toate câmpurile acelei structuri au același tip. De exemplu, o funcție care necesită un argument de tip Color nu va putea primi un Point ca și parametru, chiar dacă ambele tipuri sunt formate din trei valori i32. La fel ca și în cazul tuplă, la structurile tuplă avem posibilitatea de a le descompune în elementele individuale și putem accesa o anumită valoare folosind un . urmat de indexul respectiv.
Structuri asemănătoare cu unit, fără niciun câmp
Poate vei fi surprins, dar este posibil să definești și structuri care nu includ niciun câmp! Acestea se numesc structuri asemănătoare cu unit (unit-like structs) deoarece comportamentul lor este similar cu cel al (), tipul unit pe care l-am menționat în secțiunea dedicată Tipul tuplă. Asemenea structuri pot dovedi a fi utile când ai nevoie să implementezi o trăsătură pe un anumit tip, dar concomitent nu ai nicio dată pe care dorești să o stochezi direct în tipul respectiv. Ne vom dedica mai mult acestui concept de trăsătură în Capitolul 10. Ca exemplu, iată cum poți declara și instanția o structură asemănătoare cu unit, pe care o vom numi AlwaysEqual:
Numele fișierului: src/main.rs
struct AlwaysEqual; fn main() { let subject = AlwaysEqual; }
Pentru a defini structura AlwaysEqual, utilizăm cuvântul cheie struct, urmat de numele ales de noi și semnul punct și virgulă. Nu este necesar să folosim paranteze sau acolade! Ulterior, putem obține o instanță a structurii AlwaysEqual în variabila subject prin intermediu unui proces similar: utilizând numele definit de noi, în absența oricăror paranteze sau acolade. Concepe următorul scenariu: la un moment dat, vom implementa o funcționalitate pentru acest tip, astfel încât orice instanță a AlwaysEqual să fie considerată egală cu orice instanță a altui tip, aceasta urmând să fie folosită probabil pentru a obține un rezultat standard în cazul unor teste. Pentru a implementa această funcționalitate, nu ne va fi nevoie de nicio informație suplimentară! În Capitolul 10 vei afla cum se definesc trăsăturile și cum acestea pot fi implementate pe orice tip, inclusiv pe structurile asemănătoare cu unit.
Proprietatea datelor din cadrul unei structuri
În definiția structurii
Userprezentată în Listarea 5-1, am optat pentru folosirea tipuluiString, care reprezintă un string deținut, în locul tipului de secțiune de string&str. Aceasta nu este o decizie la întâmplare, obiectivul nostru fiind ca fiecare instanță a respectivei structuri să dețină întreaga sa colecție de date, dată ce vor rămâne valabile atât timp cât structura în sine este în vigoare.De asemenea, structurile pot stoca referințe către date deținute de alte elemente, dar pentru asta este necesară utilizarea duratelor de viață, o caracteristică specifică limbajului Rust pe care o vom detalia în Capitolul 10. Duratele de viață garantează că datele referențiate de o structură rămân valabile pe întreaga durată de existență a structurii. Să presupunem că dorești să stochezi o referință într-o structură fără a indica duratele de viață, exact ca în exemplul următor; vei constata că acest lucru nu este posibil:
Numele fișierului: src/main.rs
struct User { active: bool, username: &str, email: &str, sign_in_count: u64, } fn main() { let user1 = User { active: true, username: "someusername123", email: "someone@example.com", sign_in_count: 1, }; }Compilatorul va semnala eroare, solicitând specificatori pentru durata de viață:
$ cargo run Compiling structs v0.1.0 (file:///projects/structs) error[E0106]: missing lifetime specifier --> src/main.rs:3:15 | 3 | username: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 ~ username: &'a str, | error[E0106]: missing lifetime specifier --> src/main.rs:4:12 | 4 | email: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 | username: &str, 4 ~ email: &'a str, | For more information about this error, try `rustc --explain E0106`. error: could not compile `structs` due to 2 previous errorsÎn Capitolul 10, vom discuta cum putem rezolva aceste erori pentru a stoca referințe în structuri. Până atunci însă, vom remedia astfel de erori prin folosirea tipurilor ce se află sub posesiunea noastră, precum
String, în locul referințelor de tip&str.
Un program exemplu ce utilizează structurile
Pentru a înțelege când și cum ne-ar fi util să utilizăm structurile, propunem să dezvoltăm împreună un program care calculează aria unui dreptunghi. Vom începe construind acest program cu ajutorul unor variabile simple și apoi ne vom concentra pe îmbunătățirea și refactorizarea lui prin utilizarea structurilor.
Să creăm un nou proiect binar cu Cargo, numit rectangles. Scopul acestui program va fi de a prelua lățimea și înălțimea unui dreptunghi, specificate în pixeli, și de a calcula aria acestuia. Listarea 5-8 ne arată un exemplu de program scurt care realizează exact acest lucru, modelul fiind implementat în fișierul src/main.rs al proiectului nostru.
Numele fișierului:: src/main.rs
fn main() { let width1 = 30; let height1 = 50; println!( "The area of the rectangle is {} square pixels.", area(width1, height1) ); } fn area(width: u32, height: u32) -> u32 { width * height }
Listarea 5-8: Calculul ariei unui dreptunghi, definit prin variabile separate pentru lățime și înălțime
Acum, execută acest program utilizând cargo run:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
The area of the rectangle is 1500 square pixels.
Deși codul calculează corect aria dreptunghiului, invocând funcția area cu fiecare dimensiune, acest lucru poate fi îmbunătățit pentru a crea un cod mai clar și mai lizibil.
Neclaritatea acestui cod devine evidentă atunci când ne uităm la semnătura funcției area:
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}Funcția area este destinată calculării ariei unui dreptunghi. Totuși, funcția pe care noi am redactat-o are doi parametri, și în niciun loc din programul nostru nu se menționează explicit faptul că acești parametri sunt interconectați. Ameliorarea lizibilității și gestionării codului s-ar putea realiza prin gruparea înălțimii și lățimii. Un astfel de procedeu a fost deja discutat în secțiunea “Tipul Tuplă”, din Capitolul 3, prin utilizarea tuplelor.
Refactorizarea prin utilizarea tuplelor
Lista 5-9 ilustrează o nouă variantă a programului nostru, în care am integrat utilizarea tuplelor.
Numele fișierului:: src/main.rs
fn main() { let rect1 = (30, 50); println!( "The area of the rectangle is {} square pixels.", area(rect1) ); } fn area(dimensions: (u32, u32)) -> u32 { dimensions.0 * dimensions.1 }
Listarea 5-9: Definirea lățimii și înălțimii dreptunghiului prin intermediul unei tuple
Acest program, privit dintr-o anumită perspectivă, este mai eficient. Prin utilizarea tuplelor, adăugăm o structură și trimitem un singur argument. Totuși, acestă abordare este mai puțin clară: elementele unei tuple nu sunt denumite, astfel că trebuie să indexăm părțile tuplei, ceea ce face ca procesul de calcul să devină mai greu de înțeles.
Dacă am confunda lățimea cu înălțimea nu ar avea un impact semnificativ asupra calculării ariei, dar în cazul în care am dori să reprezentăm dreptunghiul pe un ecran, atunci acest lucru ar conta! Ar trebui să ne amintim că width (lățimea) este indexul 0 al tuplei, iar height (înălțimea) este indexul 1. Aceasta ar putea fi un lucru greu de înțeles și de reținut de către o altă persoană care ar urma să utilizeze codul nostru. Deoarece nu am transmis semnificația datelor în codul nostru, introducerea erorilor devine acum mult mai ușoară.
Refactorizarea folosind structuri: Introducerea unui sens mai amplu
Folosim structurile pentru a adăuga mai mult sens datelor prin etichetarea acestora. Avem posibilitatea de a transforma tupla pe care o utilizăm într-o structură, acordând un nume atât pentru întreg, cât și pentru părțile acesteia. Acest lucru este ilustrat în Listarea 5-10.
Numele fișierului:: src/main.rs
struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", area(&rect1) ); } fn area(rectangle: &Rectangle) -> u32 { rectangle.width * rectangle.height }
Listarea 5-10: Crearea structurii Rectangle
În acest fragment de cod, am definit o structură numită Rectangle. În cadrul acoladelor, am precizat câmpurile acesteia: width (lăţime) şi height (înălţime), ambele de tipul u32. Apoi, în funcția main, am inițiat o instanță specifică Rectangle cu o lăţime de 30 şi o înălţime de 50.
Acum, funcţia noastră area este definită având un singur parametru numit rectangle, de tip împrumut imutabil al unei instanţe Rectangle. După cum am menţionat anterior în Capitolul 4, dorim să împrumutăm structura mai degrabă decât să îi preluăm total posesiunea. Astfel, funcţia main îşi păstrează posesiunea şi poate continua să utilizeze rect1, motiv pentru care utilizăm & în semnătura funcţiei şi la apelarea acesteia.
Funcţia area accesează câmpurile width şi height ale instanţei Rectangle. Notăm că accesul la câmpurile unei instanţe împrumutate nu permută valorile acestor câmpuri, acesta fiind motivul pentru care în cod Rust deseori vedem structuri anume împrumutate. Semnătura actuală a funcţiei area exprimă în mod precis intenţia noastră: de a calcula aria lui Rectangle utilizând câmpurile sale width și height. Acest lucru subliniază relaţia dintre lăţime şi înălţime şi le conferă nume descriptive, în locul folosirii valorilor de index ale tuplei 0 şi 1, implicând un câştig semnificativ în ceea ce priveşte claritatea.
Îmbunătățirea funcționalității prin folosirea de trăsături derivate
Ne-ar fi de folos să putem afișa o instanță a Rectangle în timp ce depanăm programul, vizualizând valorile tuturor câmpurilor sale. În Listarea 5-11, încercăm să utilizăm macro-ul println!, așa cum am făcut în capitolele anterioare. Totuși, aceasta nu va funcționa.
Numele fișierului:: src/main.rs
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {}", rect1);
}Listare 5-11: Tentativa de a afișa o instanță de Rectangle
Atunci când rulăm procesul de compilare pentru acest cod, obținem o eroare ce conține următorul mesaj principal:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
Macroul println! are capacitatea de a realiza diferite formate de afișare. În mod implicit, acoladele indică faptul că println! ar trebui să utilizeze un tip de formatare numit Display, care reprezintă o ieșire destinată direct consumului de către utilizatorul final. Tipurile primitive pe care le-am întâlnit până acum implementează Display în mod automat, deoarece există o singură modalitate în care ai dori să arăți un 1 sau orice alt tip primitiv unui utilizator. Însă, în cazul structurilor, modul în care println! ar trebuie să formateze ieșirea este mai puțin evident, existând numeroase variante de afișare: vrei să se utilizeze virgule sau nu? Dorești ca acoladele să fie afișate? Ar trebui toate câmpurile să fie vizibile? Din cauza acestor incertitudini, Rust nu încearcă să presupună intențiile noastre, astfel că structurile nu au o implementare predefinită a Display pentru utilizare cu println! și substituentul {}.
Dacă vom urmări în continuare mesajele de eroare, vom descoperi o notă foarte utilă:
= help: the trait `std::fmt::Display` is not implemented for `Rectangle`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
Să încercăm acest lucru! Acum, apelul macro println! ar urma să arate astfel: println!("rect1 este {:?}", rect1);. Prin adăugarea specificatorului :? în interiorul acoladelor, îi indicăm macro-ului println! că dorim să utilizăm un format de afișare numit Debug. Trăsătura Debug ne oferă capacitatea de a afișa structura noastră într-un mod care este eficient pentru dezvoltatori, permițându-ne să vizualizăm valoarea acesteia în timp ce lucrăm la depanarea codului.
Încearcă să compilezi codul cu această modificare. Drăcie! Încă o eroare:
error[E0277]: `Rectangle` doesn't implement `Debug`
Dar, din nou, compilatorul ne oferă o sugestie utilă:
= help: the trait `Debug` is not implemented for `Rectangle`
= note: add `#[derive(Debug)]` to `Rectangle` or manually `impl Debug for Rectangle`
Rust dispune de funcționalitatea de a afișa informații pentru depanare, dar pentru a face această funcționalitate disponibilă structurii noastre, trebuie să optăm în mod explicit. Putem face asta prin adăugarea atributului extern #[derive(Debug)] imediat înainte de definiția structurii, așa cum este ilustrat în Listarea 5-12.
Numele fișierului:: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!("rect1 is {:?}", rect1); }
Listarea 5-12: Incorporarea atributului pentru a deriva trăsătura Debug și afișarea instanței Rectangle prin intermediul formatării de depanare
La rularea programului, acum nu vom întâlni nici o eroare, iar rezultatul arată astfel:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle { width: 30, height: 50 }
Excelent! Rezultatul nu este cel mai estetic, dar afișează valorile tuturor câmpurilor pentru instanța dată, ceea ce cu siguranță ne este de folos în timpul depanării. Când lucrăm cu structuri mai complexe, este util să obținem un rezultat mai ușor de analizat; în acele cazuri, putem aplica {:#?} în loc de {:?} in interiorul string-ului println!. De exemplu, folosirea stilului {:#?} va produce următorul rezultat:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle {
width: 30,
height: 50,
}
Un alt mod de a afișa o valoare utilizând formatul Debug este prin intermediul macro-ului dbg!. Acesta preia în posesiune o anumită expresie (în contradicție cu println!, care folosește o referință), afișează fișierul și linia de cod unde macro-ul dbg! este apelat în programul tău, împreună cu rezultatul acelei expresii, după care restituie posesiunea valorii.
Notă: Apelarea macro-ului
dbg!afișează informațiile în fluxul standard de erori (stderr), spre deosebire deprintln!, care afișează în fluxul standard de ieșire (stdout). Vom vorbi mai mult desprestderrșistdoutîn secțiunea „Scrierea mesajelor de eroare la fluxul standard de erori în loc de fluxul standard de ieșire” din Capitolul 12.
Iată un exemplu în care ne interesează valoarea atribuită câmpului width, precum și valoarea întregii structuri numită rect1:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let scale = 2; let rect1 = Rectangle { width: dbg!(30 * scale), height: 50, }; dbg!(&rect1); }
Putem înconjura expresia 30 * scale cu dbg! și, din moment ce dbg! ne redă posesiunea valorii expresiei, câmpul width va primi aceeași valoare ca și în cazul în care nu am fi apelat dbg!. Nu dorim ca dbg! să preia posesiunea asupra rect1, astfel încât utilizăm o referință la rect1 în următorul apel. Iată cum se prezintă rezultatul acestui exemplu:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10] 30 * scale = 60
[src/main.rs:14] &rect1 = Rectangle {
width: 60,
height: 50,
}
Putem observa că primul fragment de output provine de la src/main.rs, linia 10, unde depanăm expresia 30 * scale. Valoarea rezultată este 60, având în vedere că formatarea Debug pentru numerele întregi este realizată prin afișarea exclusivă a valorilor acestora. Apelul dbg! de pe linia 14 din src/main.rs afișează valoarea &rect1, care reprezintă structura Rectangle. Acest output utilizează o formatare frumoasă, Debug, specifice tipului Rectangle. Macro-ul dbg! poate fi foarte util atunci când încerci să înțelegi ce face codul tău!
Pe lângă trăsătură Debug, Rust ne oferă numeroase trăsături pe care le putem folosi cu atributul derive. Acestea pot adăuga comportamente utile tipurilor noastre. Trăsăturile date și comportamentele lor se găsesc în Anexa C. Vom discuta în Capitolul 10 modul de implementare a acestor trăsături cu funcționalitate particularizată, dar și modul de creare a propriilor trăsături. De asemenea, există și alte atribute în afară de derive; pentru mai multe informații, vezi secțiunea "Atribute".
Funcția noastră area este foarte specifică. Aceasta calculează doar ariile dreptunghiurilor. Ar fi benefic să legăm mai strâns acest comportament de structura noastră Rectangle, având în vedere faptul că nu funcționează cu niciun alt tip. Să vedem cum putem continua să îmbunătățim acest cod, transformând funcția area într-o metodă area definită pe tipul nostru Rectangle.
Sintaxa pentru metode
Metodele sunt similare cu funcțiile. Le definim folosind cuvântul-cheie fn, urmat de un nume. Metodele pot avea parametri și pot returna o valoare, exact ca funcțiile. De asemenea, ele conțin un bloc de cod care este executat atunci când metoda este invocată de undeva.
Totuși, există o diferență importantă: spre deosebire de funcții, metodele sunt definite în cadrul unei structuri (sau a unei enumerări ori a unui obiect de tip trăsătură, subiecte pe care le vom aborda în Capitolul 6 și Capitolul
17, respectiv). Primul lor parametru este întotdeauna self, care reprezintă instanța curentă a structurii pe care este invocată metoda.
Definirea metodelor
Vom modifica funcția area care primește o instanță Rectangle ca parametru și vom crea o metodă area, definită direct pe structura Rectangle. Această modificare este prezentată în Listarea 5-13.
Numele fișierului: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", rect1.area() ); }
Listarea 5-13: Definirea metodei area asociate cu structura Rectangle
Pentru a adăuga funcția în cadrul Rectangle, vom începe prin a iniția un bloc de implementare impl specific pentru Rectangle. Orice element care va fi inclus în acest bloc impl va fi asociat direct cu tipul Rectangle. Apoi, funcția area trebuie să fie mutată în interiorul acoladelor blocului impl. Primul parametru (unicul, în acest caz) va deveni self, atât în semnătura funcției, cât și în corpul acesteia. În funcția main, unde anterior funcția area era apelată cu rect1 ca argument, vom utiliza în schimb sintaxa metodei. Astfel, metoda area va fi apelată direct pe instanța Rectangle. Sintaxa metodei intervine după instanță: adăugăm un punct, urmat de numele metodei, paranteze și oricare argumente necesare.
În semnătura pentru funcția area, am preferat să folosim &self în loc de rectangle: &Rectangle. De fapt, &self nu este altceva decât o formă prescurtată a expresiei self: &Self. În cadrul unui bloc impl, Self denotă tipul pentru care este destinat blocul impl. Orice metodă trebuie să aibă un parametru denumit self de tipul Self ca primul său parametru. Rust ne permite să simplificăm aceasta folosind doar termenul self ca prim parametru. Este important de remarcat că & trebuie să precedă scurtătura self pentru a indica faptul că această metodă împrumută instanța Self, exact cum am procedat în rectangle: &Rectangle. Metodele pot lua posesia self, pot împrumuta self în mod imutabil, cum este cazul de față, sau pot împrumuta self în mod mutabil, exact ca în cazul oricărui alt parametru.
Am optat pentru &self din același motiv pentru care am folosit &Rectangle în cazul funcției: nu dorim să preluăm posesiunea și aspirăm să citim doar datele din structură, nu și să scriem în aceasta. Dacă intenția noastră ar fi fost să modificăm instanța pe care am invocat-o în cadrul metodei, am fi folosit &mut self ca prim parametru. Este destul de neobișnuit să avem o metodă care preia posesiunea instanței folosind doar self ca prim parametru. În mod obișnuit, ne folosim de acest procedeu când metoda transformă self în ceva diferit, iar scopul nostru este de a împiedica autorul apelului să folosească instanța originală după finalizarea transformării.
Motivul principal de a opta pentru metode în detrimentul funcțiilor, dincolo de a oferi sintaxa metodei și de a evita repetarea tipului self în fiecare semnătură a metodei, este legat de organizare. Practic, am concentrat într-un singur bloc impl tot ceea ce putem realiza cu o instanță a unui anumit tip. Astfel, nu obligăm viitorii utilizatori ai codului nostru să caute capacitățile Rectangle împrăștiate în diverse colțuri ale bibliotecii pe care o furnizăm.
Trebuie să reții că avem libertatea de a denumi o metodă identic cu unul dintre câmpurile structurii. De exemplu, putem defini o metodă în structura Rectangle și o putem numi tot width:
Numele fișierului: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn width(&self) -> bool { self.width > 0 } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; if rect1.width() { println!("The rectangle has a nonzero width; it is {}", rect1.width); } }
În acest caz, optăm să configurăm metoda width astfel încât să returneze true dacă valoarea din câmpul width al instanței este mai mare decât 0 și false în caz contrar, când valoarea este 0. Este important de subliniat faptul că avem libertatea de a utiliza un câmp în cadrul unei metode cu același nume, în funcție de necesități. De exemplu, în funcția main, atunci când denumirea rect1.width este urmată de paranteze, compilatorul Rust înțelege că ne referim la metoda width. În schimb, în absența parantezelor, Rust interpretează că ne referim la câmpul width.
Deși nu este întotdeauna cazul, frecvent, atunci când atribuim unei metode același nume cu un câmp, intenția este ca aceasta să returneze exclusiv valoarea din acel câmp, fără a efectua alte operații. Asemenea metode sunt denumite getteri. Este important de subliniat faptul că, spre deosebire de unele limbaje de programare, Rust nu generează în mod automat asemenea getteri pentru câmpurile structurilor. Getterii se dovedesc a fi utili deoarece permit transformarea câmpului într-unul privat și a metodei într-una publică, oferind astfel accesul în regim doar-de-citire a acelui câmp, rol ce intră în alcătuirea API-ului public al tipului respectiv. Conceptele de public și privat, precum și modalitatea de a desemna un câmp sau o metodă ca fiind publice sau private, vor fi detaliate în Capitolul 7.
Care este echivalentul operatorului
->în Rust?
În limbajele de programare C și C++, sunt folosiți doi operatori diferiți pentru apelarea metodelor: se utilizează
.atunci când metoda este apelată direct pe obiect, iar->este folosit dacă metoda este apelată pe un pointer către obiect, caz în care este necesar să se realizeze o dereferențiere a pointerului. Adică, dacăobjecteste un pointer, atunciobject->something()este similar cu(*object).something().Rust nu are un echivalent direct pentru operatorul
->. În schimb, oferă o caracteristică numită referențiere și dereferențiere automată. Această caracteristică este aplicată în contextul apelării metodelor, unul dintre puținele locuri în Rust unde se întâmplă acest lucru.Iată cum funcționează: când apelezi o metodă cu
object.something(), Rust include automat operatorii&,&mut, sau*pentru a se asigura căobjectcorespunde semnăturii metodei. Așadar, următoarele două apeluri de metode sunt echivalente:#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Point { x: f64, y: f64, } impl Point { fn distance(&self, other: &Point) -> f64 { let x_squared = f64::powi(other.x - self.x, 2); let y_squared = f64::powi(other.y - self.y, 2); f64::sqrt(x_squared + y_squared) } } let p1 = Point { x: 0.0, y: 0.0 }; let p2 = Point { x: 5.0, y: 6.5 }; p1.distance(&p2); (&p1).distance(&p2); }Primul mod de apelare pare mult mai elegant. Acest procedeu de referențiere automată este posibil datorită faptului că metodele au un receptor distinct - tipul
self. Cunoscând receptorul și numele unei metode, Rust poate deduce cu precizie dacă metoda este de citire (&self), modificare (&mut self), sau consumă (self) receptorul. Aceasta abordare implicită de împrumutare pentru receptorii de metode contribuie semnificativ la eficiența posesiunii în practică.
Metode cu parametri multipli
Să ne familiarizăm mai bine cu metodele prin crearea unei a doua metode în structura Rectangle. În acest caz, vrem ca o instanță a Rectangle să poată primi o altă instanță de Rectangle și să returneze true dacă al doilea Rectangle poate fi încorporat integral în interiorul primului (self); în caz contrar, ar trebui să returneze false. Mai pe scurt, după ce am definit metoda can_hold, dorim să fim în măsură să scriem programul prezentat în Listarea 5-14.
Numele fișierului: src/main.rs
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}Listarea 5-14: Apelarea metodei încă nedefinite can_hold
Avem următoarea ieșire anticipată, deoarece dimensiunile rect2 sunt mai mici decât cele ale lui rect1, pe când rect3 este mai lat decât rect1:
Can rect1 hold rect2? true
Can rect1 hold rect3? false
Știm că intenționăm să definim o metodă, așadar aceasta se va găsi în blocul impl Rectangle. Metoda se va numi can_hold, iar ca parametru va prelua un împrumut imutabil către un alt Rectangle. Tipul parametrului este deducibil inspectând codul care apelează metoda: rect1.can_hold(&rect2) transmite &rect2, adică un împrumut imutabil către rect2, o instanță a Rectangle. Acest lucru este logic, de vreme ce avem nevoie doar să citim rect2, nu să-l și scriem (în acest ultim caz, am avea nevoie de un împrumut mutabil). Mai mult, dorim ca main să-și păstreze posesiunea asupra rect2, pentru a putea folosi din nou instanța după ce apelăm metoda can_hold. Valoarea returnată de can_hold va fi de tip Boolean, iar implementarea va verifica dacă atât lățimea, cât și înălțimea instanței self, sunt mai mari decât cele corespunzătoare altui Rectangle. Acum putem adăuga noua metodă can_hold în blocul impl extras din Lista 5-13, și prezentat în Lista 5-15.
Numele fișierului: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; let rect2 = Rectangle { width: 10, height: 40, }; let rect3 = Rectangle { width: 60, height: 45, }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
Listarea 5-15: Implementăm metoda can_hold pentru Rectangle, aceasta acceptând o altă instanță Rectangle ca argument
Atunci când rulăm acest cod împreună cu funcția main prezentată în Listarea 5-14, obținem rezultatul scontat. Metodele pot accepta mai mulți parametri, pe care îi adăugăm în semnătură după parametrul self. Acești parametri se comportă exact ca parametrii standard din funcții.
Funcții asociate
Toate funcțiile care sunt definite în interiorul unui bloc impl poartă denumirea de funcții asociate, deoarece sunt legate de tipul ce este indicat după impl. Avem posibilitatea de a defini funcții asociate care nu au self drept prim parametru (acestea, prin urmare, nu sunt metode), întrucât nu necesită o instanță a respectivului tip pentru a putea funcționa. Deja am întâlnit o funcție de acest fel: funcția String::from, care este definită pentru tipul String.
Funcțiile asociate care nu sunt metode sunt frecvent utilizate în rol de constructori, aceștia având menirea de a returna o nouă instanță a unei structuri. În mod obișnuit, acestea poartă numele de new, dar new nu este un nume special sau implicit în limbaj. De exemplu, am putea opta să oferim o funcție asociată sub numele de square (pătrat), care să aibă un singur parametru ce reprezintă dimensiunea, utilizând-o atât pentru lățime, cât și pentru înălțime, simplificând astfel procesul de creare a unui dreptunghi Rectangle pătrat, fără a fi nevoie să introducem aceeași valoare de două ori.
Numele fișierului: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn square(size: u32) -> Self { Self { width: size, height: size, } } } fn main() { let sq = Rectangle::square(3); }
Cuvintele cheie Self, prezente atât în tipul de retur, cât și în corpul funcției, reprezintă alias-uri pentru tipul care urmează după cuvântul cheie impl. În acest context, acest tip este Rectangle.
Pentru a invoca această funcție asociată, utilizăm sintaxa :: împreună cu numele structurii. De exemplu, let sq = Rectangle::square(3);. Această funcție este asociată unui spațiu de nume definit de structura respectivă: sintaxa :: este folosită în ambele situații, atât pentru funcțiile asociate, cât și pentru spațiile de nume generate de module. Vom aborda subiectul modulelor în detaliu în Capitolul 7.
Multiple blocuri impl
Fiecare structură are permisiunea de a avea mai multe blocuri impl. De exemplu, codul din Listarea 5-15 corespunde cu cel prezentat în Listarea 5-16, unde fiecare metodă este separată în propriul său bloc impl.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } impl Rectangle { fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; let rect2 = Rectangle { width: 10, height: 40, }; let rect3 = Rectangle { width: 60, height: 45, }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
Listarea 5-16: Rescrierea Listării 5-15 utilizând mai multe blocuri impl
Deși în acest context nu există un motiv anume pentru a separa aceste metode în diverse blocuri impl, este important de menționat că aceasta este o sintaxă validă. Vom întâlni un caz de utilizare util pentru multiple blocuri impl în Capitolul 10, unde vom discuta despre tipurile generice și trăsături.
Sumar
Structurile permit crearea tipurilor personalizate relevante pentru domeniul în care lucrezi. Folosind structurile, poți menține conexiuni între diverse date asociate și le poți numi pe fiecare în parte, astfel încât codul tău să fie mai clar. În blocurile impl, poți defini funcții care sunt legate de tipul tău și metodele, care sunt un fel de funcții asociate și care îți permit să definești comportamentul pe care instanțele structurilor tale îl au.
Totuși, structurile nu sunt singura metodă de a crea tipuri personalizate: să ne îndreptăm atenția către caracteristica enum a limbajului Rust pentru a adăuga un nou instrument în trusa ta de unelte.
Enumerări și potrivirea modelelor
În cadrul acestui capitol, ne vom concentra asupra enumerărilor, sau cum sunt ele numite în mod obișnuit, enum. Enum-urile ne oferă posibilitatea de a defini un tip prin enumerarea variantelor sale posibile. Vom începe prin a defini și utiliza un enum pentru a ilustra cum putem încorpora atât sens, cât și date în cadrul unui enum. Ulterior, vom explora un exemplu specific de enum, numit Option, care exprimă ideea că o valoare poate reprezenta fie ceva, fie nimic. În continuare, vom analiza cum potrivirea modelelor în cadrul expresiei match ne facilitează posibilitatea de a executa diferite bucăți de cod, în funcție de valorile diferite pe care le poate lua un enum. În final, vom discuta despre cum construcția if let reprezintă un alt instrument convenabil și concis pe care îl avem la dispoziție pentru a manipula enum-urile în codul nostru.
Definirea unei enumerări
Structurile ne oferă o modalitate de a grupa câmpuri și date conexe. De exemplu, un Rectangle cu width și height. În contrast, enumerările ne permit să expresăm ideea că o valoare poate fi una dintre diversele opțiuni posibile. De pildă, am putea dori să specificăm că Rectangle este doar una dintre posibilele forme, care mai cuprinde și Circle și Triangle. Rust ne permite să transpunem aceste posibilități în cod prin intermediul unei enumerări.
Pentru a ilustra, să luăm în considerare o situație care ar avea nevoie să fie exprimată în cod pentru a înțelege de ce enumerările sunt utile și mai potrivite decât structurile. Să presupunem că dorim să lucrăm cu adrese IP. În prezent, există două standarde principale pentru adrese IP: versiunea patru și versiunea șase. Acestea sunt singurele variante de adrese IP cu care programul nostru va interacționa, deci putem enumera toate aceste variante, lucru de unde provine termenul de enumerare.
Orice adresă IP poate fi fie de versiunea patru, fie de versiunea șase, dar nu ambele simultan. Această caracteristică a adreselor IP face ca structura de date de tip enumerare să fie adecvată cazului nostru, pentru că o valoare de tip enumerare poate fi doar una dintre variantele sale. Adresele de versiunea patru și șase sunt, în esență, adrese IP, deci ar trebui considerate ca fiind de același tip atunci când codul gestionează situații care se aplică la ambele tipuri de adrese IP.
Acest concept poate fi transpus în cod prin definirea unei enumerări IpAddrKind și enumerarea tipurilor potențiale pe care o adresă IP le poate avea, adică V4 și V6. Acestea sunt variantele enumerării:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
Acum, IpAddrKind este un tip de date personalizat pe care îl putem utiliza în alte părți ale codului nostru.
Valori enum
Putem genera instanțe pentru ambele variante ale IpAddrKind astfel:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
Observă că variantele enum-ului sunt îngrădite în spațiul de nume al identificatorului său, iar noi utilizăm două puncte pentru a le separa. Acest aspect este util fiindcă, acum, ambele valori IpAddrKind::V4 și IpAddrKind::V6 sunt de același tip: IpAddrKind. Astfel, putem, de exemplu, să definim o funcție care poate primi orice IpAddrKind:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
Iar această funcție poate fi apelată cu oricare dintre variantele enumerate:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
Utilizarea enum-urilor aduce și mai multe beneficii. Dacă ne gândim mai atent la tipul adreselor noastre IP, momentan nu avem o modalitate de a stoca efectiv datele adreselor IP; cunoaștem doar tipul acestora. Dat fiind că tocmai ai aflat despre structuri în Capitolul 5, ai putea fi tentat să soluționezi această problemă utilizând structurile, așa cum este exemplificat în Listarea 6-1.
fn main() { enum IpAddrKind { V4, V6, } struct IpAddr { kind: IpAddrKind, address: String, } let home = IpAddr { kind: IpAddrKind::V4, address: String::from("127.0.0.1"), }; let loopback = IpAddr { kind: IpAddrKind::V6, address: String::from("::1"), }; }
Listarea 6-1: Încapsularea datelor și a variantei IpAddrKind
ale unei adrese IP folosind o structură
În aceste rânduri, am definit o structură numită IpAddr. Aceasta conține două câmpuri: un câmp kind, care este de tip IpAddrKind (enumerarea pe care am stabilit-o mai devreme) și un câmp address de tip String. Avem două instanțe ale acestei structuri. Prima se numește home și cuprinde valoarea IpAddrKind::V4 atribuită câmpului kind, având asociată adresa 127.0.0.1. Cea de-a doua instanță, loopback, conține cealaltă variantă a IpAddrKind pentru câmpul kind, respectiv V6, și este asociată cu adresa ::1. Am utilizat o structură pentru a grupa valorile kind și address, astfel încât acum varianta este legată direct de valoarea ei.
Cu toate acestea, putem exprima același concept într-un mod mai concis doar cu ajutorul unei enumerări: în loc să încapsulăm o enumerare într-o structură, putem plasa datele direct în fiecare variantă a enumeraței. Această nouă definiție a enumerației IpAddr indică faptul că ambele variante V4 și V6 vor fi asociate cu valori de tip String:
fn main() { enum IpAddr { V4(String), V6(String), } let home = IpAddr::V4(String::from("127.0.0.1")); let loopback = IpAddr::V6(String::from("::1")); }
Atașăm datele direct variantei respective a enum-ului, astfel eliminând necesitatea unei structuri suplimentare. Tot aici, este mult mai simplu să înțelegem un alt aspect legat de funcționarea enum-urilor: numele fiecărei variante de enum pe care o definim se transformă de asemenea într-o funcție ce construiește o instanță a acelui enum. Adică, IpAddr::V4() reprezintă un apel de funcție care primește un argument de tip String și returnează o instanță a tipului IpAddr. Obținem în mod automat această funcție constructor ca rezultat al definirii enum-ului.
Mai există un avantaj în utilizarea unui enum în locul unei structuri: fiecare variantă poate avea diferite tipuri și cantități de date asociate. Adresele IP de versiunea patru vor avea mereu patru componente numerice cu valori între 0 și 255. Dacă am dori să stocăm adresele V4 sub forma a patru valori u8, dar să reprezentăm în același timp adresele V6 sub forma unei valori String, aceasta nu ar fi posibilă cu o structură. Cu toate acestea, enum-urile gestionează cu ușurință acest caz:
fn main() { enum IpAddr { V4(u8, u8, u8, u8), V6(String), } let home = IpAddr::V4(127, 0, 0, 1); let loopback = IpAddr::V6(String::from("::1")); }
Am prezentat mai multe metode prin care se pot defini structurile de date pentru a stoca adresele IP de versiunea patru și versiunea șase. Cu toate acestea, se pare că necesitatea de a stoca adrese IP și de a indica tipul lor este atât de frecventă încât însăși biblioteca standard include o definiție pe care o putem utiliza! Să ne uităm cum biblioteca standard definește IpAddr: aceasta conține aceeași enumerare și variante pe care noi le-am definit și utilizat, însă datele adresei sunt incluse în variante sub forma a două structuri diferite, definite în mod distinct pentru fiecare variantă:
#![allow(unused)] fn main() { struct Ipv4Addr { // --snip-- } struct Ipv6Addr { // --snip-- } enum IpAddr { V4(Ipv4Addr), V6(Ipv6Addr), } }
Acest cod exemplifică faptul că într-o variantă de enumerare se pot integra variate tipuri de date, fie ele string-uri, numere sau structuri. Se poate chiar insera și o altă enumerare. În plus, tipurile din biblioteca standard nu sunt de regulă mult mai complexe decât cele pe care le-ai putea elabora tu.
Deși biblioteca standard posedă o definiție pentru IpAddr, noi avem capacitatea de a crea și utiliza propria noastră definiție pentru IpAddr, fără a întâlni conflicte. Aceasta deoarece nu am importat definiția provenită din biblioteca standard în domeniul nostru de vizibilitate. Profundăm discuția despre cum se importă tipuri în domeniul de vizibilitate în Capitolul 7.
Să analizăm un alt exemplu de enumerare, ce poate fi găsit în Listarea 6-2. Aici observăm o diversitate mare de tipuri incluse în variantele enumerării.
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() {}
Listarea 6-2: Enum-ul Message are variante ce stochează cantități și tipuri diferite de valori
Acest enum conține patru variante de tipuri diferite:
Quitnu are asociat niciun fel de date.Moveconține câmpuri numite, similar unei structuri.Writeinclude un singurString.ChangeColorinclude trei valori de tipi32.
Crearea unui enum cu variante cum sunt cele din Listarea 6-2 se aseamănă cu definirea diferitelor tipuri de structuri, dar cu câteva diferențe: enum nu folosește cuvântul cheie struct și toate variantele sunt grupate sub tipul Message. Structurile enumerate mai jos ar putea reține aceleași date ca și variantele enum-ului menționate anterior:
struct QuitMessage; // unit struct struct MoveMessage { x: i32, y: i32, } struct WriteMessage(String); // tuple struct struct ChangeColorMessage(i32, i32, i32); // tuple struct fn main() {}
Dacă am utiliza structuri diferite, fiecare având propriul său tip, ar fi mai dificil să definim o funcție care poate accepta oricare dintre aceste tipuri de mesaje. În schimb, prin intermediul enum-ului Message, definit în Listarea 6-2, putem realiza acest lucru mult mai simplu deoarece Message reprezintă un singur tip.
Enum-urile și structurile mai au o similitudine: așa cum definim metode pe structuri utilizând impl, tot așa putem defini metode și pe enum-uri. Să luăm de exemplu metoda numită call, pe care am putea să o definim pentru enum-ul nostru Message:
fn main() { enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } impl Message { fn call(&self) { // method body would be defined here } } let m = Message::Write(String::from("hello")); m.call(); }
În corpul metodei utilizăm self pentru a obține valoarea pe care am invocat metoda. În acest exemplu, am creat variabila m cu valoarea Message::Write(String::from("hello")), iar aceasta va reprezenta self în corpul metodei call când se execută instrucțiunea m.call().
Să examinăm și un alt enum foarte comun și util din biblioteca standard, numit Option.
Enum-ul Option și superioritatea sa față de valorile null
Această secțiune urmărește un studiu de caz al Option, care reprezintă o altă enumerare definită înlăuntrul librăriei standard. Tipul Option reflectă scenariul întâlnit frecvent în care o valoare poate exista sau poate absenta.
De exemplu, dacă ai solicita primul element dintr-o listă ce conține elemente, ai obține o valoare. În schimb, dacă ai solicita primul element dintr-o listă goală, nu ai obține nimic. Transpunerea acestui concept în sistemul de tipuri permite compilatorului să verifice dacă ai tratat toate cazurile pe care ar trebui să le gestionezi; această funcționalitate poate contribui la prevenirea apariției unor erori extrem de comune în alte limbaje de programare.
Designul unui limbaj de programare este adesea gândit în contextul funcțiilor pe care le adaugi, dar funcțiile pe care le ignori sunt la fel de importante. Rust nu dispune de opțiunea null pe care multe alte limbaje o oferă. Null este o valoare care indică lipsa unui răspuns sau a unei valori valide. În limbajele care permit valori null, variabilele pot exista mereu într-una din cele două stări: null sau non-null.
În discursul său din 2009, intitulat "Referințe Nule: Eroarea de un miliard de dolari", Tony Hoare, părintele conceptului de null, exprima astfel:
Aceasta este greșeala mea de un miliard de dolari. Atunci, în acel moment, eram la etapa de proiectare a primului sistem complet de tipuri pentru referințe în cadrul unui limbaj orientat pe obiecte. Misiunea pe care mi-o asumasem era să garantez că orice utilizare a referințelor va fi absolut sigură, cu verificări efectuate automat de către compilator. Cu toate acestea, tentația de a introduce o referință nulă, deoarece era atât de simplu de realizat, a fost irezistibilă. Aceasta a condus la un număr inestimabil de erori, vulnerabilități și sisteme care s-au prăbușit, provocând, probabil, prejudicii de un miliard de dolari în ultimele patru decenii.
Problema cu valorile nule constă în faptul că, atunci când încerci să folosești o valoare nulă ca și cum ar fi una nenulă, inevitabil vei întâlni o eroare. Această caracteristică de null sau non-null este atât de răspândită, încât este extrem de ușor să comiți acest tip de eroare.
Totuși, conceptul pe care valoarea null îl reprezintă este în continuare unul esențial: un null reprezintă o valoare care este, temporar, nevalidă sau menținută absentă, dintr-un anumit motiv.
Problema nu este cu conceptul în sine, ci mai degrabă cu modul său specific de implementare. Prin urmare, Rust nu conține valori null, dar dispune de o enumerare care poate exemplifica ideea de prezență sau absență a unei valori. Această enumerare este Option<T>, definită în biblioteca standard astfel:
#![allow(unused)] fn main() { enum Option<T> { None, Some(T), } }
Enumerarea Option<T> este atât de folositoare încât este inclusă chiar și în preludiu, nu necesită a fi adusă explicit în domeniul de vizibilitate. Variantele sale sunt de asemenea incluse în preludiu: poți folosi Some și None direct, fără a avea nevoie de prefixul Option::. Enumerarea Option<T> rămâne doar o enumerare obișnuită, iar Some(T) și None sunt în continuare variantele sale, de tip Option<T>.
Sintaxa <T> este o caracteristică a Rust pe care nu am discutat-o încă. Este un parametru de tip generic, despre care vom vorbi în amănunt în Capitolul 10. Deocamdată, trebuie doar să știi că <T> semnifică faptul că varianta Some a enumerării Option poate conține o dată de orice tip, iar fiecare tip concret care este utilizat în locul lui T transformă tipul global Option<T> într-un tip diferit. Iată câteva exemple de utilizare a valorilor Option pentru a reține tipuri de numere și de șiruri de caractere:
fn main() { let some_number = Some(5); let some_char = Some('e'); let absent_number: Option<i32> = None; }
Tipul variabilei some_number este Option<i32>. În contrast, some_char este de tip Option<char>, deci avem de-a face cu un tip diferit. Rust este capabil să deducă aceste tipuri fără nicio intervenție din partea noastră datorită faptului că am specificat deja o valoare în varianta Some. În cazul lui absent_number, lucrurile sunt un pic diferite. Aici, Rust ne solicită să adnotăm explicit tipul Option principal: compilatorul nu poate deduce tipul pe care variantul Some îl va deține doar uitându-se la o valoare None. De aceea, în acest context, îi comunicăm noi explicit lui Rust că intenționăm ca absent_number să fie de tip Option<i32>.
Când lucrăm cu o valoare Some, știm că avem o valoare prezentă și că aceasta se află în interiorul Some. În contrast, când avem o valoare None, semnifică într-un fel același lucru ca și null: nu dispunem de o valoare validă. Dar de ce ar fi mai avantajos să folosim Option<T> în locul lui null?
Pe scurt, avantajul de a lucra cu Option<T> în loc de null ține de faptul că Option<T> și T (unde T poate fi orice tip) reprezintă tipuri diferite. De-oarece avem de a face cu tipuri diferite, compilatorul nu ne va permite să utilizăm o valoare Option<T> ca și cum am fi absolut siguri că ea conține o valoare validă. De exemplu, codul următor nu va compila, deoarece încearcă să adauge un i8 la un Option<i8>:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
}Dacă rulăm acest cod, vom primi un mesaj de eroare similar cu acesta:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let sum = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
<&'a i8 as Add<i8>>
<&i8 as Add<&i8>>
<i8 as Add<&i8>>
<i8 as Add>
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` due to previous error
Intens! Acesta ne spune că Rust nu poate efectua operația de adunare între un i8 și un Option<i8>, deoarece acestea sunt de tipuri diferite. În Rust, atunci când lucrăm cu o valoare de tip i8, compilatorul se asigură că valoarea respectivă este întotdeauna validă. Prin urmare, putem utiliza valoarea respectivă fără a fi nevoie să verificăm în prealabil dacă aceasta este null. Problemele apar doar atunci când avem de-a face cu un Option<i8> (sau orice alt tip de valoare). În acest caz, este posibil să nu avem o valoare validă, iar compilatorul se va asigura că vom trata acest caz corect înainte de a folosi valoarea respectivă.
Altfel spus, pentru a putea efectua operațiuni cu Option<T>, va trebui mai întâi să-l convertim la T. Această regulă ne ajută să depistăm una dintre problemele cele mai comune legate de valoarea null: presupunerea că o anumită valoare nu poate fi null, când de fapt aceasta poate fi.
Faptul că putem elimina riscul de a presupune incorect că o valoare nu este null ne conferă mai multă încredere în corectitudinea codului nostru. De asemenea, pentru a putea avea o valoare care să poată fi eventual null, trebuie să optăm explicit pentru tipul de valoare Option<T>. Ulterior, la utilizarea acestei valori, vom fi nevoiți să tratăm explicit cazul în care valoarea este null. Oriunde avem o valoare al cărei tip nu este Option<T>, putem presupune în siguranță că valoarea respectivă nu este null. Aceasta este o decizie deliberată de proiectare a limbajului Rust, menită să limiteze prevalența valorilor null și să crească siguranța codului scris în Rust.
Acum să vedem cum putem extrage valoarea T dintr-un Option<T> de tip Some, astfel încât să o putem folosi. Enumerația Option<T> dispune de o serie de metode utile în diverse contexte, pe care le poți vedea în documentația acestora. Cunoașterea metodelor variabilei Option<T> va fi extrem de importantă pe parcursul călătoriei tale cu Rust.
În general, pentru a folosi o valoare Option<T>, va trebui să scrii un cod care să poată trata fiecare variantă. Vei avea nevoie de un cod ce se va executa doar atunci când ai o valoare Some(T), iar acesta va putea folosi valoarea T internă. În același timp, vei avea nevoie de un alt cod ce se va executa doar dacă ai o valoare None, iar acesta nu va avea acces la o valoare T. Expresia match este un construct al fluxului de control care, atunci când este folosită cu enumerări, ne permite să rulăm cod diferit în funcție de tipul variantelor, având posibilitatea de a utiliza datele din interiorul valorii potrivite.
Structura de control match
Rust dispune de o structură de control extrem de puternică numită match, care permite compararea unei valori cu o serie de șabloane și executarea codului în funcție de șablonul care se potrivește. Șabloanele pot fi realizate din valori literale, nume de variabile, wildcard-uri și multe altele. Capitolul 18 acoperă toate aspectele referitoare la șabloane și funcționalitatea acestora. Puterea lui match vine din expresivitatea șabloanelor și faptul că compilatorul verifică dacă toate cazurile posibile sunt gestionate.
O expresie match poate fi înțeleasă ca o mașină de sortat monede: monedele alunecă pe o pistă cu găuri de diferite mărimi iar fiecare monedă cade prin prima gaură în care se încadrează. Similar, valorile parcurg fiecare șablon într-un match, iar la primul șablon unde valoarea se "potrivește", ea este redirecționată în blocul de cod asociat pentru a fi utilizat în timpul execuției.
Luând exemplul monedelor, putem crea o funcție care primește o monedă necunoscută din SUA și, asemenea mașinii de numărat, determină tipul monedei și returnează valoarea acesteia în cenți, așa cum se arată în Listarea 6-3.
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } fn main() {}
Listarea 6-3: O enumerare și o expresie match ce include variantele enum ca șabloane
Să analizăm match în funcția value_in_cents. Începând, scriem cuvântul-cheie match urmat de o expresie, în acest caz, valoarea coin. Aceasta poate părea similară cu o expresie condițională folosită împreună cu if, dar există o diferență semnificativă: dacă în cazul if condiția trebuie să evalueze o valoare Booleană, aici, poate fi orice tip. coin în acest exemplu este enum-ul Coin pe care l-am definit în prima linie.
Apoi, avem ramurile match. Fiecare ramură conține două părți: un șablon și un cod. Prima ramură are un șablon care corespunde valorii Coin::Penny și apoi operatorul => care separă șablonul de codul care trebuie executat. În acest caz, codul este doar valoarea 1. Fiecare ramură este separată de cea următoare printr-o virgulă.
Când expresia match se execută, valoarea rezultată se compară cu șablonul fiecărei ramuri, în ordine. Dacă un șablon corespunde valorii, codul asociat cu acel șablon este executat. Dacă șablonul nu se potrivește valorii, execuția continuă la următoarea ramură, similar cu mașina de sortat monede. Putem avea câte ramuri dorim: în Listarea 6-3, match-ul nostru are patru ramuri.
Codul asociat fiecărei ramuri este o expresie, iar valoarea rezultată din expresia ramurii care se potrivește este returnată pentru întreaga expresie match.
Nu folosim, de regulă, acolade dacă codul ramurii match este scurt, așa cum se vede în Listarea 6-3, unde fiecare ramură returnează doar o valoare. Dacă dorești să execuți mai multe linii de cod într-o ramură match, trebuie să folosești acolade, iar virgula care urmează ramurii devine atunci opțională. De exemplu, în codul de mai jos textul "Penny norocos!" este afișat de fiecare dată când metoda este apelată cu Coin::Penny, totuși, ultima valoare a blocului, 1, este returnată:
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => { println!("Lucky penny!"); 1 } Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } fn main() {}
Șabloane ce se leagă de valori
O altă particularitate valoroasă a segmentelor match este că ele pot încorpora elementele valorilor care corespund cu șablonul definit. Exact în acest mod putem desprinde valori din variantele unei enumerări.
Pentru exemplificare, modificăm una dintre variantele enumerării noastre, astfel încât să cuprindă date. În perioada 1999 - 2008, Statele Unite ale Americii au emis monede "quarter" personalizate, cu design-uri distincte pentru fiecare dintre cele 50 de state. Niciun alt tip de monedă nu a primit acest tratament special, de aceea doar "quarter"-urile au această extra valoare. Putem îngloba această informație în enumerarea noastră prin modificarea variantei Quarter, astfel încât să includă o valoare UsState în interiorul ei, așa cum am făcut în Listarea 6-4.
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() {}
Listare 6-4: O enumerare Coin în care și varianta Quarter deține o valoare UsState
Să presupunem că un prieten se străduiește să colecționeze monedele "quarter" pentru toate cele 50 de state. În timp ce noi sortăm restul de monede după tip, vom menționa și numele statului asociat cu fiecare "quarter", astfel încât, dacă este una pe care prietenul nostru nu o deține, să o poată adăuga în colecția sa.
În expresia match pentru acest segment de cod, adăugăm o variabilă numită state la șablon, care se potrivește cu valorile variantei Coin::Quarter. Când un Coin::Quarter se potrivește, variabila state se va lega de valoarea statului respectivului "quarter". Apoi putem utiliza state în codul specfic acelui segment din match, astfel:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter(state) => { println!("State quarter from {:?}!", state); 25 } } } fn main() { value_in_cents(Coin::Quarter(UsState::Alaska)); }
Dacă am apela value_in_cents(Coin::Quarter(UsState::Alaska)), coin ar fi Coin::Quarter(UsState::Alaska). Când comparam valoarea aceasta cu fiecare segment al match-ului, niciunul nu se potrivește până la segmentul Coin::Quarter(state). În acest punct, legătura pentru state va fi valoarea UsState::Alaska. Putem folosi apoi acea legătură în expresia println!, extrăgând astfel valoarea internă a statului din varianta "Quarter" din enumerarea Coin.
Corelarea cu Option<T>
În secțiunea precedentă, am aspirat să extragem valoarea internă T din variantă Some, folosind structura Option<T>. În ciuda schimbării obiectului de la enum Coin la Option<T>, funcționarea expresiei match rămâne neschimbată.
Consideră că avem nevoie de o funcție care acceptă ca parametru o structură Option<i32>. Rolul ei este de a adaugă 1 la valoarea conținută, dacă aceasta există. În caz negativ, funcția nu ar trebui să execute nicio operație și să returneze None.
Având la dispoziție expresia match, implementarea funcției devine extrem de simplă și intuitivă, asemenea exemplelor prezentate în Lista 6-5.
fn main() { fn plus_one(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), } } let five = Some(5); let six = plus_one(five); let none = plus_one(None); }
Listarea 6-5: O funcție care utilizează o expresie match pe variabila Option<i32>
Să examinăm cu mai multă atenție prima execuție a plus_one. Atunci când invocăm plus_one(five), variabila x din interiorul funcției plus_one va primi valoarea Some(5). Aceasta este apoi comparată cu fiecare ramură din instrucțiunea match:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Valoarea Some(5) nu corespunde modelului None, așa că trecem mai departe la următoarea ramură:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Se potrivește Some(5) cu Some(i)? Chiar se potrivește! Avem aceeași variantă. Simbolul i se leagă apoi de valoarea stocată în Some, astfel că i devine 5. Codul din această ramură match este executat, deci adăugăm 1 la valoarea lui i și producem o nouă valoare Some care încapsulează rezultatul nostru, 6.
Analizăm acum a doua apelare a funcției plus_one din Listarea 6-5, unde x este None. Pătrundem în interiorul match pentru a compara cu prima ramură:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Într-adevăr, se potrivește! Nu există o valoare la care să adăugăm, așadar programul încetează și returnează valoarea None aflată în partea dreaptă a =>. De vreme ce prima ramură s-a potrivit, nicio altă ramură nu va mai fi evaluată.
Folosirea împreună a match și a enumerărilor este extrem de utilă în numeroase situații. Astfel de constructe îți vor fi familiare în lucrul tău cu Rust: match asociat unui enum, creare de legături cu o variabilă către datele interne și apoi execuția codului în funcție de aceasta. Deși poate părea complex la început, pe măsură ce te obișnuiești cu acesta, vei începe să îți dorești ca acesta să fie disponibil în toate limbajele de programare. Nu întâmplător este unul dintre cele mai îndrăgite caracteristici ale limbajului de către comunitatea de utilizatori.
Corelările de tip match sunt exhaustive
Mai există un aspect important legat de sintaxa match: șabloanele asociate fiecărei ramuri din match trebuie să acopere toate scenariile posibile. Să luăm în considerare o versiune modificată a funcției noastre plus_one, care conține o eroare și, prin urmare, nu va reuși să compileze:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Am omis gestionarea cazului None, deci acest cod implicit va conține o eroare. Din fericire, aceasta este o eroare pe care Rust o poate identifica. Dacă încercăm să compilăm acest cod, vom întâmpina următoarea eroare:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/option.rs:518:1
|
= note:
/rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/option.rs:522:5: not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` due to previous error
Rust e conștient că nu am cuprins fiecare scenariu posibil și indică inclusiv șablonul pe care l-am omis! Corelările de șabloane din Rust sunt exhaustive: trebuie să epuizăm fiecare posibilitate pentru ca codul să fie considerat valid. În special în cazul Option<T>, atunci când Rust ne împiedică să trecem cu vederea cazul None, ne protejează de a face presupuneri incorecte - că avem o valoare, când de fapt ne-am putea confrunta cu o valoare null. Astfel, se evită genul de eroare costisitoare pe care l-am discutat mai devreme.
Șabloane universale și substituentul _
Prin intermediul enumerărilor, putem declanșa acțiuni specifice pentru unele valori speciale, dar pentru restul valorilor vom adopta o acțiune prestabilită. Imaginați-vă că implementăm un joc în care, dacă la o aruncare de zar iese 3, jucătorul nu se mișcă, ci primește o pălărie nouă și elegantă. Dacă zarul arată 7, jucătorul își pierde pălăria elegantă. Pentru orice altă valoare, jucătorul avansează pe tabla de joc cu numărul de spații egal cu valoarea zarului. Iată o implementare cu match a aceastei logici, unde rezultatul aruncării cu zarul este hardcoded, în locul unei valori aleatorii, iar restul logicii este reprezentat de funcții fără corpuri deoarece actuala implementare nu intră în sfera acestui exemplu:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), other => move_player(other), } fn add_fancy_hat() {} fn remove_fancy_hat() {} fn move_player(num_spaces: u8) {} }
Pentru primele două ramuri, șabloanele sunt valoriile exacte 3 și 7. Pentru ultima ramură care acoperă toate celelalte valori posibile, șablonul este variabila pe care am ales-o cu numele other. Codul ce rulează pentru ramura other utilizează această variabilă, trimițând-o către funcția move_player.
Acest cod este valid și se va compila, chiar dacă nu am enumerat explicit toate valorile pe care tipul u8 le poate avea, deoarece ultimul șablon este conceput să acopere toate aceste situații. Acest șablon universal satisface cerința ca match să fie exhaustiv. Este important de reținut că acest șablon universal trebuie plasat ultimul, pentru că șabloanele sunt evaluate în ordinea în care au fost scrise. Dacă am adăuga acest șablon universal mai devreme, celelalte ramuri nu ar mai fi accesate, de aceea Rust ne va da o alertă dacă încercăm să adăugăm alte ramuri după șablonul universal!
Rust pune la dispoziție un șablon numit _, pe care îl putem folosi atunci când dorim să implementăm un mecanism universal, însă nu suntem interesați să utilizăm valoarea pe care o captează acest mecanism. Acest șablon special se potrivește cu orice valoare și nu realizează o legătură cu acea valoare, ceea ce indică faptul că nu avem de gând să o utilizăm. Rust ne scutește de avertismentul privind o variabilă neutilizată în acest context.
Analizăm acum un scenariu în care schimbăm regulile jocului: dacă rulezi alt rezultat decât un 3 sau un 7, va trebui să rulezi din nou zarul. Ne putem dispensa de utilizarea valorii universale, deci putem modifica codul pentru a utiliza _ în locul variabilei denumite other:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), _ => reroll(), } fn add_fancy_hat() {} fn remove_fancy_hat() {} fn reroll() {} }
Acest exemplu îndeplinește și cerința de exhaustivitate, întrucât ignorăm în mod explicit toate celelalte valori în ultimul braț al structurii de control; nu am omis nimic.
Urcăm miza și schimbăm regulile jocului o dată în plus: nimic nu se va întâmpla în tura ta dacă rolezi un rezultat care nu este nici 3, nici 7. Putem exprima acest lucru prin utilizarea valorii unit (tipul de tuplă vidă despre care am vorbit în secțiunea “Tipul tuplă”), value care să fie asociată brațului de cod _:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), _ => (), } fn add_fancy_hat() {} fn remove_fancy_hat() {} }
Aici, clarificăm explicit că nu intenționăm să folosim orice altă valoare care nu corespunde unui șablon dintr-un braț anterior, și că nu dorim să se execute vreun cod în acest caz.
Vom aprofunda modul în care funcționează șabloanele și mecanismul de potrivire a acestora în Capitolul 18. Deocamdată, ne vom concentra pe sintaxa if let, utilă în situațiile în care expresia match pare a fi prea stufoasă.
Control concis al executării cu if let
Sintaxa if let îți oferă posibilitatea de a combina if și let pentru a manipula, într-un mod mai concis, valorile care corespund unui anumit șablon, ignorând în același timp restul. Ia în considerare programul din Listarea 6-6, care creează o potrivire pentru o valoare Option<u8> în variabila config_max, dar care intenționează să execute codul doar dacă valoarea este variantă Some.
fn main() { let config_max = Some(3u8); match config_max { Some(max) => println!("The maximum is configured to be {}", max), _ => (), } }
Listarea 6-6: Un match care este interesat doar de execuția
codului atunci când valoarea este Some
Dacă valoarea este Some, afișăm valoarea din variantă Some prin asocierea acesteia cu variabila max în șablon. Nu dorim să facem nimic cu valoarea None. Pentru a respecta cerințele expresiei match, suntem obligați să adăugăm _ => () după procesarea unei singure variante, ceea ce des reprezintă un cod suplimentar, inutil și iritant.
În loc să abordăm problema în modul complicat, putem simplifica procesul folosind if let. Următorul fragment de cod funcționează identic cu instrucțiunea match prezentată în Listarea 6-6:
fn main() { let config_max = Some(3u8); if let Some(max) = config_max { println!("The maximum is configured to be {}", max); } }
Sintaxa if let preia un șablon și o expresie, separate de un semn de egalitate. Funcționează în mod similar cu match, unde expresia este atribuită instrucțiunii match, iar șablonul constituie prima sa ramură. În acest caz, șablonul este Some(max), iar max se leagă de valoarea din interiorul Some. Apoi, putem utiliza max în corpul blocului if let, la fel cum am folosit max în ramura corespunzătoare a instrucțiunii match. Codul din blocul if let nu se execută dacă valoarea nu corespunde șablonului.
Folosind if let, vor rezulta mai puține caractere introduse, mai puțină indentare și mai puțin cod redundant. Totuși, pierdem verificarea completă pe care instrucțiunea match o asigură. Alegerea între match și if let depinde de natura situației cu care te confrunți și dacă economisirea spațiului este un compromis acceptabil pentru a nu realiza o verificare exhaustivă.
Cu alte cuvinte, poți percepe if let drept un zahăr sintactic pentru un match care rulează codul atunci când valoarea corespunde cu un anumit șablon, ignorând toate celelalte valori.
Avem posibilitatea de a include un else în structura if let. Blocul de cod alăturat lui else este identic cu cel care ar apărea în cazul _ în expresia match, expresie care este echivalentă cu structura if let și else. Acum să-ți reamintim de definiția enumerării Coin din listarea 6-4, unde varianta Quarter deține, de asemenea, o valoare UsState. Dacă vom dori să numărăm toate monedele care nu sunt de tipul quarter, dar și să anunțăm starea acestora, putem realiza acest lucru cu ajutorul unei expresii match, astfel:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let coin = Coin::Penny; let mut count = 0; match coin { Coin::Quarter(state) => println!("State quarter from {:?}!", state), _ => count += 1, } }
Sau am putea folosi o expresie if let și else, în felul următor:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let coin = Coin::Penny; let mut count = 0; if let Coin::Quarter(state) = coin { println!("State quarter from {:?}!", state); } else { count += 1; } }
Dacă te afli în situația în care logica din programul tău este prea complexă pentru a fi exprimată folosind un match, nu uita că if let este și el un instrument util în limbajul Rust.
Sumar
Am tratat felul în care putem folosi enumerările pentru a crea tipuri personalizate care pot avea una dintre o mulțime de valori enumerate. Am evidențiat felul în care tipul Option<T> din biblioteca standard ne ajută a preveni erorile prin folosirea sistemului de tipuri. Atunci când valorile enumerărilor conțin date, putem utiliza match sau if let pentru a extrage și folosi acele valori, în funcție de numărul de cazuri pe care trebuie să le gestionăm.
Acum, programele tale Rust sunt capabile să exprime conceptele specifice domeniului tău folosind structuri și enumerări. Crearea de tipuri personalizate pentru utilizare în API-ul tău garantează securitatea tipurilor: compilatorul se va asigura că funcțiile tale primesc doar valori ale tipului așteptat de fiecare funcție.
Cu scopul de a oferi utilizatorilor tăi un API bine structurat, ușor de utilizat și care expune doar ceea ce aceștia realmente necesită, să ne focusăm acum pe modulele din Rust.
Administrarea proiectelor în expansiune cu ajutorul pachetelor, crate-urilor și modulelor
Compunerea programelor de amploare invocă o importanță crescută asupra organizării codului tău. Grupând funcționalitățile corelate și separând codul cu particularități distincte, vei desluși unde să identifici codul care susține o anumită caracteristică și unde să intervii pentru a modifică cum acea caracteristică funcționează.
Până în prezent, programele pe care le-am creat au fost cuprinse într-un singur modul, într-un singur fișier. Odată cu expansiunea unui proiect, este esențial să organizezi codul împărțindu-l în diverse module și ulterior într-o multitudine de fișiere. Un pachet poate cuprinde multiple crate-uri binare și eventual un crate de bibliotecă. Odată cu dezvoltarea unui pachet, poți desprinde diverse componente în crate-uri distincte care vor deveni dependențe externe. Acest capitol îți prezintă toate aceste procedee. Pentru proiectele de o amploare considerabilă, compuse dintr-un ansamblu de pachete interconectate care evoluează împreună, Cargo oferă spațiile de lucru (workspaces), pe care le vom descrie în secțiunea „Spații de lucru Cargo” din Capitolul 14.
De asemenea, vom aborda subiectul încapsulării detaliilor de implementare. Acesta este un instrument esențial care îți permite să reutilizezi codul la un nivel superior. Odată ce ai implementat o operațiune, alt cod poate interacționa cu implementarea ta prin intermediul interfeței publice, fără a trebui să înțeleagă complexitatea acesteia. Modul în care structurezi codul stabilește care părți sunt accesibile altor bucăți de cod (publice) și care părți sunt detalii private ale implementării, pe care ai dreptul de a le modifica. Aceasta este o altă cale de a restrânge cantitatea de detalii pe care trebuie să o reții.
Un concept strâns legat este cel de domeniu de vizibilitate. Acesta se referă la contextul în care codul este scris, unde un set de nume sunt definite ca fiind „în domeniul de vizibilitate”. Atunci când se citește, scrie sau compilează cod, atât programatorii, cât și compilatoarele trebuie să știe dacă un anumit nume, într-un anumit context, se referă la o variabilă, o funcție, o structură, o enumerare, un modul, o constantă, sau alt element și ce semnificație are acel element. Ai libertatea de a crea domenii de vizibilitate și de a schimba ce nume sunt sau nu în vigoare. În același domeniu de vizibilitate, nu poți folosi același nume pentru două entități distincte, dar există unelte care te pot ajuta să rezolvi astfel de conflicte de nume.
Rust dispune de o varietate de funcții care îți facilitează gestionarea structurii codului, incluzând nivelul de accesibilitate a detaliilor, gradul de protecție al acestora, precum și gestionarea numelor din fiecare domeniu de vizibilitate din programele tale. Aceste facilități, adesea denumite în ansamblu ca sistemul de module, cuprind:
- Pachetele: O caracteristică proprie Cargo care îți permite să creezi, testezi și să distribui crate-uri.
- Crate-urile: Reprezintă un arbore de module ce produce o librărie sau un executabil.
- Modulele și utilizarea: Permite controlul asupra organizării, domeniului de vizibilitate și privației căilor.
- Căile: O modalitate de a denumi un element, precum o structură, o funcție sau un modul.
În cadrul acestui capitol, vom trece în revistă toate aceste facilități, vom discuta interacțiunea dintre ele și vom explica modul în care pot fi utilizate în gestionarea domeniului de vizibilitate. La final, vei avea o înțelegere profundă a sistemului de module și vei putea lucra cu domeniile de vizibilitate precum un expert!
Pachete și crate-uri
Începem explorarea sistemului de module cu pachete și crate-uri.
Un crate reprezintă unitatea minimă de cod pe care compilatorul Rust o procesează la un moment dat. Chiar dacă alegi să rulezi rustc în loc de cargo și transmiți un singur fișier sursă (așa cum am făcut în capitolul 1, la secțiunea "Scrierea și Rularea unui Program în Rust"), compilatorul tratează acel fișier ca fiind un crate. Un crate poate include module, iar aceste module pot fi definite în alte fișiere care sunt compilate împreună cu crate-ul, așa cum vom vedea în secțiunile următoare.
Există două tipuri de crate-uri: crate-uri binare și crate-uri de bibliotecă. Crate-urile binare sunt programe pe care le poți compila în fișiere executabile pe care poți să le rulezi, precum ar fi un program de linie de comandă sau un server. Fiecare crate binar trebuie să aibă o funcție numită main care definește comportamentul său atunci când este rulat. Toate crate-urile pe care le-am creat până acum au fost crate-uri binare.
Crate-urile de bibliotecă nu dispun de o funcție main și nu se compilează sub formă de executabil. Acestea conțin funcționalități concepute pentru a fi utilizate în comun de diferite proiecte. De pildă, crate-ul rand, pe care l-am utilizat în Capitolul 2, furnizează funcționalitatea de a genera numere aleatorii. De cele mai multe ori, când utilizatorii de Rust spun “crate”, se referă la crate-uri de bibliotecă. De asemenea, ei folosesc termenul "crate" alternativ cu conceptul general de "bibliotecă" în programare.
Radacina unui crate este un fișier sursă principal, punctul de start al compilatorului Rust. El alcătuiește modulul rădăcină al crate-ului tău (vom discuta în detaliu despre module în secțiunea „Definirea modulelor pentru controlul domeniului de vizibilitate și a confidențialității”).
Un pachet este un ansamblu ce poate cuprinde unul sau mai multe crate-uri, având rolul de a oferi diverse funcționalități. Fiecare pachet conține un fișier numit Cargo.toml, care servește drept ghid pentru construcția respectivelor crate-uri. Un exemplu concret este Cargo, care nu este altceva decât un pachet. Acesta include un crate de tip binar utilizat pentru instrumentul de linie de comandă cu care ai lucrat pentru a construi propriul cod. Pachetul Cargo găzduiește și un crate de tip bibliotecă, de care depinde crate-ul binar. Alte proiecte pot recurge la acest crate de tip bibliotecă pentru a folosi aceeași logică pe care o implementează instrumentul de linie de comandă.
Reflectând liber, un pachet are capacitatea de a găzdui oricâte crate-uri binare dorești, cu însă o limitare: poate conține cel mult un singur crate de tip bibliotecă. Este obligatoriu ca un pachet să aibă cel puțin un crate, indiferent dacă este vorba de unul de tip bibliotecă sau de tip binar.
În continuare, vom descrie pașii ce intervin în procesul de creare a unui pachet. Mai întâi, vom introduce comanda cargo new:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
După ce executăm comanda cargo new, putem folosi ls pentru a vedea ceea ce a generat comanda Cargo. În directoriul proiectului, vom găsi un fișier numit Cargo.toml, care ne creează un pachet. Tot acolo, se află și un directoriu src ce conține fișierul main.rs.
Dacă deschizi fișierul Cargo.toml într-un editor de text, vei observa că nu există nicio referire la src/main.rs. De fapt, Cargo urmează o convenție specifică prin care src/main.rs reprezintă rădăcina unui crate binar având același nume ca și pachetul. În același timp, Cargo recunoaște că dacă directoriul pachetului conține src/lib.rs, înseamnă că pachetul include un crate de bibliotecă cu același nume ca pachetul, iar src/lib.rs reprezintă rădăcina acestui tip de crate. Cargo transmite fișierele rădăcină ale crate-urilor către compilatorul rustc pentru a construi fie biblioteca, fie binarul.
În exemplul nostru, avem un pachet care include doar src/main.rs, ceea ce semnifică faptul că conține un singur crate binar numit my-project. Dacă un pachet ar conține atât src/main.rs cât și src/lib.rs, ar însemna că are două crate-uri: unul binar și unul de bibliotecă, ambele având același nume ca pachetul. Un pachet poate conține mai multe crate-uri binare dacă fișierele lor sunt plasate în directoriul src/bin: fiecare fișier reprezentând un crate binar separat.
Stabilirea modulelor pentru a gestiona domeniul de vizibilitate și confidențialitatea
In cadrul acestei secțiuni, vom discuta despre module și despre alte componente ale sistemului de module, în special calea care permite denumirea elementelor; cuvântul cheie use care introduce o cale în domeniul de vizibilitate; și cuvântul cheie pub, utilizat pentru a face elemente publice. Vom aborda, de asemenea, cuvântul cheie as, pachete externe și operatorul glob.
Înainte de toate, vom începe cu o listă de reguli pe care le poți consulta ușor atunci când vă organizați codul în viitor. Ulterior, vom explica fiecare regulă în detaliu.
Ghid rapid despre Module
Următoarea recapitulare oferă o privire lucrurilor esențiale despre cum modulele, căile, cuvântul-cheie use, precum și cuvântul-cheie pub colaborează cu compilatorul și cum, de obicei, dezvoltatorii își structurează codul. Deși vom discuta fiecare din aceste reguli, pe parcursul acestui capitol, referirea la acest ghid este un mod eficient de reamintire a modului în care funcționează modulele.
- Începând de la rădăcina crate-ului: În momentul compilării unui crate, compilatorul începe de la fișierul rădăcina al crate-ului (care este, de obicei, src/lib.rs pentru un crate de tip bibliotecă sau src/main.rs pentru un crate binar) în căutare de cod pentru a-l compila.
- Declararea modulelor: În fișierul rădăcină, poți introduce noi module. Să zicem că declarăm un modul numit "garden" cu
mod garden;. Compilatorul va căuta codul asociat acestui modul în următoarele locații:- În mod direct în cod, folosind acolade în locul semicolonului, după
mod garden - În fișierul src/garden.rs
- În fișierul src/garden/mod.rs
- În mod direct în cod, folosind acolade în locul semicolonului, după
- Declararea submodulelor: În orice alt fișier în afara celui rădăcină, poți declara submodule. De exemplu, ai putea declara
mod vegetables;în src/garden.rs. Compilatorul va căuta codul asociat acestui submodul în directoriul numit după modulul părinte în locațiile următoare:- Direct în cod, folosind acolade în locul semicolonului după
mod vegetables, - În fișierul src/garden/vegetables.rs
- În fișierul src/garden/vegetables/mod.rs
- Direct în cod, folosind acolade în locul semicolonului după
- Referirea către codul în module: Odată ce un modul este inclus în crate-ul tău, poți face referință la codul acestuia din orice alt loc în același crate, atât timp cât regulile de confidențialitate permit, folosind calea către acel cod. De exemplu, un tip
Asparagusdin modulul de legumă a grădinii ar putea fi referit folosind următoarea cale:crate::garden::vegetables::Asparagus. - Privat versus public: În mod implicit, codul din cadrul unui modul este privat față de modulele părinte. Pentru a face un modul public, se declară folosind
pub modîn loc demod. Pentru a face item-urile din interiorul unui modul public să fie, de asemenea, publice, foloseștepubînaintea declarațiilor acestora. - Cuvântul-cheie
use: Utilizat într-un domeniu de vizibilitate, cuvântul-cheieusecreează scurtături spre item-uri pentru a minimiza repetarea de căi lungi. În orice domeniu de vizibilitate care face referire lacrate::garden::vegetables::Asparagus, poți crea o scurtătură folosinduse crate::garden::vegetables::Asparagus;. După aceea, vei avea nevoie doar să scriiAsparaguspentru a putea folosi acest tip în cadrul domeniului de vizibilitate.
În acest exemplu, vom crea un crate binar numit "backyard" pentru a ilustra aceste reguli. Directoriul asociat cu crate-ul, care se numește și el "backyard", va conține următoarele fișiere și directoare:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
Fișierul principal al acestui crate se numește src/main.rs și conține următorul cod:
Numele fișierului: src/main.rs
use crate::garden::vegetables::Asparagus;
pub mod garden;
fn main() {
let plant = Asparagus {};
println!("I'm growing {:?}!", plant);
}Linia pub mod garden; le indică compilatorului să adauge codul pe care îl găsește în fișierul
src/garden.rs. Codul din acest fișier este următorul:
Numele fișierului: src/garden.rs
pub mod vegetables;De asemenea, linia pub mod vegetables; anunță compilatorul că trebuie să includă codul din fișierul src/garden/vegetables.rs. Codul din respectivul fișier este:
#[derive(Debug)]
pub struct Asparagus {}Acum, să detaliem aceste reguli și să le ilustrăm în acțiune!
Organizarea codului în module
Modulele ne oferă posibilitatea de a structura codul în interiorul unui crate, în scopul facilitării citirii și reutilizării acestuia. Prin intermediul modulelor, putem controla gradul de confidențialitate al elementelor, deoarece, în mod implicit, codul din interiorul unui modul este privat. Elementele private reprezintă detalii de implementare interne și nu pot fi utilizate în afara modulului. Cu toate acestea, avem opțiunea de a transforma modulele și elementele lor în entități publice, ceea ce le face accesibile pentru a fi utilizate și interconectate cu alte coduri externe.
Ca exemplu de utilizare, să presupunem că dorim să scriem un crate de bibliotecă care să reprezinte funcționalitatea unui restaurant. Vom defini semnăturile funcțiilor și vom lăsa corpurile lor goale, pentru a ne concentra pe structurarea codului, mai degrabă decât pe detaliile de implementare ale funcționării restaurantului.
În industria restaurantelor, unele zone ale unui restaurant sunt denumite zona din față a casei și, respectiv, zona din spate a casei. Zona din față a casei include spațiile în care sunt primiți clienții: locul în care ospătarii îi îndrumă pe aceștia la mese, preiau comenzi și încasează contravaloarea serviciilor, iar barmanii prepară băuturile. Zona din spate a casei este locul în care chefii și bucătarii își desfășoară activitatea în bucătărie, personalul se ocupă de curățenie, iar managerii își îndeplinesc sarcinile administrative.
Pentru a structura crate-ul nostru într-un mod optim, avem posibilitatea de a organiza funcțiile sale în module încorporate. Începe prin a crea o nouă bibliotecă pe care o vom numi restaurant. Acest lucru se poate realiza prin executarea comenzi cargo new restaurant --lib. Apoi, introdu codul afișat în Listarea 7-1 în fișierul src/lib.rs. Acest pas ne va permite definirea unor module și semnăturilor funcțiilor aferente. Să aruncăm o privire asupra secțiunii frontale a casei:
Numele fișierului: src/lib.rs
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}Listarea 7-1: Un modul front_of_house ce include alte
module ce conțin, la rândul lor, diverse funcții
Un modul se definește folosind cuvântul-cheie mod, urmat de numele ales pentru modulul respectiv -ăm făcut acest lucru mai sus cu front_of_house. Corpul modulului este închis între acolade. În interiorul modulelor, avem posibilitatea de a plasa alte module, exact cum am procedat cu modulele hosting și serving. Nu în ultimul rând, modulele pot găzdui definiții pentru alte tipuri de elemente precum structuri, enumerări, constante, trăsături și, așa cum am ilustrat în Listarea 7-1, funcții.
Utilizând module, avem posibilitatea de a grupa definițiile corelate și de a justifica această corelare. În acest mod, programatorii care vor folosi codul vor putea naviga mai ușor în funcție de grupele de definițiile create, în loc să fie nevoiți să parcurgă toate definițiile. Astfel devine mai simplu de identificat definițiile care sunt relevante pentru ei. De asemenea, când adaugă noi funcționalități în cod, vor ști exact unde să le plaseze pentru a menține organizarea programului.
Am menționat anterior că fișierele src/main.rs și src/lib.rs le denumim rădăcinile crate-urilor. Această denumire vine de la faptul că, conținutul oricăruia dintre aceste două fișiere, formează un modul numit crate, situat la baza structurii de module a crate-ului. Aceasta e cunoscută sub denumirea de arbore de module.
Listarea 7-2 prezintă arborele de module pentru structura prezentată în Listarea 7-1.
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
Listarea 7-2: Structura ierarhică a modulelor pentru codul din Listarea 7-1
Acest arbore ilustrează modul în care anumite module sunt incluse în altele; spre exemplu, modulul hosting este inclus în front_of_house. De asemenea, structura evidențiază că anumite module sunt simultane sau coexistente, adică sunt definite în același modul; hosting și serving sunt astfel de module simultane, definite în cadrul front_of_house. Dacă modulul A este inserat în modulul B, spunem că A este descendent al lui B iar B este asendent sau părinte pentru A. Observă că întregul arbore de module își are rădăcina în modulul implicit denumit crate.
Structura modulelor s-ar putea să-ți evoce structura ierarhică a directoriilor pe calculatorul tău; este o comparație extrem de adecvată! Așa cum utilizezi directoriile într-un sistem de operare pentru a-ți organiza fișierele, tot astfel folosești modulele pentru a-ți structura codul. Și exact ca în cazul fișierelor dintr-un directoriu, avem nevoie de o modalitate de a localiza modulele noastre.
Utilizarea căilor pentru a face referire la un element în structura de module
Când dorim să arătăm lui Rust unde să găsească un anumit element în structura de module, folosim o cale, exact cum am proceda atunci când navigăm printr-un sistem de fișiere. Pentru a apela o funcție este necesar să cunoaștem calea către aceasta.
Există două forme pe care o cale le poate lua:
- O cale absolută reprezintă calea completă începând de la rădăcina unui crate; în cazul codului ce provine dintr-un crate extern, calea absolută debutează cu numele crate-ului. Pentru codul din crate-ul actual, calea începe cu literalul
crate. - O cale relativă pornește de la modulul curent și utilizează
self,super, sau un identificator din cadrul modulului curent.
Fie că vorbim despre căi absolute sau relative, acestea sunt urmate de unul sau mai multe identificatori separați de patru puncte (::).
Revenind la Lista 7-1, presupunem că vrem să convocăm funcția add_to_waitlist. Asta este echivalent cu a întreba: care este calea către funcția add_to_waitlist? Lista 7-3 include Lista 7-1, dar unele dintre module și funcții au fost eliminate.
Vom prezenta în cele ce urmează două moduri de a apela funcția add_to_waitlist din cadrul unei noi funcții, eat_at_restaurant, definită la rădăcina crate-ului. Desi aceste căi sunt corecte, există o altă problemă și care va împiedica compilarea cu succes a acestui exemplu în forma lui actuală. Vom explica motivul în scurt timp.
Funcția eat_at_restaurant este parte componentă a interfeței de programare a aplicației (API) publice a crate-ului nostru de tip bibliotecă, motiv pentru care o marcam cu cuvântul cheie pub. În secțiunea “Expunerea căilor cu ajutorul cuvântului cheie pub”, vom discuta mai pe larg despre pub.
Numele fișierului: src/lib.rs
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}Listarea 7-3: Apelul funcției add_to_waitlist utilizând căi absolute și relative
În momentul în care apelăm pentru prima dată funcția add_to_waitlist în interiorul eat_at_restaurant, folosim o cale absolută. Funcția add_to_waitlist se află în același crate cu eat_at_restaurant, ceea ce înseamnă că avem posibilitatea de a folosi cuvântul cheie crate pentru a începe calea absolută. Includem apoi toate modulele succesive până ajungem la add_to_waitlist. Poți vizualiza această structură ca pe un sistem de fișiere: am specifica calea /front_of_house/hosting/add_to_waitlist pentru a executa programul add_to_waitlist; utilizarea termenului crate pentru a porni de la rădăcina unui crate este similară cu utilizarea / pentru a porni de la rădăcina sistemului de fișiere în shell-ul tău.
A doua oară când apelăm add_to_waitlist în cadrul eat_at_restaurant, utilizăm o cale relativă. Această cale începe cu front_of_house, numele modulului care este definit la același nivel în ierarhia de module ca și eat_at_restaurant. Echivalentul în contextul unui sistem de fișiere ar fi utilizarea căii front_of_house/hosting/add_to_waitlist. Pornirea de la numele unui modul indică faptul că calea este relativă.
Decizia de a utiliza o cale relativă sau una absolută va depinde de specificul proiectului tău și de probabilitatea de a mișca codul de definiție a unui element separat sau împreună cu codul care face referire la acel element. De exemplu, dacă am muta modulul front_of_house și funcția eat_at_restaurant într-un modul numit customer_experience, am fi nevoiți să actualizăm calea absolută către add_to_waitlist, însă calea relativă ar rămâne validă. În contrast, dacă am muta funcția eat_at_restaurant într-un modul numit dining, calea absolută către apelul add_to_waitlist nu s-ar schimba, doar calea relativă ar necesita o actualizare. În general, preferăm să folosim căi absolute deoarece este mai probabil să dorim să mișcăm definițiile de cod și apelurile de funcții independent unul de celălalt.
Să încercăm să compilăm Listarea 7-3 pentru a înțelege motivul pentru care nu se compilează! Eroarea pe care o întâlnim este expusă în Listarea 7-4.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
error[E0603]: module `hosting` is private
--> src/lib.rs:12:21
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` due to 2 previous errors
Listarea 7-4: Erorile de compilare a codului din Listarea 7-3
Mesajele de eroare indică faptul că modulul hosting este declarat ca fiind privat. Astfel, noi avem referințele corecte pentru modulul hosting și funcția add_to_waitlist, însă Rust nu acceptă utilizarea acestora datorită accesului restricționat la secțiunile private ale codului. În Rust, implicit, toate elementele - funcțiile, metodele, structurile, enumerările, modulele și constantele - sunt private în raport cu modulele părinte. Dacă vrei să faci un element anume, precum o funcție sau o structură, privat, îl introduci într-un modul.
Elementele dintr-un modul părinte nu pot utiliza elementele private din interiorul modulelor copil. În schimb, elementele din modulele copil au permisiunea de a folosi elementele prezentate în modulele lor ancestrale. Acest lucru se întâmplă deoarece modulele copil încapsulează și ascund detaliilor lor de implementare. Cu toate acestea, aceste module copil pot vedea contextul în care sunt definite. Într-un mod analog, putem vedea regulile de confidențialitate ca fiind similare cu gestionarea unei bucătării dintr-un restaurant: tot ceea ce se întâmplă în interior este privat din perspectiva clienților, dar managerii au capacitatea de a vedea și a coordona toate activitățile din restaurantul pe care îl administrează.
Decizia Rust de a proiecta sistemul de module în acest mod are la bază intenția de a ascunde, prin definiție, detaliile interne de implementare. În consecință, te vei putea ghida mai ușor în cunoașterea părților din cod pe care le poți modifica fără a afecta funcționarea restului de cod. Deși, Rust îți oferă posibilitatea de a dezvălui părți din interiorul codului modulelor copil către modulele ancestrale externe prin folosirea cuvântului cheie pub pentru a face un element anume public.
Expunerea căilor private cu cuvântul cheie pub
Să ne reamintim de eroarea din Listarea 7-4, care ne indica faptul că modulul hosting este privat. Obiectivul nostru este ca funcția eat_at_restaurant, din modulul părinte, să aibă acces la funcția add_to_waitlist, localizată în modulul copil. Pentru a realiza acest lucru, vom marca modulul hosting cu cuvântul cheie pub, după cum observăm în Listarea 7-5.
Numele fișierului: src/lib.rs
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}Listarea 7-5: Declararea modulului hosting ca fiind pub pentru a-l putea folosi în eat_at_restaurant
Totuși, codul din Listarea 7-5 încă generează o eroare, așa cum vedem în Listarea 7-6.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:9:37
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:12:30
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` due to 2 previous errors
Listarea 7-6: Erorile de compilare a codului din Listarea 7-5
Ce s-a întâmplat, de fapt? Adăugând cuvântul cheie pub în fața lui mod hosting, acest modul devine public. Cu această schimbare, dacă putem accesa front_of_house, atunci putem accesa și hosting. Cu toate acestea, conținutul modulului hosting rămâne în continuare privat. Transformarea unui modul într-unul public nu implică și transformarea conținutului său în public. Cuvântul cheie pub pentru un modul le permite doar modulelor ancestrale să facă referire la acesta, fără a-i putea accesa codul intern. Deoarece modulele sunt practic containere, simpla lor transformare în publice nu este de ajuns; este necesar și să decidem dacă transformăm unul sau mai multe elemente din modul în publice.
Erorile din Listarea 7-6 ne indică faptul că funcția add_to_waitlist are un statut privat. Aceste reguli privind confidențialitatea se aplică atât structurilor, enumerărilor, funcțiilor și metodelor, cât și modulelor.
Să transformăm funcția add_to_waitlist într-una publică, adăugând cuvântul cheie pub înainte de definiția sa, așa cum este ilustrat în Listarea 7-7.
Numele fișierului: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}Listarea 7-7: Prin adăugarea cuvântului cheie pub înainte de mod hosting
și fn add_to_waitlist, putem apela funcția
din eat_at_restaurant
Acum codul se va compila cu succes! Ca să înțelegem de ce utilizarea cuvântului cheie pub ne permite să folosim aceste căi în cadrul funcției add_to_waitlist, respectând astfel regulile de confidențialitate, să examinăm căile atât absolute, cât și cele relative.
În calea absolută, pornim de la crate, rădăcina arborelui de module ale crate-ului nostru. Modulul front_of_house este definit chiar la rădăcina crate-ului. Deși front_of_house nu are statutul de public, putem totuși referi front_of_house în cadrul funcției eat_at_restaurant, întrucât ambele sunt definite în același modul (adică, sunt "surori"). Următorul pas este modulul hosting marcat cu pub. Putem accesa modulul părinte al hosting, ceea ce înseamnă că putem accesa hosting. În final, funcția add_to_waitlist este marcată cu pub și putem accesa modulul ei părinte, deci apelul funcției noastre funcționează!
În calea relativă, procesul este identic cu cel din calea absolută, cu excepția primului pas: în loc să înceapă de la rădăcina crate-ului, calea demarează de la front_of_house. Modulul front_of_house este definit în cadrul aceluiași modul cu eat_at_restaurant, așadar calea relativă ce pornește din modulul unde eat_at_restaurant este definit este funcțională. Ulterior, pentru că hosting și add_to_waitlist sunt etichetate cu pub, restul căii este funcțional și acest apel de funcție este valid!
Dacă vrei să îți distribui crate-ul de librărie pentru ca alte proiecte să utilizeze codul tău, API-ul tău public este contractul tău cu utilizatorii crate-ului tău. Acesta va stabili modul în care aceștia pot interacționa cu codul tău. E mult de luat în considerare atunci când vine vorba de gestionarea modificărilor la API-ul tău public pentru a facilita dependența utilizatorilor față de crate-ul tău. Aceste aspecte nu sunt cuprinse în sfera acestei cărți; dacă acest subiect te interesează, consultă Ghidul pentru API-ul Rust.
Practici recomandate pentru pachete cu un executabil și o bibliotecă
Am precizat anterior că un pachet poate include atât un crate de tip executabil în src/main.rs, cât și un crate de tip bibliotecă în src/lib.rs, ambele având în mod implicit numele pachetului. De obicei, pachetele construite astfel încât să dispună de un crate de tip bibliotecă și unul de tip executabil, vor avea un cod minim în crate-ul executabil, necesar doar pentru a iniția un executabil care va apela codul din crate-ul de tip bibliotecă. Aceasta abordare permite altor proiecte să beneficieze de funcționalitățile oferite la maximum de pachet, întrucât codul crate-ului de tip bibliotecă poate fi distribuit. Structura arborelui de module trebuie definită în src/lib.rs. Apoi, elementele publice pot fi folosite în crate-ul de tip executabil, prin specificarea numelui pachetului la începutul căilor. Astfel, crate-ul de tip executabil devine un utilizator al crate-ului de tip bibliotecă, exact cum un crate complet extern ar utiliza crate-ul de tip bibliotecă: are acces doar la API-ul public. Acest lucru ajută la conceperea unui API eficient; nu numai că ești autor, dar ești și utilizator! În Capitolul 12, vom ilustra această bună practică organizatorică printr-un program de linie de comandă, care va include atât un crate de tip executabil, cât și unul de tip bibliotecă.
Inițierea căilor relative cu super
Putem crea căi relative care încep direct cu modulul părinte, în loc să le începem cu modulul curent sau cu rădăcina crate-ului. Aceasta se realizează utilizând super la începutul căii. Acest concept este similar cu începutul unei căi de sistem de fișiere cu sintaxa ... Prin utilizarea super avem capacitatea de a referi un element de care știm că se găsește în modulul părinte. Aceasta poate facilita procesul de rearanjare a structurii modulelor, în special dacă modulul este strâns legat de modulul părinte, dar acesta din urmă ar putea fi mutat în altă parte a structurii de module în viitor.
Luăm în considerare codul din Listarea 7-8, în care este prezentată situația în care un bucătar corectează o comandă greșită și o duce personal clientului. Funcția fix_incorrect_order definită în modulul back_of_house apelează funcția deliver_order definită în modulul părinte, indicația către funcția deliver_order începând cu super:
Numele fișierului: src/lib.rs
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order();
}
fn cook_order() {}
}Listare 7-8: Apelul unei funcții folosind o cale relativă, care începe cu super
Funcția fix_incorrect_order se află în modulul back_of_house, așa că folosim super pentru a ajunge la modulul părinte al back_of_house, care, în acest caz, este crate, rădăcina. De acolo, căutăm deliver_order și îl găsim. Succes! Considerăm că modulul back_of_house și funcția deliver_order vor păstra aceeași relație și că acestea vor fi mutate împreună în cazul în care decidem să reorganizăm structura modulelor în crate. Prin urmare, utilizăm super pentru a avea mai puține locuri de actualizat în codul sursă în viitor, dacă acest cod va fi mutat într-un modul diferit.
Setarea structurilor și enumerărilor ca fiind publice
Avem posibilitatea de a folosi pub pentru a seta structurile și enumerările ca fiind publice. Cu toate acestea, există câteva aspecte suplimentare referitoare la modul în care pub interacționează cu structurile și enumerările. Dacă aplicăm pub înaintea definiției unei structuri, facem structura publică, dar câmpurile acesteia vor rămâne private. Putem decide individual dacă fiecare câmp în parte va fi sau nu public. În Listarea 7-9, am definit o structură publică back_of_house::Breakfast care conține un câmp public toast, dar și un câmp privat seasonal_fruit. Acest lucru este similar cu situația dintr-un restaurant în care clientul poate alege tipul de pâine care însoțește masa, însă bucătarul hotărăște care fruct va acompania masa, în funcție de fructele de sezon disponibile. Deoarece varietatea de fructe disponibile se schimbă frecvent, clienții nu au posibilitatea de a alege fructul sau chiar de a vedea ce fruct vor primi.
Numele fișierului: src/lib.rs
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Order a breakfast in the summer with Rye toast
let mut meal = back_of_house::Breakfast::summer("Rye");
// Change our mind about what bread we'd like
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// The next line won't compile if we uncomment it; we're not allowed
// to see or modify the seasonal fruit that comes with the meal
// meal.seasonal_fruit = String::from("blueberries");
}Listarea 7-9: O structură cu anumite câmpuri publice și altele private
Datorită faptului că în structura back_of_house::Breakfast, câmpul toast este public, putem citi și scrie în câmpul toast folosind notația cu punct, în funcția eat_at_restaurant. Rețineți că nu putem utiliza câmpul 'seasonal_fruit' în eat_at_restaurant, deoarece 'seasonal_fruit' este privat. Încearcă să de-comentezi linia care modifică valoarea câmpului seasonal_fruit pentru a vedea ce eroare apare!
Trebuie remarcat și faptul că, deoarece back_of_house::Breakfast conține un câmp privat, structura trebuie să ofere o funcție asociată publică pentru a construi o instanță a Breakfast (în acest caz, am numit-o summer). Dacă Breakfast nu ar avea o astfel de funcție, în funcția eat_at_restaurant nu am putea crea o instanță a Breakfast, deoarece nu am putea seta valoarea câmpului privat seasonal_fruit.
În contrast, dacă stabilim o enumerare ca fiind publică, toate variantele acesteia devin publice. Ne este suficient să aplicăm pub înainte de cuvântul-cheie enum, așa cum este ilustrat în Listarea 7-10.
Numnele fișierului: src/lib.rs
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}Listarea 7-10: Selectarea unei enumerări ca publică face ca toate variantele acesteia să fie accesibile
Am declarat enum-ul Appetizer ca fiind public, ceea ce ne permite să folosim variantele Soup și Salad în codul eat_at_restaurant.
Enumerările nu sunt foarte utile dacă variantelor lor nu le este permis accesul public; ar fi incomod să trebuiască să adnotăm fiecare variantă a enumerării cu pub în fiecare caz. Din acest motiv, modul implicit pentru variantele de enumerări este acela de a fi public. Pe de altă parte, structurile sunt frecvent folosite fără ca câmpurile lor să fie publice, astfel că câmpurile unei structuri urmează regula generală unde totul este privat în mod implicit, cu excepția cazului în care este adnotat cu pub.
Există încă o situație în care este implicată utilizarea pub și pe care nu am discutat-o încă, aceasta fiind ultima caracteristică a sistemului de module, și anume cuvântul cheie use. Vom discuta mai întâi use în mod independent, apoi vom demonstra cum să combinăm pub și use.
Utilizarea cuvântului cheie use pentru a aduce căile în domeniul de vizibilitate
Scrierea completă a căilor pentru apelarea funcțiilor poate fi incomod de repetitivă. În Listarea 7-7, indiferent dacă optăm pentru drumul absolut sau cel relativ către funcția add_to_waitlist, am trebuit de fiecare dată să specificăm și front_of_house și hosting. Din fericire, există o modalitate de a simplifica acest proces: putem crea o scurtătură către o cale cu ajutorul cuvântului cheie use. Astfel, putem folosi un nume mai scurt în restul domeniului de vizibilitate.
În Listarea 7-11, introducem modulul crate::front_of_house::hosting în domeniul de vizibilitate al funcției eat_at_restaurant. Astfel, pentru apelarea funcției add_to_waitlist în contextul eat_at_restaurant, trebuie doar să specificăm hosting::add_to_waitlist.
Numele fișierului: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}Listarea 7-11: Introducerea unui modul în domeniul de vizibilitate cu use
Adăugarea use și a unei căi într-un domeniu este similară cu operațiunea de creare a unui link simbolic în sistemul de fișiere. Prin introducerea use crate::front_of_house::hosting la nivelul rădăcinii crate-ului, hosting devine un nume valid în cadrul acestui domeniu de vizibilitate, ca și cum modulul hosting ar fi fost definit chiar în rădăcina crate-ului. Căile aduse în vizibilitate cu use au capacitatea de a verifica confidențialitatea, la fel ca toate celelalte căi.
Trebuie să ținem minte că use creează o scurtătură doar în cadrul specific al domeniului de vizibilitate în care este folosit. Listarea 7-12 plasează funcția eat_at_restaurant într-un nou submodul numit customer. Acesta reprezintă un domeniu diferit de cel al declarației use, așa că funcția nu va putea fi compilată:
Filename: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
mod customer {
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
}Listarea 7-12: Instrucțiunea use este aplicabilă doar în domeniul de vizibilitate în care se găsește
Eroarea de compilare indică faptul că scurtătura nu mai este valabilă în interiorul modulului customer:
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
warning: unused import: `crate::front_of_house::hosting`
--> src/lib.rs:7:5
|
7 | use crate::front_of_house::hosting;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
error[E0433]: failed to resolve: use of undeclared crate or module `hosting`
--> src/lib.rs:11:9
|
11 | hosting::add_to_waitlist();
| ^^^^^^^ use of undeclared crate or module `hosting`
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` due to previous error; 1 warning emitted
Este important de observat că există de asemenea un avertisment care ne informează că instrucțiunea use nu mai este folosită în domeniul său de vizibilitate! Pentru a remediat această problemă, putem muta instrucțiunea use direct în interiorul modulului customer sau putem face referire la scurtătură din modulul părinte folosind super::hosting, în interiorul modulului copil customer.
Căi use idiomatice
E posibil să te fi întrebat, privind Listarea 7-11, de ce am utilizat use crate::front_of_house::hosting și apoi am apelat funcția hosting::add_to_waitlist în cadrul funcției eat_at_restaurant. De ce nu am specificat calea completă în use până la funcția add_to_waitlist pentru a obține același rezultat? Acest ultim mod de a proceda este ilustrat în Listarea 7-13.
Numele fișierului: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
}Listarea 7-13: Introducerea funcției add_to_waitlist în domeniul de vizibilitate cu use, o abordare care nu respectă normele idiomatice ale limbajului
Deși ambele metode, ilustrate în Listările 7-11 și 7-13, îndeplinesc aceeași sarcină, abordarea din Listarea 7-11 este considerată a fi cea corectă, conform obiceiurilor limbajului. Utilizarea lui use pentru a introduce modulul părinte al funcției în domeniul de vizibilitate necesită specificarea modulului părinte când apelăm funcția. Însă, astfel, devine evident că funcția nu este definită local, minimizând în același timp repetarea căii complete. În schimb, codul din Listarea 7-13 lasă în incertitudine locul unde add_to_waitlist este definită.
Cu toate acestea, când introducem în domeniul de vizibilitate structuri, enumerări și alte elemente cu ajutorul lui use, este idiomatic să se specifice calea completă. Listarea 7-14 arată metoda adecvată de a aduce structura HashMap din biblioteca standard în domeniul de vizibilitate al unui crate binar.
Numele fișierului: src/main.rs
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); map.insert(1, 2); }
Listarea 7-14: Introducerea HashMap în domeniu de vizibilitate în modul consecvent
Această idiomă nu are o cauză anume, este doar o tradiție care a fost adoptată pentru scrierea și citirea codului Rust.
Excepția la această convenție este dacă aducem în domeniul de vizibilitate două elemente care au același nume, folosind declarațiile use. Rust nu permite asta. Listarea 7-15 ilustrează cum să introducem în domeniul de vizibilitate două tipuri Result cu același nume, dar provenind din module părinte diferite și cum să le referim.
Numele fișierului: src/lib.rs
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
Ok(())
}
fn function2() -> io::Result<()> {
// --snip--
Ok(())
}Listarea 7-15: Introducerea simultană a două tipuri cu același nume în același domeniu de vizibilitate impune utilizarea modulelor părinte.
După cum poți observa, specificarea modulelor părinte ne ajută să distingem între cele două tipuri Result. Dacă am fi folosit use std::fmt::Result și use std::io::Result, am fi ajuns cu două tipuri Result în același domeniu și Rust nu ar fi putut distinge la care tip Result ne referim.
Utilizarea cuvântului cheie as pentru a atribui nume noi
O altă soluție la problema aducerii a două tipuri cu același nume în același domeniu de vizibilitate cu use implică folosirea cuvântului cheie as. După ce specificăm calea, putem adăuga as și un nume local nou, sau un alias, pentru tipul respectiv. Listarea 7-16 ne prezintă o altă variantă de a scrie codul din Listarea 7-15 prin redenumirea unuia dintre cele două tipuri Result folosind as.
Numele fișierului: src/lib.rs
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
Ok(())
}
fn function2() -> IoResult<()> {
// --snip--
Ok(())
}Listarea 7-16: Redenumirea unui tip la momentul introducerii acestuia în domeniul de vizibilitate, folosind cuvântul cheie as
În cel de-al doilea enunț use, noi am decis să alegem numele IoResult pentru tipul std::io::Result. Acesta nu va intra în conflict cu tipul Result din std::fmt pe care tot l-am adus în domeniul de vizibilitate. Atât Listarea 7-15 cât și Listarea 7-16 reprezintă abordări idiomatice, deci ai libertatea de a alege cea care ți se potrivește cel mai bine!
Re-exportarea numelor cu pub use
Când aducem un nume în domeniul de vizibilitate cu ajutorul cuvântului cheie use, numele disponibil în noul domeniu de vizibilitate este privat. Pentru a permite codului care apelează codul nostru să se refere la acel nume ca și cum ar fi fost definit în domeniul de vizibilitate al acelui cod, putem combina pub și use. Această tehnică se numește re-exportare deoarece aducem un element în domeniul de vizibilitate, dar de asemenea face acel element disponibil și pentru cei ce importă codul nostru.
Listarea 7-17 prezintă codul din Listarea 7-11 cu use în modulul root modificat în pub use.
Numele fișierului: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}Listarea 7-17: Facem un nume disponibil pentru orice cod de utilizat dintr-un nou domeniu de vizibilitate cu pub use
Înainte de această modificare, codul extern ar trebui să apeleze funcția add_to_waitlist utilizând calea restaurant::front_of_house::hosting::add_to_waitlist(). Acum, având în vedere că pub use a re-exportat modulul hosting din modulul root, codul extern poate acum utiliza calea restaurant::hosting::add_to_waitlist() în schimb.
Re-exportarea este utilă când structura internă a codului tău este diferită de felul în care programatorii care apelează codul tău ar gândi despre domeniu. De exemplu, în această metaforă despre restaurant, oamenii care administrează restaurantul gândesc despre "fața casei" și "spatele casei". Dar clienții care vizitează un restaurant probabil nu vor gândi despre părțile restaurantului în acești termeni. Cu pub use, putem scrie codul nostru cu o structură, dar expunem o structură diferită. Făcând acest lucru, biblioteca noastră este bine organizată atât pentru programatorii care lucrează în bibliotecă cât și pentru programatorii care apelează biblioteca. Vom privi un alt exemplu de pub use și cum acesta afectează documentația crate-ului tău în secțiunea „Exportarea unui API public și accesibil cu pub use” din Capitolul 14.
Utilizarea pachetelor externe
În capitolul 2, am creat un joc de ghicit numere, care se baza pe un pachet extern numit rand pentru generarea numerelor aleatorii. Pentru a folosi rand în cadrul proiectului nostru, am inclus următoarea linie în fișierul Cargo.toml:
Numele fișierului: Cargo.toml
rand = "0.8.5"
Adăugarea rand ca o dependență în fișierul Cargo.toml instruiește sistemul Cargo să descarce pachetul rand și orice dependențe asociate de pe crates.io și să-l predea la dispoziția proiectului nostru.
Ulterior, pentru a aduce definițiile din rand în domeniul de vizibilitate al pachetului nostru, am inclus o instrucțiune use. Aceasta era precedată de numele pachetului, rand, și continuată cu lista elementelor pe care am dorit să le aducem în vizibilitate. Îți poți aduce aminte de secțiunea „Generarea unui număr aleator” din capitolul 2, unde am introdus trăsătura Rng în domeniul de vizibilitate și am apelat funcția rand::thread_rng:
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Membrii comunității Rust au pus la dispoziție multe pachete pe crates.io, iar integrarea oricăruia dintre acestea în pachetul tău presupune aceeași pași: listarea pachetelor în fișierul Cargo.toml și utilizarea instrucțiunii use pentru a introduce elemente din aceste pachete în domeniul de vizibilitate.
Este important de notat că și biblioteca standard std este de asemenea un crate extern pachetului nostru. Totuși, deoarece biblioteca standard este inclusă în setul de livrare standard al limbajului Rust, nu trebuie să modificăm Cargo.toml pentru a include std. Trebuie doar să folosim instrucțiunea use pentru a introduce elemente din aceasta în domeniul de vizibilitate al pachetului nostru. De exemplu, pentru a folosi HashMap, am utiliza următoarea linie:
#![allow(unused)] fn main() { use std::collections::HashMap; }
Aceasta este o cale absolută care începe cu std, numele crate-ului bibliotecii standard.
Utilizarea căilor îmbinate pentru a economisi spațiu în listele lungi de use
Când lucrăm cu numeroase elemente definite în același crate sau în același modul, este obositor și consumator de spațiu să le listăm pe fiecare în parte pe linii separate. Să luăm ca exemplu jocul Ghicitoarea din Listarea 2-4, unde am folosit două declarații use pentru a importa elemente din std în domeniul nostru de vizibilitate:
Numele fișierului: src/main.rs
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}În loc de aceasta, putem utiliza căi îmbinate pentru a aduce aceleași elemente în domeniul de vizibilitate într-o singură linie. Acest lucru se face prin specificarea părții comune a căii, continuată cu două puncte și cu acolade ce îngrădesc părțile diferite ale căilor. Acest concept este prezentat in Listarea 7-18.
Numele fișierului: src/main.rs
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Listarea 7-18: Utilizarea unei căi îmbinate pentru a importa mai multe elemente cu același prefix în domeniul de vizibilitate
În cadrul programelor mari, tehnica importării unui număr mare de elemente din același crate sau modul prin căi îmbinate poate reduce considerabil numărul de declarații use separate.
O cale îmbinată poate fi utilizată la orice nivel într-o cale, fapt util atunci când dorim să combinăm două declarații use care au o sub-cale comună. De exemplu, Lista 7-19 ne arată două declarații use: una ce aduce std::io în domeniul de vizibilitate și una care aduce std::io::Write în domeniul de vizibilitate.
Numele fișierului: src/lib.rs
use std::io;
use std::io::Write;Listarea 7-19: Două declarații use cu o sub-cale comună
Pentru a combina cele două căi într-o singură declarație use, folosim self în cadrul căii îmbinate, așa cum vedem în Listarea 7-20.
Numele fișierului: src/lib.rs
use std::io::{self, Write};Listarea 7-20: Combinarea căilor din Lista 7-19 într-o singură declarație use
În urma acestei operațiuni, std::io și std::io::Write sunt aduse în domeniul de vizibilitate.
Utilizarea operatorului * (glob)
Daca dorim să includem toate elementele publice definite printr-o anumită cale în domeniul nostru de vizibilitate, atunci trebuie sa utilizăm calea dorită completată cu operatorul *:
#![allow(unused)] fn main() { use std::collections::*; }
Această instrucțiune use face ca toate elementele publice definite în std::collections să fie disponibile în domeniul de vizibilitate actual. Trebuie să fim prudenți când utilizăm operatorul *! Ne poate face dificilă identificarea numelor care sunt în domeniul de vizibilitate și localizarea locului unde a fost definit un nume folosit în programul nostru.
De obicei, utilizăm operatorul * atunci când realizăm teste pentru a include totul în modulul tests. Vom aborda acest subiect în secțiunea „Cum să scriem teste” din Capitolul 11. De asemenea, uneori operatorul * face parte din pattern-ul 'preludiu'. Poți accesa documentația bibliotecii standard pentru a afla mai multe detalii despre acest pattern.
Separarea modulelor în diferite fișiere
Toate exemplele prezentate până acum în acest capitol au învățat cum să definim mai multe module într-un singur fișier. Când modulele devin mai complexe, ai putea dori să separi definițiile acestora în fișiere diferite pentru a naviga mai ușor prin cod.
Ca punct de plecare, vom lua codul din Listarea 7-17 care conține multiple module restaurant. Scopul este să extragem modulele în diferite fișiere, în loc să le păstrăm toate în fișierul rădăcină al crate-ului. În cazul de față, fișierul rădăcină este src/lib.rs. Cu toate acestea, același proces se aplică și crate-urilor binare, unde fișierul rădăcină este src/main.rs.
Începem prin a delega modulul front_of_house în propriul fișier. Pentru asta, eliminăm codul din interiorul acoladelor modulului front_of_house, lăsând doar declarația mod front_of_house;. Astfel, src/lib.rs va conține codul prezentat în Listarea 7-21. Atenție: acest cod nu va putea fi compilat până când nu vom crea fișierul src/front_of_house.rs, așa cum este prezentat în Listarea 7-22.
Numele fișierului: src/lib.rs
{{#includefile_rustdoc ../lista/ch07-gestionand-proiecte-in-crestere/listare-07-21-si-22/src/lib.rs}}Listarea 7-21: Declararea modulului front_of_house care va fi conținut în src/front_of_house.rs
În etapa următoare, trebuie să mută codul din interiorul acoladelor într-un fișier nou, numit src/front_of_house.rs, conform Listării 7-22. Compilatorul va găsi acest fișier datorită declarației de modul din rădăcina crate-ului, unde se specifică numele front_of_house.
Numele fișierului: src/front_of_house.rs
pub mod hosting {
pub fn add_to_waitlist() {}
}Listarea 7-22: Definim anumite aspecte în interiorul modulului front_of_house localizat în src/front_of_house.rs
Reține că trebuie să încarci un fișier folosind o declarație mod o singură dată în arborele tău de module. Odată ce compilatorul este informat că fișierul aparține proiectului (și cunoaște locul în care se găsește codul datorită poziției declarației mod ), restul fișierelor din proiect trebuie să se refere la codul fișierului încărcat utilizând o cale spre locul declarării acestuia. Această metodă este descrisă în secțiunea „Cum să referi un element în structura modulelor”. În cuvinte mai simple, mod nu este o comandă de "include", așa cum este utilizată în alte limbaje de programare.
Următorul pas va fi mutarea modulului hosting în propriul său fișier. Procesul este ușor diferit deoarece hosting este un submodul al front_of_house, nu un modul rădăcină. Noua locație a fișierului va fi un nou directoriu, care va purta numele submodulului în structura de module - în cazul nostru, src/front_of_house/.
Pentru mutarea hosting, modificăm src/front_of_house.rs pentru a găzdui doar declarația modulului hosting:
Numele fișierului: src/front_of_house.rs
pub mod hosting;Apoi, creăm directoriul src/front_of_house și fișierul hosting.rs, care va conține definițiile din cadrul modulului hosting:
Numele fișierului: src/front_of_house/hosting.rs
pub fn add_to_waitlist() {}Daca am plasa hosting.rs în directoriul src, compilatorul s-ar aștepta ca fișierul hosting.rs să fie un modul rădăcină hosting din structura proiectului, și nu un submodul al front_of_house. Regulile interne ale compilatorului referitoare la asocierea fișierelor cu modulele specifice fac ca structura de directorii și fișiere să urmeze cu exactitate structura de module.
Căi alternative de fișiere
Până în prezent, am discutat despre căile de fișiere cel mai des utilizate în Rust, dar trebuie să știi că acest limbaj de programare acceptă și un stil mai vechi de definire a acestora. Să luăm exemplul unui modul numit
front_of_house, pe care îl avem declarat la rădăcina unui crate - compilatorul Rust va căuta codul acestuia în următoarele locații:
- src/front_of_house.rs (am discutat deja despre aceasta)
- src/front_of_house/mod.rs (o variantă mai veche, care este încă acceptată)
Referitor la un modul numit
hosting, definit ca submodul alfront_of_house, compilatorul va căuta codul său în:
- src/front_of_house/hosting.rs (am menționat deja acesta)
- src/front_of_house/hosting/mod.rs (încă o versiune veche, încă valabilă)
Dacă alegi să utilizezi ambele stiluri pentru același modul, vei obține o eroare din partea compilatorului. Deși ești liber să utilizezi o combinație a celor două stiluri pentru diferite module din același proiect, aceasta ar putea genera confuzii pentru cei care explorează proiectul.
Unul dintre dezavantajele metodei care implică utilizarea de fișiere numite mod.rs este că proiectul poate ajunge să conțină un număr mare de astfel de fișiere, ceea ce poate fi confuz atunci când le avem deschise simultan în editor.
Noutatea este că acum avem codul fiecărui modul într-un fișier separat, dar structura modulelor în sine nu s-a schimbat. Chiar dacă acum definițiile lor se află în fișiere diferite, apelurile funcției în
eat_at_restaurantvor funcționa în mod normal, fără a necesita vreo modificare. Aceasta ne permite să mutăm modulele în fișiere noi pe măsură ce acestea se măresc în dimensiune.Observăm că linia
pub use crate::front_of_house::hostingdin src/lib.rs nu a fost afectată, la fel cum nici folosirea cuvântului cheieusenu influențează fișierele care sunt compilate ca parte a crate-ului. Cuvântul cheiemodeste folosit pentru a declara module, iar Rust va căuta codul acestora în fișiere care au același nume precum modulul în sine.
Sumar
Rust îți oferă posibilitatea de a diviza un pachet în crate-uri multiple și un crate în diverse module. Acest lucru permite referirea la elemente definite într-un anumit modul dintr-un altul. Această acțiune poate fi realizată prin specificarea unor căi absolute sau relative. Cu ajutorul instrucțiunii use, aceste căi pot fi aduse în domeniul de vizibilitate, permițând astfel un acces mai rapid și mai eficient. Deși codul unui modul este inițial privat, acesta poate fi făcut public adăugând termenul pub.
În capitolul următor, vom explora unele structuri de colecție din librăria standard, pe care le vei putea folosi în codul tău bine organizat.
Colecțiile comune în Rust
Biblioteca standard Rust ne pune la dispoziție o serie de structuri de date foarte utile, denumite generic colecții. Spre deosebire de celelalte tipuri de date care reprezintă o singură valoare, colecțiile pot stoca multiple valori. În plus, nu ca tipurile native array și tuplă, datele la care se referă aceste colecții sunt stocate în heap, deci volumul acestora nu trebuie să fie cunoscut în momentul compilării și poate varia pe parcursul execuției programului. Fiecare tip de colecție vine cu propriile sale capabilități și costuri asociate, așadar selectarea celei potrivite pentru situația curentă este o abilitate care se dezvoltă în timp. În acest capitol ne vom concentra pe trei colecții foarte utilizate în programele Rust:
- Vectorul ne permite stocarea unui număr variabil de valori alături.
- String-ul reprezintă o colecție de caractere. Deși am menționat anterior tipul
String, în acest capitol îl vom aborda în profunzime. - O hartă hash ne dă posibilitatea de a asocia o valoare cu o cheie specifică, fiind un caz particular de implementare a structurii de date denumite map.
Consultează documentația pentru a afla despre celelalte tipuri de colecții disponibile în biblioteca standard.
Vom discuta despre cum putem crea și actualiza vectori, string-uri și hărți hash, precum și despre ce caracteristici unice are fiecare.
Păstrarea listelor de valori folosind vectori
Primul tip de colecție pe care îl vom discuta se numește Vec<T>, cunoscut mai bine ca vector. Vectorii ne permit să păstrăm mai multe valori într-o singură structură de date care plasează toate valorile una lângă alta în memorie. Un aspect important este că vectorii pot conține doar valori de același tip. Aceștia se dovedesc a fi foarte utili când ai o listă de elemente, precum liniile de text dintr-un fișier sau prețurile produselor dintr-un coș de cumpărături.
Crearea unui vector nou
Pentru a crea un vector nou și gol, utilizăm funcția Vec::new, după cum urmează în Listarea 8-1.
fn main() { let v: Vec<i32> = Vec::new(); }
Listarea 8-1: Crearea unui vector nou și gol pentru valori de tip i32
Aici am adăugat o adnotare de tip deoarece nu introducem valori și Rust nu poate deduce tipul elementelor pe care dorim să le stocăm. Acest aspect este crucial. Vectorii sunt construiți folosind generice, iar utilizarea genericelor cu tipurile proprii le vom explora în Capitolul 10. Până atunci, este important să știi că tipul Vec<T> din biblioteca standard poate conține orice alt tip. Când inițializăm un vector pentru un anumit tip, specificăm acest tip între paranteze unghiulare. În Listarea 8-1, i-am indicat lui Rust că Vec<T> de la variabila v va conține elemente de tip i32.
De obicei, cel mai frecvent vei inițializa vectorii Vec<T> cu valori specifice și Rust va infera automat tipul de date pe care dorești să-l stochezi. Prin urmare, este rar necesar să oferi adnotări de tip. Rust oferă macro-ul vec!, care te ajută să creezi direct un vector nou cu valorile specificate. Listarea 8-2 arată cum să creezi un Vec<i32> care stochează valorile 1, 2 și 3. Tipul de date pentru întregi este i32, conform predefinirii pentru tipul întreg, așa cum am discutat în secțiunea „Tipuri de date” din Capitolul 3.
fn main() { let v = vec![1, 2, 3]; }
Listarea 8-2: Crearea unui vector nou care include anumite valori
Deoarece am furnizat valori inițiale de tip i32, Rust poate determina că v este de tipul Vec<i32>, așadar adnotarea de tip nu este necesară. Următorul pas este să învățăm cum putem modifica un vector.
Actualizarea unui vector
Pentru a crea un vector și a-i adăuga elemente, putem utiliza metoda push. Urmărește exemplul din Listarea 8-3.
fn main() { let mut v = Vec::new(); v.push(5); v.push(6); v.push(7); v.push(8); }
Listarea 8-3: Adăugarea valorilor într-un vector folosind metoda push
Dacă vrem să modificăm o variabilă, trebuie să o declarăm ca fiind mutabilă, utilizând cuvântul cheie mut, după cum am explicat în Capitolul 3. Toate numerele inserate sunt de tip i32. Rust înțelege acest lucru automat din datele furnizate, astfel încât nu este necesară specificarea explicită a tipului Vec<i32>.
Accesarea elementelor din vectori
Există două modalități prin care poți referenția o valoare stocată într-un vector: prin indexare sau utilizând metoda get. Pentru claritate, în exemplele următoare am specificat tipurile valorilor returnate de aceste două funcții.
În Listarea 8-4, sunt ilustrate ambele metode de accesare a unei valori dintr-un vector - prin indexare directă și folosind metoda get.
fn main() { let v = vec![1, 2, 3, 4, 5]; let third: &i32 = &v[2]; println!("The third element is {third}"); let third: Option<&i32> = v.get(2); match third { Some(third) => println!("The third element is {third}"), None => println!("There is no third element."), } }
Listarea 8-4: Accesarea unui element dintr-un vector folosind sintaxa de indexare sau metoda get
Aici trebuie să remarcăm anumite detalii. Folosim indicele 2 pentru a ajunge la al treilea element, având în vedere că vectorii sunt indexați începând cu zero. Operatorul & împreună cu [] ne oferă o referință către elementul situat la indicele specificat. Când apelăm metoda get cu un indice ca argument, primim o variantă Option<&T>, pe care putem să o utilizăm într-o instrucțiune match.
Rust ne oferă aceste două metode de referențiere astfel încât să putem alege cum dorești să răspundă programul atunci când accesăm un indice din afara limitelor vectorului. Să luăm un exemplu: ce se întâmplă dacă avem un vector cu cinci elemente și încercăm să accesăm un element la indicele 100 folosind fiecare metodă, așa cum vedem în Listarea 8-5.
fn main() { let v = vec![1, 2, 3, 4, 5]; let does_not_exist = &v[100]; let does_not_exist = v.get(100); }
Listarea 8-5: Tentativa de a accesa elementul la indicele 100 dintr-un vector cu cinci elemente
Rulând acest cod, prima metodă, cea cu [], va provoca o eroare fără recuperare (panică), din cauza referinței la un element inexistent. Această methodă e utilă când vrem ca programul să se oprească în cazul unei tentative de a accesa un element dincolo de capătul vectorului.
Pe de altă parte, când metoda get primește un indice ce depășește limitele vectorului, aceasta returnează None fără a genera o panică. Ai alege această cale dacă posibilitatea unui acces la un indice în afara vectorului aparține situațiilor normale în aplicația ta. Astfel, codul va include logica de tratare a cazurilor atunci când rezultatul e Some(&element) sau None, după cum am analizat în Capitolul 6. De exemplu, un utilizator poate introduce accidental un număr prea mare, iar programul ar returna None. În acest caz, ai putea să-l informezi despre numărul de elemente din vector și să-i oferi o nouă șansă pentru a introduce un număr valabil, o soluție mult mai favorabilă decât închiderea programului.
Atunci când avem o referință valabilă, verificatorul de împrumut verifică regulile de proprietate și împrumut (abordate în Capitolul 4), pentru a se asigura că această referință, precum și orice alte referințe la conținutul vectorului, sunt valide. Amintește-ți de regula importantă care impune că nu poți deține referințe mutabile și imutabile simultan. Această regulă este ilustrată în Listarea 8-6, unde avem o referință imutabilă la primul element din vector, iar în același timp încercăm să adăugăm un element la final. Programul nu va funcționa dacă apoi încercăm să accesăm din nou acel element:
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}Listarea 8-6: Încercarea de adăugare a unui element la vector în timp ce există o referință către un element al său
Compilarea acestui cod va genera următoarea eroare:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {first}");
| ----- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` due to previous error
Poate părea surprinzător că acest cod generează o eroare, deoarece te-ai putea întreba de ce o referință la primul element ar fi afectată de modificările produse la capătul vectorului. Motivul erorii este legat de cum vectorii își gestionează memoria: adăugând un nou element, poate fi necesară alocarea unui nou segment de memorie și copierea elementelor vechi în acesta, dacă spațiul actual nu este suficient. Într-o astfel de situație, referința la primul element ar indica spre memorie care a fost eliberată. Regulile de împrumut împiedică astfel de situații neplăcute.
Notă: Pentru mai multe detalii despre implementarea tipului
Vec<T>, poți consulta “The Rustonomicon”.
Iterând prin elementele unui vector
Pentru a accesa elementele unui vector rând pe rând, cel mai eficient este să folosim o iterație completă, decât să accesăm elementele individual prin indici. Listarea 8-7 demonstrează modul în care putem utiliza un ciclu for pentru a parcurge un vector de valori de tip i32, obținând referințe imutabile la fiecare element și afișându-le.
fn main() { let v = vec![100, 32, 57]; for i in &v { println!("{i}"); } }
Listarea 8-7: Afișarea fiecărui element al unui vector prin iterare cu ajutorul unui ciclu for
Este posibil să iterăm și prin referințe mutabile ale elementelor unui vector mutabil, pentru a modifica toate elementele acestuia. Ciclul for din Listarea 8-8 adaugă 50 la valoarea fiecărui element.
fn main() { let mut v = vec![100, 32, 57]; for i in &mut v { *i += 50; } }
Listarea 8-8: Iterarea prin referințe mutabile ale elementelor dintr-un vector
Pentru a modifica valoarea la care se referă o referință mutabilă, folosim operatorul de dereferențiere * pentru a accesa valoarea efectivă din i înainte să aplicăm operatorul +=. Vom discuta mai detaliat despre operatorul de dereferențiere în secțiunea "Urmărind pointer-ul până la valoare cu ajutorul operatorului de dereferențiere"deref din Capitolul 15.
Iterația printr-un vector, fie că face acces imutabil sau mutabil, este sigură datorită regulilor impuse de verificatorul de împrumuturi. Dacă încercăm să adăugăm sau să eliminăm elemente în timpul execuției unui ciclu for, așa cum se face în Listările 8-7 și 8-8, ne vom confrunta cu o eroare de compilare similară cu cea întâmpinată în Listarea 8-6. Referința la vector menținută de ciclul for previne orice modificare simultană asupra întregului vector.
Folosirea unui enum pentru a combina mai multe tipuri într-un vector
Vectorii sunt limitați la stocarea valorilor de același tip, ceea ce poate fi restrictiv în anumite situații. Spre norocul nostru, variantele unui enum sunt grupate sub același tip de enum, permițându-ne să folosim un singur enum pentru a reprezenta elemente de tipuri diferite. Așadar, atunci când dorim să combinăm diverse tipuri într-o singură structură, putem apela la un enum!
Să presupunem că dorim să extragem valori dintr-un rând al unui tabel, unde coloanele acelui rând conțin întregi, numere în virgulă mobilă sau string-uri. Ne putem defini un enum cu variante pentru fiecare tip de valoare, iar aceste variante de enum vor fi considerate același tip: tipul enum-ului în sine. Putem crea apoi un vector care să păstreze acest enum și, în final, să cuprindă tipuri variate. Acest concept este ilustrat în Listarea 8-9.
fn main() { enum SpreadsheetCell { Int(i32), Float(f64), Text(String), } let row = vec![ SpreadsheetCell::Int(3), SpreadsheetCell::Text(String::from("blue")), SpreadsheetCell::Float(10.12), ]; }
Listarea 8-9: Crearea unui enum pentru stocarea valorilor de diferite tipuri într-un vector
Rust trebuie să cunoască de la momentul compilării ce tipuri vor fi incluse în vector, astfel încât să aloce în mod corespunzător memoria necesară pe heap pentru fiecare element. De asemenea, trebuie să specificăm în mod explicit care tipuri sunt acceptate în vector. Dacă Rust ar permite unui vector să conțină orice tip, ar exista riscul ca unele tipuri să genereze erori în momentul operațiilor executate asupra elementelor. Utilizând un enum în combinare cu o expresie match, Rust garantează la compilare că fiecare caz posibil este luat în considerație, conform discuției din Capitolul 6.
Dacă nu știm dinainte toate tipurile de date cu care programul nostru va opera la executare, abordarea cu enum nu este aplicabilă. Ca alternativă, se poate folosi un obiect de tip trăsătură, subiect pe care îl vom aborda în Capitolul 17.
După ce am explorat unele dintre cele mai frecvente utilizări ale vectorilor, te încurajez să consulți documentația API pentru a descoperi multitudinea de metode utile definite pentru Vec<T> de către biblioteca standard. De exemplu, pe lângă metoda push, există și metoda pop, care elimină și returnează ultimul element din vector.
Un vector își eliberează elementele la distrugere
Ca orice struct, un vector este eliberat automat când domeniul său de vizibilitate se încheie, după cum vedem în Listarea 8-10.
fn main() { { let v = vec![1, 2, 3, 4]; // do stuff with v } // <- v goes out of scope and is freed here }
Listarea 8-10: Ilustrarea punctelor unde vectorul și elementele sale sunt eliberate
Eliberarea unui vector implică și curățarea tuturor elementelor sale; în cazul nostru, numerele întregi vor fi de asemenea eliminate. Verificatorul de împrumuturi se asigură că referințele la elementele vectorului sunt folosite numai atât timp cât vectorul respectiv este în vigoare.
Acum să ne îndreptăm atenția spre următorul tip de colecție: String!
Manipularea textelor codate UTF-8 utilizând string-uri
Am introdus noțiunile despre string-uri în Capitolul 4, dar acum vom aprofunda subiectul. Utilizatorii noi de Rust au adesea dificultăți cu string-urile din cauza unei combinații a trei aspecte: abordarea Rust de a evidenția posibilele greșeli, complexitatea neașteptată a string-urilor ca structură de date și particularitățile codării UTF-8. Toate acestea pot crea provocări, mai ales pentru cei veniți din alte limbaje de programare.
Vorbim despre string-uri în cadrul temei colecțiilor pentru că, în esență, un string este o colecție de octeți (bytes), completată de metode care facilitează lucrul cu textul. În această secțiune, ne vom concentra pe operațiunile comune oricărui tip de colecție, care se aplică și pentru String: cum le creăm, le actualizăm și le citim. Vom discuta și despre caracteristicile care diferențiază String de alte tipuri de colecții, concentrându-ne în special pe complexitatea indexării într-un String, dată de modul diferit în care oamenii și calculatoarele procesează informația dintr-un String.
Ce este un string?
Să clarificăm ce înțelegem noi prin "string". În limbajul Rust, există un singur tip fundamental de string, anume secțiunea de string - str, care de obicei apare sub forma împrumutată &str. În Capitolul 4, am abordat conceptul de secțiuni de string, care reprezintă referințe la date de tip string codificate în UTF-8 și stocate în altă parte. Spread exemplu, literalele de string sunt incluse în fișierul binar al programului, motiv pentru care sunt considerate secțiuni de string.
Pe de altă parte, avem tipul String, oferit de biblioteca standard a limbajului Rust și nu parte integrantă a nucleului limbajului. Acesta este un tip de string extensibil, mutabil, cu proprietate asupra datelor și codificat în UTF-8. Când vorbim despre "string-uri" în Rust, ne referim atât la tipul String, cât și la secțiunile de string &str, nu exclusiv la unul dintre ele. Deși accentul acestei secțiuni este pe String, ambele forme sunt fundamentale în biblioteca standard și, atât String, cât și secțiunile de string respectă codificarea UTF-8.
Crearea unui string nou
Operațiunile pe care le facem cu Vec<T> pot fi aplicate și pe String, deoarece String este efectiv o încapsulare peste un vector de octeți, având anumite garanții suplimentare, restricții și funcționalități. Să luăm drept exemplu funcția new, care ne permite să creăm o nouă instanță de String, ilustrată în Listarea 8-11.
fn main() { let mut s = String::new(); }
Listarea 8-11: Crearea unui String gol
Această linie de cod creează un String nou și gol, pe nume s, în care putem încărca date ulterior. Adesea avem date inițiale pe care dorim să le folosim pentru a popula string-ul. Pentru acest caz folosim metoda to_string, disponibilă pentru orice tip ce implementează trăsătura Display, așa cum fac literalele string. Listarea 8-12 prezintă două exemple.
fn main() { let data = "initial contents"; let s = data.to_string(); // the method also works on a literal directly: let s = "initial contents".to_string(); }
Listarea 8-12: Crearea unui String dintr-un literal string folosind metoda to_string
Codul de mai sus generează un string ce conține textul initial contents.
Putem folosi, de asemenea, funcția String::from pentru a crea un String pornind de la un literal string. Codul din Listarea 8-13 este similar celui din Listarea 8-12, care a utilizat to_string.
fn main() { let s = String::from("initial contents"); }
Listarea 8-13: Utilizarea funcției String::from pentru a obține un String dintr-un literal string
Având în vedere numărul mare de aplicații ale string-urilor, există multe API-uri generice pentru lucrul cu acestea, oferindu-ne o varietate mare de opțiuni. Unele dintre acestea par redundante, dar fiecare își are rostul său! În acest caz, String::from și to_string îndeplinesc aceeași funcție, astfel alegerea dintre cele două este bazată mai mult pe preferințe de stil și claritate.
Rețineți că string-urile sunt codate în UTF-8, astfel orice date codate adecvat pot fi inclusă în acestea, așa cum este demonstrat în Listarea 8-14.
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שָׁלוֹם"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
Listarea 8-14: Salvarea mesajelor de salut în diferite limbi în string-uri
Toate acestea reprezintă valori String corecte.
Actualizarea unui string
Un String poate să se extindă și să-și schimbe conținutul, similar cu Vec<T>, atunci când adaugi mai multe date. De asemenea, e simplu să concatenezi valori String folosind operatorul + sau macro-ul format!.
Adăugând la un string cu push_str și push
Un String poate fi mărit adăugând o secțiune de string cu ajutorul metodei push_str, așa cum vedem în Listarea 8-15.
fn main() { let mut s = String::from("foo"); s.push_str("bar"); }
Listarea 8-15: Adăugarea unei secțiuni de string la un String cu push_str
După aceste operațiuni, s va conține foobar. Metoda push_str primește o secțiune de string pentru că nu dorește, de obicei, să preia controlul acestuia. De exemplu, în exemplul din Listarea 8-16, vrem ca s2 să fie utilizabil și după ce l-am concatenat cu s1.
fn main() { let mut s1 = String::from("foo"); let s2 = "bar"; s1.push_str(s2); println!("s2 is {s2}"); }
Listarea 8-16: Utilizarea unei secțiuni de string după ce a fost adăugată la un String
Dacă metoda push_str ar fi solicitat posesiunea asupra lui s2, nu am fi putut afișa valoarea acestuia la sfârșit. Însă, codul funcționează cum ne-am așteptat!
Metoda push acceptă un caracter și îl adaugă la String. În Listarea 8-17, adăugăm litera "l" la un String folosind push.
fn main() { let mut s = String::from("lo"); s.push('l'); }
Listarea 8-17: Adăugarea unui caracter la un String cu push
Rezultatul va fi că s va conține lol.
Concatenarea cu operatorul + sau macro-ul format!
Adesea, ai nevoie să unifici două string-uri existente. Poți face asta folosind operatorul +, cum este arătat în Listarea 8-18.
fn main() { let s1 = String::from("Hello, "); let s2 = String::from("world!"); let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used }
Listarea 8-18: Utilizarea operatorului + pentru a concatena două valori de tip String într-una nouă
String-ul s3 va conține textul Hello, world!. După această operație, s1 nu mai este valid, iar motivul pentru care am utilizat o referință la s2 este legat de semnătura metodei add, apelată prin operatorul +. Iată cum arată semnătura:
fn add(self, s: &str) -> String {Deși în biblioteca standard add este definit cu generice, noi am folosit tipuri specifice pentru a putea explica. Acest lucru se întâmplă automat când invoci metoda cu valori de tip String. Vom detalia genericele în Capitolul 10. Semnătura ne oferă indicii pentru a demistifica operatorul +.
Mai întâi, observăm că s2 este precedat de &, ceea ce indică faptul că adăugăm o referință la al doilea string. Aceasta este necesar, deoarece funcția add acceptă doar o referință &str pentru concatenare, nu două valori de tip String. Dar de ce funcționează codul din Listarea 8-18, având în vedere că &s2 este de fapt de tip &String şi nu &str?
Explicația este că compilatorul poate converti &String la &str prin intermediul unei coerciții de dereferențiere. Când apelăm metoda add, &s2 este convertit la &s2[..]. Aflăm mai multe despre aceasta în Capitolul 15. Deoarece add nu preia posesiunea parametrului s, s2 rămâne un String valid după operație.
În al doilea rând, add preia posesiunea lui self, care nu este marcat cu un &. Acest lucru înseamnă că s1 va fi consumat de apelul add și nu va mai putea fi folosit în continuare. Prin urmare, instrucțiunea let s3 = s1 + &s2; poate părea că doar copiază string-urile pentru a crea unul nou, dar, de fapt, preia s1, adaugă la el conținutul copiat din s2, și returnează noua valoare. Astfel, în loc să efectueze multe copieri inutile, operația este de fapt mai eficientă.
Pentru concatenarea mai multor string-uri, folosirea operatorului + poate deveni incomodă:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = s1 + "-" + &s2 + "-" + &s3; }
Aici, s va fi tic-tac-toe. Însă, cu atâtea + și ", codul devine încărcat și greu de urmărit. Pentru cazuri mai complexe, putem apela la macro-ul format!:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = format!("{s1}-{s2}-{s3}"); }
Acest fragment de cod atribuie tot tic-tac-toe pentru s. Macro-ul format!, similar cu println!, nu afișează rezultatul pe ecran, ci returnează un String cu conținutul formatat. Varianta cu format! este clar mai lizibilă și nu preia posesiunea niciunui parametru, lucru de preferat în anumite contexte.
Accesarea elementelor unui string prin index
Accesul la caracterele unui string folosind indexul lor este o practică obișnuită în multe limbaje de programare. Cu toate acestea, în Rust, încercarea de a accesa elemente dintr-un String prin indexare va genera o eroare. Iată codul incorect prezentat în Listarea 8-19.
fn main() {
let s1 = String::from("hello");
let h = s1[0];
}Listarea 8-19: Tentativa de utilizare a indexării cu un String
Executarea acestui cod va produce următoarea eroare:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `String` cannot be indexed by `{integer}`
--> src/main.rs:3:13
|
3 | let h = s1[0];
| ^^^^^ `String` cannot be indexed by `{integer}`
|
= help: the trait `Index<{integer}>` is not implemented for `String`
= help: the following other types implement trait `Index<Idx>`:
<String as Index<RangeFrom<usize>>>
<String as Index<RangeFull>>
<String as Index<RangeInclusive<usize>>>
<String as Index<RangeTo<usize>>>
<String as Index<RangeToInclusive<usize>>>
<String as Index<std::ops::Range<usize>>>
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` due to previous error
Mesajul de eroare explică problema: string-urile din Rust nu permit folosirea indexării. De ce se întâmplă asta? Pentru a înțelege motivul, trebuie să discutăm despre modul în care Rust gestionează string-urile în memorie.
Structura internă a unui string
Un String este practic un Vec<u8>. Să analizăm câteva exemple de string-uri corect codificate în UTF-8 din Listarea 8-14. Începem cu exemplul acesta:
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שָׁלוֹם"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
Aici, len va fi 4, ceea ce înseamnă că vectorul care păstrează string-ul "Hola" are o lungime de 4 bytes. Fiecare literă ocupă 1 byte în codificarea UTF-8. Totuși, următoarea linie te poate surprinde. (Observă că acest string începe cu litera mare chirilică Ze, nu numărul 3.)
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שָׁלוֹם"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
La întrebarea despre lungimea string-ului, ai putea răspunde că este de 12. În realitate, Rust îți spune că este 24: acesta este numărul de bytes necesari pentru a codifica "Здравствуйте" în UTF-8. Acest lucru se datorează faptului că fiecare valoare scalară Unicode în acel string ocupă 2 bytes. Așadar, un indice al octeților string-ului nu corespunde întotdeauna unei valori scalare Unicode valide. Ca exemplu, iată un cod Rust incorect:
let hello = "Здравствуйте";
let answer = &hello[0];Știm că answer nu va fi З, prima literă. În codificarea UTF-8, primul byte pentru З este 208, iar al doilea este 151. Prin urmare, ai putea crede că answer ar trebui să fie 208, dar 208 nu reprezintă un caracter valid de sine stătător. Acest rezultat nu este probabil ceea ce un utilizator ar aștepta când solicită prima literă a string-ului; în orice caz, Rust nu are la dispoziție alte date la indicele de byte zero. În general, utilizatorii nu doresc valoarea octetului în sine, chiar dacă string-ul constă doar din litere latine: dacă &"hello"[0] ar fi un cod valid care returnează valoarea octetului, acesta ar returna 104, nu h.
Concluzia este că pentru a evita generarea unei valori neașteptate și introducerea de bug-uri ce ar putea rămâne nedetectate pentru o perioadă, Rust alege să nu compileze acest cod deloc, prevenind astfel confuziile încă din fazele incipiente ale dezvoltării software.
Octeți, valori scalare și grupuri de grafeme
Un alt aspect legat de UTF-8 este faptul că există trei moduri în care Rust consideră string-urile: ca octeți, valori scalare, și grupuri de grafeme (cel mai apropiat termen pentru ceea ce numim "litere").
De exemplu, cuvântul hindi "नमस्ते" scris în scriptul Devanagari este stocat ca un vector de valori u8 în felul următor:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
Acestea sunt 18 octeți și reprezintă modul în care calculatoarele stochează aceste date. Privindu-le ca valori scalare Unicode, care sunt reprezentate de tipul char în Rust, acești octeți arată astfel:
['न', 'म', 'स', '्', 'त', 'े']
Avem aici șase valori char, dar a patra și a șasea nu reprezintă litere: ele sunt diacritice fără sens de sine stătător. În final, dacă le privim ca grupuri de grafeme, obținem cele patru "litere" care formează cuvântul hindi:
["न", "म", "स्", "ते"]
Rust oferă diferite metode de interpretare a datelor brute ale unui string pentru ca fiecare program să își poată alege abordarea necesară, indiferent de limba umană în care sunt datele.
Un motiv suplimentar pentru care Rust nu permite indexarea unui String pentru a extrage un caracter este că se așteaptă ca operațiile de indexare să se efectueze într-un timp constant (O(1)). Dar acest lucru nu poate fi garantat cu String, deoarece Rust ar trebui să parcurgă conținutul de la început până la index pentru a identifica numărul de caractere valide.
Secționarea string-urilor
A accesa un string folosind indici este adesea nerecomandat deoarece nu este clar ce tip de valoare ar trebui să returneze operația de indexare: un octet, un caracter, un cluster de grafeme sau o secțiune de string. Din acest motiv, Rust necesită specificații mai exacte atunci când vrei să folosești indici pentru a obține secțiuni de string.
În loc să te bazezi pe [] cu un singur număr, este posibil să utilizezi [] cu un diapazon pentru a crea o secțiune ce include anumiți octeți:
#![allow(unused)] fn main() { let hello = "Здравствуйте"; let s = &hello[0..4]; }
În exemplul de mai sus, s este un &str care cuprinde primii 4 octeți din string. Anterior, am menționat că fiecare caracter este reprezentat de 2 octeți, deci s va conține Зд.
Dacă am încerca să extragem doar o parte a octeților unui caracter, cum ar fi cu &hello[0..1], Rust va genera o eroare la rulare asemănătoare celei întâmpinate când se accesează un index invalid într-un array:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at 'byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`', src/main.rs:4:14
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Utilizează cu atenție diapazoanele când creezi secțiuni de string, deoarece acest lucru poate duce la erori grave în timpul execuției programului.
Metode de iterație pentru string-uri
Când lucrezi cu părți din string-uri, e important să specifici clar dacă dorești să accesezi caractere sau octeți. Dacă ai nevoie de valori scalare Unicode individuale, folosește metoda chars. Dacă aplici chars pe textul “Зд”, vei obține două valori de tip char, pe care le poți parcurge prin iterare pentru a accesa fiecare caracter:
#![allow(unused)] fn main() { for c in "Зд".chars() { println!("{c}"); } }
Acest exemplu de cod va afișa caracterele:
З
д
Pe de altă parte, metoda bytes îți returnează octeții individuali ai textului, ceea ce poate fi util în anumite scenarii:
#![allow(unused)] fn main() { for b in "Зд".bytes() { println!("{b}"); } }
Acest cod va afișa cei patru octeți care formează textul dat:
208
151
208
180
Este important să ții minte că o valoare scalară validă în Unicode poate fi alcătuită din mai mulți octeți.
Extragerea clusterelor de grafeme din string-uri, cum ar fi cele din scrierea Devanagari, este o operație complexă și, din acest motiv, nu este inclusă în biblioteca standard. Pentru această nevoie, poți găsi crate-uri specializate pe crates.io.
Simplitatea înșelătoare a string-urilor
Pentru a rezuma, lucrurile cu string-urile sunt complexe. Fiecare limbaj de programare alege diferit cum să îţi prezinte această complexitate. Rust optează pentru gestionarea corectă a datelor String ca opțiune standard în orice program Rust. Acest lucru înseamnă că trebuie să acorzi o atenție sporită procesării datelor UTF-8 din start. Această abordare scoate la iveală complexitatea string-urilor mai mult decât în alte limbaje, însă astfel, eviți întâmpinarea erorilor legate de caractere non-ASCII în etapele avansate de dezvoltare a proiectelor tale.
Partea încurajatoare este că biblioteca standard vine la pachet cu multe funcționalități, bazate pe String și &str, care sunt gândite să ajute la navigarea cu succes prin aceste complexități. Nu rata documentația, unde vei găsi metode valoroase cum ar fi contains, pentru căutarea într-un string, sau replace, pentru înlocuirea secțiunilor dintr-un string cu alte string-uri.
Acum, să ne îndreptăm atenția spre ceva mai simplu: hash map-urile!
Utilizarea hash map-urilor pentru a asocia chei cu valori
Ultima dintre colecțiile fundamentale pe care le vom discuta este hash map-ul. Structura HashMap<K, V> permite stocarea unei asocieri între chei de tipul K și valori de tipul V, printr-o funcție de hash care stabilește cum sunt așezate aceste chei și valori în memorie. Această structură de date este cunoscută în multe limbaje de programare sub diverse nume precum hash, map, object, hash table, dictionary sau associative array.
Hash map-urile sunt de mare ajutor atunci când dorești să accesezi datele folosind o cheie de orice tip, nu un index, cum este cazul la vectori. De exemplu, într-un joc, poți urmări scorul diferitelor echipe folosind un hash map în care cheile sunt numele echipelor, iar valorile sunt scorurile acestora. Astfel, cu numele unei echipe, poți să obții rapid scorul aferent.
În această secțiune, vom explora funcționalitățile de bază ale hash map-urilor, dar biblioteca standard oferă multe alte capabilități interesante asociate cu HashMap<K, V>. Pentru detalii suplimentare, te încurajăm să consulți documentația bibliotecii standard.
Cum să creezi un hash map nou
Pentru a inițializa un hash map gol, putem folosi metoda new și apoi adăugăm elemente prin metoda insert. În Listarea 8-20, monitorizăm scorurile a două echipe, denumite Blue și Yellow. Echipa Blue debutează cu 10 puncte, pe când Yellow începe jocul cu 50 de puncte.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); }
Listarea 8-20: Inițializarea unui hash map nou și inserarea unor perechi cheie-valoare
Este important de observat că, înainte de toate, trebuie să includem HashMap în sfera noastră de lucru prin intermediul instrucțiunii use, din secțiunea de colecții a bibliotecii standard. Dintre cele trei tipuri principale de colecții, hash map-ul este cel mai rar utilizat, motiv pentru care nu este importat implicit în preludiul Rust. Hash map-urile beneficiază, de asemenea, de un suport mai limitat din partea bibliotecii standard - nu există, de exemplu, un macro predefinit pentru construirea acestora.
Similar vectorilor, hash map-urile păstrează datele în heap. Acest HashMap utilizează chei de tip String și valori de tip i32. Și, precum în cazul vectorilor, has hmap-urile sunt colecții omogene - toate cheile trebuie să fie de același tip și toate valorile de alt tip, dar uniform între ele.
Accesul la valorile dintr-un hash map
Noi putem extrage o valoare dintr-un hash map oferind cheia corespunzătoare metodei get, după cum se arată în Listarea 8-21.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); let team_name = String::from("Blue"); let score = scores.get(&team_name).copied().unwrap_or(0); }
Listarea 8-21: Obținerea scorului pentru echipa Albastră din hash map
În acest exemplu, variabila score va prelua valoarea asociată echipei Albastre, care va fi 10. Metoda get returnează Option<&V>, semnificând că dacă nu se află o valoare pentru cheia dată în hash map, get va oferi ca răspuns None. În acest program, opționalitatea este tratată prin folosirea metodei copied, care transformă Option<&i32> în Option<i32>, iar apoi, cu ajutorul metodei unwrap_or, setăm score la zero dacă hash map-ul scores nu conține o valoare pentru cheia respectivă.
Pentru a parcurge fiecare pereche cheie/valoare dintr-un hash map, noi putem folosi o abordare similară cu cea pentru vectori, aplicând o buclă for:
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); for (key, value) in &scores { println!("{key}: {value}"); } }
Acest fragment de cod va afișa fiecare pereche într-o ordine aleatoare:
Galben: 50
Albastru: 10
Hash map-uri și posesiunea datelor
Când inserăm date într-un hash map, ce se întâmplă cu acestea depinde de tipul lor. Dacă tipul de date implementează trăsătura Copy, cum este cazul lui i32, atunci valorile sunt duplicate și inserate în hash map fără a-și pierde originalul. Pe de altă parte, pentru tipuri de date cu posesiune unică, precum String, inserarea înseamnă transferul posesiunii: hash map-ul devine noul proprietar al acestor valori. Următoarea listare ilustrează această comportare:
fn main() { use std::collections::HashMap; let field_name = String::from("Favorite color"); let field_value = String::from("Blue"); let mut map = HashMap::new(); map.insert(field_name, field_value); // field_name and field_value are invalid at this point, try using them and // see what compiler error you get! }
Listarea 8-22: Ilustrarea modului în care hash map-ul devine posesorul cheilor și valorilor după ce sunt inserate
După această operațiune de inserare, nu mai putem utiliza variabilele field_name și field_value; ele au fost permutate în hash map și acum hash map-ul deține drepturile asupra lor.
Dacă dorim să păstrăm drepturile asupra datelor și să inserăm doar referințe în hash map, va trebui să ne asigurăm că acele date originale rămân valabile pentru toată durata de viață a hash map-ului. Această temă este aprofundată în secțiunea despre „Validarea referințelor prin durate de viață”, pe care o vom explora în Capitolul 10.
Cum actualizăm un hash map
Deși numărul de perechi cheie-valoare dintr-un hash map poate crește, fiecare cheie unică poate avea atribuită o singură valoare în același timp (ceea ce nu este valabil și invers; spre exemplu, echipa Blue și echipa Yellow ar putea ambele să aibă valoarea 10 în hash map-ul scores).
Când dorești să schimbi datele dintr-un hash map, trebuie să alegi cum să procedezi atunci când o cheie are deja atribuită o valoare. Există câteva opțiuni: poți înlocui valoarea veche cu cea nouă, ignorând complet valoarea anterioară. Poți păstra valoarea veche și să ignori pe cea nouă, adăugându-o doar dacă cheia nu are încă o valoare asignată. Sau, poți combina valoarea veche cu cea nouă. Să explorăm cum putem aplica fiecare dintre aceste metode!
Înlocuirea unei valori
Când adăugăm într-un hash map o pereche de cheie și valoare, iar mai apoi inserăm din nou aceeași cheie cu o valoare diferită, valoarea asociată cu cheia respectivă va fi înlocuită. Chiar dacă în codul prezentat în Listarea 8-23 executăm funcția insert de două ori, hash map-ul va conține o singură pereche de cheie și valoare, deoarece ambele inserări se referă la cheia echipei Blue.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Blue"), 25); println!("{:?}", scores); }
Listarea 8-23: Înlocuirea unei valori asociate cu o anumită cheie
Acest cod va afișa rezultatul {"Blue": 25}. Prima valoare, 10, a fost înlocuită cu noua valoare, 25.
Adăugarea unei chei și valori numai dacă cheia lipsește
Un scenariu frecvent în lucrul cu hash map-uri este verificarea prezenței unei chei specifice înainte de a adăuga o valoare. Dacă cheia este deja prezentă, valoarea existentă trebuie să rămână neschimbată. În caz contrar, cheia și valoarea ei trebuie inserate în map.
Pentru aceasta, hash map-urile oferă o metodă specială numită entry, care primește ca parametru cheia de verificat. Rezultatul metodei entry este o enumerare Entry care indică dacă o valoare există sau nu pentru acea cheie. De exemplu, dacă vrem să verificăm dacă echipa Yellow are o valoare atribuită cheii sale și, în caz negativ, să inserăm valoarea 50; procedăm similar pentru echipa Blue. Utilizând API-ul entry, codul arată ca în Listarea 8-24.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.entry(String::from("Yellow")).or_insert(50); scores.entry(String::from("Blue")).or_insert(50); println!("{:?}", scores); }
Listarea 8-24: Utilizarea metodei entry pentru a insera valori doar când cheia nu există
Metoda or_insert de pe Entry returnează o referință mutabilă la valoarea asociată cheii respective, dacă cheia există. Dacă nu, aceasta inserează valoarea primită ca parametru pentru cheia respectivă și returnează o referință mutabilă la noua valoare inserată. Această abordare este mult mai elegantă și mai eficientă decât să implementăm manual această logică, având și avantajul unei mai bune compatibilități cu verificatorul de împrumuturi.
Execuția codului din Listarea 8-24 va genera rezultatul {"Yellow": 50, "Blue": 10}. Prima invocare a metodei entry va adăuga cheia pentru echipa Yellow cu valoarea 50, deoarece aceasta nu are o valoare predefinită. Cea de-a doua invocare nu va modifica hash map-ul, deoarece echipa Blue dispune deja de valoarea 10.
Actualizarea unei valori în funcție de valoarea precedentă
Folosirea hash map-urilor pentru a actualiza valori pe baza celor anterioare este o practică obișnuită. De exemplu, în Listarea 8-25, codul prezentat numără cât de des apare fiecare cuvânt într-un text dat. Folosim un hash map cu cuvintele drept chei și creștem valoarea asociată pentru a contoriza numărul de apariții ale fiecărui cuvânt. Dacă întâlnim un cuvânt pentru prima dată, inserăm inițial valoarea 0.
fn main() { use std::collections::HashMap; let text = "hello world wonderful world"; let mut map = HashMap::new(); for word in text.split_whitespace() { let count = map.entry(word).or_insert(0); *count += 1; } println!("{:?}", map); }
Listarea 8-25: Numărarea aparițiilor cuvintelor cu ajutorul unui hash map care stochează cuvinte și contoare
Acest cod va rezulta în afișarea {"world": 2, "hello": 1, "wonderful": 1}. Însă, ordinea acestor perechi cheie/valoare ar putea fi diferită, deoarece, așa cum am menționat în secțiunea “Accesarea valorilor într-un hash map”, ordinea de iterație a unui hash map este întâmplătoare.
Metoda split_whitespace generează un iterator care oferă acces la sub-șirurile de caractere, separate prin spații, din text. Metoda or_insert furnizează o referință mutabilă (&mut V) la valoarea corespunzătoare cheii indicate. Stocăm această referință mutabilă în variabila count și, pentru a-i modifica valoarea, folosim dereferențierea cu ajutorul simbolului asterisc (*). Referința mutabilă își încheie domeniul de vizibilitate la finalul buclei for, astfel încât toate modificările sunt sigure și respectă regulile de împrumutare ale limbajului Rust.
Funcția de hash în HashMap
Implicit, HashMap folosește o funcție de hash denumită SipHash. Aceasta oferă protecție împotriva atacurilor cibernetice de tip Denial of Service (DoS) care vizează tabelele de hash. SipHash nu este neapărat cel mai rapid algoritm de hash, însă avantajele în ceea ce privește securitatea compensează pentru scăderea în performanță. Dacă, în urma analizei performanței codului tău, descoperi că funcția de hash standard este prea înceată, poți opta pentru un alt algoritm de hash alegând un hasher diferit. Un hasher este un tip de date ce implementează trăsătura BuildHasher. Vom explora conceptul de trăsături și implementarea acestora mai detaliat în Capitolul 10. Nu este obligatoriu să scrii un hasher de la zero; pe crates.io găsești biblioteci create de comunitatea Rust care includ hasheri cu o varietate de algoritmi de hash cunoscuți.
Sumar
Aflăm că vectorii, string-urile și hash map-urile sunt esențiali pentru manipularea și gestionarea datelor în programe. În continuare, vei avea prilejul să aplici cunoștințele dobândite prin rezolvarea următoarelor sarcini:
- În cazul unei liste de numere întregi, folosește un vector pentru a determina mediana (elementul din mijlocul listei sortate) și moda (elementul care apare de cele mai multe ori; un hash map va fi de ajutor aici).
- Transformă string-urile în pig latin în felul următor: mută prima consoană a fiecărui cuvânt la sfârșitul acestuia și adaugă sufixul "ay", ca în "first" care devine "irst-fay". Cuvintele ce încep cu vocală primesc sufixul "hay" la final ("apple" se transformă în "apple-hay"), având în vedere specificitățile codificării UTF-8.
- Utilizând un hash map și vectori, dezvoltă o interfață text prin care un utilizator poate adăuga nume de angajați la un anumit departament într-o firmă, de exemplu "Adaugă pe Sally în departamentul de Inginerie" sau "Adaugă pe Amir în departamentul de Vânzări". În plus, asigură posibilitatea de a obține lista angajaților unui departament sau lista completă a angajaților companiei, împărțită pe departamente, organizată alfabetic.
Documentația API a bibliotecii standard detaliază metodele disponibile pentru vectori, string-uri și hash map-uri, care îți vor fi utile pentru a completa aceste exerciții.
Pe măsură ce programarea se complică și operațiunile pot eșua, este esențial să învățăm despre gestionarea erorilor. Este subiectul pe care îl vom aborda în continuare!
Tratarea erorilor
În lumea dezvoltării software-ului, întâlnirea cu erori este inevitabilă. Din acest motiv, Rust include diverse mecanisme pentru a aborda situațiile în care lucrurile nu funcționează conform așteptărilor. Rust te forțează adesea să recunoști posibilitatea apariției unei erori și să iei măsuri corespunzătoare înainte ca codul să fie compilat. Această abordare îmbunătățește fiabilitatea programului tău, asigurându-te că vei identifica și gestiona erorile în mod adecvat înainte ca software-ul să ajungă în mediul de producție.
Rust clasifică erorile în două categorii principale: erori recuperabile și irecuperabile. În cazul unei erori recuperabile, cum ar fi "fișier negăsit", de obicei, dorim să informăm utilizatorul și să încercăm din nou acțiunea. Pe de altă parte, erorile irecuperabile indică prezența unor bug-uri, ca de exemplu o tentativă de acces la o zonă din afara limitelor unui array, caz în care este imperios să oprim programul de îndată.
Multe limbaje de programare nu fac distincție între aceste tipuri de erori și le abordează în același mod, adesea prin intermediul excepțiilor. Rust nu utilizează excepții. În schimb, oferă tipul Result<T, E> pentru gestionarea erorilor recuperabile și macro-ul panic! pentru situațiile irecuperabile, când execuția programului trebuie oprită de urgență. În acest capitol, vom începe prin a discuta folosirea panic! și apoi ne vom concentra pe întoarcerea valorilor de tip Result<T, E>. De asemenea, vom lua în considerare când este potrivit să recuperăm după o eroare și când este mai bine să întrerupem execuția.
Gestionarea erorilor irecuperabile cu panic!
În codul tău pot apărea situații neașteptate și iremediabile. Pentru aceste cazuri, Rust oferă macro-ul panic!. Poți declanșa o panică în două moduri: fie realizând o acțiune care duce la panică în codul nostru - de exemplu, accesând un array dincolo de capacitatea sa, fie apelând direct macro-ul panic!. Ambele variante vor provoca o panică în programul nostru care, implicit, va afișa un mesaj de eroare, va desface stiva, va efectua curățarea acesteia și va încheia execuția programului. Prin setarea unei variabile de mediu, poți de asemenea instrui Rust să afișeze stiva de apeluri în momentul unei panici, facilitând astfel identificarea cauzei problemei.
Gestionarea panicii: Dezactivarea stivei sau abandonarea programului
Implicit, când se declanșează o panică, programul începe procesul de dezactivare a stivei (unwinding): Rust urcă stiva invers și eliberează memoria ocupată de datele din fiecare funcție întâlnită. Totuși, acest procedeu este destul de laborios. De aceea, Rust îți oferă opțiunea de abandonare, care oprește programul direct, fără a elibera resursele utilizate. În acest caz, sistemul de operare va trebui să curețe memoria folosită de program. Dacă ai nevoie să minimizezi dimensiunea executabilului în proiectul tău, poți opta pentru încheierea abruptă a programului în caz de panică prin adăugarea liniei
panic = 'abort'în secțiunile[profile]relevante din fișierul Cargo.toml. De exemplu, pentru a seta această opțiune în modul Release, inserează:[profile.release] panic = 'abort'
Să folosim panic! într-un program simplu:
Numele fișierului: src/main.rs
fn main() { panic!("crash and burn"); }
Când executăm programul, vom observa un mesaj similar cu acesta:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished dev [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at 'crash and burn', src/main.rs:2:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Utilizarea panic! generează mesajul de eroare afișat în ultimele două rânduri. Primul rând îți prezintă mesajul nostru de panică, precum și locul din sursa noastră unde panica a avut loc: src/main.rs:2:5 ne indică faptul că problema se află la linia a doua, caracterul cinci din fișierul nostru src/main.rs.
În exemplul nostru, linia indicată ne duce direct la codul scris de noi, unde găsim apelul macro-ului panic!. Cu toate acestea, uneori apelul panic! s-ar putea să fie în cod la care codul nostru face referire și atunci, numele fișierului și numărul liniei raportate de mesajul de eroare vor semnala locația din codul altei persoane unde a fost invocat panic!, nu punctul din codul nostru care a cauzat în ultimă instanță invocarea panic!. Putem să folosim backtrace-ul pentru a urmări din ce funcții vine apelul panic! și să identificăm astfel partea din codul nostru responsabilă pentru eroare. Vom discuta backtrace-urile mai în detaliu în curând.
Urmărirea stivei cu panic!
Să analizăm un exemplu în care panic! este declanșat de o bibliotecă din pricina unei greșeli în codul nostru, în loc de a proveni direct din codul care invocă macrocomanda. Listarea 9-1 prezintă cod care încearcă să acceseze un index inexistent într-un vector, dincolo de limita indexurilor valide.
Numele fișierului: src/main.rs
fn main() { let v = vec![1, 2, 3]; v[99]; }
Listarea 9-1: Tentativa de accesare a unui element în afara limitelor unui vector, ce va declanșa un apel la panic!
În acest caz, încercăm să accesăm elementul cu indexul 100 din vectorul nostru (care ar fi de fapt la indexul 99, deoarece numerotarea începe de la zero), însă vectorul nostru conține doar 3 elemente. In această situație, Rust va apela panica. Folosirea operatorului [] presupune a extrage un element, dar când indexul este incorect, Rust nu poate furniza un răspuns adecvat.
În limbajul C, citirea datelor dincolo de capătul unei structuri de date este un comportament nedefinit. S-ar putea să primești date aleatoare din memoria ce corespunde acelui index în structura de date, chiar dacă acea porțiune de memorie nu face parte din structură. Acest fenomen, cunoscut sub numele de supracitire a buffer-ului, poate crea vulnerabilități de securitate dacă un atacator reușește să modifice indexul în așa fel încât să citească date neautorizate, plasate în memorie după structura de date.
Pentru a proteja programul tău de vulnerabilități, Rust va opri execuția dacă încerci să accesezi un element la un index inexistent, refuzând astfel să continue. Să vedem cum se întâmplă asta:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished dev [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:4:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Mesajul de eroare arată că greșeala se află la linia 4 din fișierul nostru main.rs, unde am încercat să accesăm elementul cu indexul 99. Nota atașată ne spune că putem seta variabila de mediu RUST_BACKTRACE pentru a primi un backtrace detaliat, care să ne arate exact ce a cauzat eroarea. Un backtrace reprezintă o listă cu toate funcțiile invocate până în punctul erorii. Interpretarea unui backtrace în Rust se face la fel ca în alte limbaje: pornește de la începutul listei și continuă să citești până când recunoști fișiere pe care le-ai scris tu. Acolo se găsește originea problemei. Liniile care preced această marcă sunt codul apelat de codul tău; cele care urmează sunt cele care l-au apelat pe al tău. Aceasta implică posibil codul fundamental Rust, librăriile standard sau crate-urile utilizate. Să obținem un backtrace setând variabila de mediu RUST_BACKTRACE la orice altceva decât 0. În Listarea 9-2 vei găsi un exemplu de afișaj similar cu cel pe care îl vei întâlni.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:4:5
stack backtrace:
0: rust_begin_unwind
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/std/src/panicking.rs:584:5
1: core::panicking::panic_fmt
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/panicking.rs:142:14
2: core::panicking::panic_bounds_check
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/panicking.rs:84:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/slice/index.rs:242:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/slice/index.rs:18:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/alloc/src/vec/mod.rs:2591:9
6: panic::main
at ./src/main.rs:4:5
7: core::ops::function::FnOnce::call_once
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/ops/function.rs:248:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
Listarea 9-2: Backtrace generat de panic!, vizibil când variabila de mediu RUST_BACKTRACE este activă
Este o mulțime de informație afișată! Afișajul pe care îl vei vedea poate varia în funcție de sistemul de operare și versiunea de Rust utilizată. Pentru a obține backtrace-uri detaliate ca acestea, este necesar ca simbolurile de depanare să fie activate. Aceste simboluri sunt activate automat când folosești cargo build sau cargo run fară opțiunea --release, cum este cazul aici.
În afișajul din Listarea 9-2, linia 6 din backtrace ne conduce direct la linia din proiectul nostru care generează problema: linia 4 din src/main.rs. Dacă dorim să evităm panica în program, ar trebui să începem analiza acolo unde prima linie indică un fișier creat de noi. De exemplu, în Listarea 9-1, unde codul a fost scris intenționat pentru a genera o panică, soluția pentru a evita aceasta este să nu accesăm un element dintr-un vector ce depășește limitele indicilor acestuia. Când codul tău generează o panică în viitor, va trebui să identifici care acțiune și valori conduc la acea panică și ce ar trebui de fapt să facă codul tău.
Vom reveni la discuția despre panic!, când ar trebui și când nu ar trebui să folosim panic! pentru a trata erorile, în secțiunea „Când să folosim panic! și când nu” mai târziu în acest capitol. În continuare, vom explora cum să gestionăm recuperarea dintr-o eroare folosind Result.
Gestionarea erorilor recuperabile cu Result
Nu toate erorile sunt atât de grave încât să necesite oprirea completă a programului. Când o funcție eșuează, uneori motivul poate fi ușor de interpretat și de abordat. Spre exemplu, dacă încerci să deschizi un fișier iar operațiunea nu reușește pentru că fișierul lipsește, ai putea să optezi pentru crearea fișierului în loc să oprești programul.
Reamintește-ți din Capitolul 2, secțiunea „Gestionarea potențialelor eșecuri cu Result” . Am discutat atunci că enum-ul Result este definit cu două variante: Ok și Err.
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
T și E sunt parametri de tip generic. Vom discuta despre generice mai pe larg în Capitolul 10. Important de știut acum este că T reprezintă tipul valorii returnate în caz de succes de varianta Ok, iar E tipul erorii returnate în caz de eșec de varianta Err. Cu acești parametri generici, tipul Result poate fi utilizat în multe contexte diferite, unde valorile succesului și ale erorii pot varia.
Imaginează-ți că apelăm o funcție care returnează o valoare Result pentru că funcția ar putea să nu reușească. În Listarea 9-3, încercăm să deschidem un fișier.
Numele fișierului: src/main.rs
use std::fs::File; fn main() { let greeting_file_result = File::open("hello.txt"); }
Listarea 9-3: Deschiderea unui fișier
Tipul returnat de File::open este Result<T, E>. În acest context, T este std::fs::File, adică un descriptor al fișierului, iar E este std::io::Error. Acest lucru înseamnă că apelul la File::open poate reuși sau eșua — fișierul să nu existe sau să nu avem permisiunea necesară. Funcția File::open trebuie astfel să ne poată informa despre reușită sau eșec și să ne furnizeze descriptorul fișierului sau date despre eroare. Result este exact mecanismul care transmite aceste informații.
Dacă File::open reușește, variabila greeting_file_result va conține o instanță Ok cu descriptorul fișierului. Dacă eșuează, va conține Err cu informații suplimentare privind eroarea survenită.
Trebuie să extindem codul din Listarea 9-3 pentru a gestiona diferite rezultate ale funcției File::open. Listarea 9-4 prezintă cum putem folosi expresia match pentru aceasta, discutată în Capitolul 6.
Numele fișierului: src/main.rs
use std::fs::File; fn main() { let greeting_file_result = File::open("hello.txt"); let greeting_file = match greeting_file_result { Ok(file) => file, Err(error) => panic!("Problem opening the file: {:?}", error), }; }
Listarea 9-4: Utilizarea match pentru gestionarea variantelor Result
La fel ca Option, și Result și variantele sale sunt importate automat, deci nu avem nevoie să precizăm Result:: înainte de Ok și Err în ramurile match.
Când rezultatul este Ok, codul extrage valoarea file din varianta Ok și o atribuie variabilei greeting_file. Ulterior, descriptorul fișierului poate fi folosit pentru citire sau scriere.
Ramura pentru Err din match gestionează situația eșecului de la File::open. În acest exemplu, optăm pentru panică, prin panic!. Dacă nu există un fișier denumit hello.txt în directoriul nostru curent atunci când rulăm codul, panic! ne va arăta următoarea ieșire:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished dev [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at 'Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }', src/main.rs:8:23
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Ca de obicei, această ieșire ne detaliază cu precizie problema întâmpinată.
Diferențiind reacția la erori
Codul prezentat în Listarea 9-4 va genera o panică (panic!) indiferent de cauza eșecului funcției File::open. Totuși, noi intenționăm să abordăm diferit motivele specifice ale eșecului: dacă File::open nu reușește datorită inexistenței fișierului, intenționăm să creăm fișierul și să returnăm un descriptor către acesta. În schimb, dacă File::open eșuează din alte motive - de exemplu, lipsa permisiunilor de acces - dorim să menținem reacția inițială de panică, așa cum este ilustrat în Listarea 9-4. Pentru a gestiona acest comportament, includem o expresie match suplimentară, ilustrată în Listarea 9-5.
Numele fișierului: src/main.rs
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {:?}", e),
},
other_error => {
panic!("Problem opening the file: {:?}", other_error);
}
},
};
}Listarea 9-5: Abordări diferențiate ale gestionării erorilor
Tipul valorii returnate de File::open când întâlnește o eroare (Err) este io::Error, o structură definită în biblioteca standard. Această structură include metoda kind, prin care putem obține o valoare de tip io::ErrorKind. Enum-ul io::ErrorKind, de asemenea furnizat de biblioteca standard, categorizează potențialele erori ce pot apărea în timpul unei operațiuni io. Pentru cazul nostru, ne folosim de varianta ErrorKind::NotFound, care semnalizează că fișierul pe care dorim să-l deschidem nu există încă. Acest lucru ne conduce la aplicarea unui match pe variabila greeting_file_result, dar în interiorul acestuia aplicăm și un match pe rezultatul apelării error.kind().
Ne interesează să verificăm, în cadrul match-ului intern, dacă valoarea întoarsă de error.kind() corespunde cu varianta NotFound a enum-ului ErrorKind. Dacă este așa, înaintăm cu încercarea de creare a fișierului folosind File::create. Însă, cum și această operațiune poate să eșueze, introducem un al doilea braț în expresia de match din interior. În situația în care crearea fișierului nu este posibilă, se va afișa un mesaj de eroare diferit. Cel de-al doilea braț al match-ului exterior rămâne neschimbat, astfel programul va genera o panică pentru orice alt tip de eroare, în afara erorii generată de absența fișierului.
Metode alternative la utilizarea
matchcuResult<T, E>Expresia
matcheste extrem de utilă, însă poate deveni încărcată în anumite contexte. În Capitolul 13, veți descoperi closures, care facilitează lucrul cu diverse metode definite pentruResult<T, E>. Aceste metode oferă abordări mai concise comparativ cumatchpentru gestionarea valorilorResult<T, E>în cod.De pildă, vă prezentăm o altă cale de a implementa logica din Listarea 9-5, utilizând de această dată closures și metoda
unwrap_or_else:use std::fs::File; use std::io::ErrorKind; fn main() { let greeting_file = File::open("hello.txt").unwrap_or_else(|error| { if error.kind() == ErrorKind::NotFound { File::create("hello.txt").unwrap_or_else(|error| { panic!("Problem creating the file: {:?}", error); }) } else { panic!("Problem opening the file: {:?}", error); } }); }Deși acest fragment de cod produce același efect ca Listarea 9-5, el nu conține niciun
match, ceea ce îl face mai curat și mai lizibil. Vă sugerăm să reveniți la acest exemplu după parcurgerea Capitolului 13 și să consultați documentația metodeiunwrap_or_elsedin biblioteca standard a Rust. Vei descoperi că există multe alte metode care pot simplifica expresii complexe și îmbinate dematch, mai ales atunci când tratați erori în codul dvs.
Scurtături pentru panică la eroare: unwrap și expect
Deși este destul de eficientă, utilizarea expresiei match poate deveni oneroasă și nu întotdeauna exprimă clar intenția programatorului. Tipul Result<T, E> dispune de numeroase metode auxiliare destinate efectuării de operații specifice. Una dintre aceste metode este unwrap, care funcționează similar cu expresia match pe care am detaliat-o în Listarea 9-4. Dacă Result este varianta Ok, unwrap extrage și returnează valoarea conținută. În schimb, dacă Result este varianta Err, unwrap va apela macro-ul panic!. Iată unwrap în aplicare:
Numele fișierului: src/main.rs
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt").unwrap(); }
Dacă executăm acest cod fără a avea fișierul hello.txt, vom întâlni un mesaj de eroare generat de apelul panic! pe care îl face metoda unwrap:
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: Os {
code: 2, kind: NotFound, message: "No such file or directory" }',
src/main.rs:4:49
Metoda expect ne oferă posibilitatea de a alege mesajul de eroare pentru panic!. Prin folosirea lui expect în locul lui unwrap și prin oferirea de mesaje explicite de eroare, îți poți clarifica intenția și facilita identificarea sursei unei erori fatale. Sintaxa metodei expect este următoarea:
Numele fișierului: src/main.rs
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt") .expect("hello.txt should be included in this project"); }
Expect se utilizează la fel cum procedăm cu unwrap: intenționăm să extragem descriptorul fișierului sau să declanșăm macro-ul panic!. Cu toate acestea, mesajul de eroare dat de expect când apelează panic! va fi textul specific pe care îl pasăm către expect, spre deosebire de mesajul prestabilit al lui unwrap. Iată cum arată în practică:
thread 'main' panicked at 'hello.txt should be included in this project: Os {
code: 2, kind: NotFound, message: "No such file or directory" }',
src/main.rs:5:10
În codul destinat producției, Rustaceanii aleg de obicei expect în loc de unwrap, furnizând mai multe detalii legate de motivul pentru care operațiunea ar trebui să reușească întotdeauna. În acest fel, dacă ipotezele tale se dovedesc a fi incorecte, vei dispune de mai multe informații utile pentru depanare.
Propagarea erorilor
Când o funcție se confruntă cu posibilitatea unui eșec în timpul executării, poți alege să nu soluționezi eroarea în interiorul acelei funcții. În schimb, poți redirecționa eroarea către codul care a inițiat apelul funcției, permițându-i să decidă cum să procedeze. Această abordare se numește propagarea erorii și conferă un grad mai mare de control codului apelant, care ar putea deține informații suplimentare sau o logică specifică pentru tratamentul erorii, comparativ cu ce este disponibil în contextul funcției tale.
De exemplu, în Listarea 9-6 este prezentată o funcție ce încearcă să citească numele de utilizator dintr-un fișier. Dacă fișierul nu există sau nu poate fi accesat, această funcție va returna erorile întâmpinate direct codului ce a solicitat funcția.
Numele fișierului: src/main.rs
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let username_file_result = File::open("hello.txt"); let mut username_file = match username_file_result { Ok(file) => file, Err(e) => return Err(e), }; let mut username = String::new(); match username_file.read_to_string(&mut username) { Ok(_) => Ok(username), Err(e) => Err(e), } } }
Listarea 9-6: Funcție care gestionează erorile prin match
Funcția prezentată poate fi scrisă într-o formă mult mai concisă. Totuși, pentru a înțelege mai bine gestionarea erorilor, vom începe cu o abordare manuală, pas cu pas. La final, vom prezenta și versiunea simplificată. Mai întâi, să ne concentrăm asupra tipului de retur: Result<String, io::Error>. Acesta indică faptul că funcția returnează Result<T, E>, unde parametrul generic T este specificat ca String, iar E ca io::Error.
Dacă funcția se execută corect, rezultatul va fi un Ok conținând un String—numele de utilizator citit din fișier. În cazul apariției unei erori, se va returna Err cu un io::Error, detaliind problema survenită. Alegem să folosim io::Error ca tip de eroare pentru că acesta este returnat atunci când operațiunile File::open sau read_to_string eșuează, acestea fiind funcțiile utilizate în cadrul funcției noastre.
Începem corpul funcției apelând funcția File::open. Gestionăm rezultatul Result printr-un match asemănător celui din Listarea 9-4. Dacă File::open reușește, variabila de tip șablon file, care acum stochează descriptorul fișierului, este asignată variabilei mutabile username_file, iar execuția funcției continuă. În caz de eroare Err, în loc să utilizăm macro-ul panic!, preferăm să ieșim din funcție folosind cuvântul cheie return, returnând direct eroarea primită de la File::open, acum stocată în variabila șablon e.
Dacă avem un descriptor de fișier valid în username_file, funcția trece la crearea unui nou String în variabila username. Apoi invocăm metoda read_to_string pe descriptorul din username_file pentru a citi conținutul fișierului în username. Metoda read_to_string returnează și ea un Result, deoarece poate eșua, chiar și când File::open a avut succes. Prin urmare, aplicăm un nou match pentru acest Result. Dacă read_to_string se finalizează cu succes, funcția noastră este și ea un succes și returnăm numele de utilizator din fișier, acum aflat în username, încapsulat într-un Ok. Dacă read_to_string dă greș, tratăm eroarea în mod similar cu cel din match-ul precedent, dar fără a mai folosi explicit cuvântul return, fiindcă aceasta este ultima expresie din funcție, iar valorile erorilor sunt întoarse implicit.
Codul care cheamă funcția noastră va trebui să gestioneze rezultatul: fie o valoare Ok ce conține un nume de utilizator, fie o valoare Err ce include o eroare io::Error. Depinde de codul apelant să decidă cum va proceda cu aceste rezultate. În cazul unei valori Err, codul respectiv poate alege să genereze panică folosind panic! și astfel să oprească execuția programului, să utilizeze un nume de utilizator prestabilit sau să caute numele de utilizator prin alte metode, care nu implică accesul la un fișier. Noi nu cunoaștem intențiile specifice ale codului apelant, prin urmare, transmitem informațiile despre succes sau eroare mai departe pentru ca acesta să le gestioneze în cel mai potrivit mod.
Această metodă de a transmite erorile este atât de răspândită în Rust, încât limbajul include operatorul ? pentru a simplifica acest proces.
Propagarea erorilor cu operatorul ?
Listarea 9-7 ne prezintă cum să folosim funcția read_username_from_file pentru a obține aceleași rezultate ca și în Listarea 9-6, dar de această dată folosind operatorul ?.
Numele fișierului: src/main.rs
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username_file = File::open("hello.txt")?; let mut username = String::new(); username_file.read_to_string(&mut username)?; Ok(username) } }
Listarea 9-7: O funcție care returnează erori către codul apelant folosind operatorul ?
Atunci când se pune operatorul ? după o valoare de tip Result, acesta funcționează similar cu expresiile match pe care le-am utilizat anterior pentru a gestiona valorile Result în Listarea 9-6. Dacă rezultatul de tip Result este Ok, conținutul lui Ok este returnat și execuția programului continuă. Dacă rezultatul este Err, atunci Err este returnat de întreaga funcție, ca și cum am folosi cuvântul cheie return, astfel propagând eroarea către codul care a invocat funcția.
Însă, există o diferență între expresiile match din Listarea 9-6 și operatorul ?: erorile asupra cărora este aplicat operatorul ? sunt trecute prin funcția from, definită de trăsătura From din biblioteca standard. Funcția from transformă valorile dintr-un tip în altul. Când operatorul ? invocă from, tipul erorii revine convertit la tipul de eroare specificat în semnătura funcției curente. Acest aspect se dovedește a fi util atunci când o funcție trebuie să returneze un singur tip de eroare pentru a reprezenta diferitele cauze care pot conduce la eșecul acesteia.
De exemplu, putem modifica funcția read_username_from_file prezentată în Listarea 9-7 astfel încât să returneze un tip propriu de eroare, denumit OurError, pe care îl definim noi. De asemenea, dacă implementăm impl From<io::Error> pentru OurError pentru a crea o instanță OurError dintr-un io::Error, apelurile operatorului ? din funcția read_username_from_file vor utiliza automat from pentru a converti erorile, fără să mai adăugăm cod suplimentar.
În cazul prezentat în Listarea 9-7, semnul ? de la sfârșitul apelului File::open va extrage valoarea dintr-un rezultat Ok și o va asigna variabilei username_file. Dacă întâmpinăm o eroare, operatorul ? va opri execuția funcției imediat și va transmite valoarea Err codului care a făcut apelul. Același principiu se aplică și pentru ? de la sfârșitul apelului read_to_string.
Operatorul ? reduce semnificativ redundanța codului și facilitează simplificarea implementării funcției. Mai mult, prin înlănțuirea directă a apelurilor de metode după ?, putem condensa codul și mai mult, aspect ilustrat în Listarea 9-8.
Numele fișierului: src/main.rs
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username = String::new(); File::open("hello.txt")?.read_to_string(&mut username)?; Ok(username) } }
Listarea 9-8: Lănțuirea metodelor după operatorul ?
Am inițializat noul string username la începutul funcției, ca și înainte. În loc să declarăm o variabilă username_file, acum apelăm metoda read_to_string imediat după File::open("hello.txt")?. Continuăm să folosim ? la sfârșitul lui read_to_string și returnăm un Ok care conține username dacă atât File::open, cât și read_to_string reușesc, evitând returnarea de erori. Practic, obținem aceeași funcționalitate ca în Listarea 9-6 și Listarea 9-7, dar printr-o scriere mai compactă și ergonomică.
Listarea 9-9 va prezenta cum să simplificăm și mai mult codul, utilizând fs::read_to_string.
Filename: src/main.rs
#![allow(unused)] fn main() { use std::fs; use std::io; fn read_username_from_file() -> Result<String, io::Error> { fs::read_to_string("hello.txt") } }
Listarea 9-9: Folosirea funcției fs::read_to_string pentru a evita deschiderea și citirea explicită a fișierului
Citirea conținutului unui fișier într-un string este o operaţie frecventă, iar biblioteca standard facilitează această operație prin funcția practică fs::read_to_string. Această funcție deschide fișierul, inițializează un nou String, citește conținutul fișierului, îl stochează în acel String și apoi îl returnează. Desigur, prin utilizarea fs::read_to_string nu putem ilustra în detaliu gestionarea erorilor, motiv pentru care am ales inițial metoda mai elaborată.
Unde poate fi folosit operatorul ?
Operatorul ? poate fi utilizat numai în funcții a căror valoare de retur este compatibilă cu tipul de valoare asupra căruia se aplică ?. Acest lucru se datorează faptului că operatorul ? este conceput pentru a efectua un retur prematur din funcție, similar cu expresia match pe care am descris-o în Listarea 9-6. În cazul Listării 9-6, match opera cu o valoare de tip Result, iar ramura de retur prematur returna o valoare Err(e). Funcția trebuie să aibă ca tip de retur un Result pentru a fi compatibil cu acțiunea de return.
În Listarea 9-10 vom vedea ce eroare apare atunci când utilizăm operatorul ? într-o funcție main care are un tip de retur incompatibil cu tipul valorii pentru care aplicăm ?:
Numele fișierului: src/main.rs
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")?;
}Listarea 9-10: Tentativa de a folosi ? în funcția main care returnează () nu va funcționa
Acest cod încearcă să deschidă un fișier, operațiune care poate să eșueze. Operatorul ? este aplicat valorii Result returnate de File::open, însă funcția main are definit ca tip de retur (), nu Result. Când încercăm să compilăm acest cod, ne întâmpină următorul mesaj de eroare:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let greeting_file = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
= help: the trait `FromResidual<Result<Infallible, std::io::Error>>` is not implemented for `()`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` due to previous error
Această eroare semnalează faptul că putem utiliza operatorul ? exclusiv în cadrul funcțiilor care returnează Result, Option, sau alte tipuri ce implementează FromResidual.
Pentru a corecta eroarea, ai două opțiuni. Prima este să modifici tipul de retur al funcției tale astfel încât să corespundă cu tipul valorii peste care aplici operatorul ?, cu condiția să nu existe restricții care te împiedică. Alternativa este folosirea unei structuri match sau a metodelor disponibile pentru Result<T, E> pentru a gestiona rezultatul Result<T, E> în modul cel mai potrivit pentru contextul tău.
Mesajul de eroare a subliniat, de asemenea, că operatorul ? poate fi aplicat pe valori de tip Option<T>. Asemenea utilizării ? pe Result, acesta poate fi folosit pe Option numai într-o funcție care returnează un Option. Atunci când ? este utilizat pe un Option<T>, comportamentul său este asemănător: dacă valoarea este None, atunci None se returnează imediat, întrerupând execuția funcției. Dacă valoarea este de tip Some, conținutul lui Some devine valoarea expresiei, iar execuția funcției continuă. Următoarea listare, 9-11, conține un exemplu de funcție care identifică ultimul caracter din prima linie a unui text furnizat:
fn last_char_of_first_line(text: &str) -> Option<char> { text.lines().next()?.chars().last() } fn main() { assert_eq!( last_char_of_first_line("Hello, world\nHow are you today?"), Some('d') ); assert_eq!(last_char_of_first_line(""), None); assert_eq!(last_char_of_first_line("\nhi"), None); }
Listarea 9-11: Utilizarea operatorului ? pentru o valoare Option<T>
Funcția aceasta returnează Option<char> deoarece există posibilitatea ca un caracter să fie prezent, dar de asemenea e posibil ca acesta să lipsească. Codul ia secțiunea de string text ca argument și îi aplică metoda lines, care oferă un iterator pentru liniile din string. Pentru a examina prima linie, folosim metoda next pe iterator, pentru a extrage prima valoare. Dacă text este un string gol, next va returna None; în acest caz, operatorul ? intervine pentru a opri execuția și a returna None din last_char_of_first_line. Dacă în schimb text nu este gol, next va returna un Some ce conține slice-ul primei linii din text.
Operatorul ? extrage acea secțiune, permițându-ne apoi să apelăm metoda chars pentru a obține un iterator al caracterelor sale. Ne interesează ultimul caracter din prima linie, deci apelăm last pentru a obține ultimul element al iteratorului, care este tot un Option. Este posibil ca prima linie să fie și ea un string gol – de exemplu, dacă text începe cu o linie goală, urmată de alte linii cu caractere, cum ar fi "\nhi". În cazul în care există un caracter final în prima linie, acesta va fi returnat într-o valoare Some. Folosind operatorul ?, putem exprima această verificare concis, permițând implementarea funcției într-o singură linie. Altfel, fără operatorul ? aplicabil pe Option, am fi nevoiți să reconstruim această logică prin mai multe apeluri de metode sau printr-o expresie match.
Trebuie să reții că operatorul ? poate fi utilizat pentru a propaga erorile într-o funcție care returnează un Result atunci când lucrezi cu un Result, iar în cazul în care lucrezi cu un Option, poți utiliza operatorul ? într-o funcție care returnează un Option. Însă nu este posibilă utilizarea mixtă a ambelor. Cu alte cuvinte, operatorul ? nu realizează automat conversia între Result și Option sau invers; în acele situații, trebuie să apelezi metode specifice, cum ar fi ok pentru Result sau ok_or pentru Option, pentru a efectua conversia în mod explicit.
Până în prezent, toate funcțiile main pe care le-am utilizat returnau (). Merită să subliniem că funcția main este unică, fiind punctul de start și de terminare al programelor executabile. Există restricții specifice legate de tipul de retur pe care îl poate avea, astfel încât programul să funcționeze corespunzător.
Noutatea bună e că main poate de asemenea să returneze Result<(), E>. În Listarea 9-12, prezentăm codul din Listarea 9-10, dar cu tipul de retur al funcției main modificat în Result<(), Box<dyn Error>> și adăugăm la final valoarea de retur Ok(()). Cu aceste modificări, codul este gata de compilat:
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?;
Ok(())
}Listarea 9-12: Modificând funcția main pentru a returna Result<(), E>, permitem folosirea operatorului ? pe valorile Result
Tipul Box<dyn Error> este un obiect trăsătură, concept pe care îl vom aborda mai detaliat în secțiunea „Utilizarea obiectelor trăsături care permit valori de diferite tipuri” din Capitolul 17. Până atunci, poți gândi la Box<dyn Error> ca o modalitate de a desemna „orice fel de eroare”. Utilizarea operatorului ? pe o valoare de tip Result în funcția main este posibilă atunci când tipul erorii este Box<dyn Error>, pentru că aceasta acceptă returnarea anticipată a oricărei valori de eroare Err. Deși corpul funcției main va genera, în mod normal, doar erori de tip std::io::Error, prin definirea tipului de eroare ca fiind Box<dyn Error>, semnătura acestuia rămâne validă chiar și atunci când adăugăm mai mult cod care generează alte tipuri de erori în main.
Când funcția main returnează un Result<(), E>, aplicația va termina execuția cu valoarea 0 dacă main returnează Ok(()) și va închide cu o valoare diferită de zero dacă main generează o eroare Err. Executabilele în limbajul C returnează valori întregi când se încheie execuția: programele care se termină corect returnează întregul 0, în timp ce programele care se închid cu o eroare returnează un întreg diferit de 0. Rust adoptă această convenție, returnând întregi de la executabile pentru compatibilitate.
Funcția main poate returna orice tip de date care implementează trăsătura std::process::Termination, care include funcția report rezultând într-un ExitCode. Consultă documentația bibliotecii standard Rust pentru mai multe detalii despre cum să implementezi trăsătura Termination pentru tipurile tale.
După ce am clarificat modul în care apelăm panic! sau returnăm Result, să discutăm cum alegem între aceste opțiuni în funcție de situație.
Să panic!-ăm sau nu?
Cum alegi când să apelezi la panic! și când e preferabil să returnezi un Result? Odată ce codul intră în panică, nu mai există cale de recuperare. Ai putea utiliza panic! pentru orice eroare, indiferent dacă există o șansă de reparare sau nu, dar astfel decizi tu că o situație e de nerezolvat, în locul celui care folosește codul tău. Prin furnizarea unei valori Result, permiți utilizatorului codului să aleagă soluția adecvată contextului său sau să determine că o valoare Err este una definitivă, apelând la panic! pentru a-și asuma ireversibilitatea. De aceea, este indicat să returnezi un Result când concepi o funcție care ar putea să nu funcționeze cum trebuie.
În situații precum documentația de exemplu, prototipuri și teste, e mai potrivit să optezi pentru codul ce induce panic! decât să returnezi un Result. Explorăm acum de ce este asta așa, și vom discuta cazurile în care compilatorul nu detectează imposibilitatea unui eșec, dar tu în calitate de programator înțelegi situația. Capitolul se va încheia cu un set de linii directoare fundamentale pentru a decide dacă să folosești panic! în codul bibliotecilor.
Exemple, cod de prototipare și teste
Când elaborezi un exemplu pentru a ilustra un concept, includerea codului complex pentru gestionarea erorilor poate aduce un minus de claritate. Se înțelege că, în exemple, utilizarea unei metode cum ar fi unwrap, care ar putea declanșa o panică, este doar un substituent temporar pentru modul în care ai gestiona normal erorile în aplicația ta, acest mod variind în funcție de codul existent.
Similar, metodele unwrap și expect sunt de mare ajutor în stadiul de prototipare, când încă nu ai hotărât cum să abordezi gestionarea erorilor. Ele lasă semne evidente în cod pentru momentul în care ești pregătit să îți consolidezi programul.
Dacă un apel al metodei nu reușește în timpul testării, ideal este ca întreg testul să fie afectat de acest eșec, chiar dacă metoda în cauză nu este funcționalitatea principală care se testează. Deoarece instrucțiunea panic! semnalează eșecul unui test, utilizarea unwrap sau expect este tocmai procedura adecvată în acest context.
Situațiile în care ai mai multe informații decât compilatorul
Este recomandabil să apelezi unwrap sau expect atunci când deții o anumită logică de asigurare că Result va fi Ok, chiar dacă logica respectivă nu este interpretată de compilator. În asemenea cazuri, încă trebuie să gestionăm valoarea Result: orice funcție invocată are potențialul de a eșua în principiu, chiar dacă eșecul este logic imposibil în situația particulară actuală. Dacă ești capabil prin verificarea manuală a codului să asiguri absența unei variante Err, apelarea lui unwrap este complet justificată și chiar încurajată. În plus, documentarea motivului pentru care este exclusă o variantă Err în mesajul metodei expect este o practică deosebit de beneficiară. Aici este un exemplu:
fn main() { use std::net::IpAddr; let home: IpAddr = "127.0.0.1" .parse() .expect("Hardcoded IP address should be valid"); }
Aici instanțiăm o structură IpAddr prin parsarea unui string predefinit. Cum 127.0.0.1 este clar o adresă IP validă, este logic să apelăm expect. Totuși, prezența unui string valid și predefinit nu influențează tipul de retur pentru metoda parse: rămânem cu o valoare de tip Result, iar compilatorul ne va solicita să gestionăm Result ca și când varianta Err ar fi o eventualitate, deoarece nu este echipat să recunoască automat că acest string este mereu o adresă IP validă. Dacă sursa string-ului cu adresa IP ar fi exterioară, adică provenind de la un utilizator și nu fiind stabilită inițial în cod, atunci cu certitudine am prefera o abordare mai atentă a valorii Result. Evidențierea faptului că adresa IP este predefinită în cod ne stimulează să actualizăm expect cu un cod de gestionare a erorilor mai avansat dacă e necesar să adaptăm sursa de unde obținem adresa IP în viitor.
Recomandări pentru tratarea erorilor
Este prudent să lași codul tău să declanșeze panică în momentele când s-ar putea să ajungă într-o stare critică. Prin stare critică înțelegem situația în care o anumită asumpție, garanție, acord sau invariant a fost compromis, exemplificat prin primirea de valori invalide, contradictorii sau inexistente - plus una sau mai multe dintre următoarele circumstanțe:
- Starea critică este una imprevizibilă, nu una care ar apărea frecvent, cum ar fi erorile de introducere a datelor de către un utilizator.
- Codul tău de după acest punct presupune că nu se află în acea stare critică și nu verifică problema la fiecare etapă.
- Nu este posibil să exprimi aceste informații suficient de clar utilizând tipurile curente. Vom explora această idee prin intermediul unui exemplu în secțiunea „Exprimarea stărilor și comportamentelor prin tipuri” din capitolul 17.
Dacă cineva folosește codul tău și introduce valori nesigure, este ideal să returnezi o eroare, dacă este posibil, astfel încât cel ce folosește biblioteca ta să determine cea mai bună acțiune de urmat. Totuși, în situații unde continuarea ar putea fi riscantă sau dăunătoare, decizia cea mai judicioasă ar fi să folosești panic!. Asta va notifica persoana care utilizează biblioteca ta despre defectul din codul său, permițând corectarea acestuia în cadrul dezvoltării. De asemenea, este adesea adecvat să folosești panic! atunci când execuți cod extern peste care nu ai control și acesta returnează o stare defectuoasă pe care nu ai cum să o corectezi.
Totuși, când un eșec este prevăzut, este preferabil să returnăm un Result în loc să apelăm panic!. Exemplele pot include situația în care un parser primește date corupte sau o solicitare HTTP care returnează un statut ce arată că s-a atins limita de rată. În aceste cazuri, returnarea unui Result indică faptul că eșecul este recunoscut ca o posibilitate așteptată, pe care codul apelant trebuie să o manajeze.
Când codul efectuează o operație care poate fi riscantă pentru un utilizator dacă este chemată cu valori invalide, trebuie să verifice dacă valorile sunt valide înainte și să panicheze dacă acestea nu sunt. Motivul principal este securitatea: lucrul cu date invalide poate crea vulnerabilități în codul tău. Acesta este motivul pentru care biblioteca standard va produce panic! dacă se încearcă accesul la memorie dincolo de limitele permise: încercarea de a accesa memoria care nu face parte din structura de date actuală este o problemă obișnuită de securitate. Funcțiile au adesea contracte: comportamentul lor este garantat doar dacă intrările îndeplinesc cerințele specificate. A panica atunci când un contract este încălcat este justificat deoarece o încălcare a contractului indică mereu o problemă din partea celui care apelează și nu este un tip de eroare care ar trebui gestionat explicit de către codul apelant. În esență, nu există o modalitate rezonabilă prin care codul apelant să poată remedia; programatorii apelanți trebuie să repare codul. Contractele unei funcții, în special atunci când nerespectarea lor conduce la panică, ar trebui să fie explicite în documentația API a respectivei funcții.
A include numeroase verificări de erori în toate funcțiile poate deveni copleșitor și plictisitor. Din fericire, sistemul de tipizare oferit de Rust și verificarea tipurilor efectuată de compilatorul lui Rust îți permit să automatizezi multe din aceste controale. Atunci când funcția ta specifică un anumit tip pentru un parametru, îți poți duce execuția codului mai departe având certitudinea că ai primit o valoare validă, grație compilatorului. De exemplu, dacă preferi un tip concret în locul tipului Option, programul se așteaptă să opereze cu ceva și nu cu nimic. Acest lucru înseamnă că nu trebuie să gestionezi separat cazurile Some și None, ci doar situația în care ai deja o valoare garantată. Astfel, încercările de a folosi funcția cu valori nule sunt oprite în faza de compilare, eliminând necesitatea efectuării acestei verificări în timpul execuției. Un alt exemplu, optarea pentru tipuri de numere întregi fără semn, precum u32, îți asigură că parametrul nu va putea fi niciodată negativ.
Crearea de tipuri particularizate pentru validare
Să explorăm cum putem utiliza sistemul de tipuri din Rust pentru a ne asigura că avem valori valide, prin crearea de tipuri personalizate pentru validarea acestora. Revenind la jocul cu ghicirea numărului din Capitolul 2, unde codul cerea utilizatorului să ghicească un număr între 1 și 100, observăm că nu am validat dacă ghicirea utilizatorului se încadra în acest interval înainte de a o compara cu numărul secret; ne-am limitat doar la verificarea pozitivității ghicirii. Cu toate că în acest caz consecințele nerespectării intervalului nu erau majore – răspunsurile „Prea mare” sau „Prea mic” fiind adecvate –, tot ar fi benefică îndrumarea utilizatorilor spre ghiciri corecte și o diferențiere clară a comportamentului programului atunci când utilizatorul introduce un număr în afara intervalului sau, de exemplu, litere.
Un mod de a implementa acest lucru ar fi prin parsarea ghicirii ca un i32, care permite numere negative, și adăugarea unei verificări care să confirme că numărul se află în intervalul dorit:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("The secret number will be between 1 and 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Instrucțiunea if verifică dacă valoarea introdusă este în afara intervalului, informează utilizatorul în privința erorii și execută continue pentru a iniția o nouă iterație a buclei și a solicita o altă ghicire. După această verificare, comparațiile dintre guess și numărul secret pot fi efectuate cu certitudinea că guess cade între 1 și 100.
Cu toate acestea, soluția nu este optimă într-un context în care este critic ca programul să lucreze exclusiv cu valori între 1 și 100 – mai ales dacă mai multe funcții impun această limită –, căci inserarea aceluiași tip de verificare în fiecare dintre ele ar fi monotonă și ar putea influența performanța.
Ca alternativă, am putea defini un tip nou și să centralizăm validările într-o funcție dedicată creării de instanțe ale acestui tip, evitând astfel repetarea validărilor. Astfel, este sigur de utilizat noul tip în semnăturile funcțiilor, care ar putea opera cu încredere folosind valorile primite. În Listarea 9-13, prezentăm o metodă de a defini un tip Guess, care va crea o instanță validă a acestuia numai dacă funcția new este invocată cu o valoare între 1 și 100.
#![allow(unused)] fn main() { pub struct Guess { value: i32, } impl Guess { pub fn new(value: i32) -> Guess { if value < 1 || value > 100 { panic!("Guess value must be between 1 and 100, got {}.", value); } Guess { value } } pub fn value(&self) -> i32 { self.value } } }
Listarea 9-13: Tipul Guess ce acceptă numai valorile între 1 și 100
Inițial, definim o structură cu denumirea Guess, având un câmp numit value care conține un i32. Acesta este locul unde va fi stocat numărul.
Ulterior, implementăm o funcție asociată intitulată new pentru structura Guess, pentru a crea instanțe ale tipului Guess. Funcția new este configurată să primească un parametru numit value, de tip i32, și să returneze un Guess. În corpul funcției new, verificăm valoarea lui value pentru a ne asigura că se încadrează între 1 și 100. În cazul în care value nu îndeplinește acest criteriu, utilizăm macro-ul panic!, care va semnala programatorului care a apelat codul despre prezența unui defect ce necesită rezolvare, deoarece constituirea unui Guess cu o valoare value exterioară acelui interval ar încălca prerogativele funcției Guess::new. Situațiile în care Guess::new ar putea cauza o panică trebuie detaliate în documentația API destinată publicului; vom aborda standardele de documentare ce marchează posibilitatea unei panici în documentația API pe care o veți alcătui în Capitolul 14. Dacă value satisface cerința, compilăm o nouă structură Guess, stabilind valoarea câmpului value la parametrul primit și întorcând Guess.
Mai departe, implementăm o metodă denumită value ce împrumută self și returnează un i32, fără a solicita alți parametri. Această metodă este adesea identificată ca getter, deoarece scopul ei este de a extrage informații din câmpurile proprii și de a le furniza extern. Această metodă publică este esențială dat fiind că atributul value al structurii Guess este privat. Este crucial pentru atributul value să fie privat, astfel încât codul care utilizează structura Guess să nu fie în măsură să seteze value în mod direct: codul din afara modulului trebuie să recurgă la funcția Guess::new pentru a asambla o instanță de Guess, garantându-se în acest mod că orice Guess posedă un value validat de condițiile prezentate în funcția Guess::new.
O funcție care manipulează numai numere între 1 și 100 poate alege să indice în semnătura sa că primește sau returnează o structură Guess în loc de un i32, ceea ce ar permite să ocolească efectuarea unor verificări în plus în conținutul său.
Sumar
Capacitățile de gestionare a erorilor din Rust sunt concepute pentru a sprijini scrierea unui cod cât mai solid. Macro-ul panic! indică o stare irecuperabilă a programului și oferă posibilitatea de a întrerupe execuția, evitând continuarea cu valori greșite sau invalide. Enum-ul Result exploatează sistemul de tipuri al Rust pentru a scoate în evidență potențialul eșec al operațiunilor, din care codul tău ar putea să revină. Result poate fi folosit pentru a informa codul client că trebuie gestionată atât reușita, cât și eșecul. Folosirea judicioasă a panic! și a Result va crește fiabilitatea codului tău în fața problemelor inevitabile.
Având în vedere utilizările benefice ale genericilor în enum-urile Option și Result de către biblioteca standard, vom discuta în continuare despre funcționarea genericilor și modul în care pot fi implementați în codul tău.
Tipuri generice, trăsături și durate de viață
Fiecare limbaj de programare dispune de unelte specifice pentru a gestiona eficient duplicarea conceptelor. În Rust, un asemenea instrument sunt genericele: substituenți abstracți pentru tipuri concrete sau alte caracteristici. Ne permite să descriem comportamentul genericelor sau relațiile acestora cu alte generice fără a cunoaște ce le va înlocui atunci când codul este compilat și executat.
Funcțiile pot accepta parametri de orice tip generic, în locul unui tip concret precum i32 sau String, similar modului în care o funcție acceptă parametri cu valori necunoscute pentru a rula același cod peste multiple valori concrete. De fapt, am utilizat genericele în Capitolul 6 cu Option<T>, în Capitolul 8 cu Vec<T> și HashMap<K, V>, și în Capitolul 9 cu Result<T, E>. În acest capitol, vei explora cum să-ți definești propriile tipuri, funcții și metode utilizând generice!
Vom începe cu o recapitulare a metodei de extragere a unei funcții în scopul reducerii duplicării de cod. Vom folosi aceeași tehnică pentru a deriva o funcție generică din două funcții care diferă numai prin tipurile parametrilor lor. Îți vom arăta cum se aplică tipurile generice în definițiile structurilor și enumerărilor.
Mai departe, vei învăța să folosești trăsături (trait) pentru a defini comportamente într-un mod generic. Combinând trăsăturile cu tipuri generice, putem limita un tip generic să accepte doar acele tipuri care prezintă un anumit comportament, spre deosebire de orice tip.
La final, vom discuta despre duratele de viață: o categorie specială de generice ce furnizează compilatorului date privind modul în care referințele interacționează unele cu altele. Duratele de viață ne permit să înzestrăm compilatorul cu informații suficiente despre valorile împrumutate, permițându-i acestuia să asigure că referințele sunt valide într-o paletă mai largă de scenarii decât ar fi posibil fără sprijinul nostru.
Reducerea duplicării prin extragerea unei funcții
Genericele ne permit să substituim tipuri specifice cu un placeholder, ce reprezintă mai multe tipuri, și astfel să eliminăm duplicarea în cod. Înainte de a ne familiariza cu sintaxa de generice, să vedem prima dată cum putem înlătura duplicările într-un mod care nu implică tipuri generice. Acest lucru se realizează prin extragerea unei funcții care înlocuiește valorile specifice cu un placeholder pentru multiple valori. Apoi, vom aplica aceeași abordare pentru a defini o funcție generică! Înțelegând cum să recunoaștem codul duplicat care se poate transforma într-o funcție, vei începe să identifici și codul duplicat care poate beneficia de generice.
Pornim cu un program simplu prezentat în Listarea 10-1, care determină cel mai mare număr dintr-o listă.
Numele fișierului: src/main.rs
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {}", largest); assert_eq!(*largest, 100); }
Listarea 10-1: Identificarea celui mai mare număr dintr-o listă de numere
Noi salvăm o listă de numere întregi în variabila number_list și atribuim o referință la primul număr din listă variabilei largest. Procedăm apoi la iterarea prin fiecare număr din listă, iar dacă numărul curent este mai mare decât cel referențiat de largest, actualizăm referința din această variabilă. Pe de altă parte, dacă numărul curent este mai mic sau egal cu cel mai mare număr întâlnit până în acel moment, variabila largest rămâne neschimbată, iar codul continuă cu următorul număr din listă. După ce toate numerele din listă sunt evaluate, largest va indica cel mai mare număr, care în acest exemplu este 100.
Ne-am propus acum să găsim cel mai mare număr din două seturi diferite de numere. Putem alege să duplicăm codul din Listarea 10-1 sau să aplicăm aceeași logică în două locuri diferite din program, așa cum este prezentat în Listarea 10-2.
Numele fișierului: src/main.rs
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {}", largest); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {}", largest); }
Listarea 10-2: Cod pentru identificarea celui mai mare număr din două liste de numere
Chiar dacă acest cod este funcțional, duplicarea sa este monotonă și predispusă la erori. În plus, trebuie să ne amintim să actualizăm codul în diverse locuri atunci când dorim să facem modificări.
Pentru a elimina această duplicare, vom introduce o abstracție prin definirea unei funcții care operează pe orice array de numere întregi dat ca parametru. Această metodă îmbunătățește claritatea codului și ne permite să formulăm conceptul de identificare a celui mai mare număr dintr-un array într-un mod abstract.
În Listarea 10-3, extragem codul care identifică cel mai mare număr într-o funcție numită largest. Apoi invocăm funcția pentru a determina cel mai mare număr din cele două liste prezentate în Listarea 10-2. Totodată, putem utiliza funcția pentru orice alte array-uri de valori i32 pe care le-am putea avea în viitor.
Numele fișierului: src/main.rs
fn largest(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest(&number_list); println!("The largest number is {}", result); assert_eq!(*result, 100); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let result = largest(&number_list); println!("The largest number is {}", result); assert_eq!(*result, 6000); }
Listarea 10-3: Cod abstractizat pentru găsirea celui mai mare număr din două liste
Funcția largest are un parametru denumit list, care poate reprezenta orice secțiune concretă de valori i32 introdusă în funcție. În consecință, când apelăm funcția, codul se execută folosind valorile specifice furnizate.
Rezumând, aceștia sunt pașii pe care i-am urmat pentru a transforma codul din Listarea 10-2 în Listarea 10-3:
- Identifică codul duplicat.
- Extrage codul duplicat în corpul funcției și specifică intrările și valorile de retur ale acestui cod în semnătura funcției.
- Actualizează cele două instanțe de cod duplicat pentru a apela funcția în locul acestuia.
În continuare, vom folosi acești pași împreună cu genericele pentru a reduce și mai mult duplicarea codului. La fel cum corpul unei funcții poate opera pe o list abstractă și nu pe valori concrete, genericele ne permit să lucrăm cu tipuri abstracte.
De pildă, să ne imaginăm că avem două funcții: una care determină elementul cel mai mare dintr-o secțiune de valori i32 și una care găsește cel mai mare element într-o secțiune de valori char. Cum am putea elimina această duplicare? Să explorăm!
Tipuri de date generice
Genericile sunt instrumente pe care le utilizăm pentru a construi definiții de elemente, cum ar fi semnăturile de funcții sau structurile, ce pot fi apoi folosite cu o multitudine de tipuri de date concrete. Înainte de toate, să ne uităm cum putem defini funcții, structuri, enumerări și metode folosind genericile. Ulterior, vom aborda impactul pe care îl au genericile asupra performanței codului.
Definirea funcțiilor cu generici
Atunci când definim o funcție ce folosește generici, introducem genericii în semnătura funcției acolo unde, în mod obișnuit, am specifica tipurile de date pentru parametri și valoarea returnată. Acest demers face codul nostru mai maleabil și oferă mai multă funcționalitate celor ce apelează funcția, prevenind duplicarea de cod.
Continuând cu funcția noastră largest, Listarea 10-4 prezintă două funcții care identifică valoarea cea mai mare dintr-o secțiune. Apoi, vom unifica acestea într-o singură funcție care încorporează generici.
Numele fișierului: src/main.rs
fn largest_i32(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn largest_char(list: &[char]) -> &char { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest_i32(&number_list); println!("The largest number is {}", result); assert_eq!(*result, 100); let char_list = vec!['y', 'm', 'a', 'q']; let result = largest_char(&char_list); println!("The largest char is {}", result); assert_eq!(*result, 'y'); }
Listarea 10-4: Două funcții care se diferențiază prin numele și tipurile specificate în semnăturile lor
Funcția largest_i32, pe care am extras-o în Listarea 10-3, localizează cel mai mare i32 dintr-o secțiune. Funcția largest_char identifică cel mai mare char dintr-o secțiune. Cum ambele funcții au corpuri identice, vom elimina duplicarea introducând un parametru de tip generic într-o funcție singulară.
Pentru a parametriza tipurile în noua funcție singulară, trebuie să numim parametrul de tip, la fel cum nominalizăm parametrii valorici ai unei funcții. Orice identificator poate fi folosit ca nume de parametru de tip. Totuși, ne vom folosi de T conform convenției uzuale în Rust, unde numele parametrilor de tip sunt scurte, frecvent doar o literă, și urmează stilul de denumire UpperCamelCase. T, fiind prescurtarea pentru „type”, este alegerea preferată de majoritatea dezvoltatorilor de Rust.
Când utilizăm un parametru în corpul funcției, trebuie să îl declarăm în semnătură pentru ca compilatorul să înțeleagă la ce ne referim. În mod similar, atunci când utilizăm un nume pentru un parametru de tip în semnătura unei funcții, trebuie să declarăm acest nume de tip înainte de a-l folosi. Pentru a defini funcția generică largest, vom insera numele de tip în interiorul parantezelor unghiulare, <>, așezate între numele funcției și lista de parametri, în felul următor:
fn largest<T>(list: &[T]) -> &T {Descifrăm această definiție în felul următor: funcția largest funcționează generic pentru un anumit tip T. Funcția dispune de un parametru denumit list, care este o secțiune de elemente de tip T. Funcția largest va returna o referință către o valoare de același tip T.
Listarea 10-5 ne oferă definiția combinată a funcției largest, care incorporează tipul de date generic în semnătura sa. Listarea ilustrează și cum putem invoca funcția folosind fie o secțiune de valori i32, fie una de char. Observăm că acest cod nu va compila încă, dar vom adresa această problemă mai târziu în capitul curent.
Numele fișierului: src/main.rs
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}Listarea 10-5: Funcția largest utilizând parametrii de tip generic; în stadiul actual codul nu se compilează
Dacă încercăm să compilăm acest cod acum, ne vom confrunta cu următoarea eroare:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` due to previous error
Mesajul de ajutor ne îndreaptă atenția spre std::cmp::PartialOrd, care este o trăsătură, subiect ce va fi abordat în secțiunea următoare. Pentru moment, este important să înțelegem că această eroare ne transmite că implementarea funcției largest nu va opera corect pentru toate tipurile posibile ale lui T. Pentru că dorim să comparăm valorile de tip T în corpul funcției, ne limităm la acele tipuri ale căror valori pot fi comparate în ordine. Biblioteca standard facilitează acest lucru prin intermediul trăsăturii std::cmp::PartialOrd, pe care o puteți implementa pentru diverse tipuri (pentru mai multe detalii referitoare la această trăsătură, consultați Anexa C). Urmând sugestia din mesajul de ajutor, vom restricționa tipurile valide pentru T la cele care implementează PartialOrd, și astfel exemplul nostru va compila fără probleme, dat fiind că biblioteca standard furnizează implementări pentru PartialOrd atât pentru tipul i32, cât și pentru char.
În definiția structurilor
Noi putem defini structuri care să încorporeze unul sau mai multe câmpuri care folosesc parametri de tip generic, prin intermediul sintaxei cu paranteze unghiulare <>. Listarea 10-6 înfățișează definiția structurii Point<T>, care reține valori ale coordonatelor x și y de orice tip.
Numele fișierului: src/main.rs
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }
Listarea 10-6: O structură Point<T> ce conține valori x și y de tip T
Utilizarea genericilor în definirea structurilor urmează o sintaxă similară cu aceea din definițiile funcțiilor. Inițial, numele parametrului de tip generic e declarat între paranteze unghiulare după denumirea structurii. În continuare, folosim tipul generic în cadrul definiției structurii în locul unde, de obicei, sunt specificate tipuri de date fixe.
Este esențial să avem în vedere că, prin utilizarea unui unic tip generic în definirea Point<T>, noi comunicăm că structura Point<T> este generică peste un anumit tip T, și că câmpurile x și y sunt în ambele situații de același tip, oricare ar fi acesta. Astfel, dacă creăm o instanță Point<T> cu valori ale tipurilor diferite, așa cum arată Listarea 10-7, codul nu va fi compilabil.
Numele fișierului: src/main.rs
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}Listarea 10-7: Câmpurile x și y trebuie să fie de același tip din cauză că ambele folosesc tipul de date generic T.
În exemplul de față, o dată ce atribuim x-ului valoarea întreagă 5, îi semnalăm compilatorului că pentru această instanță de Point<T>, tipul generic T va fi un întreg. Apoi, dacă pentru y specificăm valoarea 4.0, care ar trebui să fie de același tip ca x, vom întâmpina o eroare de incompatibilitate a tipurilor, după cum urmează:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` due to previous error
Dacă dorim să definim o structură Point în care x și y să fie generice și să accepte tipuri diferite, ne putem folosi de parametri de tip generic multipli. Ca exemplu, în Listarea 10-8, am modificat definiția lui Point pentru a deveni generică peste tipurile de date T și U, unde x este de tip T și y de tip U.
Numele fișierului: src/main.rs
struct Point<T, U> { x: T, y: U, } fn main() { let both_integer = Point { x: 5, y: 10 }; let both_float = Point { x: 1.0, y: 4.0 }; let integer_and_float = Point { x: 5, y: 4.0 }; }
Listarea 10-8: Structura Point<T, U>, generică peste două tipuri, permițând ca x și y să fie de tipuri diferite
Acum fiecare dintre exemplele prezentate pentru Point sunt posibile! Este permisă utilizarea unei varietăți de parametri de tip generic în definiția unei structuri, însă un exces în acest sens poate mări complexitatea codului și îl face greu de urmărit. Dacă-ți dai seama că ai nevoie de multe tipuri generice în codul tău, probabil ar fi benefică o restructurare pentru simplificarea codului.
În definiția enumerărilor
Ca și în cazul structurilor, putem defini enumerări ce includ tipuri de date generice în variantele lor. Să revizuim enumerarea Option<T>, pusă la dispoziție de biblioteca standard, pe care am utilizat-o anterior în Capitolul 6:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
Această definiție ar trebui acum să fie mai inteligibilă pentru tine. După cum poți vedea, enumerarea Option<T> este generică peste tipul T și are două variante: Some, care include o valoare de tipul T, și None, care nu include nicio valoare. Utilizând enumerarea Option<T>, putem exprima conceptul abstract al unei valori facultative și, fiindcă Option<T> este generic, această noțiune poate fi aplicată indiferent de tipul valorii facultative.
De asemenea, enumerările pot folosi mai multe tipuri generice. Definiția enumerării Result, pe care am folosit-o în Capitolul 9, este un astfel de exemplu:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
Enumerarea Result este generică peste două tipuri, T și E, și încorporează două variante: Ok, ce include o valoare de tip T, și Err, ce include o valoare de tip E. Această definiție facilitează folosirea enumerării Result în orice context avem o operațiune ce ar putea avea succes (întorcând o valoare de un anumit tip T) sau ar putea eșua (întorcând o eroare de un anumit tip E). Aceasta este metoda pe care am aplicat-o atunci când am deschis un fișier în Listarea 9-3, unde T a fost înlocuit cu tipul std::fs::File pentru un caz de succes și E a fost înlocuit cu std::io::Error pentru cazurile de eroare în deschiderea fișierului.
Atunci când întâmpini în codul tău situații în care multiple structuri sau enumerări se diferențiază doar prin tipul valorilor pe care le conțin, poți evita repetiția prin aplicarea tipurilor generice.
În definiția metodelor
Noi putem implementa metode pe structuri și enumerări, așa cum am făcut în Capitolul 5, utilizând și tipuri generice în definițiile lor. În Listarea 10-9 este prezentată structura Point<T>, definită anterior în Listarea 10-6, cu o metodă numită x implementată pe ea.
Numele fișierului: src/main.rs
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
Listarea 10-9: Implementarea unei metode denumite x pe structura Point<T>, care returnează o referință către câmpul x de tip T
Aici, am definit o metodă x pe Point<T> care oferă o referință către datele din câmpul x.
Este necesar să declarăm T imediat după impl pentru a putea folosi T în specificarea că implementăm metode pe structura Point<T>. Declarând T ca tip generic după impl, Rust înțelege că tipul din parantezele unghiulare din Point este generic și nu concret. Desigur, am fi putut alege un nume diferit pentru acest parametru generic, comparativ cu cel din definiția structurii, dar convenția sugerează utilizarea aceluiași nume. Metodele definite într-un bloc impl care declară tipul generic vor fi aplicabile pe orice instanță de Point<T>, indiferent de substituția tipului generic cu un tip concret.
Putem impune, de asemenea, anumite restricții asupra tipurilor generice când definim metode pe un anumit tip. De exemplu, putem implementa metode exclusiv pe instanțe de Point<f32> și nu pe Point<T> cu orice tip generic. În Listarea 10-10, utilizăm tipul concret f32, fără a declarăm tipuri după impl.
Numele fișierului: src/main.rs
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } impl Point<f32> { fn distance_from_origin(&self) -> f32 { (self.x.powi(2) + self.y.powi(2)).sqrt() } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
Listarea 10-10: Un bloc impl specific pentru o structură cu un tip concret dat pentru parametrul generic T
Prin acest cod, Point<f32> va avea o metodă distance_from_origin, în timp ce alte instanțe de Point<T>, unde T nu este f32, nu vor avea definită această metodă. Metoda calculează cât de departe este un punct de originea de coordonate (0.0, 0.0), folosind operațiuni matematice specifice pentru tipurile cu virgulă mobilă.
Parametrii generici din definiția unei structuri nu trebuie să corespundă întotdeauna cu cei din semnăturile metodelor respectivei structuri. Listarea 10-11 folosește tipurile generice X1 și Y1 pentru structura Point și X2, Y2 pentru semnătura metodei mixup, pentru a ilustra mai clar concepția. Metoda creează o nouă instanță Point cu valoarea x din instanța self de tip X1 și valoarea y din instanța de Point primită ca argument, de tip Y2.
Numele fișierului: src/main.rs
struct Point<X1, Y1> { x: X1, y: Y1, } impl<X1, Y1> Point<X1, Y1> { fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Hello", y: 'c' }; let p3 = p1.mixup(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
Listarea 10-11: O metodă care utilizează tipuri generice diferite de cele ale definiției structurii sale
În funcția main, am definit un Point cu un i32 pentru x (valoare 5) și un f64 pentru y (valoare 10.4). Variabila p2 este un Point care conține o secțiune de string pentru x (cu valoarea "Hello") și un char pentru y (cu valoarea c). Apelând metoda mixup pe p1 cu argumentul p2 generăm variabila p3, ce va prelua valoarea x de tip i32 de la p1 și valoarea y de tip char de la p2. Apelul macro-ului println! va afișa: p3.x = 5, p3.y = c.
Exemplul servește la demonstrarea unei situații în care unii parametri generici sunt definiți în blocul impl și alții sunt incluși în definiția metodei propriu-zise. În acest context, parametrii generici X1 și Y1 sunt declarați alături de impl deoarece sunt asociați cu definiția structurii, în vreme ce X2 și Y2 sunt introduși odată cu definiția funcției mixup, având relevanță doar în contextul acelei metode.
Performanța codului folosind generici
Ai putea să te întrebi dacă folosirea parametrilor de tip generic implică un cost la rulare. Vestea excelentă este că utilizarea genericilor nu va încetini executarea programului tău comparativ cu folosirea tipurilor concrete.
Rust atinge acest performanță prin monomorfizarea codului cu generici în timpul compilării. Monomorfizarea este procesul prin care codul generic este transformat în cod specific, prin completarea cu tipurile concrete utilizate în momentul compilării. În acest proces, compilatorul face contrariul demersurilor noastre din crearea funcției generice prezentată în Listarea 10-5: acesta analizează toate locurile unde este invocat codul generic și generează cod pentru tipurile concrete utilizate.
Explorăm acest mecanism prin intermediul enum-ului generic Option<T> din biblioteca standardă a limbajului Rust:
#![allow(unused)] fn main() { let integer = Some(5); let float = Some(5.0); }
La compilarea acestui cod, Rust efectuează monomorfizarea. Compilatorul identifică valorile folosite în instanțele Option<T> și recunoaște două variante ale lui Option<T>: una pentru i32 și alta pentru f64. În consecință, extinde definiția generică a Option<T> în două versiuni specializate pentru i32 și f64, substituind astfel definiția generică.
Versiunea monomorfizată a codului ar putea arăta astfel (compilatorul folosește denumiri diferite de cele alese de noi aici pentru exemplificare):
Numele fișierului: src/main.rs
enum Option_i32 { Some(i32), None, } enum Option_f64 { Some(f64), None, } fn main() { let integer = Option_i32::Some(5); let float = Option_f64::Some(5.0); }
Genericul Option<T> este substituit cu definițiile specifice generate de compilator. Deoarece Rust transformă codul generic în cod care precizează tipul pentru fiecare instanță, nu întâmpinăm niciun cost suplimentar la rulare atunci când folosim genericii. Astfel, când codul este executat, performanța este echivalentă cu cea pe care am obține-o dacă am duplica manual fiecare definiție. Procesul de monomorfizare face ca genericii din Rust să fie extrem de performanți la executare.
Traits: definirea comportamentului partajat
O trăsătură (trait) definește funcționalitățile pe care un tip le posedă și care pot fi partajate cu alte tipuri. Noi utilizăm trăsăturile pentru a stabili în mod abstract comportamentul partajat. Totodată, prin limitele trăsăturii specificăm că un tip generic poate fi orice tip care manifestă anumite comportamente.
Notă: Trăsăturile sunt similare cu o funcționalitate frecvent întâlnită în alte limbaje de programare, des numită interfețe, deși există diferențe notabile.
Definirea unei trăsături
Comportamentul unui tip este caracterizat de metodele care pot fi invocate pe acel tip. Diverse tipuri au un comportament comun dacă este posibil să apelăm aceleași metode pe fiecare dintre ele. Definițiile trăsăturilor reprezintă o metodă de a grupa semnături de metode pentru a contura un set de comportamente necesare pentru îndeplinirea unui obiectiv anume.
Să presupunem, de exemplu, că dispunem de structuri multiple care stochează diferite cantități și tipuri de text: o structură NewsArticle care conține o știre legată de o locație specifică și un Tweet care poate avea până la 280 de caractere, împreună cu metadate care precizează dacă acesta este un tweet nou, un retweet sau un răspuns la un alt tweet.
Ne propunem să construim o crate de bibliotecă de agregare ale articolelor media numită aggregator, capabilă să prezinte sumare ale datelor care pot fi conținute de instanțe ale NewsArticle sau Tweet. Pentru acest lucru, avem nevoie de un rezumat din partea fiecărui tip, pe care îl solicităm prin apelarea metodei summarize pe o instanță respectivă. Listarea 10-12 ilustrează definiția unei trăsături publice Summary ce exprimă acest comportament.
Numele fișierului: src/lib.rs
pub trait Summary {
fn summarize(&self) -> String;
}Listarea 10-12: O trăsătură Summary ce constă din comportamentul oferit de metoda summarize
În acest caz, introducem o trăsătură utilizând cuvântul cheie trait urmat de numele trăsăturii, care este Summary. Am declarat trăsătura ca fiind publică (pub), astfel încât alte crate-uri care depind de acesta să aibă posibilitatea de a o folosi, așa cum vom observa în unele exemple ulterioare. În spațiul dintre acolade, sunt prezentate semnăturile metodelor care definesc comportamentele asumate de tipurile care implementează această trăsătură; în cazul de față fiind fn summarize(&self) -> String.
În loc să furnizăm o implementare a metodei între acolade, punem un punct și virgulă după semnătură. Fiecărui tip care realizează această trăsătură îi revine sarcina de a implementa propriul comportament pentru corpul metodei. Compilatorul va asigura că orice tip cu trăsătura Summary va avea definită metoda summarize cu anume această semnătură exactă.
O trăsătură poate include în corpul său mai multe metode: semnăturile acestora sunt enumerate independent, pe rânduri separate, iar fiecare rând se încheie cu un punct și virgulă.
Implementarea unei trăsături pentru un tip
Noi am definit semnăturile dorite ale metodelor trăsăturii Summary și acum e timpul să le implementăm pentru tipurile din agregatorul nostru de media. Listarea 10-13 ilustrează implementarea trăsăturii Summary pentru structura NewsArticle, utilizând titlul, autorul și locația pentru a crea valoarea de retur a metodei summarize. În cazul structurii Tweet, metoda summarize este definită ca numele de utilizator urmat de întregul text al tweet-ului, având în vedere că conținutul tweet-ului este limitat la 280 de caractere.
Numele fișierului: src/lib.rs
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Listarea 10-13: Implementarea trăsăturii Summary pentru tipurile NewsArticle și Tweet
Implementarea unei trăsături pentru un tip este similară cu implementarea metodelor obișnuite. Diferența constă în faptul că, după impl, specificăm numele trăsăturii pe care dorim să o realizăm, folosim cuvântul cheie for, și apoi numele tipului pentru care implementăm trăsătura. În blocul impl, includem semnăturile metodelor definite de trăsătura respectivă. În loc să finalizăm fiecare semnătură cu un punct și virgulă, adăugăm acolade și detaliem corpul fiecărei metode pentru a defini comportamentul specific pe care îl dorim de la metodele trăsăturii pentru tipul respectiv.
Odată ce biblioteca noastră a implementat trăsătura Summary pentru NewsArticle și Tweet, utilizatori crate-ului pot folosi metodele trăsăturii pe instanțe de NewsArticle și Tweet, similar cu modul în care sunt apelate metodele obișnuite. Singura diferență este că utilizatorii trebuie să includă atât trăsătura cât și tipurile în domeniul de vizibilitate. Aici este un exemplu de cum ar putea fi utilizată biblioteca noastră aggregator în cadrul unui crate binar:
use aggregator::{Summary, Tweet};
fn main() {
let tweet = Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
};
println!("1 new tweet: {}", tweet.summarize());
}Acest exemplu de cod va afișa 1 new tweet: horse_ebooks: of course, as you probably already know, people.
Alte crate-uri care utilizează crate-ul aggregator pot de asemenea să își aducă trăsătura Summary în domeniul de vizibilitate pentru a o implementa pe tipurile proprii. O restricție de reținut este că putem implementa o trăsătură pe un tip doar în cazul în care cel puțin unul dintre elemente - trăsătura sau tipul - este definit local în propriul nostru crate. De exemplu, putem implementa trăsături standard ale bibliotecii, cum ar fi Display, pentru un tip nativ crate-ului nostru ca Tweet, ca parte a funcționalității aggregator. De asemenea, putem implementa Summary pentru Vec<T> în cadrul aggregator, din moment ce trăsătura Summary este locală crate-ului nostru.
Cu toate acestea, nu avem posibilitatea să implementăm trăsături externe pentru tipuri externe. Spre exemplu, nu putem să realizăm implementarea trăsăturii Display pentru Vec<T> în cadrul crate-ului aggregator, pentru că atât Display cât și Vec<T> sunt parte din biblioteca standard și nu sunt locale lui aggregator. Această limitare este o parte din principiul de coerență, mai precis din regula orfanilor. Această regulă asigură că codul altor persoane nu poate interfera cu al tău și în același timp protejează codul tău de a fi afectat de alții. Fără această regulă, ar exista posibilitatea ca două crate-uri diferite să implementeze aceeași trăsătură pentru același tip, ceea ce ar crea confuzie pentru Rust cu privire la care implementare ar trebui utilizată.
Implementări implicite
Câteodată e util să avem un comportament implicit pentru unele sau pentru toate metodele unei trăsături în loc să necesităm implementări pentru toate metodele pe fiecare tip. Prin urmare, atunci când implementăm trăsătura pe un anumit tip, putem menține sau suprascrie comportamentul implicit al fiecărei metode.
În Listarea 10-14, am specificat un string implicit pentru metoda summarize a trăsăturii Summary în loc doar să definim semnătura metodei, cum am făcut în Listarea 10-12.
Numele fișierului: src/lib.rs
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Listarea 10-14: Definirea trăsăturii Summary cu o implementare implicită a metodei summarize
Pentru a folosi o implementare implicită în rezumarea instanțelor de NewsArticle, specificăm un bloc impl gol cu impl Summary for NewsArticle {}.
Deși nu mai definim metoda summarize în mod direct pe NewsArticle, am furnizat o implementare implicită și am specificat că NewsArticle implementează trăsătura Summary. Drept rezultat, putem totuși apela metoda summarize pe o instanță de NewsArticle, astfel:
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
}Acest cod afișează New article available! (Read more...).
Crearea unei implementări implicite nu ne obligă să modificăm nimic în ceea ce privește implementarea Summary pentru Tweet, conform Listării 10-13. Acest lucru este datorat faptului că sintaxa pentru a suprascrie o implementare implicită este identică cu sintaxa pentru implementarea unei metode de trăsătură care nu are nicio implementare implicită.
Implementările implicite pot apela alte metode din aceeași trăsătură, chiar dacă aceste alte metode nu dispun de implementări implicite. Astfel, o trăsătură poate oferi multe funcționalități utile și poate cere implementatorilor să definească doar o mică parte din acelea. De exemplu, am putea defini trăsătura Summary să includă o metodă summarize_author ce necesită implementare, și apoi să definim o metodă summarize care are o implementare implicită ce invocă summarize_author:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Când folosim această versiune de Summary, trebuie să definim summarize_author doar când implementăm trăsătura pentru un tip:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}După ce definim summarize_author, putem invoca summarize pe instanțele structurii Tweet, iar implementarea implicită a summarize va utiliza definiția de summarize_author pe care am furnizat-o. Întrucât am implementat summarize_author, trăsătura Summary ne oferă funcționalitatea metodei summarize fără să fie nevoie să scriem cod suplimentar.
use aggregator::{self, Summary, Tweet};
fn main() {
let tweet = Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
};
println!("1 new tweet: {}", tweet.summarize());
}Acest cod afișează 1 new tweet: (Read more from @horse_ebooks...).
Notă: nu este posibil să apelăm implementarea implicită din cadrul unei implementări care o suprascrie pe aceeași metodă.
Utilizarea trăsăturilor drept parametri
Înarmat cu abilitatea de a defini și implementa trăsături, ești acum pregătit să descoperi cum să folosești trăsături pentru a concepe funcții care să accepte o varietate de tipuri diferite. Vom apela la trăsătura Summary, implementată pentru NewsArticle și Tweet în Listarea 10-13, pentru a defini funcția notify care invocă metoda summarize pe parametrul său item. Acest item trebuie să fie de un tip care implementează trăsătura Summary. Procedăm astfel folosind sintaxa impl Trait, în modul următor:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}În loc de un tip explicit pentru parametrul item, specificăm cuvântul cheie impl și numele trăsăturii. Acest parametru va accepta orice tip care implementează trăsătura indicată. În cadrul funcției notify, avem posibilitatea să apelăm orice metode asociate cu item ce derivă din trăsătura Summary, precum summarize. Funcția notify poate fi apelată utilizând orice exemplar de NewsArticle sau Tweet. Încercarea de a folosi funcția cu tipuri care nu implementează Summary, cum ar fi String sau i32, nu va fi compilată, deoarece aceste tipuri nu îndeplinesc cerința trăsăturii Summary.
Sintaxa delimitării de trăsături
Sintaxa impl Trait este practică în situații simple, dar de fapt reprezintă o formă abreviată pentru o formă mai extinsă, cunoscută ca delimitare de trăsături (trait bound); aceasta se prezintă astfel:
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}Această variantă completă este identică cu exemplul din secțiunea anterioară, dar mai explicită. Plasăm delimitările de trăsături împreună cu declararea parametrului de tip generic după două puncte (:) și în interiorul parantezelor unghiulare.
Sintaxa impl Trait oferă concizie în cazurile simple, în timp ce sintaxa extinsă a delimitărilor de trăsături poate să exprime mai multă complexitate în alte situații. De pildă, putem avea doi parametri ce implementează Summary. Aplicarea sintaxei impl Trait apare în felul următor:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {Utilizarea impl Trait este adecvată dacă dorim ca funcția să permită lui item1 și item2 să fie de tipuri diferite (atât timp cât ambele tipuri implementează Summary). Totuși, dacă vrem să constrângem ambii parametri să fie de același tip, atunci trebuie să apelăm la delimitarea de trăsături, ca în exemplul următor:
pub fn notify<T: Summary>(item1: &T, item2: &T) {Tipul generic T, specificat ca tip pentru parametrii item1 și item2, restricționează funcția astfel încât tipul concret al valorilor transmise ca argumente pentru item1 și item2 trebuie să fie același.
Indicarea mai multor delimitări de trăsătură folosind sintaxa +
Este posibil să specificăm concurent mai multe delimitări de trăsătă. De exemplu, dacă dorim ca notify să utilizeze formatare prin afișare, precum și metoda summarize pentru item, trebuie să notăm în definiția notify că item trebuie să implementeze trăsăturile Display și Summary. Putem realiza acest lucru utilizând sintaxa +:
pub fn notify(item: &(impl Summary + Display)) {Această sintaxă + poate fi folosită și în cazul limitelor impuse pe trăsături pentru tipuri generice:
pub fn notify<T: Summary + Display>(item: &T) {Odată ce ambele trăsături sunt specificate, în cadrul lui notify putem invoca summarize și folosi {} pentru a formata item, ceea ce este posibil datorită implementării trăsăturii Display.
Delimitări de trăsătură mai clare cu clauza where
Abundența de delimitări de trăsătură pe generici poate avea dezavantaje. Fiecare tip generic vine cu propriile sale restricții de trăsătură, astfel funcțiile cu mai mulți parametri generici pot fi supraîncărcate cu informații privind trăsăturile între numele funcției și lista parametrilor, complicând citirea semnăturii funcției. Pentru a simplifica această problemă, Rust oferă o sintaxă alternativă prin utilizarea unei clauze where care se plasează după semnătura funcției. Astfel, în loc de a scrie în modul următor:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {putem opta pentru utilizarea unei clauze where, cum ar fi:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}Semnătura funcției este astfel mai clară: numele funcției, lista parametrilor și tipul returnat sunt regrupate în proximitate, similar unei funcții simple care nu include numeroase restricții de trăsătură.
Returnarea tipurilor ce implementează trăsături
Este posibil de asemenea să utilizăm sintaxa impl Trait în poziția de returnare pentru a returna o valoare de un tip care implementează o trăsătură, așa cum este arătat în exemplul de mai jos:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
}
}Prin aplicarea impl Summary ca tip de retur, indicăm că funcția returns_summarizable va întoarce un tip ce implementează trăsătura Summary, fără a specifica tipul concret. În acest caz specific, returns_summarizable returnează un Tweet, dar codul care cheamă această funcție nu are nevoie să cunoască acest amănunt.
Posibilitatea de a specifica un tip de retur exclusiv prin trăsătura implementată se dovedește a fi extrem de valoroasă în contextul închiderilor (closure) și iteratorilor, teme ce vor fi explorate în Capitolul 13. Aceste închideri și iteratori produc tipuri cunoscute doar de compilator sau tipuri care ar fi oneros de specificat complet. Sintaxa impl Trait facilitează specificarea succintă a faptului că o funcție returnează un tip care implementează trăsătura Iterator, eliminând necesitatea de a descrie un tip extensiv.
Totuși, impl Trait poate fi folosit doar atunci când se returnează un tip unic. Spre exemplu, codul care face returnarea unui NewsArticle sau un Tweet, având tipul de retur definit ca impl Summary, nu va funcționa:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
}
}
}Este interzisă returnarea fie a unui NewsArticle, fie a unui Tweet, pe fondul restricțiilor asociate modului de implementare a sintaxei impl Trait în compilator. Metodologia de scriere a unei funcții cu acest comportament va fi detaliată în secțiunea „Utilizând obiecte de trăsătură ce permit valori pentru tipuri diverse” din Capitolul 17.
Folosirea delimitărilor de trăsături pentru implementarea condiționată a metodelor
Prin utilizarea unei delimitări de trăsături într-un bloc impl ce include parametri de tip generic, noi putem să implementăm metode în mod condiționat pentru tipurile care implementează trăsăturile specificate. Spre exemplu, tipul Pair<T> din Listarea 10-15 implementează constant funcția new pentru a crea o nouă instanță de Pair<T> (reîmprospătăm aici din secțiunea “Definirea Metodelor” a Capitolului 5 că Self este un sinonim pentru tipul blocului impl, care în acest caz este Pair<T>). Totuși, în următorul bloc impl, Pair<T> implementează metoda cmp_display doar dacă tipul său intern T aderă atât la trăsătura PartialOrd ce face posibilă compararea cât și la trăsătura Display ce permite afișarea.
Numele fișierului: src/lib.rs
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}Listarea 10-15: Implementarea condiționată a metodelor pe un tip generic, în dependență de delimitările de trăsătură
De asemenea, putem implementa condiționat o trăsătură pentru orice tip care implementează o altă trăsătură. Aceste implementări, realizate pentru orice tip care îndeplinește delimitările de trăsătură, poartă numele de implementări generalizate (blanket implementations) și sunt utilizate extensiv în biblioteca standard Rust. De exemplu, biblioteca standard oferă implementarea trăsăturii ToString pentru orice tip care implementează trăsătura Display. Blocul impl din biblioteca standard este similar cu acest fragment de cod:
impl<T: Display> ToString for T {
// --snip--
}Datorită acestei implementări generalizate prezente în biblioteca standard, noi putem invoca metoda to_string, definită de trăsătura ToString, pe orice tip ce implementează trăsătura Display. Ca urmare, avem posibilitatea de a transforma numere întregi în echivalentele lor String pentru că întregii implementează Display:
#![allow(unused)] fn main() { let s = 3.to_string(); }
Implementările generalizate pot fi găsite în documentația referitoare la trăsătura respectivă, în secțiunea “Implementors”.
Trăsăturile și delimitările de trăsături ne permit să concepem cod care utilizează parametrii de tip generic pentru a reduce dublarea, dar ne și permit să indicăm compilatorului că dorim ca tipul generic să prezinte un anumit comportament. Compilatorul, folosind informațiile delimitărilor de trăsături, poate verifica dacă toate tipurile concrete folosite în codul nostru corespund comportamentului cerut. În limbajele de programare cu tipizare dinamică, erorile legate de apeluri ale unor metode nedefinite pe un tip apar la runtime, pe când Rust transferă aceste erori la timpul de compilare, obligându-ne să rezolvăm problemele înainte ca programul nostru să fie capabil să ruleze. Mai mult, evităm necesitatea de a scrie cod care să verifice comportamentul la runtime deoarece verificările au loc în timpul compilării. Acest proces îmbunătățește performanța fără a renunța la flexibilitatea oferită de utilizarea genericilor.
Validarea referințelor cu ajutorul lifetimes
Lifetimes sunt un alt fel de generici pe care i-am utilizat deja. Aceștia nu doar că asigură faptul că un tip are comportamentul pe care îl dorim, ci și că referințele rămân valide pentru durata necesară.
Un aspect pe care nu l-am discutat în secțiunea „Referințe și împrumutare” din Capitolul 4 este acela că fiecare referință în Rust deține un lifetime, adică un domeniu de vizibilitate pentru care referința este validă. În cele mai multe situații, lifetimes sunt impliciți și inferați, așa cum sunt și tipurile, în mod obișnuit. Adnotarea tipurilor este necesară doar atunci când mai multe tipuri sunt posibile. Analog, adnotarea lifetimes este necesară atunci când duratele de viață ale referințelor pot fi interpretate diferit. Rust ne cere să definim aceste relații utilizând parametri de lifetime generici pentru a garanta că referințele utilizate în timpul execuției vor fi valide în mod cert.
Conceptul de adnotare a lifetimes nu există în multe alte limbaje de programare, ceea ce îl face să ni se pară neobișnuit. Deși nu vom trata lifetimes în totalitatea lor în acest capitol, vom explora modalitățile comune prin care este posibil să întâlnim sintaxa specifică lifetimes astfel încât să ne obișnuim cu conceptul.
Combaterea referințelor suspendate prin intermediul duratelor de viață
Scopul esențial al duratelor de viață (lifetimes) este de a înlătura referințele suspendate (dangling references), care determină programul să referențieze alte date decât cele destinate. Analizează programul din Listarea 10-16, ce conține un domeniu de vizibilitate extern și unul intern.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}Listarea 10-16: Tentativa de a folosi o referință a cărei valoare nu mai este în domeniul de vizibilitate
Notă: În Listările 10-16, 10-17 și 10-23 sunt declarate variabile fără valori inițiale, astfel numele lor sunt prezente în domeniul extern. La prima vedere, acest lucru poate părea că intră în conflict cu faptul că Rust nu permite valori null. Cu toate acestea, dacă încercăm să utilizăm o variabilă înainte să îi atribuim o valoare, vom întâlni o eroare la compilare, confirmând astfel că Rust nu acceptă valori null.
În domeniul extern este declarată o variabilă r fără valoare inițială, iar în domeniul intern este declarată o variabilă x cu valoarea inițială de 5. În domeniul intern, încercăm să stabilim r ca referință la x. La încheierea domeniului intern, încercăm să afișăm valoarea referită de r. Acest cod nu va compila deoarece valoarea la care r face referire a ieșit din domeniul de vizibilitate înainte de a fi folosită. Iată mesajul de eroare:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {}", r);
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` due to previous error
Variabila x nu "durează" suficient de mult. Aceasta iese din domeniul de vizibilitate când domeniul intern se sfârșește la linia 7. Cu toate acestea, r rămâne în domeniul extern; deoarece domeniul său de vizibilitate este mai amplu, spunem că "are o durată de viață mai mare". Dacă Rust ar permite ca acest cod să funcționeze, r ar face referință la memorie care a fost dezalocată când x a ieșit din domeniu, și orice tentativă de interacțiune cu r nu ar avea rezultate corecte. Cum determină Rust că acest cod este nevalid? Prin utilizarea unui verificator de împrumut (borrow checker).
Verificatorul de împrumut
Compilatorul Rust beneficiază de un verificator de împrumut care evaluează domeniile de vizibilitate și stabilește dacă toate împrumuturile sunt conforme. Listarea 10-17 îți prezintă același cod ca Listarea 10-16, dar cu adnotări ce indică durata de viață a variabilelor.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {}", r); // |
} // ---------+Listarea 10-17: Adnotările duratelor de viață ale r și x, denumite 'a și 'b, în ordine
În exemplul de față, am însemnat durata de viață a r cu 'a și pe cea a lui x cu 'b. Remarcăm că blocul intern 'b este considerabil mai restrâns decât blocul extern 'a. În etapa de compilare, Rust analizează și compară extinderea celor două durate și identifică faptul că r există pentru 'a, dar face referire la memorie ale cărei valori au durata 'b. Programul este respins pentru că durata 'b este inferioară lui 'a: entitatea la care face referire nu persistă atât cât durează referința.
Listarea 10-18 rezolvă problema referinței suspendate și se compilează fără niciun fel de eroare.
fn main() { let x = 5; // ----------+-- 'b // | let r = &x; // --+-- 'a | // | | println!("r: {}", r); // | | // --+ | } // ----------+
Listarea 10-18: O referință corectă, având în vedere că informațiile referite au o durată de viață mai lungă decât referința însăși
În această situație, x deține durata de viață 'b, care de această dată excede 'a. Astfel, r are libertatea de a referi x, deoarece Rust confirmă că referința din r va fi întotdeauna în vigoare pe durata existenței lui x.
Acum, cunoscând localizarea duratelor de viață ale referințelor și metodologia prin care Rust le evaluează pentru a asigura validitatea neîntreruptă a acestora, să ne orientăm spre examinarea duratelor de viață generice pentru parametri și valori returnate în contextul funcțiilor.
Durate de viață generice în funcții
Să dezvoltăm o funcție care identifică care dintre două secțiuni de string-uri este mai lungă. Această funcție va accepta două secțiuni și va oferi ca rezultat o singură secțiune de string. Implementarea corespunzătoare pentru funcția longest va face ca exemplul prezentat în Listarea 10-19 să genereze output-ul The longest string is abcd.
Numele fișierului: src/main.rs
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}Listarea 10-19: Funcția main apelează longest pentru a afla cea mai lungă secțiune dintre două secțiuni de string-uri
Trebuie subliniat faptul că funcția trebuie să opereze cu secțiuni de string-uri, adică referințe, nu cu string-uri, pentru că nu ne dorim ca longest să preia posesiunea asupra parametrilor săi. Consultă secțiunea “Secțiuni de string-uri ca
parametri” din Capitolul 4 pentru mai multe explicații privind alegerea acestor parametri în Listarea 10-19.
Dacă vom încerca să implementăm longest așa cum e exemplificat în Listarea 10-20, vom observa că nu va compila.
Numele fișierului: src/main.rs
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}Listarea 10-20: O încercare de implementare a longest, care urmează să returneze secțiunea de string mai lungă, dar care în prezent nu compilează
Eroarea întâmpinată se referă la duratele de viață:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` due to previous error
Indicațiile de ajutor arată că tipul care se returnează necesită un parametru de durată de viață generic, pentru că Rust nu este capabil să determine dacă referința ce se returnează aparține lui x sau y. Și noi suntem în aceeași incertitudine, de vreme ce funcția poate returna fie o referință către x, fie una către y, în funcție de rezultatul condiției if.
Nu avem informațiile despre valorile exacte care vor fi introduse în funcție la definirea acesteia, deci nu putem prevedea care dintre cazurile if sau else se va întâmpla. Nu cunoaștem nici care vor fi duratele de viață concrete ale referințelor ce vor fi folosite, așa că nu putem estima domeniile lor de vizibilitate pentru a decide dacă referința returnată va fi mereu validă. Verificatorul de împrumut al lui Rust nu este capabil să facă aceste deducții singur; nu are cunoștințe despre cum se corelează duratele de viață ale lui x și y cu durata de viață a valorii ce urmează să fie returnată. Pentru a rectifica eroarea, trebuie să introducem parametri generici de durată de viață, care vor clarifica relația dintre referințele implicate, permițând astfel verificatorului de împrumut să realizeze analiza necesară.
Sintaxa adnotărilor pentru duratele de Viață
Adnotările pentru duratele de viață nu influențează cât timp supraviețuiesc referințele. În realitate, ele stabilesc relații între duratele de viață ale mai multor referințe, neavând impact asupra acestora. Asemănător cu funcțiile ce acceptă orice tip când sunt definite cu parametri generici de tip, funcțiile pot accepta referințe cu orice durată de viață specificând un parametru generic de durată de viață.
Adnotările pentru duratele de viață utilizează o sintaxă ceva mai neobișnuită: numele acestor parametri încep cu apostrof (') și sunt de regulă foarte scurte și scrise cu litere mici, în manieră similară tipurilor generice. Denumirea 'a este adesea prima opțiune pentru o adnotare de durată de viață. Aceste adnotări se plasează după simbolul & al unei referințe, cu un spațiu între adnotarea și tipul referinței.
Iată nişte exemple: o referință către un i32 fără un parametru de durată de viață, o referință către un i32 cu un parametru de durată de viață 'a, și o referință mutabilă către un i32 care are de asemenea durata de viață 'a.
&i32 // o referință
&'a i32 // o referință cu durată de viață explicită
&'a mut i32 // o referință mutabilă cu durată de viață explicităO singură adnotare de durată de viață, luată individual, nu aduce multă claritate, deoarece aceste adnotări sunt proiectate să descrie pentru Rust cum relaționează între ele parametrii de durată de viață generici ai diferitelor referințe. Să analizăm cum aceste adnotări pentru duratele de viață interacționează reciproc în contextul funcției longest.
Adnotarea duratelor de viață în semnăturile funcțiilor
Pentru a aplica adnotări ale duratelor de viață în semnăturile funcțiilor, este necesar să declarăm parametrii de durată de viață generici, plasându-i între parantezele unghiulare care se află între numele funcției și lista de parametri, procedând astfel ca în cazul parametrilor de tip generici.
Semnătura trebuie să exprime următoarea restricție: referința returnată rămâne validă pe durata de viață a ambilor parametri. Aceasta descrie relația dintre duratele de viață ale parametrilor și valoarea returnată. Durata de viață 'a este numele pe care îl vom da acestei relații, pe care o vom adnota pe fiecare referință, așa cum este ilustrat în Listarea 10-21.
Numele fișierului: src/main.rs
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {}", result); } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
Listarea 10-21: Definirea funcției longest, indicând că toate referințele din semnătură trebuie să aibă durata de viață 'a
Acest cod ar trebui să compileze și să genereze rezultatul dorit atunci când este folosit odată cu
funcția main din Listarea 10-19.
Semnătura funcției ne anunță că pentru o anumită durată de viață 'a, aceasta primește doi parametri, ambii fiind secțiuni de string-uri care persistă minim pe durata de viață 'a. De asemenea, semnătura precizează că secțiunea de string returnată de funcție va persista cel puțin pe durata de viață 'a. În practică, acest lucru sugerează că durata de viață a referinței întoarse de funcțialongest corespunde cu cea mai scurtă durată de viață a valorilor referite de argumentele funcției. Aceste legături sunt relațiile pe care dorim ca Rust să le folosească în evaluarea codului nostru.
Trebuie reținut că atunci când definim parametri de durată de viață în această semnătură, nu modificăm duratele de viață ale valorilor care sunt transmise sau întoarse de funcție. În schimb, stabilim condițiile pe care verificatorul de împrumut trebuie să le aplice, respingând valorile care nu se încadrează în aceste limite. Cu alte cuvinte, funcția longest nu trebuie să cunoască exact cât timp x și y vor exista, ci trebuie să fie garantat că va exista o durată de viață care poate fi atribuită lui 'a și care va îndeplini cerințele acestei semnături.
Când vine vorba de adnotarea duratelor de viață în funcții, acestea sunt specificate în semnătura funcției, nu în corpul acesteia. Astfel adnotările devin parte integrantă a contractului funcției, pe picior de egalitate cu tipurile din semnătură. Includerea acestui contract de durată de viață în semnătura funcției simplifică analiza realizată de compilatorul Rust. Dacă întâmpinăm probleme legate de adnotările unei funcții sau de modul în care este invocată, erorile generate de compilator pot indica precis unde în codul nostru se află problemele și care sunt constrângerile nerespectate. Dacă ar exista o dependență mai mare pe inferențele Rust în ceea ce privește intențiile noastre legate de relațiile duratelor de viață, atunci compilatorul ar putea indica problemele abia după urmărirea utilizării codului la câteva niveluri de la cauza de bază.
Când folosim referințe specifice cu funcția longest, durata de viață concretă substituită pentru 'a este acea parte din durata de viață a lui x care coincide cu durata de viață a lui y. Mai direct spus, durata de viață generică 'a se va concretiza în cea mai scurtă durată de viață dintre cele ale lui x și y. Dat fiind că am adnotat referința returnată cu același parametru de durată de viață 'a, și referința returnată va fi validă pentru aceeași perioadă de timp cât sunt valide x și y.
Evaluăm acum modul în care adnotările de durată de viață limitează funcția longest printr-o demonstrație unde sunt folosite referințe cu durate de viață concrete diferite. Listarea 10-22 ne furnizează un astfel de exemplu explicit.
Numele fișierului: src/main.rs
fn main() { let string1 = String::from("long string is long"); { let string2 = String::from("xyz"); let result = longest(string1.as_str(), string2.as_str()); println!("The longest string is {}", result); } } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
Listarea 10-22: Utilizarea funcției longest cu referințe la valori String ce au durate de viață concrete diferite
În acest caz, string1 rămâne valid până la încheierea domeniului de vizibilitate exterior, string2 este valid până la încheierea domeniului de vizibilitate interior, iar result indică o valoare care rămâne validă până la finalul domeniului de vizibilitate interior. Dacă executăm acest cod, vom constata că este acreditat de verificatorul de împrumut; va compila și va crea afișajul „The longest string is long string is long”.
Continuând, să analizăm un exemplu care ilustrează necesitatea ca durata de viață a referinței în `result` să fie mai scurtă decât duratele de viață ale celor două argumente. Declararea variabilei `result` va fi efectuată în afara domeniului de vizibilitate intern, în timp ce asignarea valorii pentru aceasta va rămâne în interiorul acelui domeniu împreună cu `string2`. Vom muta instrucțiunea `println!`, ce utilizează `result`, în afara domeniului intern, după ce acesta se încheie. Codul prezentat în Listarea 10-23 nu va fi compilabil.
<span class="filename">Numele fișierului: src/main.rs</span>
```rust,ignore,does_not_compile
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {}", result);
}
#
# fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
# if x.len() > y.len() {
# x
# } else {
# y
# }
# }
Listarea 10-23: Tentativa de utilizare a result după ce string2 nu se mai află în domeniul de vizibilitate
La încercarea de a compila acest cod, întâmpinăm eroarea:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^^^^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {}", result);
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` due to previous error
Eroarea ne arată că, pentru a fi valid pentru instrucțiunea println!, string2 ar necesita să fie disponibil până la finalul domeniului extern. Rust înțelege acest aspect deoarece am adnotat duratele de viață ale parametrilor funcției și ale valorii de retur utilizând același parametru 'a.
Noi, oamenii, putem privi acest cod și înțelege că string1 este disponibil mai mult timp decât string2 și, prin urmare, result va conține o referință către string1, care, nefiind încă ieșită din domeniul de vizibilitate, rămâne validă pentru instrucțiunea println!. Cu toate acestea, compilatorul nu este capabil să deducă că referința este validă în acest caz. I-am indicat compilatorului Rust că durata de viață a referinței returnate de funcția longest coincide cu durata cea mai scurtă a referințelor primite. În consecință, verificatorul de împrumut respinge codul din Listarea 10-23 pentru că s-ar putea să aibă o referință invalidă.
Propune-ți să experimentezi cu diverse scenarii care alterează valorile și duratele de viață ale referințelor transmise funcției longest, precum și modul în care este utilizată referința retur. Înainte de compilare, formulează presupuneri referitoare la rezultatele verificatorului de împrumut și verifică ulterior dacă acestea sunt corecte!
Gândirea în termeni de durate de viață
Alegerea parametrilor de durată de viață este strâns legată de lucrul efectuat de funcția în cauză. Dacă, spre exemplu, am decide ca funcția longest să returneze constant primul argument în locul celei mai lungi secțiuni de string, indicația de durată de viață pentru parametrul y nu ar fi necesară. Așadar, următorul cod va fi considerat valid de către compilator:
Numele fișierului: src/main.rs
fn main() { let string1 = String::from("abcd"); let string2 = "efghijklmnopqrstuvwxyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {}", result); } fn longest<'a>(x: &'a str, y: &str) -> &'a str { x }
Prin introducerea parametrului de durată de viață 'a pentru argumentul x și pentru tipul de retur, dar omițându-l pe y, recunoaștem că durata de viață a lui y nu are conexiuni cu durata de viață a lui x ori cu valoarea returnată.
O funcție care returnează o referință trebuie să sincronizeze durata de viață a tipului de retur cu durata de viață a unuia dintre argumente. Dacă referința returnată nu corespunde niciunui argument, atunci ea trebuie să indică spre o valoare creată intern în funcție, ceea ce inevitabil va crea o referință suspendată, dat fiind că respectivele valori vor părăsi domeniul de vizibilitate când funcția se încheie. Să luăm spre analiză un caz de implementare eșuată a funcției longest, care va fi respins de compilator:
Numele fișierului: src/main.rs
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}Deși am definit parametrul de durată de viață 'a pentru tipul returnat, codul nu trece de etapa de compilare, pentru că durata de viață a valorii returnate nu are nicio legătură cu duratele de viață ale argumentelor. Acesta este mesajul de eroare afișat:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return reference to local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ^^^^^^^^^^^^^^^ returns a reference to data owned by the current function
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` due to previous error
Complicația de aici provine din faptul că result nu mai există după închiderea funcției longest, încercând totodată să returneze o referință către aceasta. Nu putem remedia prin parametrii de durată de viață acest tip de referință suspendată, iar in sistemul Rust, acestea sunt inacceptabile. În situații similare, soluția cea mai potrivită ar fi să optăm pentru returnarea unei date cu posesiune completă, nu sub formă de referință, astfel încât funcția apelatoare să preia responsabilitatea gestiunii acesteia.
Concluzionând, aplicarea corectă a sintaxei duratelor de viață leagă duratele de viață ale diverselor argumente de cele ale valorilor returnate, permițându-i astfel limbajului Rust să asigure operațiuni de gestionare a memoriei în mod sigur și să interzică orice operațiune ce ar putea duce la apariția referințelor suspendate sau care ar putea pune în pericol siguranța manipulării memoriei.
Adnotări de durată de viață în definițiile de structuri
Până acum, structurile pe care le-am descris includ tipuri de date cu posesiune proprie. Avem posibilitatea să definim structuri ce conțin referințe, dar pentru aceasta este necesar să adăugăm adnotări de durată de viață pentru toate referințele din definiția structurii. În Listarea 10-24, este prezentată structura ImportantExcerpt, care încorporează o secțiune de tip string.
Numele fișierului: src/main.rs
struct ImportantExcerpt<'a> { part: &'a str, } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().expect("Could not find a '.'"); let i = ImportantExcerpt { part: first_sentence, }; }
Listarea 10-24: Structura care include o referință necesitând adnotare de durată de viață
Structura posedă un unic câmp part, ce conține o secțiune dintr-un string, iar aceasta este o referință. În maniera tipurilor generice, numele parametrului generic al duratei de viață se declară în paranteze unghiulare după numele structurii, ceea ce ne permite să folosim parametrul în cadrul definiției structurii. Adnotarea indică faptul că o instanță de ImportantExcerpt nu are voie să depășească durata de viață a referinței din câmpul part.
Funcția main generează o instanță a structurii ImportantExcerpt, care înglobează o referință la prima sentință din String aparținând variabilei novel. Informația conținută în novel este disponibilă cu mult înainte de crearea instanței ImportantExcerpt. În plus, novel nu devine inaccesibil până după ce structura ImportantExcerpt este retrasă din domeniul de vizibilitate, făcând astfel ca referința din instanța ImportantExcerpt să fie validă.
Eliziunea duratei de viață
Am învățat că fiecare referință are o durată de viață şi trebuie să specificăm parametrii de durată de viață pentru funcții sau structuri care folosesc referințe. Totuși, în Capitolul 4, am prezentat o funcție în Listarea 4-9, reafirmată în Listarea 10-25, ce s-a compilat fără adnotări de durată de viață.
Numele fişierului: src/lib.rs
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // first_word works on slices of `String`s let word = first_word(&my_string[..]); let my_string_literal = "hello world"; // first_word works on slices of string literals let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
Listarea 10-25: O funcție definită în Listarea 4-9 care s-a compilat fără adnotările de durată de viață, deși parametrul și tipul de retur sunt referințe
Funcția se compilează fără adnotări de durată de viață din motive istorice: în versiunile timpurii (pre-1.0) ale Rust, codul respectiv nu ar fi funcționat, fiind necesară o durată de viață explicită pentru fiecare referință. Semnătura funcției de atunci ar fi arătat astfel:
fn first_word<'a>(s: &'a str) -> &'a str {După redactarea unei cantități considerabile de cod Rust, echipa a identificat situații specifice unde programatorii Rust repetă adnotări similare de durată de viață. Având un șablon previzibil și determinist, dezvoltatorii au înscris aceste modele în comportamentul compilatorului, astfel încât verificatorul de împrumut să poată înțelege duratele de viață implicit, eliminând necesitatea adnotărilor explicite.
Această parte din istoria Rust este relevantă, deoarece este posibil ca în viitor, pe măsură ce sunt identificate alte șabloane deterministe, să avem nevoie de și mai puține adnotări de durată de viață.
Regulile care guvernează această analiză a referințelor în Rust se numesc regulile de eliziune a duratei de viață. Acestea nu sunt directive pentru programatori, ci cazuri specifice pe care compilatorul le recunoaște, iar în prezența acestora, nu este nevoie să specifice durate de viață în cod.
Eliziunea nu implică inferență totală. Dacă, după aplicarea regulilor în mod deterministic, rămân ambiguități cu privire la duratele de viață ale anumitor referințe, compilatorul nu va specula asupra lor. În schimb, va emite o eroare ce poate fi rezolvată prin adăugarea explicită a adnotărilor necesare.
Duratele de viață asociate parametrilor de funcție sau metodei sunt cunoscute drept durate de viață de intrare, iar cele legate de valori returnate sunt durate de viață de ieșire.
Pentru deducerea duratelor de viață ale referințelor lipsite de adnotări explicite, compilatorul urmează trei reguli. Prima se aplică la duratele de viață de intrare, iar următoarele două la duratele de viață de ieșire. Dacă, după aceste trei reguli, există referințe având în continuare o durată de viață nedeterminată, compilatorul va întrerupe procesul și va raporta o eroare. Regulile sunt aplicabile atât definițiilor de fn, cât și blocurilor impl.
Prima regulă pe care compilatorul o impune este aceea că atribuie un parametru de durată de viață pentru fiecare parametru care este o referință. Concret, o funcție cu un singur parametru va avea un parametru de durată de viață: fn foo<'a>(x: &'a i32). În cazul unei funcții cu doi parametri, vor exista doi parametri de durată de viață separați: fn foo<'a, 'b>(x: &'a i32, y: &'b i32) și așa mai departe.
Conform celei de-a doua reguli, dacă avem un singur parametru de intrare cu durată de viață, atunci aceasta se aplică întregii ieșiri: fn foo<'a>(x: &'a i32) -> &'a i32.
Când intervin mai mulți parametri de intrare cu durate de viață și unul dintre aceștia este &self sau &mut self – adică în contextul unei metode – durata de viață a self se va atribui la întreaga ieșire. Acest lucru simplifică scrierea și citirea metodelor, deoarece nu este nevoie de atât de multe simboluri.
Imaginându-ne în rolul compilatorului, aplicăm aceste reguli pentru a înțelege duratele de viață ale referințelor din semnătura funcției first_word, așa cum e prezentată în Listarea 10-25. Semnătura inițială nu conține nicio durată de viață asociată referințelor:
fn first_word(s: &str) -> &str {Aplicând prima regulă, compilatorul acordă fiecărui parametru propria durată de viață, etichetată în mod tradițional cu 'a:
fn first_word<'a>(s: &'a str) -> &str {Datorită prezenței unui unic parametru de intrare cu durată de viață, a doua regulă intervine pentru a atribui aceeași durată de viață și la ieșire, rezultând în următoarea semnătură:
fn first_word<'a>(s: &'a str) -> &'a str {Astfel, toate referințele din această semnătură de funcție sunt acum prevăzute cu durate de viață, dând voie compilatorului să progreseze în analiză fără ca programatorul să fie nevoit să adnoteze manual aceste durate.
Luăm ca exemplu funcția longest, care la început nu includea parametri de durată de viață, așa cum vedem în Listarea 10-20:
fn longest(x: &str, y: &str) -> &str {Aplicăm prima regulă și observăm că fiecare dintre cei doi parametri are asignată o durată de viață distinctă:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {În acest caz, nici a doua nici a treia regulă nu sunt aplicabile – a doua pentru că avem multiple durate de viață de intrare și a treia pentru că nu avem de-a face cu o metodă care implică self. Prin urmare, după examinarea celor trei reguli, încă nu se poate determina durata de viață a returnării funcției — motiv pentru care întâmpinăm o eroare la compilarea codului din Listarea 10-20: regulile de eliziune nu oferă suficiente informații compilatorului pentru a stabili duratele de viață ale referințelor din semnătură.
Deoarece a treia regulă este relevantă preponderent pentru metode, ne vom orienta în continuare spre analiza duratelor de viață în acest context particular, astfel încât să înțelegem de ce adnotarea manuală a duratelor de viață în semnăturile metodelor nu este, de obicei, necesară.
Adnotarea duratelor de viață în definirea metodelor
Când definim metode pentru o structură ce include durate de viață, aplicăm aceeași sintaxă ca și pentru parametrii de tipuri generice, demonstrată în Listarea 10-11. Decizia de unde să declarăm și să utilizăm parametrii duratei de viață este influențată de faptul că aceștia sunt asociați cu câmpurile structurii sau cu parametrii metodelor și valorile returnate.
Numele pentru duratele de viață ale câmpurilor structurii sunt întotdeauna necesare după cuvântul impl și trebuie utilizate în continuarea numelui structurii, deoarece aceste durate de viață fac parte integrantă din tipul structurii.
În cadrul semnăturilor de metode din blocul impl, referințele pot fi conectate la durata de viață a referințelor din câmpurile structurii sau pot fi complet independente. În plus, regulile de eliziune a duratelor de viață percep frecvent în așa fel încât adnotările de durată de viață nu sunt necesare în semnăturile metodelor. Să evaluăm câteva exemple folosind structura ImportantExcerpt, pe care am definit-o în Listarea 10-24.
Mai întâi, examinăm o metodă denumită level, cu singurul parametru fiind o referință la self, care returnează o valoare de tip i32 și nu este o referință la altceva:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {}", announcement); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().expect("Could not find a '.'"); let i = ImportantExcerpt { part: first_sentence, }; }
Este necesară declararea parametrului de durată de viață după impl și a utilizării acestuia după numele tipului, însă nu este imperativă adnotarea duratei de viață a referinței la self datorită primei reguli de eliziune.
Iată un exemplu în care intervine a treia regulă de eliziune a duratei de viață:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {}", announcement); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().expect("Could not find a '.'"); let i = ImportantExcerpt { part: first_sentence, }; }
Dat fiind că există două durate de viață pentru argumente, Rust aplică prima regulă de eliziune și atribuie fiecăruia dintre &self și announcement propria durată de viață. Deoarece &self este unul dintre parametri, tipul de retur primește durata de viață a referinței &self, astfel fiind stabilite toate duratele de viață.
Durata de viață 'static
Un tip special de durată de viață pe care trebuie să-l abordăm este 'static, care semnalează că referința în cauză poate persista pentru întregul timp al execuției programului. Fiecare literal de tip string are durata de viață 'static, pe care o putem nota în felul următor:
#![allow(unused)] fn main() { let s: &'static str = "Am o durată de viață statică."; }
Textul acestui string este încapsulat direct în binarul programului, care este constant disponibil. Așadar, durata de viață a tuturor literalelor de string este 'static.
Poate că vei întâlni sugestii de utilizare a duratei de viață 'static atunci când apar mesaje de eroare. Însă, înainte de a atribui 'static ca timp de durată de viață pentru o referință, e vital să te gândești dacă respectiva referință chiar necesită o durată de viață ce acoperă întreaga perioadă a programului, și dacă chiar vrei acest lucru. De regulă, un mesaj de eroare ce recomandă durata de viață 'static este cauzat de încercarea de a genera o referință suspendată sau de o discrepanță între duratele de viață disponibile. În astfel de situații, este indicat să remediem aceste probleme, și nu să optăm pentru specificarea duratei de viață 'static.
Combinarea parametrilor generici de tip, delimitărilor de trăsături și a duratelor de viață
Să abordăm sintaxa necesară pentru a defini parametri generici de tip, delimitări de trăsături și durate de viață, toți concentrați într-o singura funcție!
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest_with_an_announcement( string1.as_str(), string2, "Today is someone's birthday!", ); println!("The longest string is {}", result); } use std::fmt::Display; fn longest_with_an_announcement<'a, T>( x: &'a str, y: &'a str, ann: T, ) -> &'a str where T: Display, { println!("Announcement! {}", ann); if x.len() > y.len() { x } else { y } }
Aceasta este funcția longest din Listarea 10-21, care va returna secțiunea de string mai lungă dintre două. Acum a fost adăugat un parametru suplimentar denumit ann de tipul generic T. Acesta poate fi orice tip ce implementează trăsătura Display, așa cum este indicat de clauza where. Parametrul suplimentar este afișat utilizând {}, de aici și necesitatea delimitării trăsăturii Display. Duratele de viață sunt considerate tot un tip de parametri generici, așadar declarațiile parametrului a și ale tipului generic T sunt listate împreună, în interiorul parantezelor unghiulare care succed numele funcției.
Sumar
Am abordat numeroase subiecte în acest capitol! Ești acum înarmat cu cunoștințele necesare despre parametrii de tip generic, trăsăturile și delimitările de trăsătură, cât și despre parametrii generici de durată de viață, astfel încât să poți crea cod fără redundanțe, aplicabil în diverse contexte. Parametrii de tip generic îți permit să extinzi aplicabilitatea codului la mai multe tipuri. Folosirea trăsăturilor și a delimitărilor de trăsătură asigură că tipurile generice vor poseda comportamentul cerut de codul tău. Ți s-a prezentat modul de utilizare a adnotărilor de durată de viață pentru a preveni orice referințe suspendate în codul flexibil pe care îl produci. Toate aceste analize se desfășoară în etapa de compilare, fără a afecta performanța la rulare!
Este uimitor cât de multe mai sunt de învățat pe temele pe care le-am parcurs: Capitolul 17 se concentrează pe obiectele-trăsătură, oferindu-ți o nouă perspectivă asupra utilizării trăsăturilor. De asemenea, vei descoperi scenarii mai complexe ce implică adnotările de durată de viață, relevante îndeosebi în cazuri avansate; pentru aceste situații, recomandăm consultarea Rust Reference. Dar înainte de aceasta, vei învăța cum să elaborezi testele în Rust, pentru a confirma că programul tău se comportă exact cum trebuie.
Testare automatizată în Rust
În eseu din 1972 intitulat "The Humble Programmer", Edsger W. Dijkstra remarcă faptul că "Testarea programelor poate fi un mijloc foarte eficace de a evidenția prezența defectelor, însă este total inadecvată pentru a garanta absența lor." Aceasta nu înseamnă că nu ar trebui să ne străduim să testăm tot ce putem!
Corectitudinea în programele noastre se referă la măsura în care codul nostru efectuează ceea ce ne-am propus să realizeze. Rust este conceput cu o atenție sporită asupra corectitudinii programelor, dar această corectitudine este complexă și dificil de atestat. Sistemul de tipuri din Rust poartă o bună parte din această responsabilitate, însă sistemul de tipuri nu poate intercepta toate problemele. Din acest motiv, Rust oferă suport pentru scrierea de teste automate.
Luăm cazul în care compunem o funcție add_two care adaugă 2 la numărul primit ca argument.
Această funcție are o semnătură care primește un integer ca parametru și returnează un
integer ca rezultat. Implementând și compilând această funcție, Rust efectuează toate
verificările de tip și de împrumut pe care le-am studiat până acum pentru a ne asigura că, de exemplu, nu introducem un String sau o referință nevalidă
în această funcție. Dar, Rust nu poate confirma dacă funcția va executa exact
ce dorim noi, care este să returneze parametrul adunat cu 2 în locul parametrului adunat cu 10 sau scăzut cu 50! Pentru acest lucru sunt indispensabile testele.
Putem crea teste care susțin, de pildă, că atunci când pasăm 3 la
funcția add_two, ieșirea este 5. Aceste teste le putem executa ori de câte ori
facem schimbări la cod pentru a verifica faptul că niciun comportament corect deja existent
nu a fost afectat.
Testarea este o capacitate complexă: deși nu putem acoperi toate detaliile despre cum se scriu teste de înaltă calitate într-un singur capitol, vom trata mecanismele sistemului de testare din Rust. Vom discuta despre adnotațiile și macro-urile pe care le aveți la dispoziție când redactați teste, comportamentul implicit și opțiunile de rulare a testelor, și cum să clasificăm testele în teste de unitate și teste de integrare.
Cum să scriem teste
Testele sunt funcții Rust care verifică dacă codul non-test funcționează așa cum este așteptat. Corpurile funcțiilor de test îndeplinesc, de regulă, următoarele trei acțiuni:
- Inițializarea datelor sau a stării necesare.
- Executarea codului pe care dorești să-l testezi.
- Confirmarea că rezultatele sunt cele așteptate.
Să examinăm caracteristicile specifice pe care Rust le pune la dispoziție pentru scrierea testelor care realizează aceste acțiuni. Printre acestea se numără atributul test, câteva macro-uri, precum și atributul should_panic.
Anatomia unei funcții de test
În cea mai simplă formă, un test în Rust este o funcție adnotată cu atributul test. Atributele sunt meta-date despre porțiuni de cod Rust; un exemplu este atributul derive pe care l-am folosit atunci când lucram cu structurile în Capitolul 5. Ca să schimbi o funcție obișnuită într-o funcție de test, trebuie să adaugi #[test] pe linia deasupra lui fn. Atunci când executăm testele utilizând comanda cargo test, Rust compilează un binar runner de test care rulează funcțiile adnotate și raportează dacă fiecare dintre funcțiile de test a trecut sau nu.
Când începem un proiect nou de bibliotecă cu Cargo, un modul de test cu o funcție de test înăuntru ni se generează automat. Acest modul ne oferă un șablon pentru scrierea testelor, astfel încât să nu fie nevoie să căutăm structura exactă și sintaxa de fiecare dată când începem un proiect nou. Putem adăuga oricâte funcții de testare și module de testare dorim!
Vom investiga unele aspecte ale modului în care funcționează testele experimentând cu șablonul de test înainte de a testa efectiv orice cod. Apoi vom scrie teste concrete care vor apela codul pe care l-am scris și vom asigura că comportamentul său este cel corect.
Să creăm un nou proiect de bibliotecă denumit adder care va aduna două numere:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
Conținutul fișierului src/lib.rs din biblioteca dumneavoastră adder ar trebui să arate ca în Listarea 11-1.
Numele fișierului: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
let result = 2 + 2;
assert_eq!(result, 4);
}
}Listarea 11-1: Modulul de test și funcția generate automat de cargo new
Pentru moment, să ignorăm primele două linii și să ne concentrăm pe funcția în sine. Notați adnotarea #[test]: acest atribut indică faptul că este o funcție de test, astfel încât runner-ul de test să știe să trateze această funcție ca pe un test. Ar putea exista și funcții care nu sunt de test în modulul tests pentru a aranja scenarii comune sau pentru a efectua operații periodice, prin urmare trebuie să indicăm întotdeauna care funcții sunt teste.
Corpul funcției exemplu folosește macro-ul assert_eq! pentru a afirma că result, care conține rezultatul adunării lui 2 cu 2, este egal cu 4. Aceasta afirmație servește ca un exemplu al formatului pentru un test tipic. Să o rulăm, pentru a vedea că acest test este valid.
Comanda cargo test efectuează rularea tuturor testelor din cadrul proiectului nostru, așa cum vedem în Listarea 11-2.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Listarea 11-2: Afişarea rezultatului testului generat automat
Cargo a compilat și a executat testul cu succes. Ne este afișată linia running 1 test, urmând ca apoi să fie prezentat numele funcției de testare generate, it_works, și că rezultatul acestui test este ok. Rezumatul care indică test result: ok. confirmă faptul că toate testele au trecut, iar detaliile 1 passed; 0 failed sumarizează numărul testelor care au avut succes și al celor care au eșuat.
Există posibilitatea ca un test să fie marcat ca ignorat, pentru a evita rularea lui în anumite condiții; acest lucru va fi discutat în secțiunea “Ignorarea unor teste la cerere” mai încolo în acest capitol. Deoarece nu am procedat așa în cazul de față, sumarul indică 0 ignored. De asemenea, putem utiliza un argument în comanda cargo test pentru a rula doar testele care corespund unui anumit șir de caractere, un proces cunoscut sub numele de filtrare, care va fi explicat în secțiunea “Rularea selectivă a testelor după nume”. În exemplul nostru nu s-a realizat filtrarea, așadar sumarul indică 0 filtered out.
Indicația 0 measured se referă la teste de tip benchmark care măsoară performanța și, momentan, sunt disponibile doar în Nightly Rust. Pentru mai multe detalii, consultați Documentația testelor de benchmark.
Partea următoare a rezultatelor testelor, începând cu Doc-tests adder, reprezintă rezultatele testelor realizate pe documentație. Deși nu am creat încă teste de documentație, Rust permite compilarea oricărui cod exemplu prezent în documentația API-ului. Aceasta garantează menținerea sincronizării între documentație și cod! Modalitatea de redactare a testelor de documentație va fi discutată în secțiunea “Testele din comentariile de documentație” din Capitolul 14. Momentan, vom lăsa deoparte ieșirea lui Doc-tests.
Să adaptăm testul astfel încât să corespundă specificațiilor dorite de noi. Începem prin a redenumi funcția it_works în ceva mai sugerativ, cum ar fi exploration, în felul următor:
Numele fișierului: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn exploration() {
assert_eq!(2 + 2, 4);
}
}Rulează comanda cargo test încă o dată. Rezultatul va afișa acum exploration în loc de it_works:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Adăugăm un test suplimentar, dar intenționat să eșueze. Un test este marcat ca fiind nereușit atunci când o parte a funcției de test dezlănțuie panică. Testele sunt executate fiecare într-un fir de execuție propriu, iar dacă firul principal identifică prăbușirea unui astfel de fir, testul respectiv este declarat eșuat. Am învățat în Capitolul 9 că modalitatea cea mai directă de a declanșa panică este apelarea macro-ului panic!. Scrie noul test ca o funcție cu numele another, pentru ca fișierul tău src/lib.rs să fie conform cu Listarea 11-3.
Numele fișierului: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn exploration() {
assert_eq!(2 + 2, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}Listarea 11-3: Adăugarea unui test secund care va eșua prin invocarea macro-ului panic!
Relansează testele folosind cargo test. Output-ul ar trebui să se alinieze cu Listarea 11-4, arătând reușita testului exploration și eșecul testului another.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'tests::another' panicked at 'Make this test fail', src/lib.rs:10:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Listarea 11-4: Rezultatele testelor când unul trece și celălalt eșuează
Linia pentru test tests::another nu mai indică ok, ci FAILED. Apar două secțiuni noi între rezultatele individuale și sumar: prima detaliază motivele eșecului fiecărui test. În exemplul nostru, se prezintă că testul another a eșuat deoarece a panicat la 'Make this test fail' la linia 10 în fișierul src/lib.rs. Următoarea secțiune enumeră simplu numele testelor care au eșuat, util când avem multiple teste cu multe informații de eșec detaliate. Numele unui test eșuat poate fi folosit pentru a rula doar acel test, ușurând astfel depanarea; vom explora mai detaliat metodele de rulare a testelor în secțiunea „Controlând cum sunt rulate testele”.
În sumar, afișat la sfârșit, vedem că rezultatul global al testării este FAILED. Avem un test care a trecut și unul care a eșuat.
Având acum cunoștințe despre cum se prezintă rezultatele testelor în diverse condiții, să ne îndreptăm atenția către alte macro-uri, în afara de panic!, care sunt utilitare în cadrul testelor.
Folosirea macro-ului assert! pentru a verifica rezultatele
Macro-ul assert!, oferit de biblioteca standard, este extrem de util pentru verificarea conformității unei condiții dintr-un test cu valoarea true. Oferim macro-ului assert! un argument care produce un rezultat Boolean. Dacă rezultatul este true, testul continuă fără întreruperi și este considerat cu succes. În cazul unui rezultat false, assert! inițiază panic!, rezultând într-un test nereușit. Implementarea macro-ului assert! ne ajută să ne asigurăm că funcționalitățile codului nostru operează conform așteptărilor.
Reamintim structura Rectangle și funcția ei can_hold prezentate în Capitolul 5, Listarea 5-15, acum reîntâlnite în Listarea 11-5. Vom include acest cod în fișierul src/lib.rs și vom dezvolta teste ce folosesc macro-ul assert!.
Numele fișierului: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}Listarea 11-5: Reutilizarea structurii Rectangle și a metodei can_hold
Având în vedere că metoda can_hold generează un Boolean, aceasta este perfectă pentru testarea cu macro-ul assert!. În Listarea 11-6, vom scrie un test pentru can_hold prin crearea unei instanțe Rectangle cu dimensiunile 8 în lățime și 7 în înălțime, verificând astfel că poate găzdui o altă instanță Rectangle de dimensiuni 5 cu 1.
Numele fișierului: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}Listarea 11-6: Un test pentru can_hold ce verifică dacă un
dreptunghi de dimensiuni mai mari poate de fapt să includă un dreptunghi mai mic
În modulul tests am adăugat linia use super::*;. Acest modul respectă regulile de vizibilitate prezentate în Capitolul 7, secțiunea privind „Utilizarea căilor pentru a face referire la un element în structura de module”
. Fiind un modul intern, este necesar să importăm codul ce trebuie testat din modulul extern în sfera de vizibilitate a modulului intern. Folosim un glob pentru ca tot ce este definit în modulul extern să fie disponibil aici, în modulul tests.
Numele testului nostru este larger_can_hold_smaller. Am construit cele două obiecte Rectangle necesare testului. Apoi, am utilizat macro-ul assert! pentru a evalua larger.can_hold(&smaller), o expresie care ar trebui să returneze true, semn că testul nostru este corect. Verificăm acum rezultatul!
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Rezultatul este conform așteptărilor! Acum, să proiectăm un alt test, care presupune că un dreptunghi mai mic nu poate conține unul mai mare:
Numele fișierului: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Deoarece rezultatul corect pentru funcția can_hold în acest caz este false,
este necesar să negăm rezultatul înainte de a-l transmite macro-ului assert!. Astfel,
testul nostru va reuși dacă can_hold returnează false:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Avem două teste care au trecut! Să vedem acum ce se întâmplă cu rezultatele testelor când
introducem un defect în cod. Vom modifica implementarea metodei can_hold
înlocuind semnul mai mare cu un semn mai mic în comparația lățimilor:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Rularea testelor acum generează următoarele:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at 'assertion failed: larger.can_hold(&smaller)', src/lib.rs:28:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Testele noastre au depistat defectul! Având în vedere că larger.width este 8 și smaller.width este 5, comparația lățimilor în can_hold acum oferă rezultatul false: 8 nu este
mai mic decât 5.
Verificarea egalității cu macro-urile assert_eq! și assert_ne!
Pentru a testa corectitudinea unei funcționalități, este des întâlnită verificarea egalității între rezultatul codului în execuție și valoarea pe care o anticipăm. Aceasta se poate efectua cu ajutorul macro-ului assert!, unde se furnizează o expresie cu operatorul ==. Dat fiind că acest tip de test este frecvent, biblioteca standard include două macro-uri speciale — assert_eq! și assert_ne! — care facilitează testarea. Acestea compară două valori pentru a determina dacă sunt egale sau diferite. În cazul în care aserțiunea eșuează, macro-urile afișează valorile comparate, ajutându-ne să înțelegem cauza eșecului. Spre deosebire, assert! indică pur și simplu că a rezultat o valoare false pentru expresia ==, fără a dezvălui valorile care au generat această concluzie.
În Listarea 11-7, am definit o funcție cu denumirea add_two, care adaugă 2 la parametrul primit. Testăm funcția prin intermediul macro-ului assert_eq!.
Numele fișierului: src/lib.rs
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
assert_eq!(4, add_two(2));
}
}Listarea 11-7: Testarea funcției add_two cu ajutorul macro-ului assert_eq!
Verificăm dacă testul se validează.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ca argument pentru assert_eq!, trimitem valoarea 4, care corespunde rezultatului funcției add_two(2). Linia reprezentativă pentru acest test este test tests::it_adds_two ... ok, iar termenul ok ne confirmă că testul a avut succes.
Pentru a vedea cum reacționează assert_eq! în caz de eșec, să inserăm o eroare în cod. Schimbăm funcția add_two astfel încât acum să adauge 3, nu 2:
pub fn add_two(a: i32) -> i32 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
assert_eq!(4, add_two(2));
}
}Repornim testele:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'tests::it_adds_two' panicked at 'assertion failed: `(left == right)`
left: `4`,
right: `5`', src/lib.rs:11:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Testul nostru a depistat defectul! Testul it_adds_two a eșuat, iar mesajul indică faptul că aserțiunea care a dat greș a fost assertion failed: `(left == right)` și ne prezintă valorile pentru left și right. Această informație ne ajută să începem depanarea: argumentul left a fost 4, dar argumentul right, unde aveam add_two(2), era 5. Imaginează-ți cât de util este acest lucru când derulăm multe teste concomitent.
E bine să știm că în anumite limbaje de programare și framework-uri de testare, parametrii funcțiunilor de aserțiune a egalității sunt denumiți expected și actual, iar ordinea în care sunt oferite argumentele e importantă. În Rust, totuși, aceștia se numesc left și right, și nu contează ordinea în care indicăm valoarea anticipată și valoarea produsă de cod. Aserțiunea din acest test ar putea fi exprimată de asemenea ca assert_eq!(add_two(2), 4), ceea ce ar genera același mesaj de eșec, afișând assertion failed: `(left == right)`.
Macro-ul assert_ne! reușește dacă cele două valori pe care le oferim nu sunt identice și eșuează dacă sunt identice. Acest macro este deosebit de folositor în situațiile în care nu putem prezice ce valoare va rezulta, dar știm sigur ce valoare nu ar trebui să fie. Dacă, de exemplu, testăm o funcție care schimbă garantat intrarea într-un anume mod, însă modul exact de schimbare depinde de ziua în care rulăm testul, cel mai adecvat ar fi să afirmăm că rezultatul funcției nu e egal cu inputul.
La nivel intern, macro-urile assert_eq! și assert_ne! utilizează operatorii == și !=. Atunci când aserțiunile nu sunt valide, aceste macro-uri afișează argumentele folosind formatul de debug, presupunând că valorile comparate implementează trăsăturile PartialEq și Debug. Toate tipurile de date primitive și majoritatea tipurilor standard le implementează. Pentru structurile și enum-urile proprii, va fi necesar să implementați PartialEq pentru a testa egalitatea acestora și Debug, pentru a afișa valorile atunci când aserțiunea pică. Fiind trăsături care pot fi obținute prin derivare, după cum este explicat în Listarea 5-12 din Capitolul 5, de obicei aceasta se face simplu, prin adăugarea adnotării #[derive(PartialEq, Debug)] la definiția structurii sau a enum-ului. Pentru mai multe detalii despre aceste trăsături si altele derivabile, consultați Anexa C, „Trăsături derivabile,”.
Adăugarea de mesaje de eroare particularizate
Este posibil să adăugați un mesaj personalizat care să fie afișat alături de mesajul de eșec, folosind argumente opționale în macro-urile assert!, assert_eq! și assert_ne!. Argumentele adiționale după cele obligatorii sunt înaintate macro-ului format! (abordat în Capitolul 8, în secțiunea “Concatenarea utilizând operatorul + sau macro-ul format!"), ceea ce înseamnă că puteți furniza un șir de formatare ce include locuri rezervate {} și valorile pentru completarea acestora. Mesajele personalizate sunt excelente pentru explicarea scopului unei afirmații și, atunci când un test nu este trecut, veți obține o înțelegere mai profundă a problemei cu care se confruntă codul.
De exemplu, presupunem că dispunem de o funcție ce emite o salutare personalizată și dorim să confirmăm că numele furnizat apare în ceea ce returnează funcția:
Numele fișierului: src/lib.rs
pub fn greeting(name: &str) -> String {
format!("Hello {}!", name)
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Cerințele programului nu au fost încă finalizate, și anticipăm că partea cu Hello din mesajul de salut va fi modificată. Am decis să evităm actualizarea testului de fiecare dată când cerințele se modifică, așa că în loc să căutăm o potrivire exactă cu valoarea întoarsă de funcția greeting, vom verifica doar dacă rezultatul include textul parametrului de intrare.
Introducem un defect în cod acum, schimbând funcția greeting pentru a nu mai include name, și vedem cum se prezintă eșecul testului fără un mesaj personalizat:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Rularea acestui test oferă următoarele informații:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished test [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at 'assertion failed: result.contains(\"Carol\")', src/lib.rs:12:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Acest rezultat doar ne informează că aserțiunea nu a reușit și pe ce linie se găsește. Un mesaj de eșec mai clarificator ar include valoarea returnată de funcția greeting. Adăugăm un mesaj personalizat ce include un șir de formatare cu un loc rezervat ce primește valoarea reală de la funcția greeting:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{}`",
result
);
}
}Acum, dacă executăm testul, vom obține un mesaj de eroare care ne oferă mai multe detalii:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished test [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at 'Greeting did not contain name, value was `Hello!`', src/lib.rs:12:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
În acest mod, putem vedea clar valoarea reală primită în test, ce ne va ușura munca de depanare, informându-ne despre ce s-a petrecut în realitate, spre deosebire de ce ne așteptam să se întâmple.
Verificarea de panică cu should_panic
Dincolo de a verifica valorile returnate, este esențial să ne asigurăm că tratăm corect condițiile de eroare în codul nostru. De pildă, să ne gândim la structura Guess definită în Capitolul 9, Listarea 9-13. Codul care implementează Guess se bazează pe premisa că instanțele de tip Guess vor include exclusiv valori între 1 și 100. De aceea, putem crea un test care să confirme că încercarea de a inițializa un obiect Guess cu o valoare din afara acestui interval va cauza o panică.
Procedăm adăugând atributul should_panic la funcția noastră de testare. Testul este considerat valid dacă se generează panică în codul funcției; eșuează în caz contrar.
Listarea 11-8 ilustrează un test care asigură că condițiile de eroare de la Guess::new se produc conform așteptărilor.
Numele fișierului: src/lib.rs
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}Listarea 11-8: Testarea unei condiții determinante pentru
generarea unei panic!
Atributul #[should_panic] este așezat imediat după #[test] și înaintea funcției de test căreia i se aplică. Privim rezultatul când acest test își atinge scopul:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Rezultatul este convingător! Acum, să provocăm intenționat o eroare înlăturând condiția ca funcția new să declanșeze o panică atunci când valoarea depășește 100:
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}În momentul în care executăm testul din Listarea 11-8, observăm că va eșua:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Mesajul primit în această situație nu este foarte informativ, dar când inspectăm funcția de test, remarcăm că este marcată cu `#[should_panic]`. Înseamnă că testul a eșuat pentru că codul nu a provocat o panică.
Testele care folosesc `should_panic` pot fi neclare. Astfel de teste ar putea reuși chiar dacă panică apar din alte motive decât cele pe care le anticipam. Pentru a îmbunătăți precizia testelor cu `should_panic`, putem adăuga un parametru facultativ `expected` atributului `should_panic`. Aparatul de testare va confirma că mesajul de eroare conține textul furnizat. De pildă, să luăm în calcul codul modificat pentru `Guess` prezentat în Listarea 11-9, care ilustrează că funcția `new` declanșează panica cu mesaje diferite, bazat pe valoarea fiind prea mică sau prea mare.
<span class="filename">Numele fișierului: src/lib.rs</span>
```rust,noplayground
# pub struct Guess {
# value: i32,
# }
#
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {}.",
value
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {}.",
value
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}
Listarea 11-9: Testul unui panic! cu un mesaj ce conține un substring specificat
Acest test va reuși fiindcă valoarea adăugată la parametrul expected din atributul should_panic se regăsește în mesajul emis la panicare de funcția Guess::new. Opțional, am fi putut alege să detaliem întreg mesajul la care ne așteptam, în acest caz fiind Guess value must be less than or equal to 100, got 200. Hotărâm ce mesaj dorim să includem în baza a cât de unic sau variabil este mesajul de panică și cât de exact dorim să fie testul. În situația de față, un substring al mesajului de panică este suficient pentru a verifica că în funcția de test s-a executat secțiunea else if value > 100.
Să vedem ce se întâmplă atunci când un test should_panic cu un mesaj expected nu trece. Vom crea din nou o eroare în codul nostru prin schimbarea locului conținuturilor blocurilor if value < 1 cu else if value > 100:
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {}.",
value
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {}.",
value
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}Când executăm testul should_panic, acesta nu se desfășoară așa cum am dori:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at 'Guess value must be greater than or equal to 1, got 200.', src/lib.rs:13:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: `"Guess value must be greater than or equal to 1, got 200."`,
expected substring: `"less than or equal to 100"`
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Mesajul de eroare arată că testul a cauzat o panică, cum era anticipat, însă mesajul de panică nu a inclus substring-ul dorit 'Guess value must be less than or equal to 100'. În schimb, mesajul de panică primit a fost Guess value must be greater than or equal to 1, got 200. Acum, putem începe investigarea pentru identificarea sursei problemei din cod.
Utilizarea Result<T, E> în teste
Până acum, testele create au generat panică atunci când s-au confruntat cu un eșec. O altă abordare este scrierea de teste care folosesc Result<T, E>. Ca exemplu, redau testul din Listarea 11-1, reconfigurat astfel încât să utilizeze Result<T, E> și să returneze Err în loc să declanșeze panică:
#[cfg(test)]
mod tests {
#[test]
fn it_works() -> Result<(), String> {
if 2 + 2 == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}Acum, funcția it_works are tipul de retur Result<(), String>. În corpul acesteia, în loc să folosim macro-ul assert_eq!, vom returna Ok(()) pentru un test reușit sau Err cu un String atașat în caz de eșec.
Folosirea Result<T, E> la scrierea testelor ne permite să aplicăm operatorul ? direct în corpul acestora, oferind o metodă practică pentru redactarea testelor care trebuie să eșueze când orice operațiune internă returnează varianta Err.
Adnotarea #[should_panic] nu poate fi folosită în testele care returnează Result<T, E>. Dacă dorim să asigurăm că o operațiune specifică se finalizează cu o variantă Err, nu ar trebui să utilizăm operatorul ? pentru valorile Result<T, E>, ci mai degrabă să validăm eșecul cu assert!(value.is_err()).
Având astfel mai multe metode de creare a testelor, este momentul oportun să înțelegem mai bine ce se întâmplă atunci când executăm testele și să explorăm opțiunile disponibile prin comanda cargo test.
Controlul modului în care testele sunt executate
Similar cu cargo run, care compilează codul și ulterior rulează binarul rezultat,
cargo test compilează codul în mod de test și execută binarul de testare creat. Comportamentul standard al binarului generat de cargo test este să execute toate testele simultan și să rețină output-ul produs pe durata execuției testelor, evitând astfel afișarea output-ului și ajutând la o lectură facilă a rezultatelor testelor. Pot fi utilizate opțiuni de linie de comandă pentru a modifica acest comportament standard.
Anumite opțiuni de linie de comandă sunt pentru cargo test, iar altele pentru binarul de test rezultat. Pentru a le diferenția, argumentele destinate cargo test sunt plasate înaintea separatorului --, urmate de argumentele pentru binarul de test. Executând cargo test --help se afișează opțiunile disponibile pentru cargo test, iar cu cargo test -- --help vei obține informații despre opțiunile ce pot fi aplicate după separator.
Executarea testelor în paralel sau secvențial
Când execuți mai multe teste, implicit acestea se desfășoară în paralel folosind thread-uri, ceea ce duce la finalizarea lor mai rapidă și la obținerea rapidă a feedback-ului. Testele rulând simultan, este esențial să te asiguri că nu sunt interdependente sau că nu depind de o stare comună, incluzând medii partajate, precum directoriul de lucru curent sau variabilele de mediu.
Considerând cazul în care fiecare test execută cod care creează pe disk un fișier numit test-output.txt și îi scrie date, iar apoi verifică dacă fișierul conține o anumită valoare, diferită pentru fiecare test, simultaneitatea poate cauza probleme. Testele pot să rescrie reciproc fișierul în timp ce unul scrie și altul citește, conducând la eșecul celui de-al doilea test nu din cauza unui cod defectuos, ci din pricina interferenței între teste pe durata execuției în paralel. Soluțiile includ fiecare test să scrie într-un fișier unic sau execuția secvențială a testelor.
Pentru a evita executarea în paralel sau pentru a controla mai fin numărul de thread-uri, utilizează opțiunea --test-threads cu numărul de thread-uri dorit pentru binarul de test. Un exemplu ar fi:
$ cargo test -- --test-threads=1
Setând numărul de thread-uri de test la 1, ii transmitem programului să renunțe la paralelism. Execuția testelor pe un singur thread va lua mai mult timp decât în mod paralel, dar va preveni interferența între teste dacă acestea partajează stări comune.
Afișarea ieșirilor funcțiilor
Implicit, când un test este efectuat cu succes în Rust, orice ieșire produs de acesta este capturat și ascuns. Să spunem că un test folosește println! însă el trece; în acest caz, ieșirea lui println! nu va fi vizibil în terminal, ci doar mesajul ce indică succesul testului. Dacă un test eșuează, tot ceea ce a fost scris în ieșirea consolă standard va fi afișat împreună cu detalii despre eșecul testului.
De exemplu, Listarea 11-10 ne prezintă o funcție care afișează valoarea parametrului său și returnează numărul 10, un test care trece și un altul care eșuează.
Numele fișierului: src/lib.rs
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {}", a);
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(10, value);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(5, value);
}
}Listarea 11-10: Testele unei funcții ce utilizează println!
Când executăm aceste teste cu comanda cargo test, vom obține următorul afișaj:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at 'assertion failed: `(left == right)`
left: `5`,
right: `10`', src/lib.rs:19:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Notăm că în acest afișaj nu găsim expresia I got the value 4, ceea ce ar fi trebuit să fie afișat de testul care trece. Ieșirea acestuia a fost capturat. Pe de altă parte, afișajul testului eșuat, I got the value 8, figurează în sumarul afișajului de test, arătând și motivul eșecului.
Dacă dorim să vedem ieșirile testelor reușite, putem folosi flag-ul --show-output pentru a instrui Rust să afișeze rezultatele și pentru acele teste.
$ cargo test -- --show-output
Rulând din nou testele din Listarea 11-10 cu flag-ul --show-output, observăm următorul afișaj:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished test [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at 'assertion failed: `(left == right)`
left: `5`,
right: `10`', src/lib.rs:19:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Executarea unui subset de teste în funcție de nume
În unele cazuri, executarea întregii suite de teste poate lua timp. Dacă ești concentrat pe o secțiune anume a codului, ar putea fi util să rulezi doar testele asociate cu acea parte. Poți specifica care teste să fie executate oferind argumentul cargo test cu numele sau numele testelor dorite.
Ca exemplu pentru rularea unui subset de teste, vom defini întâi trei teste pentru funcția add_two, așa cum e ilustrat în Listarea 11-11, și vom selecta care dintre acestea să fie rulate.
Numele fișierului: src/lib.rs
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
assert_eq!(4, add_two(2));
}
#[test]
fn add_three_and_two() {
assert_eq!(5, add_two(3));
}
#[test]
fn one_hundred() {
assert_eq!(102, add_two(100));
}
}Listarea 11-11: Trei teste cu nume diferite
Dacă le executăm pe toate fără a specifica argumente, așa cum am văzut mai înainte, toate testele se vor executa simultan:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Executarea Testelor Individuale
Putem da numele oricărei funcții de test către cargo test pentru a rula exclusiv acel test:
$ cargo test one_hundred
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Numai testul cu numele one_hundred a fost executat; celelalte două teste nu au corespuns acelui nume. Afișajul ne anunță că au existat alte teste care nu au rulat prin indicativul 2 filtered out de la final.
Nu este posibil să specificăm numele mai multor teste în acest fel; doar prima valoare furnizată lui cargo test va fi utilizată. Există, însă, o metodă de a executa mai multe teste simultan.
Filtrarea testelor spre executare
Dacă specificăm o parte din numele unui test, orice test a cărui nume conține acea secvență va fi executat. Spre exemplu, având în vedere că numele a două dintre testele noastre includ add, putem executa aceste două teste folosind cargo test add:
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Această comandă a executat toate testele ce includ add în numele lor și a exclus testul denumit one_hundred. De asemenea, este important de știut că modulul în care se află un test devine parte integrantă a numelui său, deci putem executa toate testele dintr-un modul filtrând după numele acestuia.
Excluderea unor teste pînă la cerere explicită
Uneori, anumite teste pot fi extrem de consumatoare de timp atunci când sunt executate, motiv pentru care s-ar putea dori să le excluzi pe parcursul majorității rulărilor de cargo test. În loc să specifici nume după nume toate testele pe care ai de gând să le execuți, poți alege să marchezi teste consumatoare de timp cu atributul ignore pentru a le exclude, după cum urmează:
Numele fișierului: src/lib.rs
#[test]
fn it_works() {
assert_eq!(2 + 2, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// code that takes an hour to run
}În urma adnotării #[test] adăugăm #[ignore] pentru testul pe care dorim să îl omitem. Acum, când executăm testările, it_works se execută, în timp ce expensive_test nu:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test expensive_test ... ignored
test it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Funcția expensive_test este listată ca ignored. Dacă dorim să executăm exclusiv testele ignorate, putem folosi comanda cargo test -- --ignored:
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Controlând care teste sunt executate, poți asigura că rezultatele tale cargo test se obțin rapid. Când ai stabilit că este momentul oportun să verifici rezultatele testelor ignored și ai timp disponibil pentru a aștepta aceste rezultate, poți opta să rulezi cargo test -- --ignored. Dacă intenționezi să execuți toate testele, indiferent de statutul acestora,
comanda este cargo test -- --include-ignored.
Organizarea testării
Așa cum am menționat la începutul acestui capitol, testarea reprezintă o disciplină sofisticată, iar diferite persoane aplică o varietate de terminologii și abordări organizatorice. În comunitatea Rust, testele sunt privite prin prisma a două categorii principale: testele unitare și testele de integrare. Testele unitare sunt precise și se concentrează pe testarea unui modul în izolare într-un moment dat, cu posibilitatea de a verifica interfețele private. Testele de integrare, în contrast, sunt complet externe în raport cu biblioteca ta și utilizează codul exact cum ar face-o orice alt consumator extern, limitându-se la interfața publică și explorând, adeseori, multiple module într-un singur test.
Elaborarea ambelor categorii de teste este crucială pentru a confirma că componentele individuale ale bibliotecii tale funcționează conform așteptărilor, atât izolat, cât și în combinație.
Testele de unitate
Testele de unitate au ca scop verificarea fiecărei unități de cod în izolare de restul programului, pentru a determina rapid ce porțiuni funcționează sau nu conform așteptărilor. Aceste teste sunt amplasate în directoriul src, în același fișier cu codul pe care îl testează. Este o convenție uzuală să se creeze un modul cu numele tests în fiecare fișier, ce conține funcțiile de test, și să se adnoteze acest modul cu cfg(test).
Modulul de teste și adnotația #[cfg(test)]
Adnotarea #[cfg(test)] aplicată pe modulul de teste instruiește Rust să compileze și să ruleze codul de test atunci când folosim cargo test, și nu în timpul executării cargo build. Această abordare economisește timp la compilare când intenționăm să construim doar biblioteca și reduce dimensiunea artifactului compilat rezultat, prin omisiunea testelor. Observăm că, deoarece testele de integrare sunt stocate într-un directoriu distinct, acestea nu au nevoie de adnotația #[cfg(test)]. Contrar, testele unitare, fiind localizate în aceleași fișiere ca și codul, necesită utilizarea #[cfg(test)] pentru a indica faptul că nu trebuie incluse în versiunea compilată finală.
Reamintim că atunci când am generat proiectul nou adder în prima parte a acestui capitol, Cargo a creat automat următorul cod pentru noi:
Numele fișierului: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
let result = 2 + 2;
assert_eq!(result, 4);
}
}Codul afișat constituie modulul de teste produs automat. Atributul cfg reprezintă o scurtătură la configuration și indică lui Rust că elementul care urmează să fie definit ar trebui inclus doar într-o configurație specifică. În acest caz, configurația este test, pusă la dispoziție de Rust pentru a compila și executa teste. Aplicând atributul cfg, Cargo va compila codul de test doar dacă demarăm explicit testele folosind comanda cargo test. Acest lucru include și orice funcții auxiliare care ar putea exista în acest modul, alături de funcțiile adnotate cu #[test].
Testarea funcțiilor private
În comunitatea de testare există un debate privind oportunitatea testării directe a funcțiilor private. Alte limbaje de programare fac dificilă sau chiar imposibilă testarea funcțiilor private. Independent de ideologia de testare pe care o urmezi, regulile de confidențialitate din Rust îți permit să testezi funcțiile private. Să analizăm codul din Listarea 11-12, care include funcția privată internal_adder.
Numele fișierului: src/lib.rs
pub fn add_two(a: i32) -> i32 {
internal_adder(a, 2)
}
fn internal_adder(a: i32, b: i32) -> i32 {
a + b
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
assert_eq!(4, internal_adder(2, 2));
}
}Listarea 11-12: Testarea unei funcții private
Observă că funcția internal_adder nu este etichetată ca pub. Testele sunt pur și simplu cod Rust, iar modulul tests este doar un alt modul. Așa cum am discutat în secțiunea „Utilizarea căilor pentru a face referire la un element în structura de module”, elementele din modulele copil au acces la elementele din modulele strămoșilor lor. În acest test, includem toate elementele modulului părinte al test în domeniul de aplicare cu use super::*, permițând testului să apeleze internal_adder. Dacă ești de părere că funcțiile private nu ar trebui testate, Rust nu te va forța să faci acest lucru.
Testele de integrare
În Rust, testele de integrare sunt complet externe în raport cu biblioteca ta. Acestea utilizează biblioteca în exact aceeași manieră cum ar face orice alt segment de cod, ceea ce înseamnă că ele pot apela doar funcții care fac parte din interfața API publică a bibliotecii tale. Scopul lor este să verifice dacă diverse componente ale bibliotecii tale lucrează corect împreună. Unități de cod care funcționează corect izolat pot prezenta probleme atunci când sunt combinate, deci este important să se asigure o acoperire prin teste și pentru codul integrat. Pentru realizarea testelor de integrare, este necesar să creezi mai întâi un directoriu numit tests.
Directoriul tests
În structura de top a directoriului nostru de proiect, alături de src, creăm un directoriu tests. Cargo cunoaște locația acestui directoriu și va căuta aici fișierele cu testele de integrare. Aici putem adăuga oricâte fișiere de teste dorim, și Cargo le va compila individual ca pe niște crate-uri separate.
Pentru a crea un test de integrare, având codul din Listarea 11-12 în fișierul src/lib.rs, deschidem directoriul tests și creăm un fișier cu numele tests/integration_test.rs. Iată cum ar arăta structura directoriului:
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
Scriem codul din Listarea 11-13 în fișierul tests/integration_test.rs:
Numele fișierului: tests/integration_test.rs
use adder;
#[test]
fn it_adds_two() {
assert_eq!(4, adder::add_two(2));
}Listarea 11-13: Test de integrare pentru o funcție din crate-ul adder
Dat fiind că fiecare fișier din tests este tratat ca un crate separat, este necesar să includem în domeniul de vizibilitate al fiecărui test crate biblioteca pe care o testăm. Astfel, adăugăm use adder la începutul codului; aspect pe care nu l-am avut în testele unitare.
Nu este necesar să adnotăm codul din tests/integration_test.rs cu #[cfg(test)]. Cargo consideră tests un directoriu special și compilează fișierele conținute doar când executăm cargo test. Să executăm cargo test acum:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Afișajul conține trei secțiuni: testele unitare, testul de integrare și testele de documentație. Este important de reținut că dacă un test dintr-o anumită secțiune eșuează, secțiunile următoare nu vor fi executate. De exemplu, dacă un test unitar nu trece, nu vom vedea niciun output pentru testele de integrare și pentru cele de documentație, deoarece vor fi executate doar dacă testele unitare au trecut cu succes.
Prima secțiune, cea a testelor unitare, ne prezintă ceea ce am văzut și înainte: o linie pentru fiecare test unitar (inclusiv internal adăugat în Listarea 11-12) și o linie de sumar pentru toate testele unitare.
Secțiunea pentru testele de integrare debutează cu Running tests/integration_test.rs, urmată de o linie pentru fiecare funcție de test din testul de integrare, încheind cu o linie de sumar a rezultatelor testului de integrare înainte de începerea secțiunii Doc-tests adder.
Dacă adăugăm mai multe fișiere de test în directoriul tests, fiecare dintre acestea va avea propria sa secțiune de test de integrare.
Putem rula o anume funcție de test de integrare direct specificând numele funcției ca argument la cargo test. Pentru a rula toate testele dintr-un fișier specific de test de integrare, folosim argumentul --test cu numele fișierului după cargo test:
$ cargo test --test integration_test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Această comandă execută exclusiv testele din tests/integration_test.rs.
Submodule în teste de integrare
Când adaugi tot mai multe teste de integrare, e posibil să dorești noi fișiere în directoriul tests pentru a le organiza mai bine; de exemplu, pOți grupa funcțiile de test după funcționalitățile pe care le verifică. După cum am menționat anterior, fiecare fișier din directoriul tests este compilat ca un crate separat, aspect util pentru crearea de domenii de vizibilitate separate care să imite cât mai fidel modul în care utilizatorii finali vor folosi crate-ul tău. Însă, acest lucru înseamnă că fișierele din directoriul tests nu se comportă la fel ca cele din src, așa cum am învățat în Capitolul 7 cu privire la separarea codului în module și fișiere.
Diferența de comportament a fișierelor din directoriul tests devine evidentă atunci când avem un set de funcții ajutătoare pe care dorim să le utilizăm în diverse fișiere de teste de integrare și încercăm să urmăm pașii din secțiunea „Separarea modulelor în fișiere diferite” din Capitolul 7 pentru a le extrage într-un modul comun. De exemplu, dacă creăm tests/common.rs și adăugăm în el o funcție denumită setup, putem include în setup codul pe care dorim să-l apelăm din diverse funcții de testare în multiple fișiere de test:
Numele fișierului: tests/common.rs
pub fn setup() {
// setup code specific to your library's tests would go here
}La rularea testelor din nou, vom observa în afișajul testelor o nouă secțiune pentru fișierul common.rs, cu toate că acest fișier nu conține nicio funcție de test și nici n-am invocat funcția setup de undeva:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Prezența common în rezultatele de test cu mențiunea running 0 tests nu este ceea ce intenționam. Intenția noastră era pur și simplu să partajăm codul cu alte fișiere de test de integrare.
Pentru a preveni apariția secțiunii common în rezultatele de test, în loc de tests/common.rs, vom crea tests/common/mod.rs. Structura directorului proiectului va arăta acum astfel:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
Aceasta reprezintă convenția de denumire mai veche, pe care Rust o recunoaște și care a fost menționată în secțiunea „Căi alternative pentru Fișiere” din Capitolul 7. A alege acest nume de fișier îi indică lui Rust să nu considere modulul common ca fiind un fișier de teste de integrare. Când mutăm codul funcției setup în tests/common/mod.rs și ștergem fișierul tests/common.rs, secțiunea respectivă nu va mai apărea în afișajul testelor. Fișierele din subdirectoarele directoriului tests nu sunt compilate în crate-uri separate și nu au secțiuni în afișajul testelor.
După ce am creat fișierul tests/common/mod.rs, putem să-l utilizăm ca modul din orice fișier de teste de integrare. Iată cum apelăm funcția setup din testul it_adds_two din tests/integration_test.rs:
Numele fișierului: tests/integration_test.rs
use adder;
mod common;
#[test]
fn it_adds_two() {
common::setup();
assert_eq!(4, adder::add_two(2));
}Remarcăm că declarația mod common; este identică cu declarația de modul pe care am prezentat-o în Listarea 7-21. Acum în cadrul funcției de test, putem apela funcția common::setup().
Teste de integrare pentru crate-uri binare
Dacă proiectul nostru este un crate binar conținând numai un fișier src/main.rs și fără un fișier src/lib.rs, nu putem crea teste de integrare în directoriul tests și nici să aducem funcțiile definite în src/main.rs în domeniu de vizibilitate folosind o instrucțiune use. Doar crate-urile de tip bibliotecă expun funcții care pot fi folosite de alte crate-uri; crate-urile binare sunt create pentru a fi executate independent.
Acesta este unul din raționamentele pentru care proiectele Rust ce oferă un binar au un fișier src/main.rs concis, ce apelează logica implementată în fișierul src/lib.rs. Având această structură, teste de integrare pot să testeze crate-ul bibliotecă utilizând use pentru a accesa funcționalitățile esențiale. Dacă aceste funcționalități esențiale funcționează corect, atunci și cantitatea mică de cod din src/main.rs va opera corect, iar acest segment redus de cod nu necesită testare.
Sumar
Facilitățile de testare oferite de Rust ne permit să specificăm modul în care codul ar trebui să opereze pentru a garanta că acesta continuă să funcționeze conform așteptărilor, chiar și atunci când sunt aplicate modificări. Testele unitare verifică separat părți diferite ale unei biblioteci și pot testa detalii ale implementării private. Testele de integrare asigură că diferite componente ale bibliotecii lucrează corect împreună, utilizând API-ul public al acesteia pentru a verifica codul în același mod în care va fi folosit și de codul extern. Deși sistemul de tipizare și regulile de posesiune din Rust previn anumite categorii de defecțiuni, testele rămân esențiale pentru a diminua erorile de logică legate de comportamentul așteptat al codului.
În continuare să folosim cunoștințele acumulate în acest capitol și în cele anterioare pentru a dezvolta un proiect!
Un proiect de I/O: Construirea unei aplicații de linie de comandă
În acest capitol vom recapitula diversele abilități învățate până acum și vom explora noi funcționalități ale bibliotecii standard. Construim o aplicație de linie de comandă pentru a interacționa cu fișiere și intrarea/ieșirea de linie de comandă, astfel exersăm conceptele Rust cu care sunteți deja familiarizați.
Datorită vitezei, siguranței, output-ului binar unic și suportului multi-platformă, Rust este un limbaj excelent pentru crearea de aplicații de linie de comandă. În proiectul nostru vom realiza o versiune proprie a utilitarului clasic de căutare în linia de comandă grep (căutare globală pentru o regulară expresie și printare). În cel mai elementar scenariu, grep scanează un string specific în cadrul unui fișier dat. Astfel, grep utilizează ca argumente o cale de fișier și un string, citește fișierul, identifică liniile care includ string-ul specificat și le afișează.
De-a lungul capitolului, vom detalia modul în care aplicația noastră de linie de comandă poate folosi caracteristicile terminalului comune altor astfel de aplicații. Vom citi valoarea unei variabile de mediu pentru a permite utilizatorului să modifice comportamentul instrumentului nostru. Mai mult, vom afișa mesajele de eroare în fluxul consolei standard de eroare (stderr) decât în cel de ieșire standard (stdout), permițând astfel utilizatorului să redirecționeze ieșirile reușite către un fișier, dar să păstreze mesajele de eroare vizibile pe ecran.
Un membru al comunității Rust, Andrew Gallant, a creat o versiune avansată și rapidă de grep, cunoscută sub numele de ripgrep. Versiunea noastră va fi simplificată, dar capitolul va oferi informațiile de bază necesare pentru a înțelege un proiect concret precum ripgrep.
Proiectul grep va sintetiza numeroase concepte stăpânite până în momentul de față:
- Organizarea codului (așa cum am văzut în Capitolul 7)
- Folosirea vectorilor și string-urilor (discutat în Capitolul 8)
- Gestionarea erorilor (abordată în Capitolul 9)
- Implementarea trăsăturilor și gestionarea duratelor de viață (prezentate în Capitolul 10)
- Crearea de teste (explicate în Capitolul 11)
Vom face, de asemenea, o trecere rapidă prin conceptul de închideri, iteratori și obiecte-trăsătură, pe care le vom aprofunda în Capitolele 13 și 17.
Acceptarea argumentelor liniei de comandă
Să creăm un nou proiect folosind, ca întotdeauna, cargo new. Vom numi proiectul nostru minigrep pentru a-l diferenția de instrumentul grep pe care s-ar putea să îl ai deja pe sistemul tău.
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
Prima sarcină este să configurăm minigrep să accepte cei doi parametri de linie de comandă: calea fișierului și un string pentru căutare. Astfel, dorim să putem executa programul nostru cu cargo run, urmat de două liniuțe pentru a indica faptul că argumentele ulterioare sunt destinate programului nostru și nu pentru cargo, un string de căutat, și o cale către un fișier în care să efectuăm căutarea, ca în exemplul următor:
$ cargo run -- searchstring example-filename.txt
Deocamdată, programul generat de cargo new nu este capabil să proceseze argumentele pe care i le transmitem. Există biblioteci disponibile pe crates.io care ne-ar putea facilita scrierea unui program capabil să accepte argumente din linia de comandă, dar deoarece suntem în proces de învățare a acestui concept, să încercăm să implementăm această funcționalitate pe cont propriu.
Citirea valorilor argumentelor
Pentru ca minigrep să poată citi valorile argumentelor de pe linia de comandă, e necesar să folosim funcția std::env::args din biblioteca standard a Rust. Aceasta returnează un iterator cu argumentele de linia de comandă primite de minigrep. Detalii complete despre iteratori vor fi disponibile în Capitolul 13. În prezent, trebuie să reținem două aspecte despre iteratori: aceștia generează o serie de valori și putem folosi metoda collect pentru a transforma iteratorul într-o colecție, cum ar fi un array, care include toate elementele produse de acesta.
Codul din Listarea 12-1 îi va permite programului minigrep să citească argumentele de pe linia de comandă care îi sunt transmise și să le transfere într-un array.
Numele fișierului: src/main.rs
use std::env; fn main() { let args: Vec<String> = env::args().collect(); dbg!(args); }
Listarea 12-1: Colectarea argumentelor transmise pe linia de comandă într-un array și afișarea acestora
Înainte de toate, importăm modulul std::env în contextul nostru cu ajutorul unei instrucțiuni use, pentru ca să putem utiliza funcția args din acesta. Se remarcă faptul că funcția std::env::args se află în cadrul a două module. Așa cum s-a discutat în Capitolul 7, atunci când funcția dorită este situată în mai multe module, optăm să importăm modulul părinte în locul unei funcții anume. Prin această abordare, putem accesa alte funcții din std::env cu mai multă ușurință. De asemenea, evităm ambiguitatea care ar apărea prin adăugarea use std::env::args și apoi apelarea funcției simplu cu args, ceea ce ar putea fi confundat cu o funcție definită local.
Funcția
argsși Unicode invalidEste important de reținut că
std::env::argsva genera panică dacă orice argument conține Unicode invalid. Dacă este necesar ca programul tău să accepte argumente care includ Unicode invalid, atunci ar trebui utilizată funcțiastd::env::args_os. Această funcție oferă un iterator ce generează valori de tipOsStringîn loc deString. Am optat pentru utilizarea luistd::env::argsaici datorită simplității, deoarece valorile de tipOsStringvariază în funcție de platformă și sunt mai complicate de manevrat decât valorile de tipString.
La prima linie a funcției main, invocăm env::args, apoi utilizăm imediat collect pentru a converti iteratorul într-un vector care conține toate valorile generate de iterator. Putem apela funcția collect pentru a crea diferite tipuri de colecții, motiv pentru care specificăm în mod explicit tipul pentru args, indicând că dorim un vector de string-uri. Chiar dacă în Rust rar este necesar să adnotăm tipurile, când vine vorba de collect, adesea este nevoie de acest lucru deoarece aici Rust nu îți poate infera tipul de colecție dorit.
În final, afișăm vectorul folosind macro-ul de debug. Să încercăm să executăm codul mai întâi fără argumente, apoi cu două argumente:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
Observăm că prima valoare din vector este "target/debug/minigrep", numele executabilului nostru. Aceasta este în acord cu comportamentul listei de argumente din C, care permite programelor să utilizeze numele sub care au fost invocate în cursul execuției. Oferirea accesului la numele programului poate fi utilă dacă dorim să îl afișăm în mesaje sau să modificăm comportamentul programului în funcție de aliasul de la linia de comandă folosit pentru invocare. Totuși, pentru nevoile acestui capitol, vom ignora acest aspect și vom salva doar cele două argumente necesare.
Salvând valorile argumentelor în variabile
Programul nostru este acum capabil să acceseze valorile specificate ca argumente ale liniei de comandă. Trebuie să salvăm acum valorile celor doi argumente în variabile, pentru a putea utiliza aceste valori pe parcursul restului programului. Această etapă este realizată în Listarea 12-2.
Numele fișierului: src/main.rs
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {}", query);
println!("In file {}", file_path);
}Listarea 12-2: Creăm variabile pentru memorarea argumentului de căutare și argumentului cu calea fișierului
Așa cum am observat când am afișat vectorul, numele programului este stocat în prima valoare a vectorului la args[0], deci ne apucăm să lucram cu argumentele începând de la indexul 1. Primul argument pe care minigrep îl solicită este string-ul pe care dorim să îl căutăm, așa că atribuim o referință către primul argument variabilei query. Pentru al doilea argument, care reprezintă calea fișierului, atribuim o referință către al doilea argument variabilei file_path.
Printăm temporar valorile acestor variabile pentru a ne asigura că programul funcționează conform intențiilor noastre. Să executăm acest program din nou, de data aceasta cu argumentele test și sample.txt:
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
Minunat, programul funcționează corect! Valorile argumentelor necesare sunt acum salvate în variabilele potrivite. Ulterior, vom adăuga gestionarea erorilor pentru a face față situațiilor eronate, cum ar fi cazul în care utilizatorul nu furnizează niciun argument; deocamdată, vom trece peste astfel de situații și ne vom concentra asupra implementării funcționalității de citire a fișierelor.
Citirea fișierului
Acum vom adăuga funcționalitatea de citire a fișierului specificat în argumentul file_path. Mai întâi, avem nevoie de un exemplu de fișier pentru a testa: vom folosi un fișier cu o mică cantitate de text distribuit pe mai multe linii și cu anumite cuvinte repetate. Listarea 12-3 ne prezintă o poezie de Emily Dickinson care este foarte potrivită! Creează un fișier cu numele poem.txt la nivelul rădăcină al proiectului tău și include poezia “I’m Nobody! Who are you?”
Numele fișierului: poem.txt
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Listarea 12-3: O poezie de Emily Dickinson, un excelent caz de test
Cu textul prezent, editează src/main.rs și adaugă codul pentru citirea fișierului, după cum e prezentat în Listarea 12-4.
Numele fișierului: src/main.rs
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {}", query);
println!("In file {}", file_path);
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}Listarea 12-4: Citirea conținutului fișierului specificat de al doilea argument
Inițial, introducem o parte relevantă din biblioteca standard cu instrucțiunea use: ne este necesar std::fs pentru gestionarea fișierelor.
În main, noua expresie fs::read_to_string utilizează file_path, deschide fișierul respectiv și returnează un std::io::Result<String> cu conținutul fișierului.
Ulterior, adăugăm încă o instrucțiune println! temporară pentru a afișa valoarea variabilei contents după ce fișierul a fost citit, pentru a verifica funcționalitatea codului până în acest moment.
Execută acest cod folosind orice șir de caractere ca prim argument al liniei de comandă (pentru că încă nu am implementat partea de căutare) și fișierul poem.txt ca al doilea argument:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Excelent! Codul a accesat și a afișat conținutul fișierului. Totuși, codul prezintă câteva slăbiciuni. În prezent, funcția main are responsabilități multiple: în general, funcțiile sunt mai clare și mai simplu de întreținut dacă fiecare este responsabilă doar pentru un singur concept. O altă problemă este gestionarea ineficientă a erorilor. Programul este mic acum, așa că aceste deficiențe nu reprezintă o problemă majoră, dar pe măsură ce programul se mărește, acestea vor fi mai dificil de rezolvat într-un mod clar. Începerea timpurie a refactoring-ului (reorganizarea codului) în timpul dezvoltării unui program este o practică bună, deoarece refacerea codului este mult mai simplă când porțiunile sunt mai mici. Asta și vom face în continuare.
Refactorizarea pentru îmbunătățirea modularității și gestionarea erorilor
Pentru a îmbunătăți programul nostru, ne vom axa pe rezolvarea a patru probleme care sunt legate de structura programului și de modul cum gestionează acesta erorile potențiale. În primul rând, funcția noastră main îndeplinește în prezent două sarcini: parsează argumentele și citește fișiere. Odată cu creșterea programului nostru, numărul de sarcini gestionate de funcția main de asemenea va crește. Pe măsură ce o funcție acumulează mai multe responsabilități, devine tot mai dificil de analizat, mai complicat de testat și mai greoi de modificat fără a afecta una dintre funcționalitățile sale. Este preferabil să separăm funcționalitățile astfel încât fiecare funcție să fie responsabilă doar de o anumită sarcină.
Al doilea aspect ce necesită atenție este faptul că, deși query și file_path sunt variabile de configurare pentru program, avem și variabile cum ar fi contents ce sunt folosite pentru implementarea logicii programului. Cu cât blocul main se extinde, cu atât va fi necesar să aducem în scop mai multe variabile; iar odată cu creșterea numărului de variabile în domeniul de vizibilitate, devine tot mai complicat să urmărim funcția fiecăreia. Ar fi mai adecvat să consolidăm variabilele de configurare într-o singură structură pentru astfel a clarifica rolul lor.
A treia problemă constă în utilizarea instrucțiunii expect pentru generarea unui mesaj de eroare când citirea fișierului eșuează, care acum se rezumă doar la Should have been able to read the file. Eșecul citirii unui fișier poate surveni din diverse motive - cum ar fi absența fișierului sau lipsa permisiunii de acces. Momentan, am afișa același mesaj indiferent de situație, fără a furniza ceva informativ utilizatorului.
A patra problemă este legată de utilizarea repetată a lui expect în tratamentul diferitelor erori și faptul că, dacă un utilizator execută programul fără a oferi suficiente argumente, se va întâlni cu o eroare de tip index out of bounds din partea Rust, o eroare care nu descrie clar problema. Ideal ar fi ca întreg codul de gestionare a erorilor să fie centralizat, astfel încât viitorii dezvoltatori să aibă un singur punct de referință la care să se raporteze dacă logica de gestionare a erorilor necesită ajustări. Concentrând codul destinat erorilor într-un loc unic ne garantăm că mesajele generate sunt pertinente și utile pentru utilizatorii finali.
Să ne ocupăm de aceste patru probleme printr-o atentă refactorizare a proiectului.
Separarea responsabilităților în proiectele binare
Problema organizațională de atribuire a responsabilităților pentru diverse sarcini funcției main este frecventă în multe proiecte binare. Drept consecință, comunitatea Rust a elaborat ghiduri pentru descompunerea preocupărilor separate ale unui program binar când funcția main începe să crească prea mult în dimensiune. Procesul cuprinde următorii pași:
- Împarte programul într-un main.rs și un lib.rs și transferă logica programului în lib.rs.
- Dacă logica de procesare a liniei de comandă este simplă, aceasta poate să rămână în main.rs.
- Când logica de procesare a liniei de comandă devine complexă, extrage-o din main.rs și mut-o în lib.rs.
Responsabilitățile ce ar trebui să rămână în funcția main în urma acestui proces se limitează la:
- Apelarea logicii de procesare a liniei de comandă cu valorile argumentelor
- Configurarea oricăror setări suplimentare
- Invocarea unei funcții
rundin lib.rs - Tratarea erorii dacă
runreturnează o eroare
Această metodologie se axează pe separarea responsabilităților: main.rs se ocupă de execuția programului, iar lib.rs gestionează integral logica specifică sarcinii. Deoarece funcția main nu poate fi testată în mod direct, această structură îți oferă posibilitatea să testezi toată logica programului prin includerea ei în funcții din lib.rs. Codul rezidual din main.rs va fi atât de concis încât corectitudinea lui se poate constata prin simpla lectură. Să procedăm la reconfigurarea programului nostru aplicând acești pași.
Extragerea parserului de argumente
Vom separa funcționalitatea de parsare a argumentelor într-o funcție pe care main o va chema, pregătind astfel mutarea logicii de parsare a argumentelor din linia de comandă în src/lib.rs. Listarea 12-5 ilustrează noul început al funcției main, unde aceasta apelează o nouă funcție parse_config, definită momentan în src/main.rs.
Numele fișierului: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, file_path) = parse_config(&args);
// --snip--
println!("Searching for {}", query);
println!("In file {}", file_path);
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let file_path = &args[2];
(query, file_path)
}Listarea 12-5: Extragerea unei funcții parse_config din main
Continuăm să adunăm argumentele liniei de comandă într-un vector, dar în loc de a atribui direct valoarea argumentului de la indexul 1 variabilei query și valoarea argumentului de la indexul 2 variabilei file_path în funcția main, acum transmitem întreg vectorul către funcția parse_config. Funcția parse_config are acum rolul de a determina care argument corespunde căreia dintre variabile și trimite valorile înapoi în main. În main continuăm să creăm variabilele query și file_path, însă main nu mai are rolul de a face corelația dintre argumentele de comandă și variabile.
Această restructurare ar putea să pară inutilă pentru un program de dimensiuni atît de reduse ca al nostru, însă anume așa și refactorizăm: în pași mici și consecutivi. După ce efectezi această modificare, rulează iar programul pentru a te asigura că procesul de parsare a argumentelor funcționează în continuare. E recomandat să verifici progresul frecvent, pentru a putea identifica mai ușor sursa problemelor atunci când apar.
Gruparea valorilor de configurare
Putem face încă un mic pas pentru a îmbunătăți funcția parse_config.
În prezent, returnăm o tuplă, dar apoi o descompunem imediat în componentele ei individuale. Acest lucru poate semnala faptul că nu am ajuns încă la abstracția corectă.
Alt semnal care indică posibilitatea îmbunătățirii este partea config din parse_config, ce sugerează că cele două valori returnate sunt interconectate și constituie împreună o configurație unitară. În momentul de față, nu comunicăm acest sens în structura datelor, decât prin gruparea valorilor într-o tuplă; în loc de aceasta, vom încorpora cele două valori într-o structură și le vom atribui câmpurilor nume sugestive. Aceasta va simplifica munca viitorilor dezvoltatori care vor interacționa cu codul, facilitând înțelegerea interdependenței valorilor și scopurilor pe care le servesc.
Listarea 12-6 prezintă îmbunătățirile aduse funcției parse_config.
Numele fișierului: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
// --snip--
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
fn parse_config(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}Listarea 12-6: Refactorizarea funcției parse_config pentru returnarea unei instanțe a structurii Config
Am introdus o structură denumită Config, concepută cu câmpurile query și file_path. Semnătura funcției parse_config reflectă acum faptul că se returnează o valoare de tip Config. În conținutul parse_config, acolo unde înainte returnam secțiuni care făceau referire la valori de tip String din args, configurăm acum Config astfel încât să conțină în directă posesiune valorile sale String. Variabila args din funcția main este proprietara valorilor argumente și permite funcției parse_config doar să le împrumute, iar dacă Config ar încerca să preia controlul asupra acestor valori atunci situația ar contraveni regulilor Rust privind împrumutul.
Există multiple metode prin care am putea controla datele de tip String; cea mai simplă, deși posibil ineficientă, este să apelăm metoda clone pe respectivele valori. Acest lucru ar genera o copie integrală a datelor, pe care instanța Config le-ar deține, consumând mai mult timp și memorie decât dacă am stoca o referință la datele string. Totuși, clonarea datelor are avantajul de a ne simplifica codul, nefiind necesar să gestionăm duratele de viață ale referințelor. În această situație, renunțarea la o cantitate mică de performanță în schimbul simplificării este un compromis justificat.
Dezavantajele utilizării funcției
cloneMulți dintre cei care programează în Rust au tendința de a evita utilizarea funcției
clonepentru a soluționa problemele de posesiune, din cauza impactului pe care îl are asupra timpului de execuție. În Capitolul 13, vei învăța metode mai eficiente pentru aceste tipuri de situații. Totuși, în acest moment, nu este o problemă să copiezi câteva string-uri pentru a avansa în progresul tău, deoarece aceste copieri se vor face doar o singură dată și atât string-ul de interogare, cât și calea directoriului tău sunt destul de reduse ca dimensiune. Este preferabil să ai un program funcțional care nu este optimizat la maximum decât să încerci să optimizezi excesiv codul din prima încercare. Pe măsură ce vei deveni mai versat în Rust, va fi mai simplu să pornești direct cu soluția cea mai eficientă, dar pentru moment, este complet acceptabil să apelezi laclone.
Am modificat funcția main astfel încât să atribuie instanța de Config întoarsă de parse_config unei variabile denumite config, și am actualizat codul care anterior utiliza variabilele query și file_path separat, astfel încât acum să acceseze câmpurile structurii Config.
În acest fel, codul nostru comunică mai eficient faptul că query și file_path sunt corelate și că funcția lor este de a seta configurarea pentru comportamentul programului. Orice porțiune de cod care le folosește va ști că trebuie să le caute în instanța config, în câmpurile cu numele corespunzător scopului lor.
Crearea unui constructor pentru Config
Până acum, am separat logica de parsare a argumentelor liniei de comandă din main și am inclus-o în funcția parse_config. Acest demers ne-a ajutat să observăm că valorile pentru query și file_path sunt interconectate și această conexiune trebuie evidențiată în codul nostru. În consecință, am introdus structura Config pentru a numi scopul conex al query și file_path și pentru a putea returna numele acestor valori sub forma unor nume de câmpuri ale structurii din cadrul funcției parse_config.
Așadar, fiindcă rolul funcției parse_config este de a inițializa o instanță Config, putem transforma parse_config dintr-o funcție obișnuită într-o funcție numită new, asociată acum structurii Config. Prin această modificare, codul nostru va deveni mai idiomatic. Putem crea instanțe ale tipurilor din biblioteca standard, cum ar fi String, invocând String::new. În mod similar, prin schimbarea funcției parse_config în new, asociată cu Config, vom putea crea instanțe de Config invocând Config::new. Listarea 12-7 ilustrează schimbările pe care trebuie să le efectuăm.
Numele fișierului: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
// --snip--
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}Listarea 12-7: Transformarea parse_config în Config::new
Am actualizat locul din main unde parse_config era apelată, pentru a folosi în schimb Config::new. Am redenumit parse_config în new și am transferat-o într-un bloc impl, asociind astfel funcția new cu structura Config. Încearcă să compilezi din nou codul pentru a te asigura că funcționează cum trebuie.
Remediind problemele de tratare a erorilor
Acum ne vom concentra pe îmbunătățirea gestionării erorilor. Reamintim că încercarea de a accesa valorile din vectorul args la indexul 1 sau 2 poate provoca panică în program dacă vectorul are mai puțin de trei elemente. Încercând rularea programului fără niciun argument; ieșirea va arăta în felul următor:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at 'index out of bounds: the len is 1 but the index is 1', src/main.rs:27:21
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Îmbunătățind mesajul de eroare
În Listarea 12-8, includem o verificare în funcția new ce se asigură că secțiunea este destul de lungă înainte de a accesa indecșii 1 și 2. Dacă secțiunea nu este suficientă, programul va intra în panică și va afișa un mesaj de eroare îmbunătățit.
Numele fișierului: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("not enough arguments");
}
// --snip--
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}Listarea 12-8: Adăugând o verificare pentru numărul de argumente
Acest cod este similar cu funcția Guess::new pe care am creat-o în Listarea 9-13]ch9-custom-types, unde am folosit macro-ul panic! când valoarea value era în afara limitei valorilor valide. Aici, în loc de verificarea unui interval de valori, ne asigurăm că lungimea args este cel puțin 3, iar restul funcției poate opera sub presupunerea că această condiție este îndeplinită. Dacă args are mai puțin de trei elemente, această condiție este verificată și se apelează macro-ul panic! pentru a opri imediat programul.
Cu aceste câteva linii de cod suplimentare în new, să consultăm din nou rularea programului fără argumente pentru a vedea cum arată eroarea acum:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at 'not enough arguments', src/main.rs:26:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Rezultatul este mai bun: în sfîrșit avem un mesaj de eroare adecvat. Totuși, rămânem cu informații suplimentare care nu sunt necesare utilizatorilor noștri. Se pare că metoda utilizată în Listarea 9-13 nu este cea mai potrivită aici: un apel la panic! e mai adecvat pentru o problemă de programare decât una de utilizare, așa cum am discutat în Capitolul 9. În schimb, vom aplica o altă metodă pe care ai învățat-o în Capitolul 9—returnarea unui Result care indică fie succesul, fie o eroare.
Returnarea unui Result în loc de apelarea panic!
Putem opta pentru returnarea unei valori Result care va include o instanță Config în cazul unui succes și va detalia problema în situația unei erori. Intenționăm să schimbăm numele funcției din new în build, deoarece mulți programatori presupun că funcțiile new nu ar trebui să eșueze niciodată. În comunicarea dintre Config::build și main, folosim tipul Result pentru a semnala potențiala apariție a unei probleme. Astfel, putem ajusta funcția main să convertească o variantă Err într-o eroare mai prietenoasă pentru utilizatorii noștri, fără textul suplimentar legat de thread 'main' și RUST_BACKTRACE care însoțește apelul la panic!.
Listarea 12-9 prezintă modificările necesare valorii de retur a funcției denumite acum Config::build și ale corpului acesteia necesare pentru a returna un Result. Notăm că aceste schimbări nu vor compila decât după ce actualizăm și funcția main, lucru pe care îl vom face în lista următoare.
Numele fișierului: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Listarea 12-9: Returnarea unui Result din Config::build
Funcția build returnează un Result care conține o instanță Config în caz de succes și un &'static str în caz de eroare, valorile de eroare fiind întotdeauna literali de string cu durata de viață 'static.
Am efectuat două schimbări în corpul funcției: în loc să folosim panic! când utilizatorul nu furnizează suficiente argumente, acum returnăm o valoare Err și am ambalat valoarea de retur Config într-un Ok. Aceste ajustări asigură conformitatea funcției cu noua sa semnătură de tip.
Returnând o valoare Err în cadrul Config::build, funcția main poate gestiona valoarea Result returnată din build și poate încheia procesul într-o manieră mai curată în situația unei erori.
Apelarea Config::build și gestionarea erorilor
Pentru a gestiona cazul de eroare și a afișa un mesaj prietenos pentru utilizatori, trebuie să actualizăm funcția main pentru a prelucra Result returnat de Config::build, așa cum e demonstrat în Listarea 12-10. De asemenea, ne asumăm responsabilitatea de a încheia execuția instrumentului de linie de comandă cu un cod de eroare non-zero, rol care anterior îl avea panic!, și implementăm această funcție manual. Un cod de ieșire non-zero este o convenție care semnalează procesului ce a invocat programul nostru că acesta s-a terminat cu o stare de eroare.
Numele fișierului: src/main.rs
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Listarea 12-10: Terminarea execuției cu un cod de eroare dacă inițializarea unui Config nu reușește
În această listare am folosit metoda unwrap_or_else, care nu a fost încă detaliată: unwrap_or_else este definită pentru Result<T, E> de către biblioteca standard. Prin utilizarea unwrap_or_else, definim un comportament personalizat pentru gestionarea erorilor, care nu recurge la panic!. Dacă Result este o valoare Ok, metoda funcționează similar cu unwrap, returnând valoarea din interiorul Ok. În schimb, dacă avem o valoare de tip Err, metoda invocă codul specificat într-o închidere (closure), adică o funcție anonimă definită de noi și pasată ca argument la unwrap_or_else. Vom aborda închiderile în detaliu în Capitolul 13. Deocamdată, este suficient să înțelegeți că unwrap_or_else va trimite valoarea internă a erorii Err, în acest caz șirul static "not enough arguments", către închiderea noastră prin intermediul argumentului err, care este plasat între barele verticale. Astfel, închiderea poate folosi variabila err atunci când se execută.
Am adăugat un nou rând use pentru a include process din biblioteca standard în domeniul de vizibilitate. Codul din închidere care va fi executat în caz de eroare conține doar două linii: afișăm valoarea err și invocăm process::exit. Funcția process::exit oprește programul imediat și returnează numărul care a fost specificat ca cod de ieșire. Acesta este un comportament similar cu cel din gestionarea bazată pe panic! prezentată în Listarea 12-8, însă de data aceasta fără output-ul adițional. Acum să testăm:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
Excelent! Acest mesaj este mult mai accesibil utilizatorilor noștri.
Extragerea logicii din main
Odată finalizată refactorizarea analizei configurației, ne îndreptăm acum spre logica programului. Conform celor stabilite în „Separarea problemelor pentru proiectele binare”, extragem o funcție denumită run care va cuprinde toată logica existentă în funcția main, cu excepția părților care se ocupă de configurarea inițială sau de gestionarea erorilor. La finalizare, main va fi concisă și ușor de verificat printr-o simplă inspecție, iar noi vom fi capabili să scriem teste pentru întreaga logică restantă.
Listarea 12-11 ilustrează procesul de extracție a funcției run. Pentru moment, aceasta reprezintă un pas mic și gradual în îmbunătățirea codului. Funcția continuă să fie definită în src/main.rs.
Numele fișierului: src/main.rs
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) {
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Listarea 12-11: Extragerea funcției run, care conține restul logicii din program
Funcția run încorporează acum toată logica rămasă din main, începând de la etapa de citire a fișierului. Aceasta primește o instanță de Config ca parametru.
Returnarea erorilor de către funcția run
Cu partea rămasă de logică a programului separată acum în funcția run, avem oportunitatea de a îmbunătăți gestionarea erorilor, așa cum am procedat pentru Config::build în Listarea 12-9. În loc să lăsăm programul să genereze panică prin apelarea expect, funcția run va returna un Result<T, E> când ceva nu funcționează corect. Aceasta ne va da posibilitatea de a centraliza mai eficient gestionarea erorilor în main, într-un mod accesibil utilizatorului. Listarea 12-12 prezintă modificările necesare la semnătura și corpul funcției run.
Numele fișierului: src/main.rs
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Listarea 12-12: Modificarea funcției run pentru a returna Result
Am realizat trei schimbări importante aici. Prima, schimbarea tipului de retur pentru funcția run în Result<(), Box<dyn Error>>. Inițial, această funcție returna tipul unit (), pe care acum îl păstrăm ca valoare returnată în cazul de succes Ok.
Ca tip de eroare, am utilizat obiectul-trăsătură Box<dyn Error> (și am importat std::error::Error în context cu o directivă use la începutul fișierului). Vom discuta despre obiecte-trăsătură în Capitolul 17. Deocamdată, e de ajuns să știm că Box<dyn Error> înseamnă că funcția va returna un tip care implementează trăsătura Error, fără a specifica tipul exact al valorii de retur. Aceasta oferă flexibilitatea de a returna diferite valori ale erorilor în diferite scenarii de eroare. Cuvântul dyn este o abreviere pentru „dinamic” (dynamic).
În al doilea rând, am înlocuit apelul la expect cu operatorul ?, despre care am discutat în Capitolul 9. În loc să provoace panic! atunci când întâlnește o eroare, ? va returna valoarea erorii din funcția actuală pentru ca apelantul să o poată gestiona.
În al treilea rând, funcția run returnează acum o valoare Ok în caz de reușită. În semnătura ei, am declarat tipul de succes al funcției run ca fiind (), ceea ce ne obligă să închidem valoarea tipului unit într-o valoare Ok. Sintagma Ok(()) poate părea inițial ciudată, dar utilizarea () în acest fel este modul convențional de a semnala că apelăm run doar pentru efectele sale secundare; nu are o valoare de retur relevantă pentru noi.
La rularea acestui cod, compilarea se va efectua, dar va afișa un avertisment:
$ cargo run the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Rust ne avertizează că am ignorat valoarea Result și că această valoare Result ar putea semnala că s-a produs o eroare. Nu am verificat însă dacă există sau nu o astfel de eroare, iar compilatorul ne atenționează că, probabil, intenționăm să adăugăm ceva cod pentru gestionarea erorilor! Să corectăm acum acest aspect.
Tratarea erorilor returnate de run în funcția main
Detectăm erorile și le gestionăm printr-o metodă similară cu cea utilizată anterior pentru Config::build, în Listarea 12-10, dar cu o subtilă deosebire:
Numele fișierului: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Optăm pentru if let în defavoarea lui unwrap_or_else atunci când verificăm dacă run dă o valoare de tip Err și invocăm process::exit(1) în acest caz. Funcția run nu returnează o valoare pe care am vrea să-i facem unwrap, spre deosebire de ceea ce se întâmplă cu Config::build, care ne oferă instanța Config. Deoarece run returnează () când operează cu succes, suntem interesați exclusiv de depistarea unei erori și, prin urmare, nu avem nevoie de unwrap_or_else pentru a extrage valoarea neîmpachetată, care ar fi de altfel doar ().
Procedura funcțiilor if let și unwrap_or_else este la fel în ambele contexte: afișăm mesajul de eroare și terminăm execuția.
Divizarea codului într-un crate de tip bibliotecă
Proiectul nostru minigrep se prezintă excelent până acum! Urmează să împărțim conținutul fișierului src/main.rs și să transferăm unele porțiuni de cod în fișierul src/lib.rs. Astfel, vom putea testa codul și vom avea un fișier src/main.rs cu responsabilități reduse.
Să transferăm toate părțile de cod care nu sunt funcția main din src/main.rs în src/lib.rs:
- Definiția funcției
run - Declarațiile
useaplicabile - Definiția structurii
Config - Definiția metodei
Config::build
Fișierul src/lib.rs ar trebui să conțină semnăturile ilustrate în Listarea 12-13 (am omis corpurile funcțiilor pentru rezum). Atenție, acest cod nu va compila până nu facem modificările necesare în src/main.rs, așa cum este indicat în Listarea 12-14.
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
// --snip--
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}Listarea 12-13: Transferul lui Config și run în src/lib.rs
Am folosit generos cuvântul pub: la structura Config, la câmpurile și metoda sa build, precum și la funcția run. De acum, dispunem de un crate de tip bibliotecă cu un API public ce poate fi testat!
Trebuie acum să aducem în domeniul de vizibilitate al crate-ului binar din src/main.rs codul pe care l-am mutat în src/lib.rs, după cum este ilustrat în Listarea 12-14.
Numele fișierului: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = minigrep::run(config) {
// --snip--
println!("Application error: {e}");
process::exit(1);
}
}Listarea 12-14: Folosirea crate-ului de tip bibliotecă minigrep în src/main.rs
Introducem linia use minigrep::Config pentru a aduce tipul Config din crate-ul de tip bibliotecă în sfera de accesibilitate a crate-ului binar și prefixăm funcția run cu numele crate-ului nostru. Tot ansamblul de funcționalități ar trebui să fie acum interconectat și să funcționeze corect. Execută programul cu cargo run pentru a te asigura că totul merge bine.
Ce muncă intensivă! Dar prin aceasta ne-am pregătit pentru succes pe termen lung. Acum este considerabil mai simplu să gestionăm erorile și am modularizat codul. De acum înainte, majoritatea activității noastre se va concentra în src/lib.rs.
Să profităm de această modularitate nou dobândită prin executarea unei sarcini care ar fi fost complicată cu codul vechi dar este simplă cu noul cod: să scriem niște teste!
Dezvoltarea funcționalității bibliotecii cu Test-Driven Development
După ce am separat logica în src/lib.rs și ne-am limitat la colectarea argumentelor și la gestionarea erorilor în src/main.rs, testarea funcționalității nucleului codului nostru s-a simplificat considerabil. Acum este posibil să apelăm funcții direct cu diferiți parametri și să verificăm valorile de retur fără a necesita execuția binarului din linia de comandă.
Vom începe această secțiune adăugând logica de căutare la programul minigrep, prin aplicarea principiilor test-driven development (TDD) și urmând pașii de mai jos:
- Redactează un test care pică și execută-l pentru a confirma că eșuează din cauza anticipată.
- Elaborează sau ajustează strict necesarul de cod pentru a asigura trecerea noului test.
- Refactorizează codul pe care l-ai introdus sau modificat și verifică dacă testele rămân valide.
- Reia procesul de la primul pas!
Deși reprezintă doar una dintre metodele de dezvoltare software, TDD joacă un rol cheie în structurarea codului. Abordarea de a scrie testul înaintea codului care va determina succesul acestuia contribuie la menținerea unei rate constante de acoperire a testelor de-a lungul întregului proces.
Urmează să testăm implementarea funcționalității care realizează căutarea expresiei de interogare în conținutul unui fișier, rezultând într-o listă cu liniile ce se potrivesc cu interogarea specificată. Vom aduce această capabilitate într-o funcție denumită search.
Scrierea unui test ce eșuează
Pentru că nu ne mai sunt necesare, să eliminăm instrucțiunile println! din
src/lib.rs și src/main.rs pe care le-am folosit pentru a verifica comportamentul programului. Apoi, în src/lib.rs, adăugăm un modul tests cu o funcție de testare, așa cum am făcut în Capitolul 11. Funcția de testare specifică comportamentul pe care îl dorim de la funcția search: aceasta va prelua o interogare și textul de căutat și va returna doar liniile din text care includ interogarea. Listarea 12-15 prezintă acest test, care deocamdată nu poate fi compilat.
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Listarea 12-15: Crearea unui test ce eșuează pentru funcția search pe care ne dorim s-o avem
Testul acesta caută string-ul "duct". Textul supus căutării este din trei rânduri, dintre care doar unul îl conține pe "duct" (De reținut că backslash-ul după ghilimeaua de început spune compilatorului Rust să nu includă un caracter de schimbare de linie la începutul conținutului literalului de tip string). Afirmăm că valoarea returnată de funcția search va conține exclusiv rândul pe care îl așteptăm.
În prezent, nu putem să rulăm acest test și să vedem că eșuează pentru că testul nici măcar nu se compilează: funcția search nu există încă! Respectând principiile TDD, vom adăuga strict atât cod cât este necesar pentru a face testul să se compileze și să ruleze, prin definirea unei funcții search care întoarce constant un vector gol, așa cum se arată în Listarea 12-16. Apoi, testul ar trebui să se compileze și să eșueze pentru că un vector gol nu se potrivește cu un vector ce conține rândul "safe, fast, productive."
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Lista 12-16: Definirea strict necesarului pentru funcția search astfel încât testul nostru să fie compilabil
Este necesar să definim explicit durata de viață 'a în semnatura funcției search și să folosim această durată de viață atât pentru argumentul contents cât și pentru valoarea de retur. În Capitolul 10 am învățat că parametrii duratei de viață stabilesc legătura dintre durata de viață a unui argument și durata de viață a valorii returnate. În acest exemplu, specificăm că vectorul returnat trebuie să includă secțiuni de string-uri care fac referire la secțiuni din argumentul contents (și nu din query).
Cu alte cuvinte, îi comunicăm lui Rust că datele returnate de funcția search vor exista pentru tot atâta timp cât există datele furnizate funcției search prin argumentul contents. Acest aspect este crucial! Datele la care se referă o secțiune trebuie să fie valide pentru ca referința să fie, de asemenea, validă; dacă compilatorul crede că generăm secțiuni de string-uri din query în loc de contents, verificarea de siguranță va fi realizată greșit.
Dacă uităm să adăugăm adnotările de durată de viață și încercăm să compilăm această funcție, vom întâmpina următoarea eroare:
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:28:51
|
28 | pub fn search(query: &str, contents: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
28 | pub fn search<'a>(query: &'a str, contents: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` due to previous error
Rust nu poate determina de unul singur care dintre cele două argumente este cel necesar, deci trebuie să îi specificăm în mod explicit. Deoarece contents este argumentul ce conține întregul nostru text și dorim să returnăm fragmentele care se potrivesc, putem deduce că contents este argumentul care trebuie legat de valoarea de retur prin utilizarea sintaxei pentru durate de viață.
În alte limbaje de programare nu este necesară asocierea argumentelor cu valorile de retur în cadrul semnăturii funcției, însă cu practică, acest proces va deveni mai simplu. Poate fi util să compari acest exemplu cu secțiunea “Validând referințe cu timpuri de viață” din Capitolul 10.
Să executăm acum testul:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 0.97s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... FAILED
failures:
---- tests::one_result stdout ----
thread 'tests::one_result' panicked at 'assertion failed: `(left == right)`
left: `["safe, fast, productive."]`,
right: `[]`', src/lib.rs:44:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::one_result
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Minunat, testul eșuează exact cum anticipam. Să facem acum testul să treacă!
Scrierea codului pentru a trece testul
Testul nostru actual eșuează deoarece returnăm mereu un vector gol. Pentru a corecta asta și pentru a implementa funcția search, programul trebuie să urmeze acești pași:
- Parcurge fiecare linie din conținut.
- Verifică dacă linia conține string-ul nostru de căutare.
- Dacă îl conține, adaugă-l la lista valorilor pe care urmează să le returnăm.
- Dacă nu, nu întreprinde nici o acțiune.
- Întoarce lista rezultatelor care corespund criteriului de căutare.
Să abordăm fiecare pas, începând cu parcurgerea liniilor.
Parcurgerea liniilor cu metoda lines
Rust oferă o metodă utilă pentru a efectua iterația string-ului linie cu linie, numită în mod convenabil lines, care funcționează așa cum este arătat în Listarea 12-17. De notat că deocamdată acest cod nu va compila.
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Listarea 12-17: Parcurgerea fiecărei linii din contents
Metoda lines returnează un iterator. Vom discuta detalii despre iteratori în Capitolul 13, însă îți amintești că ai întâlnit modul de utilizare a iteratorilor în Listarea 3-5, unde am folosit bucla for împreună cu un iterator pentru a rula codul pe fiecare element dintr-o colecție.
Căutarea interogării în fiecare linie
Acum, să verificăm dacă fiecare linie curentă conține string-ul căutat în interogarea noastră. Din fericire, string-urile dispun de o metodă foarte utilă denumită contains care realizează această verificare pentru noi! Adăugăm o apelare la contains în funcția search, așa cum este prezentat în Listarea 12-18. Nu uita că la acest moment codul încă nu va compila.
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
if line.contains(query) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Listarea 12-18: Introducem funcționalitatea pentru a verifica dacă linia conține string-ul specificat în query
În această etapă, ne concentrăm pe dezvoltarea funcționalităților. Pentru ca programul să compileze, trebuie să returnăm o valoare din corpul funcției, conform cu ceea ce am promis în semnătura funcției.
Salvarea liniilor potrivite
Pentru a completa această funcție, avem nevoie de un mod de a salva liniile care se potrivesc și pe care vrem să le returnăm. Pentru asta, putem iniția un vector mutabil înainte de bucla for și folosim metoda push pentru a adăuga o line în vector. După bucla for, returnăm vectorul, așa cum se arată în Listarea 12-19.
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Listarea 12-19: Salvarea liniilor care se potrivesc pentru a le putea returna
Acum, funcția search ar trebui să returneze numai liniile care includ query, și testul nostru ar trebui să treacă. Să încercăm să rulăm testul:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Testul nostru a trecut cu succes, deci suntem siguri că funcționează!
În acest moment, putem lua în considerare posibilități de refactoring pentru implementarea funcției de căutare, în timp ce ne asigurăm că testele rămân trecute pentru a păstra aceeași funcționalitate. Codul din funcția de search nu este rău, dar nu beneficiază de unele funcționalități utile ale iteratorilor. Ne vom reîntoarce la acest exemplu în Capitolul 13, când vom explora pe larg iteratorii și vom vedea cum poate fi îmbunătățit.
Utilizând funcția search în funcția run
Acum că funcția search este funcțională și testată, trebuie să o apelăm din funcția run. Vom transmite valoarea config.query și conținutul pe care run îl extrage din fișier către funcția search. După aceea, run va afișa fiecare linie pe care search o returnează:
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Continuăm să utilizăm o buclă for pentru a prelua fiecare linie returnată de search și a o afișa. Acum, programul complet ar trebui să funcționeze! Să-l testăm, mai întâi cu un cuvânt care ar trebui să returneze o singură linie din poezia Emilyi Dickinson, "frog":
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
Excelent! Acum să încercăm un cuvânt care va potrivi mai multe linii, precum "body":
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
Și în final, să verificăm că nu obținem nicio linie atunci când căutăm un cuvânt ce nu există în poezie, precum "monomorphization":
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
Excelent! Ne-am creat propria variantă a unui instrument clasic și am învățat foarte multe despre structura aplicațiilor. Am aprofundat și noțiuni despre manipularea fișierelor, durata de viață, testare și analiza comenzilor introduse în linia de comandă.
Pentru a completa acest proiect, vom explica pe scurt cum să interacționăm cu variabilele de mediu și cum să scriem pe eroare standard, ambele fiind importante atunci când dezvoltați aplicații pentru linia de comandă.
Interacționând cu variabilele de mediu
Vom îmbunătăți minigrep prin adăugarea unei opțiuni noi: căutarea care nu face distincție între majuscule și minuscule, ce poate fi activată prin intermediul unei variabile de mediu. Deși această caracteristică ar putea fi oferită ca o opțiune de linie de comandă, ceea ce ar impune utilizatorilor să o introducă de fiecare dată, alegerea de a o configura ca variabilă de mediu le permite acestora să o seteze o singură dată, astfel toate căutările lor în cadrul sesiunii curente de terminal să fie insesibilă la majuscule.
Scrierea unui test nereușit pentru funcția search_case_insensitive
Adăugăm mai întâi o nouă funcție search_case_insensitive care va fi apelată atunci când variabila de mediu deține o valoare. Continuăm să urmăm procesul TDD, așadar primul pas este, din nou, să scriem un test nereușit. Vom adăuga un nou test pentru funcția search_case_insensitive și vom redenumi testul vechi din one_result în case_sensitive pentru a face distincția clară între cele două teste, după cum se arată în Listarea 12-20.
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listarea 12-20: Adăugarea unui test nou nereușit pentru funcția de căutare insensibilă la majuscule pe care urmează să o implementăm
Observați că am editat și conținutul testului anterior. Am introdus o linie nouă cu textul "Duct tape." care utilizează un D majuscul și care nu ar trebui să corespundă cu interogarea "duct" când efectuăm căutarea în mod sensibil la majuscule. Această modificare a testului anterior ajută la asigurarea faptului că nu stricăm din greșeală funcționalitatea de căutare sensibilă la majuscule pe care am realizat-o deja. Testul actual ar trebui să fie valid acum și ar trebui să rămână așa pe măsură ce dezvoltăm căutarea insensibilă la majuscule.
Testul nou pentru căutarea insensibilă la majuscule folosește interogarea "rUsT". În funcția search_case_insensitive pe care o vom adăuga în curând, interogarea "rUsT" ar trebui să găsească linia ce conține "Rust:" cu un R majuscul și să identifice și linia "Trust me.", deși ambele au diferite utilizări de majuscule față de interogare. Aceasta este definiția testului nereușit, care va eșua în compilare deoarece nu am definit încă funcția search_case_insensitive. Nu vă abțineți de la adăugarea unei implementări schelet care să returneze mereu un vector gol, asemănător cu modul în care am procedat pentru funcția search în Listarea 12-16, pentru a observa compilarea nereușită a testului.
Implementarea funcției search_case_insensitive
Funcția search_case_insensitive, ilustrată în Listarea 12-21, va fi foarte similară cu funcția search. Unica diferență constă în faptul că vom converti atât interogarea cât și fiecare linie la litere mici, astfel încât, indiferent de cazul literelor argumentelor de intrare, ele vor fi în același format când verificăm dacă linia conține interogarea.
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listarea 12-21: Definirea funcției search_case_insensitive pentru a converti interogarea și linia la litere mici înainte de a efectua comparația
În primul rând, convertim string-ul query la litere mici și îl salvăm într-o variabilă nouă, umbrită, păstrând același nume. Apelarea funcției to_lowercase asupra interogării este esențială astfel încât, indiferent de forma interogării utilizatorului – fie "rust", fie "RUST", fie "Rust", fie "rUsT" – noi vom considera interogarea ca fiind "rust", tratând-o fără să ținem cont de cazul literelor. Deși to_lowercase poate procesa caractere Unicode de bază, acuratețea nu va fi de 100%. Dacă am dezvolta o aplicație reală, am dori să fim mai meticuloși în această privință, însă aici ne concentrăm pe variabilele de mediu și nu pe Unicode, așa că o lăsăm așa cum este.
Să reținem că acum query devine un String și nu o secțiune de string, deoarece aplicarea funcției to_lowercase generează date noi în loc să referințieze datele existente. Să luăm de exemplu interogarea "rUsT": secțiunea de string originală nu include un u sau un t în litere mici la care noi să avem acces, așadar este necesar să creăm un nou String care să conțină "rust". Când transmitem interogarea ca argument funcției contains, trebuie să adăugăm semnul ampersand (&) deoarece semnătura funcției contains necesită o secțiune de string.
Acum adăugăm un apel la to_lowercase pentru fiecare line pentru a transforma toate caracterele în litere mici. După ce am convertit line și query la litere mici, vom identifica potriviri indiferent de majusculele sau minusculele interogării.
Să verificăm dacă această implementare trece testele:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Excelent! Au trecut. Acum, să invocăm funcția nouă search_case_insensitive din cadrul funcției run. Pentru început, vom adăuga o opțiune de configurare în structura Config pentru a alege între căutarea sensibilă și căutarea insensibilă la majuscule. Adăugarea acestui câmp va cauza erori de compilare deoarece nu inițializăm acest câmp în niciun loc momentan:
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Am adăugat câmpul ignore_case care conține un Boolean. Acum trebuie ca funcția run să verifice valoarea câmpului ignore_case și să folosească această informație pentru a decide dacă va apela funcția search sau search_case_insensitive, după cum este indicat în Listarea 12-22. Această parte încă nu va compila.
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listarea 12-22: Apelarea fie search, fie search_case_insensitive în funcție de valoarea din config.ignore_case
În final, avem nevoie să verificăm variabila de mediu. Funcțiile pentru interacțiunea cu variabilele de mediu se află în modulul env din biblioteca standard, așadar îl importăm în domeniu de vizibilitate la începutul src/lib.rs. Vom folosi apoi funcția var din modulul env pentru a determina dacă o valoare a fost stabilită pentru o variabilă de mediu numită IGNORE_CASE, așa cum se arată in Listarea 12-23.
Numele fișierului: src/lib.rs
use std::env;
// --snip--
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listarea 12-23: Căutarea pentru orice valoare într-o variabilă de mediu numită IGNORE_CASE
Aici, definim o nouă variabilă denumită ignore_case. Pentru a-i aloca o valoare, apelăm funcția env::var pe care o furnizează modulul env, pasându-i ca argument numele variabilei de mediu IGNORE_CASE. Funcția env::var returnează un Result care în caz de succes devine varianta Ok și conține valoarea variabilei de mediu, dacă aceasta a fost setată. Dacă variabila de mediu nu este prezentă, funcția va returna varianta Err.
Folosim metoda is_ok de pe Result pentru a verifica existența variabilei de mediu, semn că programul ar trebui să efectueze o căutare insensibilă la majuscule. Dacă variabila IGNORE_CASE nu este specificată, is_ok va da ca rezultat fals și, în consecință, programul va realiza o căutare sensibilă la majuscule (case-sensitive). Nu ne concentram asupra valorii variabilei de mediu, ci doar asupra faptului dacă aceasta este definită sau nu, prin urmare ne bazăm pe metoda is_ok în loc să optăm pentru unwrap, expect sau alte metode asociate cu Result.
Valoarea din ignore_case este transmisă instanței Config, permițând astfel funcției run să acceseze această informație și să decidă dacă să apeleze search_case_insensitive sau search, conform implementării din Listarea 12-22.
Să încercăm! În primul rând, să rulăm programul fără să setăm variabila de mediu și cu interogarea to, care ar trebui să potrivească orice linie ce conține cuvântul „to” în litere mici:
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
Iată că funcționează și așa! Acum, să executăm programul cu variabila IGNORE_CASE setată la 1, dar păstrând aceeași interogare to.
$ IGNORE_CASE=1 cargo run -- to poem.txt
Dacă utilizezi PowerShell, va trebui să setezi variabila de mediu și să execuți programul cu două comenzi separate:
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
Aceasta va face ca IGNORE_CASE să rămână activă pentru restul sesiunii de shell. Poate fi dezactivată folosind cmdlet-ul Remove-Item:
PS> Remove-Item Env:IGNORE_CASE
Ar trebui să obținem linii ce conțin „to” și care ar putea avea litere mari:
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
Excelent, am primit și linii care conțin „To”! Programul nostru minigrep poate acum efectua căutări care nu țin cont de caz, controlate prin intermediul unei variabile de mediu. Acum cunoști modul în care se pot gestiona opțiunile setate fie prin argumente de linie de comandă, fie prin variabile de mediu.
Unele programe permit folosirea argumentelor și variabilelor de mediu pentru aceeași configurare. În asemenea situații, programele stabilesc care din cele două opțiuni are prioritate. Ca exercițiu suplimentar individual, încearcă să controlezi sensibilitatea la majuscule fie printr-un argument de linie de comandă, fie printr-o variabilă de mediu. Decide care dintre cele două - argumentul de linie de comandă sau variabila de mediu - ar trebui să prevaleze în cazul în care programul este executat cu unul setat pe sensibilitate la majuscule și celălalt pe ignorarea diferențelor.
Modulul std::env include multe alte funcționalități utile legate de variabilele de mediu: verifică documentația pentru a vedea ce alte posibilități îți oferă.
Afișarea mesajelor de eroare pe eroare standard în loc de ieșire standard
În prezent, transmitem toate mesajele noastre către terminal folosind macro-ul println!. În majoritatea terminalelor există două tipuri de afișaj: ieșirea standard (stdout) pentru informații generale și eroarea standard (stderr) pentru mesajele de eroare. Acest lucru face posibilă alegerea de către utilizatori a redirecționării afișajului reușit al unui program spre un fișier, păstrând în același timp afișarea mesajelor de eroare pe ecran.
Macro-ul println! este capabil să afișeze doar pe ieșirea standard, așadar în scopul de a facilita afișarea pe eroarea standard, va trebui să apelăm la o altă metodă.
Verificarea locului unde sunt scrise erorile
La început, să examinăm cum conținutul afișat de minigrep este redat în prezent pe ieșirea standard, și cum putem direcționa mesajele de eroare către eroarea standard în schimb. Facem acest lucru redirecționând fluxul de ieșire standard către un fișier și declanșăm intenționat o eroare. Fluxul de eroare standard nu va fi redirecționat, deci tot ceea ce este trimis către eroarea standard va apărea în continuare pe ecran.
Este așteptat ca programele de linie de comandă să expedieze mesajele de eroare către fluxul de eroare standard, permițându-ni să vedem aceste mesaje pe ecran chiar dacă ieșirea standard este trimisă către un fișier. În stadiul actual, programul nostru nu respectă această convenție: ne pregătim să constatăm că mesajele de eroare sunt salvate într-un fișier, nu afișate pe ecran!
Pentru a ilustra acest comportament, vom executa programul cu > urmat de numele fișierului, output.txt, către care dorim să redirecționăm ieșirea standard. Nu vom adăuga niciun argument pentru a induce o eroare:
$ cargo run > output.txt
Sintaxa > instruiește shell-ul să trimită conținutul ieșirii standard în output.txt în loc să-l afișeze pe ecran. De vreme ce mesajul de eroare așteptat nu a fost vizibil pe ecran, presupunem că a fost redirecționat în fișier. Iată ce a ajuns în output.txt:
Problem parsing arguments: not enough arguments
Așa este, mesajul de eroare se afișează pe ieșirea standard. Este preferabil ca astfel de mesaje să fie trimise către eroarea standard, astfel încât doar rezultatele corecte să poată fi salvate în fișier. Vom face schimbarea necesară.
Afișarea erorilor pe eroarea standard
Vom utiliza codul din Listarea 12-24 pentru a schimba modul în care mesajele de eroare sunt afișate. Datorită refactoring-ului realizat anterior în acest capitol, toate porțiunile de cod ce afișează mesajele de eroare se găsesc într-o unică funcție, main. Macro-ul eprintln!, oferit de biblioteca standard, afișează către fluxul de eroare standard, așadar să modificăm cele două locuri unde apelam println! pentru a afișa erorile, utilizând în schimb eprintln!.
Numele fișierului: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}Listarea 12-24: Scrierea mesajelor de eroare pe eroarea standard în locul ieșirii standard folosind eprintln!
Acum să rulăm programul din nou în același mod, fără argumente și redirecționând ieșirea standard cu >:
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
Observăm eroarea pe ecran și output.txt nu conține nimic, acesta fiind comportamentul așteptat de la programele de linie de comandă.
Să rulăm din nou programul cu argumente care nu provoacă o eroare, totuși redirecționăm ieșirea standard către un fișier, în felul următor:
$ cargo run -- to poem.txt > output.txt
Nu vom avea parte de nicio afișare pe terminal, iar output.txt va conține rezultatele noastre:
Numele fișierului: output.txt
Are you nobody, too?
How dreary to be somebody!
Aceasta demonstrează că folosim acum ieșirea standard pentru afișajul succesului și eroarea standard pentru afișajul erorilor, așa cum este adecvat.
Sumar
În acest capitol am revăzut unele dintre cele mai importante concepte pe care le-ai asimilat până în prezent și am discutat despre cum să executăm operațiuni I/O obișnuite în Rust. Prin utilizarea argumentelor de linie de comandă, fișierelor, variabilelor de mediu, și a macro-ului eprintln! pentru afișarea erorilor, ești acum echipat să creezi aplicații pentru linie de comandă. Îmbinând aceste cunoștințe cu conceptele prezentate în capitolele anterioare, codul tău va fi structurat corect, va stoca datele eficient în structurile de date potrivite, va gestiona erorile elegant și va beneficia de testare riguroasă.
În capitolul următor, ne vom aprofunda în explorarea unor funcționalități Rust inspirate din limbajele de programare funcționale: închiderile și iteratorii.
Elemente de programare funcțională în Rust: închideri și iteratori
Designul Rust a fost inspirat de numeroase limbaje și tehnici existente, o influență semnificativă fiind programarea funcțională. Stilul funcțional de programare implică frecvent utilizarea funcțiilor ca valori: acestea pot fi transmise ca argumente, returnate de alte funcții sau atribuite variabilelor pentru execuție ulterioară.
În acest capitol, nu vom intra în dezbaterea despre ce definește programarea funcțională, ci vom explora unele caracteristici ale limbajului Rust care sunt tipice pentru limbajele considerate funcționale.
În detaliu, vom aborda:
- Închiderile (closures), structuri similare funcțiilor pe care le poți salva într-o variabilă
- Iteratorii, o abordare pentru procesarea unei serii de elemente
- Modul în care închiderile și iteratorii pot fi folosiți pentru a îmbunătăți proiectul de I/O din Capitolul 12
- Performanța închiderilor și a iteratorilor (Spoiler: sunt mai performanți decât ai crede!)
Am discutat anterior despre alte aspecte ale lui Rust, cum ar fi corelarea șabloanelor și enumerațiile, care sunt de asemenea marcate de influența stilului funcțional. Deoarece stăpânirea închiderilor și a iteratorilor constituie un element cheie în redactarea codului Rust idiomatic și eficient, le vom aloca un întreg capitol.
Închideri: funcții anonime care captează contextul
Închiderile din Rust sunt funcții anonime pe care le poți stoca într-o variabilă sau le poți folosi ca argumente în alte funcții. Poți defini o închidere într-un anumit punct și mai târziu să o apelezi într-un alt context pentru evaluare. Diferența majoră față de funcții este că închiderile pot prelua valori din domeniul de vizibilitatea (numite și context) în care au fost create. Vom arăta cum aceste posibilități ale închiderilor sporesc reutilizabilitatea codului și permit adaptarea acestuia la necesități specifice.
Capturarea contextului cu închideri
Să examinăm cum putem utiliza închiderile pentru a captura valori din mediul înconjurător în care sunt definite, pentru a le folosi ulterior. Iată scenariul: Ocazional, compania noastră de tricouri oferă ca promoție un tricou exclusiv, în ediție limitată, uneia dintre persoanele abonate la lista noastră de distribuție de emailuri. Membrii listei de distribuție pot selecta, dacă doresc, culoarea preferată în profilul lor. Dacă persoana aleasă pentru un tricou gratuit a specificat o culoare preferată, atunci va primi un tricou în acea culoare. Dacă persoana nu a indicat o culoare preferată, aceasta va primi culoarea pentru care compania are cel mai mare stoc.
Pentru realizarea acestui lucru, există numeroase abordări. În exemplul nostru, vom utiliza un enum denumit ShirtColor care include variantele Red și Blue (pentru a limita numărul de culori disponibile, simplificând astfel exemplul). Inventarul companiei este reprezentat printr-o structură numită Inventory, ce dispune de un câmp denumit shirts care conține un Vec<ShirtColor>, reprezentarea culorilor tricourilor curent în stoc. Metoda giveaway, definită în Inventory, preia preferința de culoare a tricoului opțională a câștigătorului promoției și returnează culoarea tricoului pe care îl va primi. Această structură este ilustrată în Listarea 13-1:
Numele fișierului: src/main.rs
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
}
struct Inventory {
shirts: Vec<ShirtColor>,
}
impl Inventory {
fn giveaway(&self, user_preference: Option<ShirtColor>) -> ShirtColor {
user_preference.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
fn main() {
let store = Inventory {
shirts: vec![ShirtColor::Blue, ShirtColor::Red, ShirtColor::Blue],
};
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"The user with preference {:?} gets {:?}",
user_pref1, giveaway1
);
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"The user with preference {:?} gets {:?}",
user_pref2, giveaway2
);
}Listarea 13-1: Exemplul promoției companiei de tricouri
Magazinul store definit în funcția main are în stoc două tricouri de culoare albastră și unul de culoare roșie, destinate distribuției în cadrul acestei promoții limitate. Invocăm metoda giveaway pentru un utilizator care preferă tricouri de culoare roșie și pentru altul care nu are o preferință de culoare anume.
Încă o dată, codul prezentat putea fi implementat în diverse moduri, dar pentru a ne concentra pe închideri, ne-am limitat la conceptele deja cunoscute, cu singura excepție reprezentată de corpul metodei giveaway, ce folosește o închidere. Metoda giveaway, primește preferința utilizatorului ca parametru de tip Option<ShirtColor> și apoi invocă metoda unwrap_or_else pe user_preference. Metoda [unwrap_or_else aplicată pe Option<T>][unwrap-or-else] e definită de biblioteca standard Rust. Aceasta acceptă un singur argument: o închidere care nu necesită argumente și care returnează o valoare T (tipul stocat în varianta Some a lui Option<T>, în acest caz ShirtColor). Dacă Option<T> este Some, unwrap_or_else returnează valoarea conținută acolo. Dacă Option<T> este None, unwrap_or_else apelează închiderea și returnează rezultatul acesteia.
Pentru unwrap_or_else definim expresia || self.most_stocked() ca argument. Aceasta este o închidere fără argumente proprii, evidentă prin absența parametrilor între barele verticale. Corpul închiderii apelează metoda self.most_stocked(). Închiderea este definită în acel punct și va fi evaluată de unwrap_or_else la momentul necesar.
Executând acest cod primim următorul afișaj:
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished dev [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
The user with preference Some(Red) gets Red
The user with preference None gets Blue
Un detaliu demn de remarcat este că am pasat către metoda unwrap_or_else o închidere care invocă self.most_stocked() pe instanța curentă de Inventory. Biblioteca standard nu este forțată să cunoască tipurile Inventory sau ShirtColor pe care le-am definit, nici logica specifică dorită de noi în acest caz. Închiderea reține o referință imutabilă la instanța self de Inventory și o transmite, împreună cu codul definit, metodei unwrap_or_else. În contrast, funcțiile clasice nu pot captura contextul înconjurător în aceeași manieră.
Inferența de tip și adnotarea pentru închideri
Sunt diferite distincții între funcții și închideri. De obicei, închiderile nu necesită să adnotăm tipurile parametrilor sau tipul valorii de retur, spre deosebire de funcțiile marcate cu fn. Adnotările de tip sunt imperios necesare la funcții pentru că fac parte integrantă dintr-o interfață explicit expusă utilizatorilor. Este indispensabil să definim această interfață în mod precis pentru a ne asigura că toți utilizatorii avem un acord unanim privind tipurile de valori pe care o funcție le utilizează și le întoarce. Pe de altă parte, închiderile nu sunt exploatate într-o interfață expusă într-un mod similar: sunt păstrate în variabile și utilizate anonim, fără a fi expuse utilizatorilor bibliotecii noastre.
Închiderile sunt frecvent concise și pertinente doar într-un context restrâns, nu în scenarii arbitrare. În cadrul acestui context delimitat, compilatorul poate infera tipurile parametrilor și tipul valorii returnate, similar cu capacitatea sa de a deduce tipurile pentru majoritatea variabilelor (există cazuri excepționale unde compilatorul necesită și adnotări de tip pentru închideri).
Similar cu variabilele, avem opțiunea de a adnota tipurile dacă dorim să creștem nivelul de explicitate și claritate, cu prețul unui stil mai verbos decât este absolut necesar. Procesul de adnotare a tipurilor pentru o închidere se reflectă în definiția prezentată în Listarea 13-2. În exemplul nostru, definim o închidere și o salvăm într-o variabilă, în loc să o definim imediat în punctul în care o utilizăm ca argument, așa cum am făcut în Listarea 13-1.
Numele fișierului: src/main.rs
use std::thread; use std::time::Duration; fn generate_workout(intensity: u32, random_number: u32) { let expensive_closure = |num: u32| -> u32 { println!("calculating slowly..."); thread::sleep(Duration::from_secs(2)); num }; if intensity < 25 { println!("Today, do {} pushups!", expensive_closure(intensity)); println!("Next, do {} situps!", expensive_closure(intensity)); } else { if random_number == 3 { println!("Take a break today! Remember to stay hydrated!"); } else { println!( "Today, run for {} minutes!", expensive_closure(intensity) ); } } } fn main() { let simulated_user_specified_value = 10; let simulated_random_number = 7; generate_workout(simulated_user_specified_value, simulated_random_number); }
Listarea 13-2: Adăugarea adnotațiilor de tip opționale pentru parametri și tipul de valoare de retur în închidere
Cu adnotații de tip adăugate, sintaxa închiderilor devine mai asemănătoare cu cea a funcțiilor. Definim o funcție care adaugă 1 la parametrul ei și o închidere cu același comportament pentru comparație. Am inclus și câteva spații pentru alinierea părților corespunzătoare. Aici observăm că sintaxa închiderii este asemănătoare cu cea a funcției, diferența fiind utilizarea simbolului bară și faptul că multă sintaxă este opțională;
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;Prima linie prezintă definiția unei funcții, iar a doua linie o definiție a unei închideri cu adnotații complete. În a treia linie, scoatem adnotațiile de tip din definiția închiderii. În a patra, eliminăm acoladele, ce devin opționale când corpul închiderii constă doar într-o singură expresie. Toate acestea sunt definiții valide care produc același comportament la apelare. Liniile add_one_v3 și add_one_v4 necesită ca închiderea să fie evaluată la compilare, întrucât tipurile sunt inferate din contextul utilizării. Situația e similară cu let v = Vec::new();, unde sunt necesare adnotații de tip sau valori pentru determinarea tipului de către Rust.
Pentru definițiile închiderilor, compilatorul va infera un singur tip concret pentru fiecare dintre parametrii și pentru valoarea de retur. De exemplu, Listarea 13-3 arată definiția unei închideri concise care se limitează la a returna valoarea primită ca parametru. Această închidere este simplă și e prezentată doar ca exemplu. Remarcăm că nu avem adăugate adnotații de tip în definiție. Din acest motiv, putem invoca închiderea cu orice tip, așa cum am făcut aici cu String prima dată. Dacă încercăm să apelăm example_closure cu un număr întreg, întâlnim o eroare.
Numele fișierului: src/main.rs
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}Listarea 13-3: Tentativa de apelare a unei închideri cu tipuri inferate utilizând două tipuri diferite
Compilatorul ne semnalează următoarea eroare:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| --------------- ^- help: try using a conversion method: `.to_string()`
| | |
| | expected struct `String`, found integer
| arguments to this function are incorrect
|
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let example_closure = |x| x;
| ^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` due to previous error
Când apelăm example_closure prima dată cu o valoare de tip String, compilatorul inferă că x și valoarea de retur a închiderii sunt de tip String. Aceste tipuri sunt apoi fixate pentru example_closure, generând o eroare de tip atunci când încercăm să utilizăm un tip diferit cu aceeași închidere.
Capturarea referințelor sau transferul posesiunii
Închiderile pot captura valori din mediul înconjurător în trei moduri, care se mapează direct pe cele trei metode prin care o funcție poate primi un parametru: împrumutând imutabil, împrumutând mutabil și transferând posesiunea. În funcție de cum corpul funcției folosește valorile capturate, închiderea va decide care metodă să folosească.
În Listarea 13-4, definim o închidere care capturează o referință imutabilă către vectorul numit list, deoarece are nevoie doar de o referință imutabilă pentru a afișa valoarea:
Numele fișierului: src/main.rs
fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {:?}", list); let only_borrows = || println!("From closure: {:?}", list); println!("Before calling closure: {:?}", list); only_borrows(); println!("After calling closure: {:?}", list); }
Listarea 13-4: Definirea și apelarea unei închideri care capturează o referință imutabilă
Acest exemplu arată de asemenea că o variabilă poate fi legată de o definiție de închidere, și mai târziu putem apela închiderea utilizând numele variabilei și paranteze, ca și când numele variabilei ar fi numele unei funcții.
Pentru că putem avea mai multe referințe imutabile la list în același timp, list rămâne accesibil din codul de înainte de definirea închiderii, după definirea închiderii, dar înainte ca închiderea să fie apelată, și după ce închiderea este apelată. Acest cod se compilează, rulează și produce următorul afișaj:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
Before calling closure: [1, 2, 3]
From closure: [1, 2, 3]
After calling closure: [1, 2, 3]
În continuare, în Listarea 13-5, modificăm corpul închiderii astfel încât să adauge un element în vectorul list. Acum, închiderea capturează o referință mutabilă:
Numele fișierului: src/main.rs
fn main() { let mut list = vec![1, 2, 3]; println!("Before defining closure: {:?}", list); let mut borrows_mutably = || list.push(7); borrows_mutably(); println!("After calling closure: {:?}", list); }
Listarea 13-5: Definirea și apelarea unei închideri care capturează o referință mutabilă
Acest cod se compilează, rulează și produce următorul afișaj:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
After calling closure: [1, 2, 3, 7]
Remarcăm că nu mai există un println! între momentul definirii și cel al apelării închiderii borrows_mutably: când se definește borrows_mutably, aceasta captează o referință mutabilă la list. Nu mai utilizăm închiderea după ce este apelată, deci împrumutul mutabil se sfârșește. Între momentul definirii închiderii și apelul acesteia, un împrumut imutabil pentru a afișa valoarea nu este permis, deoarece în prezența unui împrumut mutabil nu sunt permise alte împrumuturi. Încercați să adăugați un println! în acel loc pentru a vedea ce mesaj de eroare apare!
Dacă intenționați să forțați închiderea să preia posesiunea valorilor pe care le folosește din context, chiar dacă în mod strict corpul închiderii nu ar avea nevoie de posesiune, puteți folosi cuvântul cheie move înainte de lista de parametri.
Această tehnică este utilă mai ales când transmitem o închidere către un nou fir de execuție (thread) pentru a transfera datele astfel încât să fie posesiunea noului fir. Discuțiile despre firele de execuție și motivele pentru care ai vrea să le folosești le vom aprofunda în Capitolul 16, când abordăm concurența. Până atunci, să analizăm pe scurt crearea unui nou fir de execuție folosind o închidere care necesită utilizarea cuvântului cheie move. Listarea 13-6 prezintă Listarea 13-4 modificată pentru a afișa vectorul într-un nou fir de execuție în loc de firul principal:
Numele fișierului: src/main.rs
use std::thread; fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {:?}", list); thread::spawn(move || println!("From thread: {:?}", list)) .join() .unwrap(); }
Listarea 13-6: Utilizarea move pentru a forța închiderea să preia posesiunea lui list în contextul firului de execuție nou creat
Inițializăm un nou fir de execuție, pasându-i o închidere ce urmează a fi executată ca argument. Corpul închiderii afișează lista. În Listarea 13-4, închiderea a capturat doar list printr-o referință imutabilă, pentru că asta era tot accesul necesar pentru a tipări list. În exemplul prezent, deși corpul închiderii încă necesită doar o referință imutabilă, este necesar să specificăm că list trebuie să fie permutat în închidere, prin plasarea cuvântului cheie move la începutul definiției închiderii. Este posibil ca noul fir de execuție să se finalizeze înainte de a se încheia restul firului principal, sau invers. Dacă firul principal ar păstra posesiunea lui list și s-ar termina înaintea firului nou și ar distruge list, referința imutabilă din cadrul noului fir ar deveni invalidă. Așadar, compilatorul impune ca list să fie permutat în închiderea destinată noului fir de execuție, pentru a asigura validitatea referinței. Încearcă să elimini cuvântul cheie move sau să utilizezi list în firul principal după definirea închiderii, pentru a descoperi ce erori de compilare apar!
Permutarea valorilor capturate din închideri și trăsăturile Fn
După ce o închidere a capturat fie o referință, fie a luat posesiunea unei valori din mediul unde este definită (influențând astfel ce anume este permutat în închidere), codul din corpul închiderii stabilește ce se va întâmpla cu referințele sau valorile atunci când închiderea este evaluată mai târziu (influențând astfel ce anume este permutat din închidere). Corpul închiderii poate realiza oricare dintre acțiunile următoare: să permute o valoare capturată din închidere, să modifice valoarea capturată, să nu permute și să nu modifice valoarea, sau să nu captureze deloc din mediul înconjurător inițial.
Modul cum o închidere capturează și administrează valorile din mediu dictează ce trăsături Fn va implementa, iar aceste trăsături sunt modul prin care funcțiile și structurile pot specifica ce tipuri de închideri sunt compatibile. Închiderile vor implementa automat una, două sau chiar toate cele trei trăsături Fn, în mod aditiv, depinzând de cum corpul închiderii gestionează valorile:
FnOncese aplică pentru închiderile care pot fi folosite o singură dată. Toate închiderile implementează minim această trăsătură, din moment ce orice închidere poate fi folosită. O închidere care permută valorile capturate din corpul propriu va implementa exclusivFnOnceși nicio altă trăsăturăFn, fiindcă poate fi utilizată doar o singură dată.FnMutse aplică pentru închiderile care nu permută valorile capturate din corpul lor, dar care pot modifica aceste valori capturate. Aceste închideri pot fi folosite de mai multe ori.Fnse aplică pentru închiderile care nu permută valorile capturate din corpul lor și nu modifică aceste valori capturate, precum și pentru închiderile care nu capturează nimic din propriul mediu. Astfel de închideri pot fi apelate de multiple ori fără a modifica mediul lor, lucru esențial în situații precum apelul multiplu simultan al unei închideri.
Să examinăm definiția metodei unwrap_or_else pentru Option<T> prezentată în Listarea 13-1:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Reamintim că T este tipul generic destinat valorii din varianta Some a unui Option. Același tip T este, de asemenea, tipul de retur al funcției unwrap_or_else: atunci când este apelată pe un Option<String>, spre exemplu, va returna un String.
Continuând, observăm că funcția unwrap_or_else introduce un tip generic suplimentar F. Acest tip F corespunde parametrului denumit f, care este închiderea utilizată atunci când se apelează unwrap_or_else.
Limita impusă tipului generic F este FnOnce() -> T, adică F trebuie să poată fi invocat o singură dată, fără argumente și să returneze un T. Prin utilizarea FnOnce în delimitarea de trăsătură, se specifică faptul că unwrap_or_else va apela f cel mult o singură dată. Analizând corpul funcției unwrap_or_else, rezultă că în cazul unei variante Some, funcția f nu este apelată. În contrast, dacă varianta este None, f va fi invocată o dată. Fiindcă toate închiderile implementează FnOnce, unwrap_or_else poate accepta cel mai larg spectru de închideri, fiind astfel extrem de flexibilă.
Notă: Funcțiile pot implementa, de asemenea, toate cele trei trăsături
Fn. Dacă demersul pe care doriți să-l executați nu necesită capturarea unei valori din mediu, puteți opta pentru numele unei funcții, în loc de o închidere, ori de câte ori este nevoie de ceva care implementează una din trăsăturileFn. De exemplu, pentru o valoareOption<Vec<T>>, am putea folosiunwrap_or_else(Vec::new)pentru a obține un vector nou și gol dacă valoarea respectivă esteNone.
Acum să analizăm metoda sort_by_key a bibliotecii standard, care este definită pe secțiuni (slice), pentru a înțelege cum diferă aceasta de unwrap_or_else și motivul pentru care sort_by_key recurge la FnMut în loc de FnOnce ca delimitare de trăsătură. Închiderea primește un argument sub formă de referință la elementul actual din secțiunea în curs de evaluare și returnează o valoare de tip K, care poate fi ordonată. Această funcție este practică atunci când intenționăm să sortăm o secțiune după un anumit atribut al elementelor sale. În Listarea 13-7, dispunem de o listă de instanțe Rectangle și utilizăm sort_by_key pentru a le sorta după atributul width, de la cel mai mic la cel mai mare:
Numele fișierului: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let mut list = [ Rectangle { width: 10, height: 1 }, Rectangle { width: 3, height: 5 }, Rectangle { width: 7, height: 12 }, ]; list.sort_by_key(|r| r.width); println!("{:#?}", list); }
Listarea 13-7: Utilizarea metodei sort_by_key pentru sortarea dreptunghiurilor în funcție de lățime
Codul afișează următoarea ieșire:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
width: 3,
height: 5,
},
Rectangle {
width: 7,
height: 12,
},
Rectangle {
width: 10,
height: 1,
},
]
sort_by_key este definită să accepte închideri de tip FnMut deoarece invocă închiderea de mai multe ori - câte o dată pentru fiecare element din secțiune. Închiderea |r| r.width nu captează, nu modifică și nu permută nimic din contextul său, îndeplinind astfel criteriile delimitării de trăsătură.
Pe de altă parte, în Listarea 13-8 este prezentat un exemplu de închidere care implementează doar trăsătura FnOnce, deoarece permută o valoare din context. Compilatorul nu ne permite să utilizăm acest tip de închidere cu metoda sort_by_key:
Numele fișierului: src/main.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("by key called");
list.sort_by_key(|r| {
sort_operations.push(value);
r.width
});
println!("{:#?}", list);
}Listarea 13-8: Tentativa de utilizare a unei închideri FnOnce cu sort_by_key
Aceasta este o încercare forțată și complicată (care nu funcționează) de a număra de câte ori sort_by_key este invocată în timpul sortării list. Codul încearcă să realizeze această contorizare prin adăugarea value—un String din contextul închiderii—în vectorul sort_operations. Închiderea preia value și apoi îl permută în afara închiderii transferând posesiunea lui value către vectorul sort_operations. Această închidere poate fi folosită doar o dată; o nouă încercare de a o apela nu ar funcționa pentru că value nu ar mai fi prezent în context pentru a fi adăugat din nou în sort_operations! Prin urmare, închiderea implementează exclusiv FnOnce. În momentul la care încercăm să compilăm acest cod, primim următoarea eroare cum că value nu poate fi permutat din închidere pentru că închiderea trebuie să implementeze FnMut:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let value = String::from("by key called");
| ----- captured outer variable
16 |
17 | list.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | sort_operations.push(value);
| ^^^^^ move occurs because `value` has type `String`, which does not implement the `Copy` trait
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` due to previous error
Eroarea indică spre linia din corpul închiderii unde value este permutat din context. Pentru a corecta acest lucru, trebuie să modificăm corpul închiderii astfel încât să nu mai permutăm valori din context. O metodă mai simplă și directă de a contoriza câte apeluri ale funcției sort_by_key se efectuează, este să păstrăm un contor în context și să-l incrementăm în corpul închiderii. Închiderea din Listarea 13-9 funcționează cu sort_by_key pentru că se limitează la capturarea unei referințe mutabile la contorul num_sort_operations, permițând astfel apelări multiple:
Numele fișierului: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let mut list = [ Rectangle { width: 10, height: 1 }, Rectangle { width: 3, height: 5 }, Rectangle { width: 7, height: 12 }, ]; let mut num_sort_operations = 0; list.sort_by_key(|r| { num_sort_operations += 1; r.width }); println!("{:#?}, sorted in {num_sort_operations} operations", list); }
Listarea 13-9: Folosirea unei închideri FnMut împreună cu sort_by_key este acceptată
Trăiturile Fn sunt cruciale atunci când definim sau folosim funcții sau tipuri care exploatează închideri. În următoarea secțiune, ne vom axa pe iteratori. Diverse metode ale iteratorilor solicită argumente sub formă de închideri, deci nu uita aceste detalii legate de închideri în timp ce mergem mai departe!
[unwrap-or-else]: ../std/option/enum.Option.html#method.unwrap_or_else
Procesarea unei serii de elemente cu ajutorul iteratorilor
Modelul iterator permite efectuarea unei anumite sarcini pe o secvență de elemente, unul câte unul. Un iterator este responsabil de logica parcurgerii fiecărui element și stabilirea momentului în care secvența este completă. Când folosești iteratori, nu este necesar să reimplementezi tu această logică.
În Rust, iteratorii sunt indolenți (lazy), adică nu produc niciun efect până nu apelezi metode care consumă iteratorul pentru utilizare. De exemplu, codul din Listarea 13-10 creează un iterator pentru elementele din vectorul v1 prin apelarea metodei iter, definită pe Vec<T>. Acest cod în sine nu realizează nimic util.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); }
Listarea 13-10: Crearea unui iterator
În variabila v1_iter este stocat iteratorul. După ce un iterator a fost creat, putem să-l utilizăm în diferite moduri. În Listarea 3-5 din Capitolul 3, am itinerat peste un array folosind o buclă for pentru a executa un cod pe fiecare element. În realitate, acest lucru a creat și consumat implicit un iterator, dar nu am detaliat cum funcționează acest proces până acum.
În exemplul din Listarea 13-11, crearea iteratorului este separată de utilizarea lui în bucla for. Când bucla for folosește iteratorul v1_iter, fiecare element din iterator participă la o iterație a buclei, imprimând astfel fiecare valoare.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); for val in v1_iter { println!("Got: {}", val); } }
Listarea 13-11: Utilizarea unui iterator într-o buclă for
În limbajele de programare care nu dispun de iteratori în bibliotecile lor standard, probabil ai scrie aceeași funcționalitate inițializând o variabilă la indexul 0, utilizând această variabilă pentru a accesa elementele din vector și incrementând valoarea variabilei într-o buclă până la atingerea numărului total de elemente din vector.
Iteratorii se ocupă de toată această logică pentru tine, minimizând codul repetitiv care ar putea fi și greșit. Aceștia oferă o flexibilitate sporită pentru a aplica aceeași logică la diferite tipuri de secvențe, nu doar la structuri de date indexabile, precum vectorii. Acum să explorăm cum realizează iteratorii acest lucru.
Trăsătura Iterator și metoda next
Toți iteratorii implementează o trăsătură denumită Iterator definită în biblioteca standard. Definiția acestei trăsături este următoarea:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // metodele cu implementări predefinite au fost omise } }
Această definiție introduce o sintaxă nouă: type Item și Self::Item, care stabilește un tip asociat trăsăturii. Vom aborda tipurile asociate în detaliu în Capitolul 19. Deocamdată, e important să știm că, pentru a implementa trăsătura Iterator, trebuie definit și un tip Item, care este utilizat în tipul de retur al metodei next, adică tipul Item va fi tipul de date returnat de iterator.
Trăsătura Iterator necesită de la cei ce o implementează să definească o singură metodă: next, care returnează câte un element al iteratorului învelit în Some, iar când iterația s-a încheiat, returnează None.
Metoda next poate fi apelată direct pe iteratori; Listarea 13-12 ilustrează valorile returnate de apeluri multiple la next pe iteratorul creat din vector.
Numele fișierului: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}Listarea 13-12: Apelarea metodei next pe un iterator
Trebuie să remarcăm că a fost necesar să facem v1_iter mutabil: invocarea metodei next pe un iterator modifică starea internă pe care acesta o utilizează pentru a urmări poziția curentă în secvență. Practic, acest cod consumă iteratorul. Fiecare chemare a lui next consumă un element din iterator. Când folosim o buclă for, nu este nevoie să facem v1_iter mutabil deoarece bucla preia posesiunea lui v1_iter și îl face mutabil în mod implicit.
Mai trebuie să observăm că valorile obținute din apelurile la next sunt referințe imutabile la elementele din vector. Metoda iter creează un iterator de referințe imutabile. Dacă vrem un iterator care să preia posesiunea v1 și să returneze valori proprii, putem folosi metoda into_iter în loc de iter. În mod similar, pentru a itera peste referințe mutabile, putem utiliza iter_mut în locul lui iter.
Metode care consumă iteratorul
Trăsătura Iterator include o serie de metode diferite cu implementări default furnizate de biblioteca standard; poți afla mai multe despre aceste metode consultând documentația API pentru trăsătura Iterator. Câteva dintre aceste metode folosesc next în definiția lor, de aceea este necesar să implementezi metoda next când realizezi implementarea trăsăturii Iterator.
Metodele care invocă next sunt denumite adaptoare consumatoare, deoarece utilizarea lor epuizează iteratorul. Un exemplu este metoda sum, care își asumă posesiunea iteratorului și parcurge elementele prin apeluri repetate ale next, consumând în acest fel iteratorul. În timpul iterării, adaugă fiecare element la un total acumulat și returnează acest total la finalizarea iterației. Listarea 13-13 prezintă un test care ilustrează folosirea metodei sum:
Numele fișierului: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}Listarea 13-13: Utilizarea metodei sum pentru a calcula suma totală a elementelor din iterator
Nu ne este permis să utilizăm v1_iter după apelul la sum, deoarece sum preia posesiunea iteratorului pe care îl apelăm.
Metode ce generează alți iteratori
Adaptoarele de iterator sunt metode definite pe trăsătura Iterator care nu consumă iteratorul. În loc de asta, ele generează alți iteratori modificând anumite aspecte ale iteratorului original.
Listarea 13-14 prezintă un exemplu de utilizare a metodei adaptor de iterator map, care primește o închidere ce este apelată pentru fiecare element în timp ce sunt iterați. Metoda map returnează un nou iterator ce produce elementele modificate. În acest caz, închiderea creează un nou iterator unde fiecare element din vector va fi mărit cu o unitate:
Numele fișierului: src/main.rs
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; v1.iter().map(|x| x + 1); }
Listarea 13-14: Utilizarea adaptorului de iterator map pentru a genera un nou iterator
Cu toate acestea, acest cod generează un avertisment:
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
warning: `iterators` (bin "iterators") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
Codul din Listarea 13-14 de fapt nu realizează nimic; închiderea pe care am specificat-o nu este invocată niciodată. Avertismentul ne reamintește motivul: adaptoarele de iterator sunt evaluate indolent și trebuie să consumăm iteratorul aici.
Pentru a corecta acest avertisment și a consuma iteratorul, ne vom folosi de metoda collect, aceeași pe care am utilizat-o în Capitolul 12 cu env::args în Listarea 12-1. Această metodă consumă iteratorul și colectează valorile obținute într-o structură de tip colecție.
În Listarea 13-15, noi colectăm rezultatele iterației peste noul iterator rezultat din apelul la map într-un vector. Acest vector va conține în final fiecare element din vectorul inițial incrementat cu 1.
Numele fișierului: src/main.rs
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; let v2: Vec<_> = v1.iter().map(|x| x + 1).collect(); assert_eq!(v2, vec![2, 3, 4]); }
Listarea 13-15: Utilizarea metodei map pentru a genera un nou iterator și apoi utilizarea metodei collect pentru a consuma acest iterator nou și a crea un vector
Deoarece map primește o închidere, putem defini orice operație dorim să efectuăm asupra fiecărui element. Aceasta este o ilustrație excelentă a modului în care închiderile îți permit să personalizezi anumite comportamente în timp ce refolosești comportamentul de iterație pe care trăsătura Iterator îl furnizează.
Putem combina mai multe apeluri către adaptoarele de iteratori pentru a efectua acțiuni complexe într-un mod inteligibil. Totuși, fiindcă toți iteratorii sunt evaluați indolent, e necesar să folosim una dintre metodele adaptoare consumatoare pentru a obține rezultate din apelurile către adaptoare de iteratori.
Folosirea închiderilor pentru captarea variabilelor din context
Adaptoarele de iteratori folosesc des închideri ca parametri. De obicei, închiderile pe care urmează să le specificăm pentru aceste adaptoare sunt cele care captează variabilele din contextul lor.
În exemplul nostru, vom apela la metoda filter, care acceptă o închidere. Aceasta primește fiecare element din iterator și returnează un bool. Dacă închiderea evaluează la true, elementul va fi inclus în seria de date generată de filter. Pe de altă parte, dacă închiderea evaluează la false, elementul nu va fi inclus.
În Listarea 13-16, folosim filter împreună cu o închidere care include variabila shoe_size din context, pentru a itera prin colecția de structuri Shoe, furnizând doar pantofii care au o anumită mărime.
Numele fișierului: src/lib.rs
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}Listarea 13-16: Utilizarea metodei filter cu o închidere care capturează variabila shoe_size
Funcția shoes_in_size preia un vector de pantofi și o mărime a pantofului ca parametri. Ea returnează un vector care cuprinde exclusiv pantofi cu mărimea specificată.
În corpul funcției shoes_in_size, creăm un iterator prin apelarea into_iter, care preia vectorul. Următorul pas este aplicarea filter la acest iterator, transformându-l într-un nou iterator care va conține doar elementele pentru care închiderea evaluează la true.
Închiderea folosită captează parametrul shoe_size din context și îl compară cu mărimea fiecărui pantof, selectând doar pantofii care conform cu măsura specificată. Finalizând cu collect, agregăm valorile filtrate de iterator într-un vector care este apoi returnat de funcție.
Testul nostru confirmă că, după apelarea funcției shoes_in_size, rezultatul conține doar pantofii având mărimea egală cu cea specificată inițial.
Îmbunătățim proiectul nostru I/O
Grație cunoștințelor noastre recent dobândite despre iteratori, avem posibilitatea să perfecționăm proiectul I/O din Capitolul 12 prin utilizarea iteratorilor, pentru a face codul nu doar mai concis, dar și mai ușor de înțeles. Analizăm modul în care iteratorii pot optimiza implementarea funcției Config::build și a funcției search.
Înlăturăm un clone cu ajutorul unui iterator
În Listarea 12-6, am introdus cod care procesa o secțiune de String și care iniția o instanță a structurii Config, apelând la indexarea secțiunii și clonarea valorilor, pentru a-i permite structurii Config să aibă propriile valori. În Listarea 13-17, reprezentăm implementarea funcției Config::build așa cum era în Listarea 12-23:
Numele fișierului: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listarea 13-17: Reconstituirea funcției Config::build din Listarea 12-23
Inițial, am menționat că nu trebuie să ne preocupăm de ineficiența apelurilor clone, deoarece aveam de gând să le eliminăm ulterior. Acest moment a venit.
Ne-am văzut nevoiți să utilizăm clone deoarece avem o secțiune cu elemente String în parametrul args, iar funcția build nu avea posesiunea asupra args. Pentru a putea returna o instanță Config care să-și posede propriile valori, a fost necesar să clonăm valorile din câmpurile query și file_path ale structurii Config.
Înarmați cu înțelegerea nouă despre iteratori, putem modifica funcția build astfel încât să preia un iterator, și nu o secțiune (împrumutată) drept argument, preluând posesiunea acestuia. Vom aplica funcționalităţile iteratorului în locul verificării lungimii secțiunii și a indexărilor. Acest lucru va clarifica intențiile funcției Config::build prin utilizarea iteratorului care va parcurge valorile în mod direct.
Odată ce Config::build va prelua posesiunea iteratorului și va renunța la operațiuni de indexare ce presupun împrumuturi, vom putea transfera valorile String direct din iterator în Config, eliminând astfel necesitatea de a apela clone și de a crea alocări suplimentare.
Utilizăm direct iteratorul returnat
Deschide fișierul src/main.rs din proiectul de I/O, care ar trebui să arate în felul următor:
Numele fișierului: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}În primul rând, vom modifica începutul funcției main pe care l-am prezentat în Listarea 12-24, aplicând în schimb codul din Listarea 13-18, care de această dată implică utilizarea unui iterator. Codul nu va compila până nu efectuăm o actualizare și a funcției Config::build.
Numele fișierului: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}Listarea 13-18: Predarea valorii de retur a env::args către Config::build
Funcția env::args returnează un iterator! În loc de a colecta valorile iteratorului într-un array și apoi de a transmite o secțiune către Config::build, acum predăm direct posesiunea iteratorului rezultat din env::args către Config::build.
Următorul pas este actualizarea definiției Config::build. În fișierul src/lib.rs al proiectului de I/O, modificăm semnătura Config::build astfel încât să corespundă Listării 13-19. Totuși, acesta nu va compila deoarece este necesar să actualizăm și corpul funcției.
Numele fișierului: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listarea 13-19: Actualizarea semnăturii metodei Config::build pentru a accepta un iterator
Documentația bibliotecii standard pentru funcția env::args indică faptul că tipul iteratorului returnat este std::env::Args, iar acest tip implementează trăsătura Iterator și returnează obiecte de tip String.
Semnătura metodei Config::build a fost actualizată astfel încât parametrul args să fie de un tip generic cu delimitările de trăsătură impl Iterator<Item = String>, în loc de &[String]. Această folosire a sintaxei impl Trait pe care am discutat-o în secțiunea „Trăsături ca parametri” din Capitolul 10 sugerează că args poate fi de orice tip care implementează tipul Iterator și returnează elemente de tip String.
Întrucât preluăm posesiunea args și intenționăm să modificăm args iterând peste acesta, putem introduce cuvântul cheie mut în definiția parametrului args pentru a-l face mutabil.
Folosim metodele trăsăturii Iterator în locul indexării
Acum vom corecta corpul funcției Config::build. Dat fiind faptul că args implementează trăsătura Iterator, știm că putem apela metoda next asupra-i! Listarea 13-20 actualizează codul din Listarea 12-23 pentru a utiliza metoda next:
Numele fișierului: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listarea 13-20: Modificarea corpului lui Config::build pentru utilizarea metodelor iteratorului
Să ne amintim că prima valoare în afișajul returnat de env::args este numele programului. Dorim să ignorăm acesta și să accesăm următoarea valoare, prin urmare inițial apelăm next fără să utilizăm valoarea returnată. Apoi, apelăm next pentru a extrage valoarea pe care intenționăm s-o alocăm câmpului query din Config. Dacă next întoarce un Some, folosim un match pentru a extrage valoarea dorită. Dacă întoarce None, acest lucru sugerează că nu s-au furnizat destule argumente și întrerupem procesarea anticipat, returnând o valoare de tip Err. Procedăm similar și pentru valoarea file_path.
Clarificăm codul cu ajutorul adaptoarelor de iteratori
De asemenea, putem utiliza iteratorii și în funcția search din proiectul nostru de I/O, reprodusă aici în Listarea 13-21, exact cum a apărut în Listarea 12-19:
Numele fișierului: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Listarea 13-21: Implementarea funcției search din Listarea 12-19
Folosind metode adaptoare de iteratori, putem rescrie codul într-un mod mai succint. Aceasta ne permite, de asemenea, să evităm utilizarea unui vector intermediar mutabil results. Programarea funcțională preferă să minimizeze cât mai mult posibil stările mutabile, pentru a crește claritatea codului. Eliberând codul de starea mutabilă, s-ar putea deschide posibilitatea de a îmbunătăți funcția search, permițând căutarea să se desfășoare în paralel, deoarece nu va mai fi nevoie să gestionăm accesul concurent la vectorul results. În Listarea 13-22 este prezentată această modificare:
Numele fișierului: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Listarea 13-22: Aplicarea metodelor adaptoare de iteratori în implementarea funcției search
Reamintim că scopul funcției search este de a returna toate liniile din contents care conțin termenul query. Similar cu exemplul filter din Listarea 13-16, aici utilizăm adaptorul filter pentru a selecta doar liniile care, după apelul line.contains(query), returnează true. Acestea sunt apoi agregate într-un alt vector prin metoda collect. Mult mai simplu! Aplică aceeași metodă, folosind adaptoare de iteratori și pentru funcția search_case_insensitive.
Alegerem între bucle și iteratori
Întrebarea care se ridică este ce stil ar trebui să adoptăm în codul nostru și care este motivația alegerii: implementarea originală din Listarea 13-21 sau versiunea cu iteratori din Listarea 13-22. Majoritatea programatorilor Rust optează pentru utilizarea stilului cu iteratori. Deși la început poate părea mai dificil, odată ce te obișnuiești cu adaptoarele pentru iteratori și cu rolul lor, codul cu iteratori poate deveni mult mai intuitiv. În loc să ajustezi detaliile buclelor și să construiești noi array-uri, codul se focalizează asupra obiectivului principal al buclei. Acest lucru face codul mai abstract, ușurând identificarea conceptelor specifice acestui cod, precum condiția de filtrare pe care trebuie să o îndeplinească fiecare element în cadrul iteratorului.
Cu toate acestea, sunt cele două implementări de fapt echivalente? Ar putea fi tentant să presupunem că bucla mai de nivel scăzut este mai rapidă. Să examinăm aspectele legate de performanță.
Comparând performanța buclelor și a iteratorilor
Pentru a decide folosirea buclelor sau a iteratorilor, trebuie să determinăm care implementare este mai eficientă: versiunea funcției search ce utilizează o buclă for explicită sau versiunea ce se bazează pe iteratori.
Am efectuat un benchmark, încărcând întregul text al cărții The Adventures of Sherlock Holmes de Sir Arthur Conan Doyle într-un String și căutând cuvântul the în conținut. Iată rezultatele benchmark-ului pentru versiunea search folosind ciclul for și versiunea cu iteratori:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
Versiunea cu utilizarea iteratorilor a fost ușor mai rapidă! Nu vom detalia aici codul folosit în benchmark, deoarece scopul nu este să demonstrăm că cele două versiuni sunt identice ca funcționalitate, ci să înțelegem cum se compară la general cele două implementări ca performanță.
Pentru un benchmark mai amplu, ar fi indicat să folosim texte de dimensiuni variate ca contents, cu cuvinte diferite și de lungimi variate ca query, împreună cu alte multiple variații. Ideea principală este următoarea: deși reprezintă o abstracție de nivel înalt, iteratorii din Rust sunt compilați în cod foarte similar cu cel scris manual la un nivel jos. Aceștia sunt exemple ale abstracțiilor cu cost zero în Rust, prin care înțelegem că utilizarea abstracției nu adaugă supra-costuri la timpul de rulare. Conceptul dat este asemănător cu modul în care Bjarne Stroustrup, inițiatorul limbajului C++, definește noțiunea fără surplus de costuri în lucrarea sa "Foundations of C++" (2012):
În general, implementările C++ respectă principiul zero supra-cost: dacă nu folosești ceva, nu plătești pentru acesta. Și mai mult: ceea ce folosești nu ai cum să codezi manual într-un mod mai eficient.
Ca un alt exemplu, porțiunea de cod de mai jos provine dintr-un decodor audio. Algoritmul de decodare folosește operațiunea matematică de predicție liniară pentru a estima valorile viitoare bazându-se pe o funcție liniară a mostrelor anterioare. Acest cod utilizează o serie de iteratori pentru a efectua calcule asupra a trei variabile din domeniul de vizibilitatea: o secțiune buffer de date, un array cu 12 coefficients și o valoare care indică cu cât se deplasează datele în qlp_shift. Variabilele sunt declarate în acest exemplu, însă nu li s-au atribuit valori; chiar dacă acest cod nu are mult sens fără contextul său, reprezintă totuși un exemplu concret și realist al modului în care Rust transformă idei complexe în cod de nivel jos.
let buffer: &mut [i32];
let coefficients: [i64; 12];
let qlp_shift: i16;
for i in 12..buffer.len() {
let prediction = coefficients.iter()
.zip(&buffer[i - 12..i])
.map(|(&c, &s)| c * s as i64)
.sum::<i64>() >> qlp_shift;
let delta = buffer[i];
buffer[i] = prediction as i32 + delta;
}Pentru a calcula valoarea prediction, codul iterează prin fiecare dintre cele 12 valori din coefficients și aplică metoda zip pentru a forma perechi între valorile coeficienților și cele 12 mostre anterioare din buffer. Apoi, pentru fiecare pereche, se înmulțesc valorile între ele, se sumează toate rezultatele și suma rezultată este deplasată qlp_shift biți spre dreapta.
În aplicațiile precum decodoarele audio, calculele pun adesea întâietate pe performanță. În exemplul nostru, construim un iterator, utilizăm două adaptoare și apoi consumăm valoarea. În ce cod assembly va transforma codul Rust? Până la acest moment, se compilează în assembly-ul pe care l-ai scrie și manual. Nu există o buclă care să corespundă iterației peste coefficients: Rust recunoaște cele 12 iterații, așa că efectuează o „desfășurare” (unroll) a buclei. Desfășurarea este o optimizare care elimină supra-costul codului de control al buclei și generează, în schimb, cod repetitiv pentru fiecare iterație.
Toți coeficienții sunt stocați în registre, ceea ce facilitează un acces rapid la valori. La executarea codului nu sunt efectuate verificări de limită pentru array. Toate optimizările aplicate de Rust fac codul extrem de eficient. Având această cunoaștere, poți folosi iteratori și închideri fără nicio reținere! Ele fac codul să pară de un nivel înalt și nu aduc un cost adițional de performanță la execuție.
Sumar
Închiderile și iteratorii sunt caracteristici ale Rust inspirate din conceptele limbajelor de programare funcționale. Ele contribuie la abilitatea limbajului Rust de a exprima idei complexe într-un mod clar, menținând totodată performanțe specifice codului de nivel jos. Implementările închiderilor și a iteratorilor sunt concepute în așa fel încât să nu afecteze performanța la runtime. Aceasta este parte a scopului Rust de a furniza abstracții fără un extra-cost.
Acum că am îmbunătățit expresivitatea proiectului nostru I/O, să examinăm unele funcționalități suplimentare ale cargo care ne vor ajuta să distribuim proiectul cu întreaga lume.
Mai multe informații despre Cargo și Crates.io
Până în prezent, am utilizat caracteristicile fundamentale ale Cargo pentru a construi, executa și testa codul nostru. Totuși, Cargo dispune de mult mai multe. În acest capitol, vom explora câteva dintre aceste posibilități avansate, pentru a afla cum putem efectua următoarele acțiuni:
- Personalizăm procesul de build prin utilizarea profilurilor de release
- Publicăm bibliotecile pe crates.io
- Gestionăm proiecte extinse utilizând workspaces
- Instalăm pachete binare de pe crates.io
- Extindem capacitatea de a lucra cu Cargo adăugând comenzi personalizate
Posibilitățile oferite de Cargo sunt mai vaste decât cele prezentate în acest capitol, de aceea, pentru o înțelegere completă a întregului spectru de funcții, vă recomand să consultați documentația oficială.
Personalizarea build-urilor cu profile de release
În Rust, profilele de release (release profiles) sunt profile predefinite și customizabile care oferă programatorului control sporit asupra diverselor opțiuni de compilare. Fiecare profil este configurat independent față de celelalte.
Cargo pune la dispoziție două profile principale: profilul dev, activat de Cargo la executarea comenzii cargo build, și profilul release, folosit de Cargo când lansezi cargo build --release. Profilul dev este setat cu valori implicite optimizate pentru dezvoltare, iar profilul release are valori implicite optimizate pentru versiunile de publicare finală.
S-ar putea să recunoști aceste nume de profile din afișajele build-urilor efectuate:
$ cargo build
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
$ cargo build --release
Finished release [optimized] target(s) in 0.0s
dev și release sunt aceste profile diferite utilizate de compilatorul Rust.
Cargo are o serie de setări standard pentru fiecare profil, care intră în vigoare dacă nu există secțiuni [profile.*] definite explicit în fișierul Cargo.toml. Personalizând secțiunile [profile.*], poți modifica orice subansamblu din aceste setări standard. Iată valorile implicite pentru setarea opt-level ale profilelor dev și release:
Filename: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
Parametrul opt-level determină numărul de optimizări aplicate codului tău de către Rust, cu o gamă de la 0 la 3. Aplicarea mai multor optimizări prelungește timpul de compilare, de aceea, în faza de dezvoltare unde codul este compilat frecvent, este de preferat să folosești mai puține optimizări pentru a avea un timp de compilare scurt, chiar dacă codul executabil va fi mai lent. Prin urmare, valoarea implicită a opt-level pentru profilul dev este 0. În schimb, când ești pregătit să lansezi codul, este recomandat să aloci mai mult timp compilării. Codul în modul release va fi compilat o singură dată, însă va fi rulat de nenumărate ori, preferându-se astfel un timp de compilare mai mare pentru a obține un cod executabil mai rapid. Din acest motiv, valoarea implicită pentru opt-level în profilul release este 3.
Poți modifica o setare implicită adăugând o valoare diferită în Cargo.toml. Să zicem că dorim să utilizăm nivelul de optimizare 1 în profilul de dezvoltare. În acest caz, putem adăuga următoarele două linii în fișierul Cargo.toml al proiectului:
Numele fișierului: Cargo.toml
[profile.dev]
opt-level = 1
Codul de mai sus suprascrie setarea implicită de 0. Acum, la executarea comenzii cargo build, Cargo va implementa valorile implicite ale profilului dev împreună cu ajustarea făcută de noi la opt-level. Setând opt-level la valoarea 1, Cargo va aplica mai multe optimizări decât cele implicite, dar mai puține decât într-o compilare destinată profilului release.
Pentru lista completă a opțiunilor de configurare și a valorilor implicite pentru fiecare profil, consultă documentația Cargo.
Publicarea unui crate pe crates.io
Folosim crate-uri de pe crates.io ca dependențe pentru proiectul nostru, dar poți de asemenea să-ți împărtășești codul cu alți programatori publicând propriile crate-uri. Registrul de crate-uri de pe crates.io difuzează codul sursă al pachetelor tale, găzduind în principal cod open source.
Rust și Cargo dispun de caracteristici care fac mai ușoară găsirea și utilizarea crate-ului tău publicat de către alții. Vom vorbi în continuare despre unele dintre aceste caracteristici și apoi vom explica cum se publică un crate.
Crearea de comentarii documentație utile
Documentarea corectă a pachetelor voastre va ajuta alți utilizatori să înțeleagă cum și când să le folosească, de aceea este important să alocați timp pentru a redacta documentația. În Capitolul 3, am învățat cum se pot adăuga comentarii codului Rust folosind //. Rust oferă de asemenea un tip special de comentariu pentru documentație, cunoscut ca comentariu de documentație, ce generează documentație în format HTML. HTML-ul prezintă conținutul comentariilor de documentație pentru elementele API publice, orientate către programatori interesați să cunoască modul în care pot utiliza crate-ul dumneavoastră, nu neapărat cum este el implementat.
Comentariile de documentație folosesc trei slash-uri, ///, în locul celor două și permit folosirea notației Markdown pentru formatarea textelor. Aceste comentarii de documentație se plasează imediat înaintea elementului documentat. Listarea 14-1 prezintă comentariile de documentație pentru funcția add_one dintr-un crate denumit my_crate.
Numele fișierului: src/lib.rs
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Listarea 14-1: Un comentariu de documentație pentru o funcție
Aici, descriem funcționalitatea funcției add_one, demarăm o secțiune cu titlul Examples și furnizăm cod ce exemplifică modul de utilizare al funcției add_one. Putem crea documentația HTML aferentă acestui comentariu de documentație executând comanda cargo doc. Această comandă pornește instrumentul rustdoc care vine odată cu instalarea Rustului și plasează documentația HTML generată în directorul target/doc.
Pentru a facilita accesul, executând cargo doc --open va construi documentația HTML pentru crate-ul curent (inclusiv documentația pentru toate dependențele crate-ului) și va deschide rezultatul într-un navigator web. Navigând către funcția add_one, veți observa cum este randat textul din comentariile de documentație, așa cum se observă în Figura 14-1:
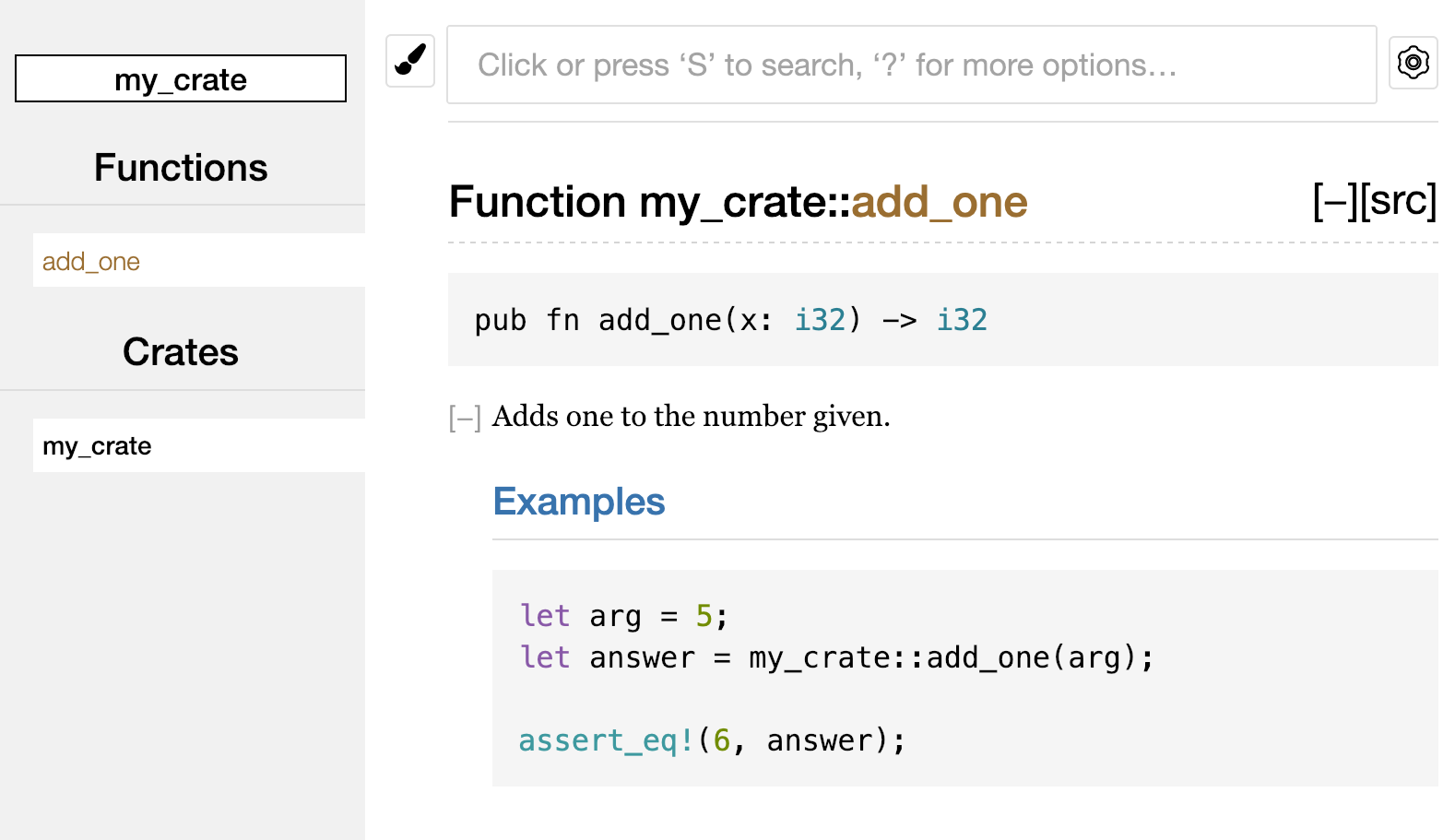
Figura 14-1: Documentația HTML pentru funcția add_one
Secțiuni comun utilizate
Am folosit antetul Markdown # Examples în Listarea 14-1 pentru a crea o secțiune în HTML cu titlul "Examples". Alte secțiuni comune pe care autorii de crate-uri le includ în documentațiile lor sunt:
- Panics: Situațiile în care funcția descrisă ar putea provoca o panică. Cei care apelează funcția trebuie să se asigure că nu o fac în aceste condiții, pentru a evita erori critice în programul lor.
- Errors: Dacă funcția returnează un
Result, este util pentru apelanți să cunoască tipurile de erori posibile și condițiile care le-ar putea cauza, astfel încât să poată gestiona corespunzător fiecare tip de eroare. - Safety: În cazul unei funcții marcate ca
unsafe(ceea ce vom aborda în Capitolul 19), este important să existe o secțiune care explică motivele pentru care funcția este considerată nesigură și care sunt invarianții pe care funcția îi presupune respectați de către apelanți.
Nu este necesar ca toate secțiunile de documentație să fie prezente, dar această listă poate servi ca o reamintire utilă despre elementele codului care ar putea fi de interes utilizatorilor.
Comentarii de documentație ca teste
Includerea exemplelor de cod în comentariile de documentație poate ilustra cum să fie folosită biblioteca ta, iar un avantaj suplimentar este că, atunci când rulezi cargo test, exemplele de cod din comentariile tale vor fi executate ca teste! Nu există ceva mai util decât documentație însoțită de exemple. Totodată, nu există ceva mai problematic decât exemple care nu funcționează pentru că s-a modificat codul de la scrierea documentației. Dacă executăm cargo test cu documentația pentru funcția add_one prezentată în Listarea 14-1, vom observa în rezultatele testelor o secțiune similară cu aceasta:
Doc-tests my_crate
running 1 test
test src/lib.rs - add_one (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Dacă acum schimbăm fie funcția, fie exemplul, astfel încât assert_eq! din exemplu să producă panică și executăm cargo test din nou, vom constata că testele din documentație detectează neconcordanța dintre exemplu și cod!
Comentarea elementelor încapsulate
Stilul de comentariu doc //! adaugă documentație la elementul care include comentariile în loc să le adauge la cele care urmează după comentarii. Folosim aceste comentarii doc în mod obișnuit în interiorul fișierului rădăcină al crate-ului (src/lib.rs conform convenției) sau în cadrul unui modul pentru a documenta întregul crate sau modul.
De exemplu, pentru a adăuga documentație care descrie scopul crate-ului my_crate, care conține funcția add_one, inserăm comentarii de documentație începând cu //! la începutul fișierului src/lib.rs, așa cum este arătat în Listarea 14-2:
Numele fișierului: src/lib.rs
//! # My Crate
//!
//! `my_crate` is a collection of utilities to make performing certain
//! calculations more convenient.
/// Adds one to the number given.
// --snip--
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Listarea 14-2: Documentația pentru crate-ul my_crate ca întreg
Remarcăm faptul că nu se găsește niciun cod după ultima linie care începe cu //!. Alegând să începem comentariile cu //! și nu cu ///, ne-am documentat elementul care conține acest comentariu și nu un element care ar urma după comentariu. În acest caz, respectivul element este fișierul src/lib.rs, rădăcina crate-ului. Aceste comentarii descriu crate-ul în totalitatea sa.
Când rulăm cargo doc --open, aceste comentarii vor fi vizibile pe pagina principală a documentației my_crate, plasate deasupra listei de elemente publice ale crate-ului, așa cum putem observa în Figura 14-2:
Figura 14-2: Documentația generată pentru my_crate, incluzând comentariul ce descrie crate-ul în întregime
Comentariile de documentație din interiorul elementelor sunt deosebit de utile pentru descrierea crate-urilor și modulelor. Le utilizăm pentru a clarifica scopul general al containerului, facilitând astfel înțelegerea organizării crate-ului de către utilizatori.
Exportarea unui API public și accesibil cu pub use
Structura API-ului public este esențială atunci când vine vorba de publicarea unui crate. Utilizatorii acestuia pot avea dificultăți în a localiza componentele dorite, mai ales dacă structura de module este labirintică.
În Capitolul 7, am explicat cum să facem elemente publice folosind cuvântul cheie pub și cum să le importăm într-un domeniu de vizibilitate cu use. Dar structura internă pe care ai dezvoltat-o ar putea să nu fie prea accesibilă pentru utilizatori. De exemplu, dacă ai structuri aranjate după o ierarhie complexă, utilizatorii s-ar putea să nu descopere ușor anumite tipuri de date sau să fie deranjați de necesitatea de a folosi o cale lungă de module: use my_crate::some_module::another_module::UsefulType; în loc de use my_crate::UsefulType;.
Norocul este că, dacă structura internă nu este convenabilă utilizatorilor din alte librării, nu e nevoie să o reorganizezi. În schimb, poți re-exporta elemente pentru a crea o structură publică diferită folosind pub use. Această tehnică permite ca elementele publice dintr-un loc să fie disponibile într-un altul, ca și cum ar fi fost definite acolo.
Să ne imaginăm, de exemplu, că am dezvoltat o bibliotecă numită art pentru reprezentarea conceptelor artistice. În interiorul acesteia avem două module: kinds, care conține două enumerări, PrimaryColor și SecondaryColor, și utils cu funcția mix, așa cum este prezentat în Listarea 14-3:
Numele fișierului: src/lib.rs
//! # Art
//!
//! A library for modeling artistic concepts.
pub mod kinds {
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
unimplemented!();
}
}Listarea 14-3: Biblioteca art cu elementele organizate în modulele kinds și utils
Figura 14-3 ilustrează cum arată pagina principală a documentației pentru crate-ul art, generată de cargo doc:
Figura 14-3: Pagina principală a documentației pentru art, care prezintă modulele kinds și utils
Remarcăm că tipurile PrimaryColor și SecondaryColor nu sunt prezentate pe pagina principală, nici funcția mix. Trebuie să selectăm modulele kinds și utils pentru a le vedea.
Pentru a utiliza această bibliotecă, un alt crate ar necesita declarații use care să includă elementele din art în domeniul de vizibilitate, specificând structura modulară curent definită. Listarea 14-4 demonstrează un exemplu de crate care integrează elementele PrimaryColor și mix din crate-ul art:
Numele fișierului: src/main.rs
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}Listarea 14-4: O crate care integrează elementele din crate-ul art cu structura sa internă expusă
Autorul codului prezentat în Listarea 14-4, care utilizează crate-ul art, a fost nevoit să descifreze că PrimaryColor este parte din modulul kinds și mix din modulul utils. Structura modulară a crate-ului art este mai semnificativă pentru cei care dezvoltă art decât pentru utilizatorii săi. Structura internă nu furnizează informații utile pentru cineva care dorește să învețe cum să folosească art, ci mai degrabă creează confuzie, fiind necesar ca dezvoltatorii să deducă locațiile specifice și să specifice modulele în declarațiile use.
Pentru a îndepărta organizarea internă din API-ul public, putem ajusta codul crate-ului art din Listarea 14-3 prin adăugarea de declarații pub use care re-exportă elementele la nivelul cel mai de sus, așa cum este prezentat în Listarea 14-5:
Numele fișierului: src/lib.rs
//! # Art
//!
//! A library for modeling artistic concepts.
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
// --snip--
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Orange
}
}Listarea 14-5: Adăugarea de declarații pub use pentru re-exportarea elementelor
Documentația API creată de cargo doc pentru acest crate va prezenta acum re-exportările pe pagina de start, după cum se poate vedea în Figura 14-4, facilitând găsirea tipurilor PrimaryColor și SecondaryColor și a funcției mix.
Figura 14-4: Pagina de start a documentației pentru art care afișează re-exportările
Utilizatorii crate-ului art încă pot vedea și utiliza structura internă din Listarea 14-3 așa cum este ilustrat în Listarea 14-4, sau pot opta pentru structura mai accesibilă din Listarea 14-5, așa cum este exemplificat în Listarea 14-6:
Numele fișierului: src/main.rs
use art::mix;
use art::PrimaryColor;
fn main() {
// --snip--
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}Listarea 14-6: Un program care utilizează elementele re-exportate din crate-ul art
Atunci când avem de-a face cu multe module încapsulate, re-exportarea tipurilor la nivelul cel mai de sus folosind pub use poate îmbunătăți semnificativ experiența utilizatorilor crate-ului. O altă practică frecventă a pub use este re-exportarea definițiilor unei dependențe în crate-ul actual, pentru a integra definițiile acelui crate în API-ul public al propriului crate.
Elaborarea unei structuri a API-ului public eficiente este mai degrabă o artă decât o știință, și multe ori e nevoie de a itera asupra ei pentru a dezvolta API-ul care răspunde cel mai bine nevoilor utilizatorilor tăi. Folosirea pub use permite flexibilitate în structurarea internă a crate-ului tău și separă acea structură internă de ceea ce oferi utilizatorilor tăi. Examinează codul din unele crate-uri pe care le-ai instalat pentru a observa dacă structura lor internă se diferențiază de API-ul public.
Configurarea unui cont pe crates.io
Pentru a publica crate-uri, trebuie mai întâi să îți creezi un cont pe crates.io și să obții o cheie (token) de API. Pentru aceasta, accesează pagina principală crates.io și conectează-te folosind un cont de GitHub. (Deocamdată este obligatoriu să folosești un cont de GitHub, dar pe viitor s-ar putea adăuga și alte metode de înregistrare.) După autentificare, mergi la setările contului tău accesând https://crates.io/me/ și copie-ți cheia API. În continuare, execută comanda cargo login cu cheia ta API, după cum urmează:
$ cargo login abcdefghijklmnopqrstuvwxyz012345
Această comandă îi va comunica lui Cargo cheia ta API și o va salva local în fișierul ~/.cargo/credentials. Fii atent, această cheie este un secret și nu trebuie să o împărtășești cu nimeni. Dacă, dintr-un anumit motiv, o vei împărtăși, revoc-o și generează una nouă pe crates.io.
Adăugarea metadatelor la un crate nou
Să zicem că ai în plan să publici un crate. Înainte de a trece la publicare, e necesar să adaugi anumite metadate în secțiunea [package] a fișierului Cargo.toml corespunzător crate-ului.
Crate-ul tău trebuie să aibă un nume unic. Atunci când lucrezi la un crate pe plan local, poți opta pentru orice nume dorești. Însă, numele pentru crate-uri pe crates.io se atribuie pe sistemul 'primul venit, primul servit'. Odată ce un nume este ocupat, nu se mai permite publicarea unui alt crate cu același nume. Verifică dacă numele pe care îl dorești este disponibil înainte de a încerca să publici crate-ul. Dacă descoperi că numele a fost deja folosit, va trebui să alegi un altul și să actualizezi câmpul name din Cargo.toml, în secțiunea [package], pentru a putea folosi noul nume la publicare, astfel:
Numele fișierului: Cargo.toml
[package]
name = "guessing_game"
Dacă ai ales un nume care este unic, când rulezi comanda cargo publish pentru publicarea crate-ului în acest punct, vei întâmpina prima dată un avertisment, urmat de o eroare:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error: missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for how to upload metadata
Apare această eroare pentru că lipsesc informații cruciale: descrierea și licența sunt obligatorii, pentru ca alții să poată înțelege ce face crate-ul tău și sub ce termeni pot să-l utilizeze. În fișierul Cargo.toml, adaugă o descriere scurtă, de una-două propoziții, aceasta urmând să apară împreună cu crate-ul tău în rezultatele de căutare. Câmpul license necesită introducerea unei valori de identificare a licenței. Identificatorii pe care îi poți folosi pentru acest scop sunt listati de Software Package Data Exchange (SPDX) a Fundației Linux. De exemplu, dacă ai licențiat crate-ul cu Licența MIT, adaugi identificatorul MIT:
Numele fișierului: Cargo.toml
[package]
name = "guessing_game"
license = "MIT"
Dacă preferi o licență care nu se află în listele SPDX, atunci textul acelei licențe trebuie inclus într-un fișier în proiectul tău și specificat folosind license-file pentru a indica numele fișierului, în loc să folosești cheia license.
Alegerea licenței potrivite pentru proiectul tău este un subiect care nu este acoperit de această carte. Este comun în comunitatea Rust ca proiecte să fie licențiate similar cu Rust, prin utilizarea unei licențe duble MIT OR Apache-2.0. Acest lucru arată că e posibil să specifici multiple identificatoare de licență, separate prin OR, pentru a oferi mai multe opțiuni de licențiere pentru proiectul tău.
Cu un nume unic, o versiune, o descriere adăugată și o licență definită, fișierul Cargo.toml al unui proiect pregătit pentru publicare poate arăta în felul următor:
Numele fișierului: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2021"
description = "Un joc distractiv unde încerci să ghicești numărul ales de calculator."
license = "MIT OR Apache-2.0"
[dependencies]
Poți găsi în documentația Cargo detalii suplimentare despre alte metadate care îmbunătățesc descoperirea și utilizarea crate-ului tău de către alții.
Publicarea pe crates.io
Acum că ți-ai creat un cont, ai salvat cheia API, ai ales un nume pentru crate-ul tău și ai specificat toate metadatele necesare, ești pregătit să publici! Publicarea unui crate trimite o versiune specifică pe crates.io pentru utilizare de către alții.
Trebuie să fii precaut, deoarece o publicare este ireversibilă. Versiunea nu poate fi înlocuită, iar codul nu poate fi retras. Unul dintre principalele obiective ale crates.io este să servească ca o arhivă permanentă de cod, pentru ca toate proiectele care depind de crate-uri de pe crates.io să poată fi construite și în viitor. Permițând ștergerea de versiuni, am împiedica atingerea acestui obiectiv. Cu toate acestea, poți publica un număr nelimitat de versiuni ale crate-ului tău.
Execută din nou comanda cargo publish. De data aceasta ar trebui să fie cu succes:
$ cargo publish
Updating crates.io index
Packaging guessing_game v0.1.0 (file:///projects/guessing_game)
Verifying guessing_game v0.1.0 (file:///projects/guessing_game)
Compiling guessing_game v0.1.0
(file:///projects/guessing_game/target/package/guessing_game-0.1.0)
Finished dev [unoptimized + debuginfo] target(s) in 0.19s
Uploading guessing_game v0.1.0 (file:///projects/guessing_game)
Felicitări! Codul tău a fost acum distribuit comunității Rust, astfel încât toți pot să includă foarte ușor crate-ul tău ca dependență în proiectele lor.
Publicarea unei versiuni noi a unui crate existent
Când ai efectuat modificări în crate-ul tău și ești pregătit să faci o versiune nouă, trebuie să modifici valoarea version din fișierul tău Cargo.toml și să re-publici. Urmărește regulile versionării semantice ca să determini care ar trebui să fie numărul de versiune adecvat, bazat pe modificările efectuate. Apoi execută cargo publish pentru a încărca noua versiune.
Retragerea versiunilor de pe crates.io folosind cargo yank
Cu toate că nu poți șterge versiunile anterioare ale unui crate, poți să previi adăugarea lor ca o nouă dependență de către proiecte viitoare. Acest lucru este de ajutor atunci când o versiune a unui crate este deficientă dintr-un oarecare motiv. În asemenea situații, Cargo oferă posibilitatea de a retrage o versiune de crate.
Retragerea unei versiuni împiedică proiectele noi să depindă de acea versiune, permițând în același timp tuturor proiectelor existente care o folosesc să continue fără probleme. În esență, a retrage o versiune semnifică faptul că toate proiectele cu un Cargo.lock deja existent nu vor avea de suferit și niciun viitor fișier Cargo.lock nou-generat nu va utiliza versiunea retrasă.
Pentru a retrage o versiune a unui crate, în directoriul unde crate-ul a fost publicat inițial, execută cargo yank și indică versiunea pe care dorești să o retragi. Spre exemplu, dacă am publicat un crate denumit guessing_game la versiunea 1.0.1 și dorim să o retragem, în directoriul proiectului guessing_game am executa:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank guessing_game@1.0.1
Prin adăugarea --undo la comandă, poți de asemenea anula o retragere și permite din nou proiectelor noi să depindă de acea versiune:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank guessing_game@1.0.1
O retragere nu implică ștergerea vreunui cod. De pildă, nu poate elimina secretele încărcate din greșeală. Dacă se întâmplă acest lucru, trebuie să resetezi imediat respectivele secrete.
Spațiile de lucru Cargo
În Capitolul 12, am creat un pachet care conținea atât un crate binar, cât și unul de bibliotecă. Conform evoluției proiectului tău, este posibil să observi că mărimea crate-ului de bibliotecă se mărește și ai dori să împarți pachetul în mai multe crate-uri de bibliotecă. Cargo pune la dispoziție o caracteristică denumită workspaces (spații de lucru), care facilitează gestionarea unui set de pachete conexe ce sunt dezvoltate simultan.
Crearea unui spațiu de lucru
Un workspace este un set de pachete care partajează același Cargo.lock și directoriu de păstrare a rezultatelor compilării. Să creăm un proiect folosind un workspace, unde vom utiliza cod simplu pentru a ne focaliza pe structura spațiului de lucru. Există diverse moduri de structurare a unui spațiu de lucru, însă vom prezenta doar o metodă frecvent utilizată. Vom avea un spațiu de lucru ce va conține un binar și două biblioteci. Binarul, care va fi responsabil de funcționalitatea principală, va depinde de cele două biblioteci. Prima bibliotecă va oferi funcția add_one, iar cea de-a doua funcția add_two. Aceste trei crate-uri vor forma unul și același workspace. Începem prin crearea unui nou directoriu pentru workspace:
$ mkdir add
$ cd add
Ulterior, în directoriul add, vom crea fișierul Cargo.toml, care va stabili configurația întregului spațiu de lucru. Acest fișier nu va avea secțiunea [package]. În loc de aceasta, va începe cu secțiunea [workspace], permițându-ne să adăugăm module la spațiul nostru de lucru prin specificarea căii pachetului ce conține binarul nostru crate. În cazul de față, acea cale este adder:
Numele fișierului: Cargo.toml
[workspace]
members = [
"adder",
]
În pasul următor, vom crea crate-ul binar adder, executând cargo new în directoriul add:
$ cargo new adder
Created binary (application) `adder` package
Acum putem construi workspace-ul executând cargo build. Fișierele din directoriul add ar trebui să aibă următoarea structură:
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Zona de lucru dispune de un singur directoriu target la nivelul superior, locul unde se vor așeza artifactele compilate; pachetul adder nu deține un directoriu target separat. Chiar dacă am executa cargo build din interiorul directoriului adder, artifactele compilate tot în add/target ar ajunge, nu în add/adder/target. Cargo organizează directoriul target într-un spațiu de lucru în acest mod deoarece crate-urile din cadrul unui workspace sunt concepute să colaboreze între ele. Dacă fiecare crate ar avea propriul directoriu target, atunci fiecare din ele ar fi nevoit să recompileze toate celelalte crate pentru a plasa artifactele în directoriul sau target. Astfel, partajând un directoriu target comun, crate-urile evită recompilări inutile.
Crearea celui de-al doilea crate în spațiul de lucru
În continuare, să creăm un alt crate membru în zona de lucru și să-l numim add_one. Modificăm Cargo.toml de nivel superior pentru a specifica calea add_one în lista members:
Numele fișierului: Cargo.toml
[workspace]
members = [
"adder",
"add_one",
]
Apoi generăm un nou crate de tip bibliotecă denumit add_one:
$ cargo new add_one --lib
Created library `add_one` package
Directorul nostru add ar trebui acum să conțină aceste directoare și fișiere:
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
În fișierul add_one/src/lib.rs, să adăugăm o funcție add_one:
Numele fișierului: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}Acum pachetul adder, care conține binarul nostru, poate depinde de crate-ul add_one cu biblioteca noastră. Pentru început, trebuie să adăugăm o dependență de cale pentru add_one în adder/Cargo.toml.
Numele fișierului: adder/Cargo.toml
[dependencies]
add_one = { path = "../add_one" }
Cargo nu presupune implicit că crate-urile dintr-un spațiu de lucru vor depinde unele de altele, deci trebuie să specificăm în mod explicit relațiile de dependență.
Acum, să utilizăm funcția add_one (din crate-ul add_one) în crate-ul adder. Deschideți fișierul adder/src/main.rs și inserați o linie use la început pentru a aduce crate-ul bibliotecă add_one în domeniul de vizibilitate. Modificați apoi funcția main pentru a chema funcția add_one, așa cum e ilustrat în Listarea 14-7.
Numele fișierului: adder/src/main.rs
use add_one;
fn main() {
let num = 10;
println!("Hello, world! {num} plus one is {}!", add_one::add_one(num));
}Listarea 14-7: Utilizarea crate-ului bibliotecă add_one din crate-ul adder
Construim spațiul de lucru executând cargo build în directorul superior add!
$ cargo build
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished dev [unoptimized + debuginfo] target(s) in 0.68s
Pentru a executa crate-ul binar din directorul add, putem preciza pachetul din zona de lucru pe care dorim să îl rulăm folosind argumentul -p și numele pachetului împreună cu cargo run:
$ cargo run -p adder
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/adder`
Hello, world! 10 plus one is 11!
Această comandă rulează codul din adder/src/main.rs, care depinde de crate-ul add_one.
Utilizarea unei dependente externe într-un workspace
Observăm că există un singur fișier Cargo.lock situat la nivelul de sus al spaíului nostru de lucru, și nu un Cargo.lock în directoriul fiecărui crate individual. Acest aranjament garantează că toate crate-urile folosesc aceleași versiuni ale dependențelor. Dacă includem pachetul rand în fișierele adder/Cargo.toml și add_one/Cargo.toml, Cargo va coordona cele două referințe pentru a utiliza o singură versiune a lui rand, pe care o va înregistra în fișierul Cargo.lock comun. Utilizarea aceleiași versiuni a dependențelor de către toate crate-urile din zona de lucru asigură că acestea vor fi întotdeauna interoperabile. Să adăugăm crate-ul rand în secțiunea [dependencies] a fișierului add_one/Cargo.toml, pentru a-l putea utiliza în crate-ul add_one:
Filename: add_one/Cargo.toml
[dependencies]
rand = "0.8.5"
Acum, putem scrie use rand; în fișierul add_one/src/lib.rs, și dacă executăm cargo build din directoriul add, acesta va descărca și compila crate-ul rand. O să primim un avertisment deoarece nu folosim rand după ce l-am introdus în domeniul de vizibilitate:
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling add_one v0.1.0 (file:///projects/add/add_one)
warning: unused import: `rand`
--> add_one/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `add_one` (lib) generated 1 warning
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished dev [unoptimized + debuginfo] target(s) in 10.18s
Fișierul Cargo.lock de la nivelul cel mai de sus conține acum informații despre faptul că add_one depinde de rand. Totuși, chiar dacă rand este folosit în unele părți ale workspace-ului, nu va putea fi utilizat în alte crate-uri decât dacă adăugăm rand și în fișierele lor Cargo.toml. De exemplu, introducerea use rand; în fișierul adder/src/main.rs al pachetului adder va conduce la o eroare:
$ cargo build
--snip--
Compiling adder v0.1.0 (file:///projects/add/adder)
error[E0432]: unresolved import `rand`
--> adder/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
Pentru a remedierea acestei probleme, actualizează fișierul Cargo.toml aferent pachetului adder indicând faptul că rand constituie de asemenea o dependență pentru el. Compilarea pachetului adder va adăuga rand în lista de dependențe pentru adder în fișierul Cargo.lock, dar nu vor fi descărcate versiuni suplimentare ale rand. Cargo a garantat că toate crate-urile din toate pachetele spaíului de lucru care folosesc pachetul rand se vor baza pe aceeași versiune, ajutându-ne să economisim spațiu și asigurând compatibilitatea între crate-urile din zona noastră de lucru.
Adăugarea unui test într-un workspace
Pentru o nouă îmbunătățire, să adăugăm un test pentru funcția add_one::add_one din crate-ul add_one:
Numele fișierului: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}Acum rulează cargo test în directoriul top-level add. Executând cargo test într-un spațiu de lucru configurat în acest mod, vor fi rulate testele pentru toate crate-urile din workspace:
$ cargo test
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.27s
Running unittests src/lib.rs (target/debug/deps/add_one-f0253159197f7841)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/adder-49979ff40686fa8e)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Prima parte a ieșierei indică faptul că testul it_works din crate-ul add_one a fost validat cu succes. Următoarea secțiune arată că nu au fost descoperite teste în crate-ul adder, iar ultima parte a output-ului revelează că nu au fost găsite teste de documentație pentru crate-ul add_one.
Putem, de asemenea, să rulăm teste doar pentru un singur crate din spațiul de lucur, făcând asta din directoriul top-level, folosind opțiunea -p și specificând numele crate-ului pe care îl testăm:
$ cargo test -p add_one
Finished test [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/add_one-b3235fea9a156f74)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Această parte a afișajului confirmă că cargo test a executat numai testele pentru crate-ul add_one, fără a include testele pentru crate-ul adder.
Dacă ai intenția de a publica crate-urile din spațiul de lucru pe crates.io, fiecare crate trebuie publicat separat. Similar cu cargo test, putem publica un anumit crate din zona de lucru folosind opțiunea -p și precizând numele acestuia.
Ca exercițiu adițional, încearcă să adaugi un crate add_two în acest spațiu de lucru, într-o manieră asemănătoare cu add_one!
Pe măsură ce proiectul tău evoluează, iată de ce ar fi benefică folosirea zonelor de lucru: este mai ușor de înțeles componente individuale și mai mici decât un monolit de cod. În plus, menținerea crate-urilor într-un spațiu de lucru poate facilita coordonarea între ele, în special când sunt modificate simultan.
Instalarea binarelor cu cargo install
Comanda cargo install îți permite să instalezi și să utiliezi crate-uri binare local. Aceasta nu este gândită să substituie pachetele sistemului; este destinată să fie o metodă comodă pentru dezvoltatorii Rust de a instala uneltele pe care alții le-au pus la dispoziție pe crates.io. Este important să notezi că se pot instala numai pachetele care conțin target-uri binare. Un target binar este programul executabil creat atunci când un crate conține un fișier src/main.rs sau un alt fișier desemnat ca binar, spre deosebire de un target de tip librărie, care nu poate fi executat independent, dar poate fi integrat în alte programe. În mod obișnuit, crate-urile includ în fișierul README informații despre dacă un crate este o librărie, dacă include un target binar sau dacă are amândouă.
Toate binarele instalate prin intermediul cargo install sunt depozitate în directoriul bin al rădăcinii de instalare. Dacă ai instalat Rust folosind rustup.rs și nu ai configurări personalizate, acest directoriu va fi $HOME/.cargo/bin. Pentru a putea executa programele instalate cu cargo install, directoriul acesta trebuie să fie inclus în variabila de mediu $PATH.
De exemplu, în Capitolul 12 am adus în discuție faptul că există o variantă Rust a instrumentului grep numit ripgrep, utilizată pentru căutarea în fișiere. Pentru a instala ripgrep, executăm următoarea comandă:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v13.0.0
Downloaded 1 crate (243.3 KB) in 0.88s
Installing ripgrep v13.0.0
--snip--
Compiling ripgrep v13.0.0
Finished release [optimized + debuginfo] target(s) in 3m 10s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v13.0.0` (executable `rg`)
Penultima linie a afișajului indică locația și numele binarului instalat, care în cazul ripgrep este rg. Dacă directoriul de instalare este inclus în variabila ta de mediu $PATH, cum am menționat anterior, poți apoi folosi comanda rg --help și începe să utilizezi un instrument mai eficient și specific limbajului Rust pentru căutarea în fișiere!
Extinderea Cargo cu Comenzi Personalizate
Cargo este proiectat pentru a permite adăugarea de subcomenzi noi fără a schimba Cargo. Dacă există un executabil în $PATH cu numele cargo-something, îl poți rula ca și cum ar fi o subcomandă Cargo prin comanda cargo something. Comenzi personalizate de acest fel sunt listate de asemenea atunci când rulezi cargo --list. Posibilitatea de a utiliza cargo install pentru instalarea extensiilor și apoi de a le executa la fel ca instrumentele predefinite Cargo reprezintă o facilitate deosebit de convenabilă a designului Cargo!
Sumar
Partajarea codului prin Cargo și crates.io contribuie la utilitatea ecosistemului Rust pentru diverse sarcini. Biblioteca standard a Rust este mică și stabilă, însă crate-urile sunt ușor de împărtășit, folosit și îmbunătățit pe un parcurs diferit de cel al limbajului în sine. Nu ezita să partajezi codul care îți este util pe crates.io; există mari șanse ca acesta să fie benefic și pentru alte persoane!
Pointeri inteligenți
Un pointer este un concept general pentru o variabilă ce conține o adresă de memorie. Această adresă referă sau „indică” către alte date. Tipul cel mai comun de pointer în Rust este referința, pe care am învățat-o în Capitolul 4. Referințele sunt semnalate de simbolul & și împrumută valoarea la care se referă. În afara acestei funcții, ele nu au capabilități speciale și nu implică un supra-cost.
În contrast, pointerii inteligenți sunt structuri de date care funcționează ca niște pointeri, dar au, de asemenea, metadate suplimentare și capacitatea de a efectua mai multe operațiuni. Conceptul de pointeri inteligenți nu este unic pentru Rust; aceștia provin din C++ și se regăsesc și în alte limbaje de programare. Biblioteca standard Rust include o selecție de pointeri inteligenți care oferă mai mult decât simple referințe. Pentru a explora acest concept în general, vom examina diferite tipuri de pointeri inteligenți, inclusiv un tip care se folosește de numărarea referințelor. Aceast pointer permite datelor să fie deținute de mai mulți posesori și, atunci când nu mai există niciun posesor, se ocupă de eliberarea acestora.
Având în vedere conceptele de posesiune și împrumut proprii lui Rust, există o diferență esențială între referințe și pointerii inteligenți: în timp ce referințele doar împrumută datele, pointerii inteligenți, deseori, dețin datele la care se referă.
Deși până acum nu i-am numit în mod explicit ca atare, am întâlnit deja câțiva pointeri inteligenți în această carte, printre care tipurile String și Vec<T> prezentate în Capitolul 8. Aceste tipuri sunt considerate pointeri inteligenți pentru că dețin memorie și permit manipularea acesteia. În plus, dispun de metadate și facilități sau garanții suplimentare. De pildă, String stochează capacitatea sa ca metadată și garantează că datele sale vor fi întotdeauna un șir de coduri UTF-8 valide.
Pointerii inteligenți sunt de obicei implementați ca structuri. Spre deosebire de o structură obișnuită, pointerii inteligenți implementează trăsăturile Deref și Drop. Trăsătura Deref le permite instanțelor structurii pointer înteligent să se comporte ca referințe, făcând posibilă scrierea codului compatibil atât cu referințele cât și cu pointerii inteligenți. Trăsătura Drop este folosită pentru personalizarea codului executat când o instanță a pointerului inteligent iese din domeniul de vizibilitate. În acest capitol, vom lua în discuție ambele trăsături și vom arăta importanța lor pentru pointerii inteligenți.
Dat fiind că pointerul inteligent este un model de proiectare des utilizat în Rust, acest capitol nu va aborda toți pointerii inteligenți existenți. Multe biblioteci oferă variante proprii de pointeri inteligenți, iar tu poți să-ți creezi chiar versiuni proprii. Ne vom concentra asupra celor mai uzuali pointeri inteligenți din biblioteca standard:
Box<T>pentru alocarea valorilor pe heapRc<T>, un tip ce gestionează numărarea referințelor și facilitează posesiunea multiplăRef<T>șiRefMut<T>, accesibile prinRefCell<T>, un tip care aplică regulile de împrumut la timpul de execuție, nu la compilare
De asemenea, vom explora modelul de mutabilitate interioară, prin care un tip imutabil oferă o interfață API pentru modificarea unei valori interne. Vom discuta, totodată, despre ciclurile de referințe: cum pot ele să genereze scurgeri de memorie și cum le putem preveni.
Să ne scufundăm în subiect!
Utilizarea Box<T> pentru a arăta spre date situate pe heap
Cel mai simplu smart pointer este boxa, ale cărei tip este notat ca Box<T>. Boxele permit stocarea datelor pe heap în loc de pe stivă. Ce rămâne pe stivă este pointerul către datele de pe heap. Pentru a revizui diferența dintre stivă și heap, putem reveni la Capitolul 4.
Boxele nu aduc un supra-cost de performanță decât în ceea ce privește stocarea datelor pe heap în locul stivei. Dar, ele nu oferă nici multe funcționalități extra. Vom utiliza boxele cel mai frecvent în următoarele situații:
- Atunci când deținem un tip a cărui dimensiune nu poate fi stabilită în timpul compilării și dorim să utilizăm o valoare de acest tip într-un context care necesită o dimensiune exactă
- Atunci când avem o cantitate mare de date și dorim să transferăm posesiunea, dar să ne asigurăm că datele nu vor fi copiate în acest proces
- Atunci când dorim să deținem o valoare și ne interesează doar ca aceasta să implementeze o anumită trăsătură, mai degrabă decât să fie de un tip anume
Primul caz va fi demonstrat în secțiunea “Activarea Tipurilor Recursive folosind Boxe”. În al doilea caz, transferul posesiunii asupra unei cantități mari de date poate dura mult deoarece datele sunt copiate pe stivă. Pentru îmbunătățirea performanței în această situație, putem stoca acele date pe heap într-o boxă. Astfel, doar o mică parte din datele pointerului sunt copiate pe stivă, pe când datele la care se referă rămân într-un singur loc pe heap. Al treilea caz este cunoscut sub numele de obiect-trăsătură, iar Capitolul 17 consacră o întreagă secțiune, “Utilizarea obiectelor-trăsătură ce permit valori de tipuri diverse,” exclusiv acestui subiect. Deci, tot ce învățăm aici va fi aplicat din nou în Capitolul 17!
Utilizarea unei Box<T> pentru a stoca date pe heap
Înainte de a discuta cazul de utilizare a Box<T> pentru stocare pe heap, vom revizui sintaxa și cum interacționăm cu valorile închise într-o Box<T>.
Listarea 15-1 ilustrează cum să folosești o boxă pentru a păstra o valoare i32 pe heap:
Numele fișierului: src/main.rs
fn main() { let b = Box::new(5); println!("b = {}", b); }
Listarea 15-1: Stocarea unei valori i32 pe heap utilizând o boxă
Definim variabila b cu valoarea unui Box care indică spre valoarea 5, alocată pe heap. Acest program va afișa b = 5; în acest context, putem accesa datele din boxă într-un mod asemănător cu cel în care am accesa datele dacă ar fi pe stivă. Așa cum se întâmplă cu orice valoare deținută, când un Box iese din domeniul de vizibilitate, cum se întâmplă pentru b la finalul main function, se va proceda la dealocarea acestuia. Dealocarea are loc atât pentru boxă (pe stivă), cât și pentru datele la care face referire (pe heap).
A așeza o singură valoare pe heap nu este frecvent utilă, prin urmare utilizarea în izolare a boxelor în acest mod nu este des întâlnită. În majoritatea situațiilor, este mai potrivit să avem valori precum o instanță i32 pe stivă, unde în mod implicit sunt stocate. Să examinăm acum o situație în care boxele ne permit să definim tipuri care în alt mod n-ar fi posibile fără existența boxelor.
Permiterea tipurilor recursive cu boxe
O valoare de tip recursiv poate include în ea însăși o altă valoare de același tip. Tipurile recursive creează o problemă în Rust deoarece, la momentul compilării, este necesar să se știe cât spațiu ocupă fiecare tip. Însă, întrepătrunderea valorilor de tipuri recursive teoretic nu are sfârșit, astfel Rust nu poate deduce cât spațiu va fi necesar. Utilizarea boxelor, care au o dimensiune fixă cunoscută, ne permite să activăm tipurile recursive prin introducerea unei boxe în definiția tipului recursiv.
Drept exemplu de tip recursiv, să analizăm lista cons. Aceasta este un tip de date des întâlnit în limbajele de programare funcțională. Tipul listei cons pe care îl vom defini este simplu, mai puțin partea recursivă; deci, conceptele din exemplul cu care vom lucra ne vor fi de folos în orice moment când ne confruntăm cu situații mai complexe ce implică tipuri recursive.
Mai multe informații despre lista cons
O cons list (listă cons) este o structură de date originară din limbajul de programare Lisp și din dialectele acestuia, alcătuită din perechi încapsulate și reprezintă versiunea în Lisp a unei liste înlănțuite. Numele provine de la funcția cons (prescurtarea pentru “construct function”) din Lisp, care construiește o nouă pereche pe baza celor doi parametri. Prin apelarea recursivă a funcției cons pe o pereche formată dintr-o valoare și o altă pereche, putem crea liste cons alcătuite din perechi recursive.
Iată un exemplu de reprezentare în pseudocod a unei liste cons care include secvența 1, 2, 3; fiecare pereche fiind închisă în paranteze:
(1, (2, (3, Nil)))
Fiecare element al unei liste cons cuprinde două componente: valoarea actuală și următorul element din listă. Ultimul element conține numai o valoare numită Nil, fără un succesor. O listă cons este generată prin apeluri recursive ale funcției cons. Termenul recunoscut universal pentru a desemna situația inițială a recursivității este Nil. Este important de subliniat că acesta nu coincide cu noțiunea de „null” sau „nil” menționată în Capitolul 6, ce se referă la o valoare nevalidă sau lipsă.
Lista cons nu este o structură de date des întâlnită în Rust. Majoritatea timpului, când avem de-a face cu o listă de elemente în Rust, opțiunea Vec<T> se dovedește a fi mai practică. Alte structuri de date recursive mai complexe sunt utile în situații variate, dar introducerea noțiunii de listă cons în acest capitol ne permite să explorăm cum boxele ne ajută să definim un tip de date recursiv, fără alte distrageri.
Listarea 15-2 conține definiția unui enum pentru o listă de tip cons. Observăm că acest cod nu o să se compileze încă, pentru că tipul List nu are o mărime cunoscută, lucru pe care îl vom demonstra.
Numele fișierului: src/main.rs
enum List {
Cons(i32, List),
Nil,
}
fn main() {}Listarea 15-2: Prima încercare de definire a unui enum pentru a reprezenta o structură de date listă cons de valori i32
Notă: Implementăm o listă cons care conține numai valori
i32pentru acest exemplu. Am fi putut să utilizăm generici, așa cum am discutat în Capitolul 10, pentru a defini un tip de listă cons capabil să stocheze valori de orice tip.
Utilizând tipul List pentru a stoca lista 1, 2, 3 arată ca și codul din Listarea 15-3:
Numele fișierului: src/main.rs
enum List {
Cons(i32, List),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}Listarea 15-3: Folosind enum-ul List pentru a stoca lista 1, 2, 3
Prima valoare Cons păstrează 1 și încă o valoare List. Această valoare List este alte o valoare Cons care păstrează 2 și încă o valoare List. Ultima valoare List este încă o valoare Cons care păstrează 3 și o valoare List, care până la urmă este Nil, varianta non-recursivă ce semnalează finalul listei.
Dacă încercăm să compilăm codul din Listarea 15-3, vom întâmpina eroarea afișată în Listarea 15-4:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
For more information about this error, try `rustc --explain E0072`.
error: could not compile `cons-list` due to previous error
Listarea 15-4: Eroarea întâlnită când încercăm să definim un enum recursiv
Eroarea indică că acest tip "are dimensiune infinită". Acest lucru se întâmplă deoarece am definit List cu o variantă care este recursivă, aceasta conținând direct altă valoare de tipul său. Drept rezultat, Rust nu poate stabili cât spațiu e necesar pentru a stoca o valoare de tip List. Să analizăm de ce apare această eroare. În primul rând, să vedem cum Rust decide cât spațiu e necesar pentru a stoca o valoare de tip non-recursiv.
Calcularea dimensiunii unui tip non-recursiv
Reamintim enum-ul Message definit în Listarea 6-2, unde am analizat definițiile enum-urilor în Capitolul 6:
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() {}
Pentru a calcula cât spațiu este necesar pentru o valoare de tip Message, Rust inspectează fiecare variantă pentru a determina care variază cel mai mult în dimensiune. Rust observă că Message::Quit nu ocupă spațiu, Message::Move necesită destul spațiu pentru două valori i32, etc. Cum doar una dintre variante va fi utilizată, cantitatea maximă de spațiu pe care o valoare Message o poate ocupa este dată de dimensiunea celei mai mari variante.
Prin contrast, observăm ce se întâmplă când Rust încearcă să determine cât spațiu este necesar pentru un tip recursiv, cum ar fi enum-ul List din Listarea 15-2. Compilatorul începe analiza cu varianta Cons, care include o valoare i32 și una de tip List. Astfel, Cons necesită un spațiu egal cu dimensiunea unui i32 adăugată la dimensiunea unui List. Pentru a deduce cât spațiu îi trebuie tipului List, compilatorul se uită la variante, pornind de la Cons. Aceasta conține o valoare i32 și una List, iar această recursivitate continuă ad infinitum, așa cum e prezentat în Figura 15-1.
Figura 15-1: O listă List infinită compusă din variante Cons la infinit
Folosirea lui Box<T> pentru a realiza un tip recursiv cu dimensiunea cunoscută
Pentru că Rust nu este capabil să calculeze automat cât spațiu de memorie trebuie alocat pentru tipurile definite recursiv, compilatorul va arăta o eroare cu următoarea sugestie utilă:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to make `List` representable
|
2 | Cons(i32, Box<List>),
| ++++ +
Aici, „un nivel de indirecție” sugerează că în loc să stocăm direct o valoare, ar trebui să modificăm structura de date astfel încât valoarea să fie stocată în mod indirect, prin intermediul unui pointer care să indice către acea valoare.
Din moment ce un Box<T> este un pointer, Rust întotdeauna va ști cât spațiu necesită un Box<T>: mărimea unui pointer rămâne constantă, indiferent de volumul de date la care face referire. Asta înseamnă că putem utiliza o boxă Box<T> în varianta Cons pe locul unei valori List directe. Box<T> va referi la următoarea intrare List, care va fi amplasată în heap și nu direct în varianta Cons. În esență, avem în continuare o listă, alcătuită din liste care conțin alte liste, însă această implementare este acum mai aproape de ideea de a așeza elementele unul lângă celălalt decât unul în altul.
Putem modifica definiția enum-ului List din Listarea 15-2 și utilizarea List din Listarea 15-3 cu codul din Listarea 15-5, care se va compila:
Numele fișierului: src/main.rs
enum List { Cons(i32, Box<List>), Nil, } use crate::List::{Cons, Nil}; fn main() { let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil)))))); }
Listarea 15-5: Definiția lui List care folosește Box<T> pentru a asigura o dimensiune cunoscută
Varianta Cons necesită dimensiunea unui i32 plus spațiul necesar pentru a stoca datele pointer-ului boxei. Varianta Nil nu stochează nicio valoare, deci ocupă mai puțin spațiu decât varianta Cons. Acum știm că orice valoare de tip List va ocupa dimensiunea unui i32 plus dimensiunea datelor pointer-ului unei boxe. Folosind o boxe am întrerupt lanțul infinit, recursiv, permițând astfel compilatorului să calculeze dimensiunea de care are nevoie pentru a stoca o valoare List. Figura 15-2 ilustrează aspectul curent al variantei Cons.

Figura 15-2: O listă List care nu este de dimensiuni infinite deoarece Cons conține un tip Box
Boxele oferă doar indirectare și alocarea memoriei pe heap; ele nu dispun de alte capabilități speciale, asemenea celor pe care le vom examina la alte categorii de pointeri inteligenți. Totodată, ele nu implică o supraplată de performanță asociată acestor capabilități speciale, fiind astfel folositoare în situații precum lista cons, unde indirectarea este singurul atribut necesar. Vom analiza mai multe întrebuințări pentru boxe și în Capitolul 17.
Tipul Box<T> este considerat un pointer inteligent deoarece implementează trăsătura Deref, ceea ce îi permite lui Box<T> să fie tratat ca o referință. Când o valoare de tip Box<T> iese din domeniul de vizibilitate, datele de pe heap la care indică boxa sunt și ele eliberate, datorită implementării trăsăturii Drop. Aceste două trăsături sunt și mai importante pentru funcționalitățile oferite de celelalte tipuri de pointeri inteligenți pe care le vom discuta în restul capitolului. Să ne aprofundăm cunoștințele despre aceste două trăsături.
Utilizarea pointerilor inteligenți la fel ca referințele obișnuite cu trăsătura Deref
Când implementăm trăsătura Deref, personalizăm comportamentul operatorului de dereferențiere * (care nu trebuie confundat cu operatorul de înmulțire sau cu operatorul glob). Prin implementarea Deref în așa fel încât un pointer inteligent să poată fi tratat ca o referință obișnuită, poți scrie cod care operează pe referințe și să folosești același cod cu pointeri inteligenți.
Să începem prin a examina modul în care operatorul de dereferențiere funcționează cu referințe convenționale. Apoi, vom defini un nou tip care se comportă similar cu Box<T>, observând de ce operatorul de dereferențiere nu își păstrează comportamentul obișnuit asupra acestui tip proaspăt definit. Vom descoperi cum implementarea trăsăturii Deref permite pointerilor inteligenți să funcționeze similar cu referințele. În continuare, vom explora funcția de coerciție deref oferită de Rust și modul în care aceasta ne facilitează lucrul fie cu referințe, fie cu pointeri inteligenți.
Notă: există o diferență majoră între tipul
MyBox<T>ce urmează să-l construim șiBox<T>autentic: varianta noastră nu va plasa datele pe heap. Concentrându-ne pe exemplificareaDeref, locația exactă unde datele sunt stocate devine secundară în fața comportamentului tipic de pointer.
Urmărind Pointer-ul până la Valoarea sa
Un referință obișnuită este un fel de pointer, și putem gândi un pointer ca fiind o săgeată ce arată spre o valoare păstrată altundeva. În Listarea 15-6, inițiem o referință la o valoare i32 și apoi aplicăm operatorul de dereferențiere pentru a ajunge la valoarea la care face referința:
Filename: src/main.rs
fn main() { let x = 5; let y = &x; assert_eq!(5, x); assert_eq!(5, *y); }
Listarea 15-6: Utilizarea operatorului de dereferențiere pentru a urma o referință către o valoare i32
Variabila x are deține o valoare i32, mai exact 5. Alocăm y să fie o referință la x. Ne putem asigura că x este egal cu 5. Însă, dacă dorim să argumentăm ceva despre valoarea către care y face referință, trebuie să folosim *y pentru a urmări referința până la valoarea respectivă (de aici termenul dereferențiere), ceea ce îi va permite compilatorului să compare valoarea actuală. Odată ce dereferențiem y, obținem accesul la valoarea numerică la care y face referință și pe care o putem compara cu 5.
Dacă am opta să folosim assert_eq!(5, y);, am întâmpina această eroare de compilare:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= help: the following other types implement trait `PartialEq<Rhs>`:
f32
f64
i128
i16
i32
i64
i8
isize
and 6 others
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` due to previous error
Nu este permis să comparam un număr cu o referință la un număr, deoarece sunt de tipuri diferite. Trebuie să utilizăm operatorul de dereferențiere pentru a accesa valoarea la care face referința.
Utilizarea Box<T> la fel ca o referință
Putem rescrie codul din Listarea 15-6 astfel încât să folosim Box<T> în loc de o referință; operatorul de dereferențiere aplicat asupra lui Box<T> în Listarea 15-7 funcționează exact ca și operatorul de dereferențiere folosit asupra referinței în Listarea 15-6:
Numele fișierului: src/main.rs
fn main() { let x = 5; let y = Box::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Listarea 15-7: Utilizarea operatorului de dereferențiere pe un Box<i32>
Principala diferență între Listarea 15-7 și Listarea 15-6 este că aici y este inițializat ca o instanță de Box<T> care conține o copie a valorii lui x, nu ca o referință la valoarea lui x. În aserțiunea finală, folosim operatorul de dereferențiere pentru a accesa pointerul din Box<T> la fel cum am făcut când y era o referință. În continuare, vom descoperi ce anume face Box<T> special și ne permite să folosim operatorul de dereferențiere, prin definirea propriului nostru tip de date.
Definirea propriului nostru pointer inteligent
Să dezvoltăm un pointer inteligent asemănător cu tipul Box<T> oferit de biblioteca standard, pentru a înțelege cum, în mod implicit, se comportă pointerii inteligenți diferit de referințe. Mai apoi, vom explora cum adăugăm funcționalitatea pentru a folosi operatorul de dereferențiere.
Tipul Box<T> este în esență definit ca un struct-tuplă cu un singur element, așadar Listarea 15-8 definește un tip MyBox<T> într-un mod similar. De asemenea, vom defini o funcție new, ca să corespundă funcției new definită pentru Box<T>.
Numele fișierului: src/main.rs
struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() {}
Listarea 15-8: Definirea tipului MyBox<T>
Definim un struct cu numele MyBox și declarăm un parametru generic T, deoarece dorim ca acest tip să poată conține valori de diverse tipuri. Tipul MyBox este un struct-tuplă ce are un singur element de tipul T. Funcția MyBox::new acceptă un parametru de tip T și returnează o instanță de MyBox care conține valoarea primită.
Să încercăm să adăugăm funcția main din Listarea 15-7 la Listarea 15-8 și să o schimbăm pentru a folosi tipul MyBox<T> definiț de noi, în loc de Box<T>. Codul din Listarea 15-9 nu va compila deoarece Rust nu recunoaște cum să dereferențieze MyBox.
Filename: src/main.rs
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Listarea 15-9: Tentativa de a utiliza MyBox<T> așa cum am folosit referințele și Box<T>
Iată eroarea de compilare care rezultă:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` due to previous error
Tipul nostru MyBox<T> nu poate fi dereferențiat deoarece nu am implementat încă această capabilitate pe el. Pentru a activa posibilitatea dereferențierii cu operatorul *, trebuie să implementăm trăsătura Deref.
Tratarea unui tip ca o referință prin implementarea trăsăturii Deref
Așa cum am discutat în secțiunea [„Implementarea unei trăsături pe un tip”][impl-trait] din Capitolul 10, pentru a implementa o trăsătură, trebuie să oferim implementări pentru toate metodele necesare ale acelei trăsături. Trăsătura Deref, furnizată de biblioteca standard, ne solicită implementarea unei metode numite deref care împrumută self și returnează o referință către datele interne. Listarea 15-10 include o implementare a Deref pe care o adăugăm la definiția MyBox:
Numele fișierului: src/main.rs
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &Self::Target { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() { let x = 5; let y = MyBox::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Listarea 15-10: Implementarea Deref pentru MyBox<T>
Sintaxa type Target = T; definește un tip asociat pe care trăsătura Deref îl va folosi. Tipurile asociate sunt un alt mod de a declara un parametru generic, însă nu este necesar să ne concentrăm asupra lor în acest moment, deoarece vor fi discutate în detaliu în Capitolul 19.
Completăm corpul metodei deref cu &self.0, astfel încât metoda deref să returneze o referință la valoarea la care vrem să avem acces utilizând operatorul *. Așa cum am revăzut în secțiunea [„Folosirea structurilor tuple fără câmpuri nominale pentru a crea tipuri diferite”][tuple-structs] din Capitolul 5, .0 permite accesul la prima valoare dintr-o structură de tip tuple. Funcția main din Listarea 15-9, care aplică operatorul * asupra unei valori MyBox<T>, acum se compilează corect și aserțiunile trec cu succes.
Fără trăsătura Deref, compilatorul este capabil să dereferențieze doar referințe de tip &. Metoda deref îi permite compilatorului să preia o valoare de orice tip care implementează Deref și să invoce metoda deref pentru a obține o referință de tip &, cu care știe să opereze prin dereferențiere.
Atunci când am folosit *y în Listarea 15-9, Rust a efectuat în spate această instrucțiune:
*(y.deref())Limbajul Rust înlocuiește operatorul * cu un apel la metoda deref, urmat de o dereferențiere simplă, permițându-ne astfel să nu ne îngrijorăm despre necesitatea apelării metodei deref. Aceasta este o facilitate a Rust care ne îngăduie să scriem cod care se comportă la fel, fie că avem o referință obișnuită sau un tip care implementează Deref.
Motivul pentru care metoda deref returnează o referință spre o valoare, și faptul că este încă necesară dereferențierea simplă în afara parantezelor în *(y.deref()), este legat de sistemul de posesiune. În cazul în care metoda deref ar elibera valoarea în mod direct, în loc de o referință la aceasta, valoarea ar fi permutată din self. Nu ne dorim să preluăm posesiunea valorii interne din MyBox<T> în acest caz, nici în majoritatea situațiilor când folosim operatorul de dereferențiere.
Este important de reținut faptul că operatorul * este substituit cu un apel la metoda deref, urmat de utilizarea a doar o singură dată a operatorului *, ori de câte ori introducem un * în codul nostru. Datorită faptului că înlocuirea operatorului * nu se repetă la infinit, obținem în final date de tipul i32, care corespunde cu valoarea 5 folosită în assert_eq! din Listarea 15-9.
Coerciția implicită Deref în funcții și metode
Coerciția Deref convertește o referință la un tip ce implementează trăsătura Deref într-o referință la alt tip. De exemplu, coerciția Deref poate converti &String în &str datorită faptului că String implementează trăsătura Deref astfel încât să returneze &str. Rust aplică automat coerciția Deref la argumentele funcțiilor și metodelor, dar numai pe acele tipuri care implementează trăsătura Deref. Aceasta are loc când pasăm o referință către o valoare de un anumit tip ca argument unei funcții sau metode ale cărei tip de parametru nu corespunde cu cel din definiția funcției sau a metodei. O succesiune de apelări ale metodei deref transformă tipul introdus în cel necesar parametrului.
Coerciția Deref a fost adăugată în Rust pentru a-i scuti pe programatori de necesitatea de a adăuga un număr mare de referințe și dereferințe explicite prin utilizarea & și *. Anume această funcționalitate ne oferă și posibilitatea de a scrie cod care este compatibil atât cu referințele, cât și cu pointerii inteligenți.
Pentru a vedea coerciția Deref în acțiune, vom folosi tipul MyBox<T> pe care l-am definit în Listarea 15-8 și implementarea Deref adăugată în Listarea 15-10. Listarea 15-11 ne arată cum să definim o funcție cu un parametru care este o secțiune de string:
Numele fișierului: src/main.rs
fn hello(name: &str) { println!("Hello, {name}!"); } fn main() {}
Listarea 15-11: Funcția hello cu parametrul name de tip &str
Putem apela funcția hello cu o secțiune de string ca argument, de pildă hello("Rust");. Coerciția Deref ne face posibilă apelarea funcției hello cu o referință la o valoare de tip MyBox<String>, așa cum este ilustrat în Listarea 15-12:
Numele fișierului: src/main.rs
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn hello(name: &str) { println!("Hello, {name}!"); } fn main() { let m = MyBox::new(String::from("Rust")); hello(&m); }
Listarea 15-12: Apelul funcției hello cu o referință la o valoare MyBox<String>, posibil datorită coerciției deref
În acest context, invocăm funcția hello cu argumentul &m, care este o referință la o valoare MyBox<String>. Având implementată trăsătura Deref pentru MyBox<T> în Listarea 15-10, Rust poate să convertească &MyBox<String> în &String prin apelarea lui deref. Biblioteca standard conține o implementare pentru Deref aplicată la String, care returnează o secțiune de string, detaliu prezent în documentația pentru API-ul Deref. Rust folosește deref încă o dată pentru a schimba &String în &str, potrivindu-se astfel cu parametrii funcției hello.
Fără implementarea coerciției deref de către Rust, ar trebui să utilizăm codul din Listarea 15-13, în locul celui din Listarea 15-12, pentru a apela funcția hello cu un argument de tip &MyBox<String>.
Numele fișierului: src/main.rs
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn hello(name: &str) { println!("Hello, {name}!"); } fn main() { let m = MyBox::new(String::from("Rust")); hello(&(*m)[..]); }
Listarea 15-13: Codul necesar în lipsa coerciției deref în Rust
Utilizând (*m) se realizează dereferențierea lui MyBox<String> într-un String. După aceea, & și [..] extrag o secțiune din String corespunzătoare întregului string, pentru a se potrivi cu definiția funcției hello. Fără utilizarea coercițiilor deref, acest cod este mai greu de citit, scris și înțeles, având în vedere multiplele simboluri implicate. Coerciția deref permite Rust să efectueze aceste transformări automat.
Atunci când trăsătura Deref este definită pentru tipurile în discuție, Rust va analiza tipurile și va aplica metoda Deref::deref atât de des cât este necesar pentru a obține o referință care se potrivește cu tipul parametrului. Determinarea numărului de aplicări ale Deref::deref are loc în timpul compilării, eliminând astfel orice penalitate asupra timpului de execuție pentru a beneficia de avantajele coerciției deref!
Cum interacționează coerciția Deref cu mutabilitatea
Similar cu modul în care utilizăm trăsătura Deref pentru a redefini operatorul * pe referințele imutabile, putem folosi trăsătura DerefMut pentru a redefini operatorul * pe referințele mutabile.
Rust aplică coerciția Deref când întâlnește tipuri și implementări de trăsături în trei situații:
- De la
&Tla&Uatunci cândT: Deref<Target=U> - De la
&mut Tla&mut Uatunci cândT: DerefMut<Target=U> - De la
&mut Tla&Uatunci cândT: Deref<Target=U>
Primele două situații sunt practic identice, cu excepția faptului că a doua situație implică mutabilitate. În primul caz, este specificat că dacă ai un &T, și T implementează Deref spre un tip U, poți obține un &U într-o manieră transparentă. În al doilea caz, se precizează că același proces de coerciție Deref este valabil și pentru referințele mutabile.
Al treilea caz este mai subtil: Rust va converti, de asemenea, o referință mutabilă într-una imutabilă. Totuși, inversul nu este posibil: referințele imutabile nu vor deveni niciodată referințe mutabile. Conform regulilor de împrumut, dacă deținem o referință mutabilă, aceasta trebuie să fie unicul indicator către datele respective (altfel, programul nu s-ar compila). Transformarea unei referințe mutabile în una imutabilă nu încalcă regulile de împrumut. Pe de altă parte, transformarea unei referințe imutabile în una mutabilă ar implica că referința imutabilă inițială este singura de acest tip către date, însă regulile de împrumut nu asigură această situație. De aceea, Rust nu poate presupune că transformarea unei referințe imutabile într-una mutabilă este fezabilă.
[impl-trait]: ch10-02-traits.html#implementing-a-trait-on-a-type [tuple-structs]: ch05-01-defining-structs.html#using-tuple-structs-without-named-fields-to-create-different-types
Executarea codului în etapa de curățare cu trăsătura Drop
A doua trăsătură esențială pentru design-ul pointerilor inteligenți este Drop, care îți oferă posibilitatea de a personaliza acțiunile ce au loc atunci când o valoare va ieși din domeniul de vizibilitate. Ai posibilitatea să implementezi trăsătura Drop pentru orice tip, iar codul respectiv poate fi utilizat pentru a elibera resurse, cum ar fi fișiere sau conexiuni de rețea.
Vorbim despre Drop în contextul pointerilor inteligenți pentru că, de obicei, funcționalitatea asociată cu trăsătura Drop este folosită în cadrul implementării unui pointer inteligent. De exemplu, atunci când un Box<T> este descărcat, el va dealoca spațiul pe heap la care se referă acesta.
În alte limbaje de programare, pentru anumite tipuri de date, dezvoltatorul trebuie să execute manual cod pentru a elibera memoria sau resursele de fiecare dată când termină de utilizat o instanță a acestor tipuri. Sunt incluse cazuri precum descriptorii de fișiere, socket-uri sau blocările de resurse. Dacă ar omite, sistemul ar putea deveni supraîncărcat și ar putea cădea. În Rust, poți specifica un anumit segment de cod care să fie rulat când o valoare părăsește domeniul de vizibilitate, iar compilatorul va insera acest segment de cod automat. Astfel, nu ești nevoit să introduci cod de curățare oriunde într-un program doar pentru că ai terminat de folosit o instanță de un anumit tip — și nu vei pierde resurse!
Specifici codul care urmează să fie executat când o valoare iese din domeniul de vizibilitate implementând trăsătura Drop. Drop necesită implementarea unei metode denumite drop care primește o referință mutabilă către self. Pentru a vedea momentul în care Rust invocă drop, să implementăm momentan metoda drop cu instrucțiuni println!.
Listarea 15-14 prezintă structura CustomSmartPointer care, prin unica ei funcționalitate particulară, va afișa mesajul Dropping CustomSmartPointer! la ieșirea instanței din domeniul de vizibilitate, demonstrând astfel momentul în care Rust execută funcția drop.
Filename: src/main.rs
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("my stuff"), }; let d = CustomSmartPointer { data: String::from("other stuff"), }; println!("CustomSmartPointers created."); }
Listarea 15-14: Structura CustomSmartPointer implementând trăsătura Drop, unde am plasa codul nostru de curățare
Trăsătura Drop este inclusă în preludiu, prin urmare, nu este nevoie să o facem vizibilă în domeniul de aplicabilitate. Implementăm trăsătura Drop pe CustomSmartPointer și oferim o implementare pentru metoda drop care invocă macro-ul println!. În corpul funcției drop ai include logica pe care dorești să o executi când o instanță a tipului tău este pe cale să iasă din domeniul de vizibilitate. În exemplul nostru, afișăm un text pentru a arăta vizual momentul la care Rust va chema drop.
În funcția main, construim două instanțe de CustomSmartPointer și apoi afișăm CustomSmartPointers created. La sfârșitul main, instanțele noastre de CustomSmartPointer vor ieși din domeniu de vizibilitate, și Rust va chema codul pe care l-am pus în metoda drop, imprimând mesajul final. Este de notat că nu e necesar să chemăm metoda drop în mod direct.
Când rulăm acest program, se va afișa următorul rezultat:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created.
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
Rust a chemat automat drop pentru noi când instanțele noastre au ieșit din domeniu de aplicabilitate, executând codul pe care l-am definit. Variabilele sunt eliberate în ordinea inversă creării lor, așadar d a fost eliberată înaintea lui c. Scopul acestor exemple este să îți ofere o ilustrare vizuală a modului în care acționează metoda drop; în mod normal ai seta codul de curățare necesar tipului tău, în loc de un mesaj tipărit.
Eliberarea anticipată a unei valori folosind std::mem::drop
Din păcate, nu este un proces simplu să dezactivezi funcționalitatea automată de drop. De altfel, dezactivarea drop nu este necesară de obicei; esența trăsăturii Drop este aceea că este gestionată în mod automat. Totuși, uneori s-ar putea să vrei să eliberezi o valoare mai devreme. Un exemplu ar fi utilizarea pointerilor inteligenți care controlează lock-uri (instrucțiunea lock e o directivă de bază a programării concurente): s-ar putea să vrei să forțezi metoda drop care eliberează un lock, astfel încât alt cod din același domeniu de vizibilitate să-l poată prelua. Rust nu îți permite să apelezi manual metoda drop a trăsăturii Drop; în loc de aceasta trebuie să folosești funcția std::mem::drop oferită de biblioteca standard, când dorești să forțezi eliberarea unei valori înainte de terminarea domeniului său de vizibilitate.
Dacă încercăm să apelăm manual metoda drop a trăsăturii Drop prin modificarea funcției main din Listarea 15-14, așa cum este arătat în Listarea 15-15, vom întâmpina o eroare de compilare:
Numele fișierului: src/main.rs
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created.");
c.drop();
println!("CustomSmartPointer dropped before the end of main.");
}Listarea 15-15: Încercarea de a invoca manual metoda drop din trăsătura Drop pentru a realiza o curățare prematură
Când încercăm să compilăm acest cod, vom primi următoarea eroare:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| --^^^^--
| | |
| | explicit destructor calls not allowed
| help: consider using `drop` function: `drop(c)`
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` due to previous error
Acest mesaj de eroare ne spune că nu ne este permis să apelăm explicit drop. Mesajul de eroare folosește termenul destructor, ceea ce în terminologia programării se referă la o funcție care face curățenie după o instanță. Destructorul este analog cu constructorul, care inițiază o instanță. Funcția drop din Rust este un exemplu de destructor.
Rust nu ne permite să apelăm metoda drop în mod explicit pentru că Rust ar apela automat metoda drop pentru valoarea respectivă la terminarea funcției main. Acest lucru ar duce la o eroare de eliberare dublă (double free), deoarece Rust ar încerca să curețe aceeași valoare de două ori.
Nu putem dezactiva inserția automată a metodei drop atunci când o valoare iese din domeniu de vizibilitate, și nici să apelăm explicit metoda drop. Astfel, dacă dorim să forțăm curățarea unei valori mai devreme, trebuie să utilizăm funcția std::mem::drop.
Funcția std::mem::drop diferă de metoda drop din trăsătura Drop. Pentru a o apela, pasăm ca argument valoarea pe care vrem să o ștergem forțat. Această funcție este inclusă în preludiu, astfel că putem modifica funcția main din Listarea 15-15 pentru a apela funcția drop, așa cum se arată în Listarea 15-16:
Numele fișierului: src/main.rs
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("some data"), }; println!("CustomSmartPointer created."); drop(c); println!("CustomSmartPointer dropped before the end of main."); }
Listarea 15-16: Apelând funcția std::mem::drop pentru a elibera explicit o valoare înainte de a ieși din domeniu de vizibilitate
Executând acest cod va genera următoarea afișare:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created.
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main.
Textul 'Dropping CustomSmartPointer with data `some data`!' este afișat între 'CustomSmartPointer created.' și 'CustomSmartPointer dropped before the end of main.', indicând faptul că codul metodei drop este executat pentru a elibera c la acel moment.
Putem utiliza codul specificat într-o implementare a trăsăturii Drop în diverse moduri pentru a asigura o curățare convenabilă și sigură: de exemplu, am putea să îl folosim pentru a dezvolta un propriul nostru alocator de memorie! Beneficiind de trăsătura Drop și de sistemul de posesiune al limbajului Rust, nu trebuie să ne amintim să realizăm curățarea deoarece Rust o face în mod automat.
De asemenea, nu trebuie să ne îngrijorăm referitor la problemele care pot apărea din cauza eliberării accidentale a valorilor încă în folosință: sistemul de posesiune, care se asigură în permanență că referințele sunt valide, mai și garantează că drop este apelat doar o singură dată, când valoarea nu mai este utilizată.
Acum, după ce am investigat Box<T> și unele din caracteristicile pointerilor inteligenți, să explorăm câțiva alți pointeri inteligenți definiți în biblioteca standard.
Rc<T>, pointerul inteligent cu numărare a referințelor
În mare parte din cazuri, conceptul de posesiune este destul de limpede: este evident care variabilă deține o anumită valoare. Cu toate acestea, există situații când o valoare poate fi proprietatea mai multor deținători. Spre exemplu, în structuri de date grafice, multiple muchii pot să indice spre același nod, care este conceptual în posesiunea tuturor muchiilor care îl indică. Acest nod nu ar trebui eliminat până nu rămâne fără nicio muchie care să-l indice, adică fără proprietari.
Posesiunea multiplă trebuie activată în mod intenționat prin utilizarea tipului Rust Rc<T>, acronim pentru reference counted (numărarea referințelor). Tipul Rc<T> urmărește numărul de referințe către o valoare pentru a determina dacă aceasta mai este în uz. Dacă nu există nicio referință către o valoare, aceasta poate fi eliminată fără ca vreo referință să devină nevalidă.
Gândește-te la Rc<T> ca la un televizor în sufragerie. Când cineva intră să vizioneze televizorul, îl pornește. Alți membri pot intra și ei și se pot bucura de program. Când ultimul telespectator părăsește sufrageria, oprește televizorul pentru că nu se mai folosește. Dacă televizorul ar fi întrerupt în timp ce alții încă se uită, ar crea nemulțumire în rândul celor rămași!
Tipul Rc<T> este indicat atunci când vrem să plasăm niște date pe heap pentru a fi accesate de diferite părți ale programului nostru și când nu putem să determinăm la momentul compilării care parte va finaliza utilizarea datelor cel din urmă. Dacă am cunoaște care fragment ar termina în ultimul rând, i-am putea da posesiune asupra datelor și regulile normale de posesiune ar fi aplicate de compilator.
Ține minte că Rc<T> este destinat utilizării în contexte cu un singur fir de execuție (single-threaded). Când vom aborda tema concurenței în Capitolul 16, vom descrie modalitățile de a implementa numărarea referințelor în programele cu executare paralelă (multithread).
Utilizarea Rc<T> pentru partajarea date
Să revenim la exemplul nostru cu lista de tip cons prezentat în Listarea 15-5. Vă amintim că am definit-o utilizând Box<T>. Acum, vom crea două liste care dețin împreună posesiunea unei a treia liste. Conceptual, acest lucru este similar cu Figura 15-3:

Figura 15-3: Două liste, b și c, care dețin împreună posesiunea unei a treia liste, a
Vom construi lista a, care cuprinde numerele 5 și apoi 10. Apoi, vom crea alte două liste: lista b, care pornește cu numărul 3, și lista c, care începe cu 4. Lista b și lista c se vor extinde apoi cu lista a, care include 5 și 10, astfel încât ambele liste vor împărtăși lista a.
Dacă încercăm să implementăm acest scenariu cu definiția noastră a List care folosește Box<T>, descoperim că nu funcționează, așa cum este demonstrat în Listarea 15-17:
Numele fișierului: src/main.rs
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}Listarea 15-17: Demonstrând că nu ne este permis să avem două liste utilizând Box<T> care să încerce să dețină împreună posesiunea unei a treia liste
La compilarea acestui cod, întâmpinăm următoarea eroare:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` due to previous error
Variantelor Cons le aparține în mod exclusiv datele pe care le conțin, așadar atunci când creăm lista b, instanța a este permutată în b și devine posesiunea listei b. Când încercăm să folosim a din nou pentru a crea lista c, nu se poate, deoarece a a fost deja permutată.
În locul acestui lucru, am putea considera modificarea lui Cons pentru a include referințe, însă acest demers ar necesita definitivarea unor parametri ai duratei de viață. Aceasta ar implica că fiecare element al listei trebuie să existe pentru cel puțin tot atât timp cât există lista în totalitate. Acesta este cazul pentru elementele și listele din Listarea 15-17, dar nu este o regulă general valabilă.
În schimb, vom modifica definiția lui List pentru a utiliza Rc<T> în locul lui Box<T>, după cum este ilustrat în Listarea 15-18. Acum, fiecare variantă Cons va conține o valoare și un Rc<T> ce indică spre o listă List. Când realizăm b, nu vom prelua controlul asupra lui a, ci vom clona Rc<List> pe care a îl menține, crescând astfel numărul de referințe de la unu la doi și permițând lui a și b să partajeze posesiunea datelor în respectivul Rc<List>. Vom proceda similar cu clonarea lui a când construim c, mărind numărul de referințe de la doi la trei. La fiecare apel al lui Rc::clone, contorul de referințe la datele din Rc<List> va crește, iar datele nu vor fi eliminate decât când nu vor mai exista referințe către acestea.
Numele fișierului: src/main.rs
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); let b = Cons(3, Rc::clone(&a)); let c = Cons(4, Rc::clone(&a)); }
Listarea 15-18: Definiția lui List folosind Rc<T>
Este necesar să adăugăm o declarație use pentru a importa Rc<T> în domeniul nostru de vizibilitate, deoarece nu este inclus în mod implicit în preludiul limbajului Rust. În funcția main, cream lista ce conține valorile 5 și 10 și o salvăm într-un Rc<List> nou în variabila a. Apoi, la crearea variabilelor b și c, invocăm funcția Rc::clone, oferind ca argument o referință către Rc<List> din a.
Ar fi fost posibil să folosim a.clone() în loc de Rc::clone(&a), dar convenția în Rust este de a folosi Rc::clone în această situație. Implementarea lui Rc::clone nu realizează o copie completă a tuturor datelor, așa cum se întâmplă la cele mai multe implementări ale funcției clone pentru alte tipuri de date. Apelul funcției Rc::clone se limitează la incrementarea contorului de referințe, proces ce nu durează mult. Realizarea de copii complete ale datelor poate fi un proces care să consume timp semnificativ. Utilizând Rc::clone în scopul numărării referințelor, putem face o distincție clară între clonările ce presupun copii complete ale datelor și cele care doar cresc numărul de referințe. Astfel, la căutarea problemelor de performanță în cod, ne vom limita analiza doar la primele și vom ignora apelurile la Rc::clone.
Clonarea unui Rc<T> mărește contorul de referințe
Să ajustăm exemplul nostru actual din Listarea 15-18 pentru a observa cum variază numărul de referințe atunci când sunt create și eliminate referințe către Rc<List> din a.
În Listarea 15-19, vom modifica main pentru a introduce un domeniu de vizibilitate intern în jurul listei c. Astfel, vom putea vedea cum se modifică contorul de referințe odată ce c nu mai este în domeniu.
Numele fișierului: src/main.rs
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); println!("count after creating a = {}", Rc::strong_count(&a)); let b = Cons(3, Rc::clone(&a)); println!("count after creating b = {}", Rc::strong_count(&a)); { let c = Cons(4, Rc::clone(&a)); println!("count after creating c = {}", Rc::strong_count(&a)); } println!("count after c goes out of scope = {}", Rc::strong_count(&a)); }
Listarea 15-19: Afișarea contorului de referințe
În fiecare punct al programului unde contorul de referințe se modifică, afișăm contorul de referințe, obținut prin apelarea funcției Rc::strong_count. Această funcție poartă numele de strong_count în loc de count deoarece tipul Rc<T> include și un weak_count; vom vedea utilizarea weak_count în secțiunea „Evitarea ciclurilor de referințe: Transformarea unui Rc<T> într-un Weak<T>”.
Acest cod va afișa următoarele:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
Observăm că Rc<List> în a pornește cu un contor de referințe de 1; apoi, de fiecare dată când invocăm clone, contorul crește cu 1. Când c nu mai este în scop, contorul scade cu 1. Nu avem nevoie să apelăm o funcție specială pentru a reduce contorul de referințe, așa cum facem cu Rc::clone pentru a-l crește: implementarea trăsăturii Drop diminuează automat contorul de referințe atunci când o valoare Rc<T> părăsește domeniul de vizibilitate.
Ce nu se vede în acest exemplu este faptul că, atunci când b și apoi a nu mai sunt în scop la sfârșitul funcției main, contorul ajunge la 0, iar Rc<List> este eliberat complet. Utilizarea Rc<T> permite ca o valoare unică să aparțină mai multor posesori, contorul asigurând că valoarea rămâne validă atâta timp cât există cel puțin unul din ei.
Printr-o serie de referințe imutabile, Rc<T> ne permite să partajăm date între diverse componente ale programului nostru, limitându-ne doar la citire. Dacă Rc<T> ar oferi posibilitatea de a avea de asemenea referințe mutabile multiple, s-ar putea încălca una dintre regulile de împrumut menționate în Capitolul 4: referințe multiple mutabile către același obiect pot declanșa curse de date și inconsistențe. Totuși, abilitatea de a modifica datele este de mare ajutor! În secțiunea următoare, vom discuta modelul de mutabilitate internă și tipul RefCell<T>, pe care îl poți utiliza împreună cu Rc<T> pentru a gestiona această limitare a imutabilității.
RefCell<T> și mutabilitatea interioară
Mutabilitate interioară este o metodologie de proiectare în Rust care îți permite să modifici datele chiar dacă există referințe imutabile la acele date; de obicei, această acțiune este restricționată de regulile de împrumut. Pentru a modifica datele, această metodă folosește cod unsafe în interiorul unei structuri de date pentru a flexibiliza regulile standard ale Rust privind mutația și împrumutul. Codul unsafe semnalează compilatorului că ne asumăm verificarea regulilor manual, în loc să ne bazăm pe compilator să facă acest lucru; vom detalia codul unsafe în capitolul 19.
Tipurile care implementează conceptul de mutabilitate interioară pot fi utilizate doar atunci când suntem capabili să garantăm respectarea regulilor de împrumut în timp real, chiar dacă compilatorul nu poate oferi această asigurare. În consecință, codul unsafe este învelit într-o interfață API sigură, iar tipul exterior al structurii rămâne imutabil.
Să ne aprofundăm înțelegerea acestui concept prin analiza tipului RefCell<T>, care utilizeară mutabilitatea interioară.
Aplicarea regulilor de împrumut la rulare cu RefCell<T>
În contrast cu Rc<T>, tipul RefCell<T> indică o unică posesiune asupra datelor pe care le deține. Atunci, ce anume diferențiază RefCell<T> de un tip ca Box<T>? Să revedem regulile de împrumut învățate în Capitolul 4:
- În orice moment, se poate avea fie (dar nu și cumulat) o referință mutabilă sau oricâte referințe imutabile.
- Referințele trebuie mereu să fie valide.
Când folosim referințe și Box<T>, invarianțele regulilor de împrumut sunt garantate la timpul de compilare. Pentru RefCell<T>, aceste invarianțe sunt aplicate la rulare. Când încălcăm aceste reguli utilizând referințe, vom întâmpina o eroare de compilator. Cu RefCell<T>, dacă regulile sunt încălcate, programul va genera panică și se va opri.
Avantajul verificării regulilor de împrumut în timpul compilării este acela că erorile sunt descoperite mai devreme în ciclul de dezvoltare, și nu influențează performanța la rulare, deoarece toată analiza este finalizată în prealabil. Aceasta este de ce verificarea în momentul compilării este preferată în majoritatea situațiilor și reprezintă implicita alegere în Rust.
Beneficiul verificării regulilor de împrumut în timpul rulării este că acesta permite anumite situații sigure pentru memoria sistemului, ce ar fi fost altfel refuzate de către verificările de compilare. Analiza statică, cum ar fi cea realizată de compilatorul Rust, este de regulă precaută. Iar unele caracteristici ale codului sunt imposibil de identificat prin simpla analiză: cea mai cunoscută problemă fiind Problema Opririi (the Halting Problem), care este dincolo de scopul acestei cărți, însă constituie un subiect fascinant de cercetare.
Deoarece unele analize sunt de neefectuat, dacă compilatorul Rust nu poate fi absolut sigur că un cod respectă regulile de posesiune, există riscul ca acesta să refuze un program corect; o abordare foarte precaută. Dacă Rust ar accepta un cod greșit, încrederea utilizatorilor în promisiunile Rust ar fi subminată. Pe de altă parte, respingerea unui program corect este doar o neplăcere pentru programator, fără consecințe grave. Tipul RefCell<T> este valoros atunci când ești convins că regulile de împrumut sunt urmate în codul tău, dar compilatorul nu poate confirma și asigura asta.
Ca și Rc<T>, RefCell<T> este menit pentru scenarii în care să se opereze pe un singur fir de execuție și va cauza o eroare la compilare dacă încerci să-l folosești într-un context multithreading. Vom discuta cum să accesăm funcționalitățile RefCell<T> într-o aplicație multithreading în Capitolul 16.
Aceasta este o recapitulare a motivelor de a alege Box<T>, Rc<T>, sau RefCell<T>:
Rc<T>permite mai mulți posesori pentru aceleași date;Box<T>șiRefCell<T>sunt limitate la un singur posesor.Box<T>aduce posibilitatea de împrumuturi imutabile sau mutabile verificate în timpul compilării;Rc<T>permite doar împrumuturi imutabile verificate în aceeași manieră;RefCell<T>oferă împrumuturi imutabile sau mutabile verificate la runtime.- Fiindcă
RefCell<T>admite împrumuturi mutabile verificate pe parcursul execuției, poți modifica valoarea din interiorulRefCell<T>chiar dacă acesta este imutabil.
A modifica valoarea în interiorul unei variabile imutabile ilustrează modelul de mutabilitate interioară. Să investigăm o situație în care mutabilitatea interioară este avantajoasă și să inspectăm cum este posibil acest lucru.
Mutabilitatea internă: Un împrumut mutabil către o valoare imutabilă
Ca urmare a regulilor de împrumut, atunci când ai o valoare imutabilă, nu poți obține un împrumut mutabil pentru aceasta. De exemplu, codul următor nu va fi compilat:
fn main() {
let x = 5;
let y = &mut x;
}Încercând să compilezi codul de mai sus, ai întâmpina următoarea eroare:
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
2 | let x = 5;
| - help: consider changing this to be mutable: `mut x`
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` due to previous error
Există, însă, situații în care ar fi de folos ca o valoare să se poată modifica însăși în metodele sale, dar să pară imutabilă din perspectiva altor părți ale codului. Codul din exteriorul metodelor acelei valori nu ar putea să modifice valoarea. Utilizarea RefCell<T> reprezintă o modalitate de a avea mutabilitate internă, dar RefCell<T> nu evită regulile de împrumut în mod complet: verificatorul de împrumut din compilator permite această mutabilitate internă, dar regulile de împrumut sunt verificate în timpul execuției, nu la compilare. Dacă încalci regulile, vei primi un panic! în loc de o eroare de compilare.
Să analizăm un exemplu practic în care utilizăm RefCell<T> pentru a muta o valoare imutabilă și să descoperim utilitatea acestui lucru.
Un caz practic pentru mutabilitatea internă: Obiectele mock
În timpul procesului de testare, un programator poate utiliza un tip ca substitut pentru altul pentru a analiza anumite comportamente și pentru a confirma că acestea sunt implementate corect. Acest substitut este numit dublură de testare (test double). Poți gândi la acesta ca echivalentul unei „dubluri de cascadorie” în filme, unde cineva intervine și joacă rolul unui actor pentru a realiza o scenă complexă. Obiectele mock (de imitare) sunt un tip specific de dublură de testare care înregistrează ce se petrece în timpul unui test, permițându-ți să verifici că acțiunile întreprinse sunt cele corecte.
În Rust nu există obiecte în modul tradițional ca în alte limbaje, nici nu dispune de funcționalitate pentru obiecte mock încorporată în librăria standard, ca în alte limbaje. Cu toate acestea, este posibil să creezi o structură care să îndeplinească funcțiile unui obiect mock.
Să ne uităm la scenariul pe care urmează să-l testăm: vom construi o librărie care supraveghează o valoare în comparație cu o valoare maximă și trimite mesaje pe baza proximității valorii sale față de acea valoare maximă. De exemplu, librăria ar putea fi utilizată pentru a monitoriza cota de apeluri API la care un utilizator are acces.
Librăria va oferi exclusiv funcții de monitorizare a distanței față de valoarea maximă și de stabilire a mesajelor care trebuie transmise și în ce momente. Se așteaptă ca aplicațiile care folosesc librăria să implementeze mecanismul de trimitere a acestor mesaje: fie că e vorba de integrarea unui mesaj în aplicație, expedierea unui email, trimiterea unui mesaj text sau orice altă metodă. Nu este necesar ca librăria să fie la curent cu aceste detalii. Tot ce necesită este o implementare a trăsăturii pe care o vom oferi și pe care o numim Messenger. Listarea 15-20 ilustrează codul acestei biblioteci:
Filename: src/lib.rs
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}Listarea 15-20: O bibliotecă pentru monitorizarea proximității unei valori față de o valoare maximă și emiterea de avertismente la atingerea anumitor niveluri
Un aspect esențial al acestui cod este faptul că trăsătura Messenger are o metodă numită send, ce primește o referință imutabilă la self și textul mesajului. Această trăsătură constituie interfața pe care mock-ul creat de noi trebuie să o implementeze pentru ca să fie folosit la fel ca un obiect real. A doua Parte importantă este că dorim să testăm comportamentul metodei set_value din clasa LimitTracker. Putem modifica valoarea parametrului value, însă set_value nu returnează nimic pe care să ne bazăm aserțiunile. Ne dorim să putem afirma că dacă inițiem un LimitTracker cu un element ce implementează trăsătura Messenger și o anumită valoare pentru max, atunci când furnizăm valori diferite pentru value, mesagerul primește instrucțiuni să expediază mesaje corespunzătoare.
Avem nevoie de un mock object care, în loc să trimită un email sau un mesaj text când se apelează metoda send, să înregistreze doar mesajele pe care e solicitat să le trimită. Putem crea un exemplar nou al obiectului mock, iniția un LimitTracker care folosește acest mock, invoca metoda set_value pe LimitTracker și apoi să verificăm dacă obiectul mock conține mesajele pe care le anticipăm. Listarea 15-21 prezintă o tentativă de implementare a unui obiect mock în acest sens, însă verificatorul de împrumut nu permite acest lucru:
Filename: src/lib.rs
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}Listarea 15-21: Tentativa de implementare a unui MockMessenger refuzată de verificatorul de împrumut
În codul de test prezentat, definim structura MockMessenger care include un câmp sent_messages cu un Vec de String-uri menit a ține evidența mesajelor ce urmează a fi expediate. Introducem, de asemenea, funcția asociată new, care permite crearea simplă a noilor instanțe MockMessenger cu o listă inițială goală de mesaje. Mai departe, punem în aplicare trăsătura Messenger pentru MockMessenger, astfel încât să putem integra un MockMessenger într-un LimitTracker. În definiția metodei send, încorporăm mesajul primit ca parametru în lista sent_messages a MockMessenger.
Testul nostru are ca obiectiv să determine comportamentul LimitTracker-ului atunci când i se cere să ajusteze value la o valoare ce depășește 75% din max. Inițial, instanțiem un MockMessenger nou, care pornește cu zero mesaje înregistrate. Urmează crearea unui LimitTracker la care atașăm o referință spre MockMessenger și stabilim max la 100. Executăm metoda set_value a LimitTrackerului cu valoarea 80, ce excede 75% din 100. Confirmăm apoi că lista de mesaje monitorizată de MockMessenger ar trebui să conțină acum un mesaj.
Totuși, acest test întâmpină o problemă, așa cum este evidențiat aici:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
2 | fn send(&self, msg: &str);
| ----- help: consider changing that to be a mutable reference: `&mut self`
...
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` due to previous error
warning: build failed, waiting for other jobs to finish...
Nu putem actualiza MockMessenger pentru a evidenția mesajele, pentru că metoda send utilizează o referință imutabilă la self. De asemenea, nu putem adopta sugestia din mesajul de eroare de a folosi &mut self, din motivul că semnătura metodei send nu ar mai fi compatibilă cu cea definită în trăsătura Messenger (ești încurajat să testezi și să vezi ce mesaj de eroare primești).
Aceasta este o situație în care mutabilitatea internă ne poate veni în ajutor! Vom stoca sent_messages într-un RefCell<T>, iar apoi metoda send va putea modifica sent_messages pentru a reține mesajele observate. Listarea 15-22 ne prezintă cum arată acest lucru:
Numele fișierului: src/lib.rs
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Listarea 15-22: Utilizarea RefCell<T> pentru modificarea unei valori interne când valoarea externă este considerată imutabilă
Câmpul sent_messages este acum de tipul RefCell<Vec<String>> în loc de Vec<String>. În funcția new, inițiem o instanță nouă de RefCell<Vec<String>> care încapsulează vectorul gol.
În implementarea metodei send, primul parametru este tot un împrumut imutabil al self, în conformitate cu definiția trăsăturii. Invocăm borrow_mut pe RefCell<Vec<String>> din self.sent_messages pentru a accesa o referință mutabilă la valoarea din RefCell<Vec<String>>, care este vectorul. După aceea, putem apela push pe referința mutabilă la vector pentru a ține evidența mesajelor trimise în timpul testului.
Ultima ajustare ce trebuie făcută este la nivelul aserțiunii: pentru a vedea câte elemente sunt în vectorul intern, invocăm borrow pe RefCell<Vec<String>> pentru a obține o referință imutabilă la vector.
Având o idee generală asupra modului de utilizare a RefCell<T>, să explorăm acum în profunzime cum funcționează acesta!
Monitorizarea împrumuturilor la execuție cu RefCell<T>
Când definim referințe imutabile și mutabile, aplicăm sintaxa & și respectiv &mut. În cazul folosirii RefCell<T>, ne bazăm pe metodele borrow și borrow_mut, ce reprezintă o parte din API-ul sigur (safe) al RefCell<T>. Metoda borrow generează pointerul inteligent de tip Ref<T>, iar borrow_mut produce pointerul inteligent de tip RefMut<T>. Având în vedere că ambele tipuri de pointeri implementează Deref, putem interacționa cu ei la fel ca și cu referințele convenționale.
RefCell<T> contabilizează câți pointeri inteligenți Ref<T> și RefMut<T> sunt activi la moment. La fiecare apel al metodei borrow, RefCell<T> crește contorul de împrumuturi imutabile active. Odată cu ieșirea unei valori Ref<T> din domeniul de vizibilitate, contorul respectiv scade cu unu. În conformitate cu regulile de împrumut stabilite la compilare, RefCell<T> permite existența simultană a mai multor împrumuturi imutabile sau a unui singur împrumut mutabil.
Dacă încălcăm aceste reguli, spre deosebire de obținerea unei erori de compilare, cum ar fi cazul cu referințele standard, implementarea RefCell<T> va declanșa o panică la execuție. Listarea 15-23 modifică implementarea metodei send prezentată în Listarea 15-22. Demonstrăm intenționat încercarea de a activa două împrumuturi mutabile pentru același domeniu de vizibilitate, pentru a arăta că RefCell<T> intervine pentru a preveni acest lucru la timpul execuției.
Numele fișierului: src/lib.rs
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Listarea 15-23: Crearea a două referințe mutabile în același domeniu de vizibilitate pentru a demonstra că RefCell<T> va genera panică
Inițializăm variabila one_borrow pentru pointerul inteligent RefMut<T> returnat de funcția borrow_mut. Apoi, inițializăm o nouă împrumutare mutabilă în mod similar în variabila two_borrow. Aceasta rezultă în două referințe mutabile în același domeniu de vizibilitate, lucru interzis. Când executăm testele pentru biblioteca noastră, codul din Listarea 15-23 va compila fără greșeli, dar testul nu va reuși:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished test [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at 'already borrowed: BorrowMutError', src/lib.rs:60:53
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Notăm că s-a generat panică cu mesajul already borrowed: BorrowMutError. Aceasta este modalitatea prin care RefCell<T> gestionează încălcarea regulilor de împrumut în timpul execuției programului.
Alegerea de a prinde erorile de împrumut în timpul execuției, în loc de în timpul compilării, cum am făcut în acest caz, ar putea însemna identificarea greșelilor din cod mai târziu în procesul de dezvoltare: posibil chiar doar după lansarea codului în producție. De asemenea, codul va suporta un mic cost suplimentar de performanță la execuție din cauza urmăririi împrumuturilor în timp real, în loc de în timpul compilării. Însă utilizarea RefCell<T> permite scrierea unui obiect mock care se poate modifica pentru a înregistra mesajele pe care le primește, chiar și într-un context unde sunt permise doar valori nealterabile. RefCell<T> poate fi folosit, acceptând anumite compromisuri, pentru o funcționalitate sporită față de referințele standard.
Mai mulți posesori de date mutabile prin combinarea Rc<T> cu RefCell<T>
O metodă frecventă de a utiliza RefCell<T> este în combinație cu Rc<T>. Reamintim că Rc<T> permite să avem mai mulți proprietari pentru aceleași date, însă ne oferă doar acces imutabil la ele. Dacă deținem un Rc<T> ce include un RefCell<T>, vom putea avea o valoare care să aibă posesori multipli și să fie mutabilă!
De exemplu, rememorăm exemplul cu lista de tip cons prezentat în Listarea 15-18, unde am utilizat Rc<T> pentru a permite mai multor liste să partajeze posesiunea unei alte liste. Fiindcă Rc<T> permite doar valori imutabile, nu putem altera nicio valoare în listă odată ce acestea au fost create. Adăugând RefCell<T>, obținem posibilitatea de a modifica valorile în cadrul listelor. Listarea 15-24 ilustrează că, integrând RefCell<T> în definiția Cons, putem schimba valoarea depozitată în toate listele:
Numele fișierului: src/main.rs
#[derive(Debug)] enum List { Cons(Rc<RefCell<i32>>, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; fn main() { let value = Rc::new(RefCell::new(5)); let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil))); let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a)); let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a)); *value.borrow_mut() += 10; println!("a after = {:?}", a); println!("b after = {:?}", b); println!("c after = {:?}", c); }
Listarea 15-24: Utilizarea Rc<RefCell<i32>> pentru a crea o Listă ce poate fi modificată
Construim o valoare care este instanța Rc<RefCell<i32>> și o păstrăm într-o variabilă numită value pentru a putea fi accesată direct ulterior. Apoi, generăm o Listă în a cu o variantă Cons care conține value. Este necesar să clonăm value pentru ca atât a, cât și value să dețină posesiunea asupra valorii interne 5, în loc să transferăm posesiunea de la value la a sau ca a să împrumute de la value.
Încapsulăm lista a cu ajutorul Rc<T>, astfel încât, când creăm listele b și c, acestea să se poată referi la a, așa cum am făcut în Listarea 15-18.
După ce am format listele a, b și c, dorim să adăugăm 10 la valoarea din value. Acest lucru îl realizăm apelând borrow_mut pe value, care se folosește de funcția de dereferențiere automată prezentată în Capitolul 5 (consulteză secțiunea „Unde este operatorul ->?”) pentru a dereferenția Rc<T> la valoarea RefCell<T> internă. Metoda borrow_mut ne generează un smart pointer RefMut<T>, iar noi utilizăm operatorul de dereferențiere pentru a schimba valoarea internă.
La afișarea listelor a, b și c, constatăm că toate prezintă noua valoare modificată de 15, nu cea inițială de 5:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
Această abordare este extrem de ingenioasă! Utilizând RefCell<T>, avem de-a face cu o valoare de listă List care pare imutabilă din exterior. Însă, avem la dispoziție metodele de pe RefCell<T> care ne permit accesul la mutabilitatea interioară, astfel încât putem interveni asupra datelor când este necesar. Verificările de runtime privind regulile de împrumut ne apără împotriva conflictelor de date, fiind în anumite cazuri rațional să oferim în schimb o ușoară diminuare a vitezei pentru această flexibilitate adăugată structurilor noastre. E important de reținut că RefCell<T> nu funcționează pentru codul executat pe mai multe thread-uri! Alternativa sigură pentru thread-uri la RefCell<T> este Mutex<T>, pe care o vom explora în Capitolul 16.
Ciclurile de referințe pot provoca scurgeri de memorie
Garanțiile oferite de Rust în privința securității memoriei fac dificilă, dar nu imposibilă, crearea accidentală a memoriei ce nu este curățată niciodată (ceea ce se numește scurgere de memorie). Rust nu garantează prevenirea totală a scurgerilor de memorie, deci scurgerile de memorie sunt considerate sigure din punct de vedere al securității memoriei în Rust. Vedem că Rust admite scurgerile de memorie când folosim Rc<T> și RefCell<T>: este posibil să construim referințe care formează un ciclu, unde elementele se referă reciproc. Acest proces determină scurgeri de memorie pentru că numărul de referințe pentru fiecare element din ciclu nu va scădea vreodată la zero, și în consecință, valorile nu vor fi niciodată eliberate.
Formarea unui ciclu de referințe
Să vedem cum se poate forma un ciclu de referințe și cum să îl evităm, începând cu definiția enum-ului List și cu metoda tail din Listarea 15-25:
Numele fișierului: src/main.rs
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() {}
Listarea 15-25: Definiție pentru o listă de tip cons care include un RefCell<T> ce ne permite să modificăm la ce anume se referă o variantă Cons
Folosim o variantă modificată a definiției List prezentată în Listarea 15-5. Cel de-al doilea element în varianta Cons este acum RefCell<Rc<List>>, astfel că, în loc să modificăm valoarea i32 cum am făcut în Listarea 15-24, acum dorim să putem modifica valoarea de tip List la care se referă varianta Cons. Am inclus și metoda tail pentru a facilita accesul la al doilea element atunci când avem de-a face cu o variantă Cons.
În Listarea 15-26, introducem funcția main care utilizează definițiile din Listarea 15-25. Codul creat generează o listă în variabila a și o altă listă în b care face referire la lista din a. Ulterior, modificăm lista din a astfel încât să indice către b, formând astfel un ciclu de referințe. Folosim instrucțiuni println! pentru a ilustra numărul de referințe la diferite momente ale acestui proces.
Numele fișierului: src/main.rs
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() { let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil)))); println!("a initial rc count = {}", Rc::strong_count(&a)); println!("a next item = {:?}", a.tail()); let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); println!("a rc count after b creation = {}", Rc::strong_count(&a)); println!("b initial rc count = {}", Rc::strong_count(&b)); println!("b next item = {:?}", b.tail()); if let Some(link) = a.tail() { *link.borrow_mut() = Rc::clone(&b); } println!("b rc count after changing a = {}", Rc::strong_count(&b)); println!("a rc count after changing a = {}", Rc::strong_count(&a)); // Uncomment the next line to see that we have a cycle; // it will overflow the stack // println!("a next item = {:?}", a.tail()); }
Listarea 15-26: Construirea unui ciclu de referințe între două valori List ce se referă reciproc
Creăm o instanță Rc<List> ce conține o valoare de tip List în variabila a cu o listă inițială de 5, Nil. Apoi, creăm o nouă instanță Rc<List> care păstrează o altă valoare List în variabila b, aceasta având valoarea 10 și făcând referire la lista din a.
Modificăm a astfel încât acum să indice spre b în loc de Nil, creând astfel un ciclu. Realizăm aceasta prin folosirea metodei tail pentru a accesa o referință la RefCell<Rc<List>> din a, pe care o salvăm în variabila link. Apoi aplicăm metoda borrow_mut pe RefCell<Rc<List>> pentru a schimba valoarea dintr-un Rc<List> ce conține un Nil în Rc<List> referențiat de b.
La rularea acestui cod, lăsând ultimul println! comentat deocamdată, vom primi următorul afișaj:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
Contorul de referințe pentru instanțele Rc<List> din a și b este de 2 după ce am modificat lista din a pentru a pointa acum către b. La terminarea funcției main, Rust renunță la variabila b, reducând contorul de referințe al instanței b Rc<List> de la 2 la 1. Memoria ocupată de Rc<List> în heap nu va fi eliberată în acest punct, deoarece contorul său de referințe este 1, nu 0. Apoi Rust renunță la a, diminuând contorul de referințe al instanței a Rc<List> și el de la 2 la 1. Nici memoria acestei instanțe nu poate fi eliberată, deoarece instanța Rc<List> rămâne cu referință la ea. Astfel, memoria alocată acestei liste va rămâne colectată pe durată nelimitată. Pentru a vizualiza acest ciclu de referințe, am creat o diagramă în Figura 15-4.

Figura 15-4: Un ciclu de referințe în care listele a și b se referă reciproc
Dacă vei decomenta ultimul println! și executa programul din nou, Rust va încerca să afișeze acest ciclu cu a pointând către b, care la rândul său pointează către a și așa mai departe, până când va supraîncărca stiva.
Comparativ cu un program din lumea reală, consecințele creării unui ciclu de referințe în acest exemplu nu sunt foarte severe: imediat după ce creăm ciclul de referințe, programul se încheie. Totuși, în cazul unui program mai complex care alocă o cantitate mare de memorie într-un ciclu și o menține pentru mult timp, acesta ar consuma mai multă memorie decât necesar și ar putea suprasolicita sistemul, ceea ce ar duce la epuizarea memoriei disponibile.
Crearea accidentală a ciclurilor de referințe nu este un proces simplu, dar nu este nici imposibil. Dacă utilizezi valori de tip RefCell<T> ce conțin valori Rc<T> sau combinații tipuri similare cu mutabilitate interioară și numărare de referințe, trebuie să te asigura că nu formezi cicluri; nu te poți baza pe Rust pentru a identifica aceste probleme. Crearea unui ciclu de referințe constituie o eroare de logică în programul tău și ar trebui să utilizezi teste automate, recenzii de cod și alte metodologii de dezvoltare software pentru a le reduce la minim.
O altă soluție pentru evitarea ciclurilor de referințe este reorganizarea structurilor de date astfel încât unele referințe să reprezinte posesiunea, iar altele nu. În consecință, poți avea cicluri constituite din relații de posesiune și relații care nu implică posesiunea, pe când doar relațiile de posesiune influențează posibilitatea de a elibera o valoare. În Listarea 15-25, dorim ca variantele Cons să dețină întotdeauna listele lor, astfel încât reorganizarea structurii de date nu este posibilă. Să examinăm un exemplu folosind grafuri alcătuite din noduri părinte și noduri copil pentru a înțelege când relațiile non-posesive sunt o modalitate adecvată pentru prevenirea ciclurilor de referințe.
Prevenirea ciclurilor de referințe: Convertirea unui Rc<T> în Weak<T>
Până acum, am arătat că invocarea Rc::clone mărește strong_count al unei instanțe Rc<T>, iar o instanță Rc<T> este eliberată din memorie doar când strong_count este 0. Poți crea de asemenea o referință slabă la valoarea conținută de o instanță Rc<T> apelând Rc::downgrade și furnizând o referință la Rc<T>. Referințele puternice reprezintă o metodă de a partaja posesiunea unei instanțe Rc<T>, în timp ce referințele slabe nu reflectă o relație de posesiune și prezența lor nu influențează momentul în care instanța Rc<T> este eliberată. Referințele slabe nu conduc la cicluri de referință deoarece orice ciclu care include referințe slabe se desface atunci când numărul referințelor puternice ale valorilor implicate ajunge la 0.
La apelarea Rc::downgrade, se obține un pointer inteligent de tip Weak<T>. Pe lângă creșterea strong_count în instanța Rc<T> cu 1 cum se întâmplă prin Rc::clone, invocarea Rc::downgrade crește weak_count cu 1. Rc<T> folosește weak_count pentru a contoriza câte referințe Weak<T> active există, asemeni lui strong_count pentru referințele puternice. O diferență majoră este că weak_count nu este nevoit să fie 0 pentru ca instanța Rc<T> să fie eliberată.
Din moment ce valoarea către care Weak<T> referă s-ar putea să fie deja eliberată, pentru a interacționa cu valoarea indicată de un Weak<T> e necesar să verifici dacă valoarea încă există. Acesta se face apelând metoda upgrade la o instanță de Weak<T>, care va returna Option<Rc<T>>. Dacă valoarea Rc<T> nu a fost eliberată, rezultatul va fi Some, în timp ce dacă valoarea Rc<T> a fost eliberată vei obține None. Cu upgrade returnând un Option<Rc<T>>, Rust se asigură că cazurile Some și None sunt adecvat gestionate, evitând existența unui pointer invalid.
Un exemplu ar fi, în loc să utilizăm o listă în care fiecare element știe doar despre următorul element, să construim un arbore unde elementele cunosc atât elementele succesoare care sunt copiii lor cât și elementul anterior care este părintele lor.
Crearea unei structuri de date de tip arbore: un Node cu noduri copil
Pentru început, vom construi un arbore în care nodurile cunosc nodurile lor copil. Vom crea un struct numit Node care conține propria valoare i32 și referințe către valorile Node ale copiilor săi:
Numele fișierului: src/main.rs
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
Dorim ca un Node să își dețină propriii copii și mai dorim să partajăm această posesiune cu variabile pentru a putea accesa direct fiecare Node din arbore. Pentru a realiza acest lucru, definim elementele Vec<T> să fie de tip Rc<Node>. În plus, dorim să putem modifica care noduri sunt copiii altui nod, astfel încât avem un RefCell<T> peste Vec<Rc<Node>> în children.
În continuare, vom folosi definiția noastră de structură pentru a crea o instanță de tip Node denumită leaf cu valoarea 3 și fără copii, și altă instanță de tip Node numită branch cu valoarea 5 și cu leaf ca unul dintre copiii săi, așa cum se arată în Listarea 15-27:
Numele fișierului: src/main.rs
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
Listarea 15-27: Crearea unui nod leaf fără copii și a unui nod branch cu leaf ca unul dintre copiii săi
Facem o clonă a Rc<Node> din leaf și o stocăm în branch, astfel încât nodul din leaf acum are doi proprietari: leaf și branch. Putem naviga de la branch la leaf prin branch.children, dar nu există o cale de a merge de la leaf la branch. Motivul este că leaf nu are o referință către branch și nu cunoaște relația dintre ele. Vrem ca leaf să cunoască că branch este părintele său. Asta vom realiza în pasul următor.
Adăugarea unei referințe de la un nod copil la părintele său
Pentru a-l face pe nodul copil conștient de părintele său, trebuie să adăugăm un câmp parent în definiția noastră a structurii Node. Provocarea este să decidem ce tip ar trebui să fie parent. Știm că nu poate fi Rc<T>, deoarece acesta ar crea un ciclu de referințe cu leaf.parent care arată către branch și branch.children care arată înapoi către leaf, fapt ce ar cauza ca valorile lor de strong_count să nu ajungă niciodată la 0.
Privind relațiile dintr-o altă perspectivă, un nod părinte ar trebui să își dețină copiii: dacă un nod părinte este șters din memorie, nodurile sale copil ar trebui să fie de asemenea șterse. Cu toate acestea, un copil nu ar trebui să-și dețină părintele: dacă ștergem un nod copil, părintele ar trebui să rămână în existență. Acesta este exact un caz pentru referințele slabe!
Prin urmare, în loc de Rc<T>, vom folosi Weak<T> pentru tipul câmpului parent, mai exact RefCell<Weak<Node>>. Cu această schimbare, definiția structurii noastre Node acum arată în felul următor:
Numele fișierului: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
Astfel, un nod va putea să facă referire la nodul părinte fără să îl dețină. În Listarea 15-28, actualizăm funcția main pentru a folosi această nouă definiție, astfel încât nodul leaf să aibă posibilitatea de a se referi la părintele său branch:
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
Listarea 15-28: Un nod leaf cu o referință slabă către părintele său branch
Procesul de creare a nodului leaf este similar cu cel din Listarea 15-27, cu excepția câmpului parent: leaf începe fără un părinte, deci creăm o instanță nouă și goală a referinței Weak<Node>.
Aici, când încercăm să obținem o referință la părintele lui leaf folosind metoda upgrade, primim o valoare None. Acest lucru ni se arată în afișajul de la prima instrucțiune println!:
leaf parent = None
Atunci când construim nodul branch, acesta va avea de asemenea o nouă referință Weak<Node> în câmpul parent, fiindcă branch nu dispune de un nod părinte. Totuși, păstrăm leaf ca fiind unul dintre copiii lui branch. După ce obținem instanța Node în branch, putem modifica leaf pentru a-i atribui o referință Weak<Node> către părintele său. Apelăm metoda borrow_mut asupra lui RefCell<Weak<Node>> din câmpul parent al leaf și apoi folosim funcția Rc::downgrade pentru a crea o referință Weak<Node> către branch plecând de la Rc<Node> din branch.
După ce afișăm din nou părintele lui leaf, de data aceasta vom primi o varianta Some care include branch: acum leaf poate să-și acceseze părintele! În momentul în care afișăm leaf, evităm și ciclul care a condus anterior la o supraîncărcare de stivă cum a avut loc în Listarea 15-26; referințele Weak<Node> sunt afișate ca (Weak):
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
Absența unei ieșiri infinite ne indică faptul că acest cod nu a generat un ciclu de referințe. Acest lucru poate fi de asemenea confirmat prin valorile obținute la apelarea funcțiilor Rc::strong_count și Rc::weak_count.
Vizualizarea schimbărilor în strong_count și weak_count
Să vedem cum valorile strong_count și weak_count ale instanțelor Rc<Node> se modifică prin crearea unui nou domeniu de vizibilitate intern și mutând inițializarea lui branch în acest domeniu. Prin aceasta, putem observa ce se întâmplă când branch este creat și apoi când este eliberat la ieșirea din domeniu. Modificările sunt ilustrate în Listarea 15-29:
Numele fișierului: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); { let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!( "branch strong = {}, weak = {}", Rc::strong_count(&branch), Rc::weak_count(&branch), ); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); } println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); }
Listarea 15-29: Crearea branch într-un domeniu de vizibilitate intern și analiza numărului de referințe puternice și slabe
După inițializarea lui leaf, Rc<Node> aferent are un strong_count de 1 și un weak_count de 0. În domeniul intern, creăm branch și îl asociem cu leaf, iar la acel punct, când printăm contoarele, Rc<Node> din branch va avea un strong_count de 1 și un weak_count de 1 (datorită lui leaf.parent care indică spre branch folosind Weak<Node>). La printarea contoarelor pentru leaf, vom observa că acesta va avea un strong_count de 2, deoarece branch deține acum un clone al Rc<Node> de la leaf în branch.children, dar weak_count va rămâne la 0.
La finalul domeniului intern, branch părăsește domeniul de vizibilitate, iar strong_count pentru Rc<Node> scade la 0, ceea ce duce la eliberarea lui Node. Valoarea lui weak_count de 1 provenind de la leaf.parent nu afectează eliberarea lui Node, așadar nu apar scurgeri de memorie!
Dacă încercăm să accesăm părintele lui leaf după ce domeniul intern se încheie, vom primi din nou None. La finalul programului, Rc<Node> în leaf va avea un strong_count de 1 și un weak_count de 0, fiindcă variabila leaf este din nou unica referință către Rc<Node>.
Toată logica de gestionare a contoarelor și de eliberare a valorilor este inclusă în Rc<T> și Weak<T>, precum și în implementările acestora ale trăsăturii Drop. Prin definirea relației dintre un nod copil și părintele acestuia ca fiind o referință Weak<T> în cadrul definiției lui Node, este posibil să ai noduri părinte care se referă către noduri copil și invers fără a genera cicluri de referințe și scurgeri de memorie.
Sumar
Am acoperit în acest capitol cum să exploatați pointerii inteligenți pentru a face unele garanții și compromisuri diferite comparativ cu cele implicite în Rust prin referințele standard. Tipul Box<T> are o dimensiune definită și se referă la date aflate pe heap. Tipul Rc<T> monitorizează numărul de referințe la datele pe heap, permițând astfel datelor să fie deținute de mai mulți proprietari. RefCell<T>, prin mutabilitatea sa internă, ne oferă un tip care este util atunci când avem nevoie de un obiect imutabil, dar dorim să schimbăm o valoare internă a acestuia; totodată, se asigură că regulile de împrumut sunt respectate în timpul execuției, nu în timpul compilării.
Au fost, de asemenea, discutate trăsăturile Deref și Drop, care fac posibilă o mare parte din funcționalitățile pointerilor inteligenți. Am explorat ciclurile de referință care pot provoca scurgeri de memorie și cum să le prevenim prin utilizarea Weak<T>.
Dacă te-a captivat acest capitol și ai vrea să creezi proprii tăi pointeri inteligenți, te încurajăm să consulți „The Rustonomicon” pentru mai multe informații de valoare.
În capitolul următor, vom explora programarea concurentă în Rust. Și chiar vei avea ocazia să înveți despre careva noi tipuri de pointeri inteligenți.
Concurență fără temeri
Unul dintre principalele obiective ale Rust este să faciliteze o programare concurentă sigură și eficientă. Programarea concurentă, care permite executarea independentă a diferitelor componente ale unui program, și programarea paralelă, care permite execuția simultană a acestora, devin tot mai relevante pe măsură ce computerele extind utilizarea procesoarelor multiple. În trecut, aceste forme de programare au prezentat dificultăți semnificative și erau predispuse la greșeli: Rust intenționează să revoluționeze acest domeniu.
La început, echipa Rust era de părere că asigurarea siguranței memoriei și prevenirea problemelor de concurență sunt două provocări distincte, ce ar trebui soluționate cu metode diferite. Cu timpul, echipa a realizat că sistemele de posesiune și de tipizare sunt un set de unelte extrem de eficiente în gestionarea atât a siguranței memoriei cât și a problemelor de concurență! Folosindu-se de conceptul de posesiune și verificarea tipurilor, multe erori legate de concurență se transformă în erori de compilare în Rust, în loc de erori de rulare. Deci, în loc să pierzi timp încercând să reproduci condițiile exacte în care apare un bug de concurență la execuție, codul eronat pur și simplu nu va compila, afișând o eroare ce explică problema. Prin urmare, poti rectifica codul în timp ce lucrezi la el, nu după ce acesta a ajuns deja în producție. Această abordare din Rust este cunoscută sub numele de concurența fără teamă. Concurența fără teamă îți oferă posibilitatea de a scrie cod fără bug-uri subtile și care poate fi refactorizat cu ușurință fără a introduce noi erori.
Notă: Pentru a menține simplitatea, vom numi multe dintre probleme ca fiind concurente în loc de a fi mai preciși și a spune concurente și/sau paralele. Dacă subiectul acestei cărți ar fi fost concurența și/sau paralelismul, am fi fost mai expliciți. Pentru acest capitol, te rog să substitui mental concurente și/sau paralele de fiecare dată când folosim termenul concurente.
Multe limbaje sunt rigide când vine vorba de soluțiile pe care le propun pentru gestionarea problemelor de concurență. De exemplu, Erlang oferă facilități elegante pentru concurența prin pasare de mesaje, dar are doar câteva metode obtuze pentru a împărtăși starea între fire de execuție. A susține exclusiv o gamă limitată de soluții este o strategie acceptabilă pentru limbajele de nivel înalt, dat fiind că aceste limbaje promit avantaje prin sacrificarea unei părți din control în schimbul abstracțiilor. În schimb, limbajele de nivel jos sunt așteptate să furnizeze soluția cu cea mai bună performanță în fiecare situație specifică și oferă mai puține abstracții ale hardware-ului. Așadar, Rust pune la dispoziție o gamă variată de instrumente pentru modelarea problemelor în orice mod se potrivește cel mai bine situației și necesităților tale.
Iată temele pe care le vom aborda în acest capitol:
- Cum să inițiezi thread-uri pentru a executa simultan mai multe porțiuni de cod
- Concurența prin pasarea de mesaje, unde canale comunică mesaje între fire de execuție
- Concurența cu stare partajată, unde mai multe fire de execuție au acces la același fragment de date
- Trăsăturile
SyncșiSend, care extind garanțiile de concurență oferite de Rust către tipurile definite de utilizator, precum și către cele oferite de biblioteca standard
Utilizarea firelor de execuție pentru a executa cod simultan
În cele mai multe sisteme de operare actuale, codul unui program executat este rulat în cadrul unui proces, iar sistemul de operare gestionează în același timp multiple procese. În interiorul unui program, poți avea de asemenea părți independente care rulează simultan. Capabilitățile care execută aceste părți independente se numesc fire de execuție, or thread-uri. De exemplu, un server web poate avea mai multe thread-uri pentru a răspunde simultan la mai multe cereri.
Împărțirea calculului din programul tău în mai multe fire de execuție pentru a rula simultan mai multe sarcini poate îmbunătăți performanța, dar adaugă și complexitate. Fiindcă thread-urile pot rula simultan, nu există o garanție implicită asupra ordinii în care secțiunile de cod de pe diferite thread-uri se vor executa. Aceasta poate cauza probleme, cum ar fi:
- Condiții de cursă (Race conditions), când thread-urile accesează date sau resurse într-un ordine neconsistentă
- Interblocaje (Deadlocks), în situația unde două thread-uri așteaptă unul pe celălalt, împiedicând astfel continuarea ambelor thread-uri
- Erori care apar numai în anumite condiții și sunt dificil de reprodus și de reparat în mod fiabil
Rust încearcă să minimizeze efectele negative ale utilizării thread-urilor, însă programarea într-un context multithreaded necesită o gândire meticuloasă și impune o structură a codului diferită de cea a programelor rulate într-un singur fir.
Limbajele de programare implementează thread-uri în diferite moduri, iar multe sisteme de operare furnizează un API pe care limbajul îl poate folosi pentru a crea noi thread-uri. Biblioteca standard Rust utilizează un model de implementare 1:1 pentru thread-uri, prin care un program folosește un thread de sistem de operare pentru fiecare thread de limbaj. Există crate-uri care pun în practică alte modele de threading ce oferă compromisuri diferite comparativ cu modelul 1:1.
Crearea unui fir nou de execuție cu spawn
Pentru a crea un fir nou de execuție, apelăm funcția thread::spawn la care pasăm o închidere (discutate în Capitolul 13) care conține codul ce urmează să fie executat în nou-creatul fir de execuție. Exemplul din Listarea 16-1 afișează un text din firul principal și alt text dintr-un fir nou-creat:
Numele fișierului: src/main.rs
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { for i in 1..10 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } }
Listarea 16-1: Crearea unui nou fir de execuție pentru a printa ceva, în timp ce firul principal printează altceva
Notăm că atunci când firul principal al unui program Rust se finalizează, toate firele secundare care au fost create sunt închise, indiferent dacă și-au finisat execuția sau nu. Rezultatul executării acestui program poate varia la fiecare rulare, dar va arăta similar cu următoarea afișare:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the main thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
Apelurile la thread::sleep determină un fir de execuție să își întrerupă temporar execuția, ceea ce permite altui fir să preia controlul. Este posibil ca firele să se alterneze, dar nu este garantat, deoarece acest lucru depinde de cum sistemul de operare gestionează secvențierea firelor de execuție. În această execuție, firul principal a făcut prima afișare, chiar dacă instrucțiunea de printare din firul secundar apare prima în cod. Chiar dacă i s-a specificat firului secundar să continue printarea până când i ajunge la 9, acesta a reușit doar să ajungă la 5 înainte ca firul principal să fie închis.
În cazul în care executând acest cod observi doar rezultate din partea firului principal, sau nu există nicio suprapunere, încearcă să extinzi valorile maxime pentru a oferi mai multe șanse sistemului de operare să alterneze între firele de execuție.
Așteptarea finalizării tuturor firelor de execuție folosind join
Codul din Listarea 16-1 nu doar că oprește prematur firul de execuție creat din cauza terminării firului principal, dar dat fiind faptul că nu există o garanție cu privire la ordinea execuției firelor de execuție, de asemenea nu putem asigura că firul de execuție creat va rula în genere!
Problema firului de execuție creat care nu rulează sau care se încheie prematur poate fi rezolvată salvând valoarea returnată de thread::spawn într-o variabilă. Tipul returnat de thread::spawn este un descriptor JoinHandle. Un JoinHandle este o valoare deținută (owned) care, la apelarea metodei join pe aceasta, va aștepta finalizarea firului de execuție asociat. Listarea 16-2 ilustrează utilizarea lui JoinHandle pentru firul de execuție creat în Listarea 16-1 și invocarea lui join pentru a ne asigura că firul de execuție inițiat se finalizează înainte de terminarea funcției main:
Numele fișierului: src/main.rs
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } handle.join().unwrap(); }
Listarea 16-2: Salvând un JoinHandle de la thread::spawn pentru a asigura finalizarea completă a firului de execuție
Apelarea lui join pe descriptor blochează firul de execuție curent până când firul reprezentat de acel descriptor se termină. Blocarea unui fir de execuție împiedică acesta să efectueze sarcini sau să se termine. De aceea, punând apelul la join după bucla for a main thread-ului, executarea Listării 16-2 ar trebui să genereze un afișaj similar cu acesta:
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 1 from the spawned thread!
hi number 3 from the main thread!
hi number 2 from the spawned thread!
hi number 4 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
Ambele fire de execuție continuă să alterneze, însă firul principal așteaptă datorită apelului metodei join pe descriptor și nu se va încheia până nu se finalizează firul de execuție inițiat.
Acum, să analizăm ce se întâmplă dacă mutăm handle.join() înainte de bucla for în funcția main, în felul următor:
Numele fișierului: src/main.rs
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); handle.join().unwrap(); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } }
Thread-ul principal va aștepta finalizarea firului de execuție inițiat și apoi va executa propria buclă for, astfel încât afișajul nu va mai fi intercalat, după cum putem vedea aici:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
Detalii subtile, precum locația unde este invocat join, pot influența dacă firele de execuție se vor rula simultan sau nu.
Folosirea închiderilor move cu fire de execuție
Frecvent, utilizăm cuvântul cheie move cu închiderile transmise la thread::spawn, deoarece în acest mod închiderea preia posesiunea asupra valorilor utilizate din mediu, transferând astfel posesiunea acestor valori de la un fir de execuție la altul. În secțiunea „Capturarea referințelor sau transferul posesiunii” din Capitolul 13, am discutat despre move în contextul închiderilor. Acum, vom aprofunda interacțiunea dintre move și thread::spawn.
În Listarea 16-1 putem observa că închiderea pe care o trecem la thread::spawn nu are argumente: nu utilizăm date din firul de execuție principal în codul firului de execuție nou. Pentru a folosi date din firul principal în cel nou, închiderea firului de execuție trebuie să captureze valorile necesare. Listarea 16-3 ne arată o tentativă de a folosi un vector creat în firul de execuție principal într-un fir secundar. Cu toate acestea, momentan acest lucru nu funcționează, cum vom vedem mai jos.
Numele fișierului: src/main.rs
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {:?}", v);
});
handle.join().unwrap();
}Listarea 16-3: Încercarea de utilizare a unui vector creat în firul de execuție principal într-un alt fir de execuție
Închiderea utilizează v, așadar va captura v și o va integra în mediul închiderii. Deoarece thread::spawn execută această închidere într-un fir de execuție nou, teoretic ar trebui să fie posibilă accesarea variabilei v în acest fir. Dar când încercăm să compilăm exemplul, întâmpinăm eroarea următoare:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {:?}", v);
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {:?}", v);
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` due to previous error
Rust face inferențe cu privire la modul de capturare a lui v, și pentru că macro-ul println! necesită doar o referință la v, închiderea încearcă să împrumute v. Există, însă, o dificultate: Rust nu poate determina durata de execuție a firului nou, deci nu poate garanta că referința la v va rămâne validă.
Listarea 16-4 ilustrează un scenariu în care este improbabil ca referința la v să fie validă:
Numele fișierului: src/main.rs
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {:?}", v);
});
drop(v); // oh no!
handle.join().unwrap();
}Listarea 16-4: Un fir de execuție cu o închidere care încearcă să capteze o referință la v din firul de execuție principal care apoi renunță la v
Dacă Rust ar permite execuția acestui cod, am putea fi confruntați cu situația în care firul nou este mutat în fundal fără să fie executat. Firul de execuție are o referință la v la interior, dar firul principal renunță la v folosind funcția drop descrisă în Capitolul 15. Când apoi firul nou începe execuția, v nu mai este disponibil, făcând referința la acesta invalidă. O, nu!
Pentru rezolvarea erorii de compilare din Listarea 16-3, putem urma sugestia furnizată de mesajul de eroare:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
Prin adăugarea cuvântului cheie move în fața închiderii, obligăm închiderea să preia posesiunea asupra valorilor pe care le utilizează, în loc de a-l lăsa pe Rust să facă inferențe despre împrumutarea acestora. Modificările efectuate în Listarea 16-3, reprezentate în Listarea 16-5, vor permite compilarea și executarea codului așa cum intenționam:
Filename: src/main.rs
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(move || { println!("Here's a vector: {:?}", v); }); handle.join().unwrap(); }
Listarea 16-5: Folosirea cuvântului cheie move pentru a obliga o închidere să preia posesiunea valorilor pe care le utilizează
Am putea fi ispitiți să încercăm același lucru pentru a remedia codul din Listarea 16-4 în care firul principal a invocat drop, folosind o închidere move. Totuși, această reparație nu va funcționa pentru că ceea ce încearcă să realizeze Listarea 16-4 este interzis dintr-un alt motiv. Adăugând move la închiderea respectivă, am transfera v în contextul închiderii și nu am mai putea apela funcția drop pe acesta în firul principal. Ne-am confrunta în loc cu următoarea eroare de la compilator:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {:?}", v);
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` due to previous error
Regulile de posesiune din Rust ne-au salvat încă o dată! Am primit o eroare pentru codul din Listarea 16-3 pentru că Rust a fost precaut, alegând doar să împrumute variabila v firului secundar de execuție, ce ar fi putut cauza ca firul principal să invalideze referința firului pornit. Instruind Rust să mute posesiunea lui v către firul pornit, îi garantăm că firul principal nu o va mai folosi. Schimbând Listarea 16-4 în același mod, încălcăm regulile de posesiune când încercăm să accesăm v în firul principal. Cuvântul cheie move anulează comportamentul implicit precaut al Rust de a împrumuta; nu ne permite să încălcăm regulile de posesiune.
Înarmat cu noțiuni fundamentale despre firele de execuție și API-ul lor, să descoperim ce putem realiza cu ajutorul acestor fire.
Transferul datelor între fire de execuție cu pasare de mesaje
Pasarea de mesaje (message passing) este o metodă din ce în ce mai adoptată pentru a garanta concurența sigură. Această abordare implică comunicarea între fire de execuție sau actori prin intermediul mesajelor care includ date. Un slogan din documentația limbajului Go rezumă această filosofie: "Nu comunicați prin partajarea memoriei; în schimb, partajați memoria comunicând."
Rust îmbrățișează acest concept prin canale (channels), facilități oferite de biblioteca standard pentru implementarea concurenței prin trimiterea de mesaje. Un canal este un concept comun în programare pentru a transmite date de la un fir de execuție la altul.
Putem asemăna un canal în programare cu un torent de apă curgătoare, de exemplu un râu, în care obiectele plasate în apă se deplasează într-o singură direcție. Dacă introduci o rațușcă de cauciuc într-un râu, ea va pluti până la destinația din aval.
Un canal este format dintr-un emițător și un receptor. Emițătorul, situat "amonte", este locul de unde "lansezi rața de cauciuc", iar receptorul sau "avalul" este punctul unde aceasta ajunge. În practică, o parte din cod va invoca metode pe emițător pentru a trimite date, iar o altă parte va prelucra mesajele care ajung la receptor. Dacă una dintre aceste componente este distrusă, canalul este considerat închis.
Vom exemplifica această noțiune printr-un program care include un fir de execuție ce generează valori și le trimite printr-un canal și un alt fir care le recepționează și le afișează. Vom demonstra trimiterea de valori simple prin canal pentru a evidenția funcționalitatea. După ce te familiarizezi cu această abordare, poți extinde utilizarea canalelor pentru orice fire de execuție care necesită comunicare, de exemplu într-un sistem de chat sau într-un sistem de calcul distribuit unde diferite fire procesează părți dintr-o sarcină și le trimit spre un fir central care le integrează.
În prima etapă, în Listarea 16-6, intenționăm să creăm un canal, dar nu vom interacționa cu acesta. Este important de notat că acest cod nu va compila încă, pentru că Rust nu poate identifica tipul valorilor pe care dorim să le transmitem prin canal.
Numele fișierului: src/main.rs
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}Listarea 16-6: Crearea unui canal și împărțirea acestuia în două părți, tx și rx
Inițiem un canal nou cu ajutorul funcției mpsc::channel; unde mpsc sugerează ideea de producător multiplu, consumator unic (multiple producer, single consumer). Pe scurt, implementarea canalelor în biblioteca standard Rust permite existența mai multor puncte de transmitere care produc valori, dar numai un singur punct de recepție pentru a le consuma. Să ne imaginăm mai multe pârâiașe care se unesc într-un singur fluviu: orice este trimis prin aceste pârâiașe va ajunge inevitabil în fluviul mare. Pentru început, vom folosi un singur producător, urmând să adăugăm alți producători odată ce acest exemplu va fi funcțional.
Funcția mpsc::channel returnează o tuplă, ale cărei elemente sunt: primul - punctul de transmitere--transmițătorul--și al doilea - punctul de recepție--receptorul. Abrevierile tx pentru transmițător și rx pentru receptor sunt uzate frecvent în diverse domenii, astfel le vom folosi și noi pentru a denumi variabilele, marcând fiecare capăt al canalului. Aplicăm o declarație let cu un șablon care destramă tupla; mai multe despre șabloane în declarațiile let și destructurarea acestora vom explora în Capitolul 18. Pe moment, este suficient să înțelegem că utilizarea declarației let în acest mod este eficientă pentru a desface componentele tuplei oferite de mpsc::channel.
Permutăm punctul de transmitere într-un fir separat și îi permitem să expedieze un string către firul secundar, facilitând astfel comunicarea dintre noul fir de execuție și firul principal, conform exemplului prezentat în Listarea 16-7. Este ca și cum am pune o rață de cauciuc în apa râului în amonte sau am trimite un mesaj text de la un fir la altul.
Numele fișierului: src/main.rs
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); }); }
Listarea 16-7: Mutarea tx într-un fir de execuție creat și trimiterea mesajului “hi”
Din nou, folosim thread::spawn pentru a iniția un nou fir de execuție și apoi move pentru a permuta tx în închidere astfel încât noul firul de execuție să dețină tx. Firul de execuție creat are nevoie să dețină emitentul pentru a putea transmite mesaje prin canal. Emitentul dispune de metoda send, ce acceptă valoarea pe care dorim să o expediem. Metoda send returnează o structură de tip Result<T, E>, astfel că, dacă receptorul a fost deja eliminat din memorie și nu mai există un destinatar pentru valoare, operațiunea de trimitere va resulta într-o eroare. În acest exemplu, folosim unwrap pentru a induce panică în caz de eroare. Totuși, într-o aplicație reală, am aborda această situație corespunzător: vezi Capitolul 9 pentru a reexamina strategiile adecvate de gestionare a erorilor.
În Listarea 16-8, vom prelua valoarea de la receptor în firul principal. Este ca și cum am scoate rața de cauciuc din apă în punctul final al râului sau cum am primi un mesaj de chat.
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); }); let received = rx.recv().unwrap(); println!("Got: {}", received); }
Listarea 16-8: Primirea valorii “hi” în firul principal și afișarea acesteia
Receptorul are două metode utile: recv și try_recv. Utilizăm recv, abreviere pentru receive, care va opri temporar execuția firului principal și va aștepta până când o valoare va fi expediată prin canal. După expedierea unei valori, recv o va returna ca un Result<T, E>. Când emitentul se deconectează, recv va semnala prin intermediul unei erori că nu vor mai sosi valori suplimentare.
Metoda try_recv nu înterupe execuția, dar returnează imediat un Result<T, E>: o valoare Ok care conține un mesaj dacă este disponibil unul sau o valoare Err dacă nu există mesaje în acel moment. Utilizarea try_recv este eficientă dacă firul de execuție are alte activități de îndeplinit în timp ce așteaptă mesaje; am putea implementa o buclă care apelează try_recv periodic și procesează mesajul, dacă este disponibil unul, sau continuă cu alte sarcini pentru o perioadă, înainte de a verifica din nou.
Am ales recv pentru acest exemplu datorită simplității; nu avem nicio altă sarcină pentru firul principal decât așteptarea mesajelor, așa că oprirea temporară a execuției firului principal este justificată.
Când executăm codul din Listarea 16-8, vom observa valoarea afișată de către firul principal:
Got: hi
Perfect!
Canale și transferul de posesiune
Regulile de posesiune sunt vitale în trimiterea mesajelor deoarece ajută la scrierea de cod sigur și concurent. Prevenirea erorilor în programarea concurentă este un beneficiu al gândirii în termeni de posesiune de-a lungul programelor tale în Rust. Să realizăm un experiment pentru a demonstra cum canalele și posesiunea colaborează pentru a evita problemele: vom încerca să utilizăm o valoare val în firul de execuție derivat după ce am trimis-o prin canal. Încearcă să compilezi codul din Listarea 16-9 pentru a vedea motivul pentru care acest cod nu este acceptat:
Numele fișierului: src/main.rs
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {}", val);
});
let received = rx.recv().unwrap();
println!("Got: {}", received);
}Listarea 16-9: Tentativa de utilizare a val după ce a fost trimisă prin canal
Aici, încercăm să afișăm val după ce am trimis-o prin canal cu ajutorul tx.send. A permite acest lucru ar constitui o idee rea: odată ce valoarea a fost trimisă unui alt fir de execuție, acel fir ar putea să modifice sau să elibereze valoarea înainte ca noi să încercăm utilizarea acesteia. Modificările aduse de celălalt fir ar putea duce la erori sau rezultate neașteptate datorate datelor inconsistente sau inexistente. Iarăși, Rust ne returnează o eroare dacă încercăm să compilăm codul din Listarea 16-9:
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:31
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {}", val);
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` due to previous error
Greșeala noastră de concurență a produs o eroare la timpul compilării. Funcția send preia posesiunea parametrului său, iar atunci când valoarea este permutată, receptorul devine noul posesor al acesteia. Aceasta ne previne să folosim din greșeală valoarea încă o dată după trimiterea ei; sistemul de posesiune se asigură că totul este corect.
Trimiterea de multiple valori și observarea așteptării receptorului
Codul din Listarea 16-8 a fost compilat și a rulat, dar nu a demonstrat clar că două fire separate de execuție comunica între ele prin canal. În Listarea 16-10 am efectuat niște modificări care vor demonstra cum codul din Listarea 16-8 execută operațiuni în mod concurent: firul de execuție derivat va trimite acum mai multe mesaje și va însera o pauză de o secundă între fiecare.
Numele fișierului: src/main.rs
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {}", received);
}
}Listarea 16-10: Trimite mai multe mesaje și pauza între ele
În acest exemplu, firul derivat are un vector de string-uri pe care vrea să le trimită către firul principal. Iterăm pe acest vector, trimițând fiecare string în parte și folosind o pauză, invocând thread::sleep cu o valoare Duration de o secundă pe iterație.
În firul principal, nu mai apelăm funcția recv în mod direct; acum tratăm rx ca pe un iterator. Imprimăm fiecare valoare primită și când canalul se închide, iterația se oprește.
Rulând codul din Listarea 16-10, ar trebui să vezi următoarele mesaje afișate cu o pauză de 1 secundă între fiecare:
Got: hi
Got: from
Got: the
Got: thread
Faptul că bucla for din firul principal nu conține niciun cod care să producă întârzieri ne spune că firul principal așteaptă să primească valori de la firul derivat.
Crearea mai multor producători prin clonarea transmițătorului
Anterior, am menționat că mpsc este acronimul pentru producător multiplu, consumator unic. Să utilizăm mpsc și să extindem codul din Listarea 16-10 pentru a crea multiple fire de execuție care trimit valori către același receptor. Putem realiza acest lucru prin clonarea transmițătorului, așa cum este ilustrat în Listarea 16-11:
Numele fișierului: src/main.rs
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {}", received);
}
// --snip--
}Listarea 16-11: Transmiterea mai multor mesaje de la mai mulți producători
De această dată, înainte de a genera primul fir, apelăm metoda clone pe transmițător. Aceasta ne va oferi un nou transmițător pe care îl putem folosi în primul fir derivat. Transmițătorul original îl oferim unui al doilea fir derivat. Astfel obținem două fire de execuție, fiecare transmițând mesaje diferite către același receptor.
Atunci când rulezi codul, afișajul ar trebui să arate într-un fel similar cu acesta:
Got: hi
Got: more
Got: from
Got: messages
Got: for
Got: the
Got: thread
Got: you
Poți observa valorile într-o altă ordine, depinde de sistemul tău. Acest lucru face din concurență un subiect atât de interesant, cât și de dificil de abordat. Dacă joci cu valorile thread::sleep în diferitele fire, vei face ca fiecare execuție să fie mai puțin deterministă și să producă un afișaj diferit de fiecare dată.
După ce am analizat modul în care funcționează canalele, să trecem la o altă abordare a concurenței.
Concurență cu stare partajată
Transmiterea mesajelor constituie o metodă eficientă de abordare a concurenței, dar nu este unica. O altă cale este ca mai multe fire de execuție să aibă acces simultan la aceleași date partajate. Să ne reamintim de sloganul din documentația limbajului Go: "nu comunicați prin partajarea memoriei".
Dar cum ar arăta comunicarea prin partajarea memoriei? Și de ce ar îndruma avocații transmiterii mesajelor împotriva utilizării partajării memoriei?
Fundamental, canalele în cadrul oricărui limbaj de programare sunt comparabile cu ideea de posesiune unică, în sensul că după ce trimiți o valoare printr-un canal, nu ar trebui să o mai folosești. În contrast, concurența cu memorie partajată se aseamănă cu posesiunea multiplă, permițând mai multor fire accesul concomitent la aceeași locație de memorie. Cum am observat în Capitolul 15, cu ajutorul pointerilor inteligenți, posesiunea multiplă implică o complexitate sporită, deoarece trebuie gestionată coexistența acestor proprietari multipli. Sistemul de tipuri din Rust și regulile sale de posesiune oferă un sprijin considerabil în obținerea unei gestionări corecte. Pentru a ilustra, să examinăm mutexurile, una dintre cele mai răspândite primitive pentru concurența bazată pe memorie partajată.
Utilizarea unui mutex pentru acces exclusiv la date
Mutex reprezintă o abreviere pentru excludere reciprocă, adică un mutex permite accesul la date doar unui singur fir de execuție la un anumit moment. Pentru a accesa datele protejate de un mutex, un fir trebuie mai întâi să indice că își dorește accesul obținând lock-ul acestui mutex. Lock-ul este o structură de date care face parte din mutex și care monitorizează cine deține accesul exclusiv la date. Așadar, se spune că mutexul protejează datele pe care le conține folosind mecanismul de blocare.
Mutexurile sunt recunoscute pentru complexitatea lor în utilizare, de vreme ce trebuie să reținem două reguli importante:
- Trebuie să încerci să dobândești lock-ul înainte de a utiliza datele.
- Când ai terminat cu datele protejate de mutex, trebuie să eliberezi datele astfel încât alte fire să poată dobândi lock-ul.
Pentru o metaforă din viața reală a unui mutex, gândește-te la o dezbatere din cadrul unei conferințe care dispune de un singur microfon. Înainte ca un participant să poată interveni, trebuie să ceară sau să semnaleze că dorește să utilizeze microfonul. După ce a primit microfonul, poate să vorbească pentru perioada pe care o dorește și apoi să treacă microfonul următorului care a cerut să intervină. Dacă un participant uită să paseze microfonul când a terminat, nimeni altcineva nu va putea să vorbească. Dacă gestionarea microfonului partajat este defectuoasă, dezbaterea nu va decurge conform planificării!
Manevrarea mutexurilor poate fi un proces extrem de anevoios de stăpânit, ceea ce explică entuziasmul multora pentru canale. Totuși, datorită sistemului de tipuri și regulilor de posesiune din Rust, nu te poți încurca în operațiunile de blocare și deblocare.
API-ul lui Mutex<T>
Pentru a exemplifica utilizarea unui mutex, să demarăm prin incorporarea sa într-un context cu un singur fir de execuție, după cum vedem în Listarea 16-12:
Numele fișierului: src/main.rs
use std::sync::Mutex; fn main() { let m = Mutex::new(5); { let mut num = m.lock().unwrap(); *num = 6; } println!("m = {:?}", m); }
Listarea 16-12: Explorarea API-ului Mutex<T> într-un context cu un singur fir, pentru simplificare
Precum în cazul multor alte tipuri, instanțiem un Mutex<T> printr-o apelare la funcția asociată new. Ca să ajungem la datele din mutex, folosim metoda lock pentru a obține blocarea. Această operațiune va suspenda firul de execuție actual, fără a mai putea efectua alte sarcini până când îi vine rândul să preia controlul blocării.
Această apelare la lock ar da greș dacă un alt fir care are blocarea ar genera panică. În acest caz, blocarea n-ar mai putea fi preluată de nimeni, motiv pentru care am optat pentru unwrap, pentru a provoca panică în firul de execuție dacă ne confruntăm cu acest scenariu.
Odată blocarea obținută, putem considera valoarea returnată, pe care o numim num aici, ca pe o referință mutabilă către conținutul interior. Sistemul de tipuri Rust ne asigură că trebuie să avem blocarea înainte de a folosi valoarea din m. Fiindcă m este de tip Mutex<i32> și nu i32, este imperativ să invocăm lock pentru a putea opera cu valoarea i32. Datorită sistemului de tipuri nu ni se va permite să sărim peste acest pas.
Așa cum ai putea bănui, Mutex<T> funcționează ca un pointer inteligent. Mai precis, apelul la lock returnează un pointer inteligent denumit MutexGuard, ambalat într-un LockResult cu care ne-am ocupat prin unwrap. MutexGuard implementează Deref pentru a putea accesa datele interne, iar de asemenea dispune de implementarea Drop, care eliberează blocarea automat atunci când MutexGuard părăsește domeniul de vizibilitate, la finalul domeniului interior. Acest lucru înlătură riscul de a uita să eliberăm blocarea și de a împiedica folosirea mutexului de alte fire, pentru că eliberarea are loc automat.
După ce am eliberat blocarea, avem posibilitatea să afișăm valoarea mutex-ului și să constatăm că i-am modificat valoarea interioară i32 la 6.
Partajarea unui Mutex<T> între fire multiple
Să încercăm să partajăm o valoare între mai multe fire de execuție utilizând Mutex<T>. Vom lansa 10 fire și le vom permite fiecăruia să crească un contor cu 1, astfel încât contorul să ajungă de la 0 la 10. Următorul exemplu din Listarea 16-13 va produce o eroare de compilare, eroare din care vom învăța mai multe despre cum să utilizăm Mutex<T> în mod corect.
Numele fișierului: src/main.rs
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Listarea 16-13: Zece fire fiecare incrementând un contor protejat prin intermediul unui Mutex<T>
Începem prin a crea o variabilă counter ce conține un i32 în cadrul unui Mutex<T>, așa cum am procedat în Listarea 16-12. Apoi, generăm 10 fire iterând printr-un interval de numere, utilizând thread::spawn și oferind tuturor firelor aceeași închidere: una care transferă contorul în interiorul firului de execuție, obține blocarea pe Mutex<T> invocând metoda lock, după care adaugă 1 la valoarea aflată în mutex. Când un fir termină de executat funcția lambda, num va ieși din domeniul de vizibilitate și va elibera blocarea, permițând altui fir să o preia.
În firul principal, colectăm toți descriptorii de join. Ca în Listarea 16-2, apelăm join pe fiecare descriptor, pentru a ne asigura că toate firele sunt finalizate. În acel moment firul principal va obține blocarea și va afișa rezultatul acestui program.
Anterior am menționat că acest exemplu nu va compila. Să descoperim acum motivul!
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: use of moved value: `counter`
--> src/main.rs:9:36
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `Mutex<i32>`, which does not implement the `Copy` trait
...
9 | let handle = thread::spawn(move || {
| ^^^^^^^ value moved into closure here, in previous iteration of loop
10 | let mut num = counter.lock().unwrap();
| ------- use occurs due to use in closure
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` due to previous error
Mesajul de eroare arată că valoarea counter a fost transferată în iterarea precedentă a buclei. Rust ne informează că nu avem posibilitatea de a transfera proprietatea counter în multiple fire de execuție. În continuare să corectăm eroarea de compilator cu o metodă de posesiune multiplă pe care am discutat-o în Capitolul 15.
Posesiunea multiplă cu fire multiple
În Capitolul 15, am oferit unei valori mai mulți proprietari utilizând pointerul inteligent Rc<T>, pentru a crea o valoare cu numărare referențială. Să încercăm același lucru aici și să vedem ce rezultă. Vom folosi Mutex<T> incapsulat în Rc<T> în Listarea 16-14 și vom clona Rc<T> înainte de a transfera posesiunea către fir.
Numele fișierului: src/main.rs
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Listarea 16-14: Tentativa de a folosi Rc<T> pentru a permite mai multor fire să dețină Mutex<T>
Încercând din nou să compilăm, ne confruntăm cu... niște erori noi! Compilatorul se dovedește a fi un excelent mijloc de învățare.
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `[closure@src/main.rs:11:36: 11:43]`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<Mutex<i32>>` cannot be sent between threads safely
|
= help: within `[closure@src/main.rs:11:36: 11:43]`, the trait `Send` is not implemented for `Rc<Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/std/src/thread/mod.rs:704:8
|
= note: required by this bound in `spawn`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` due to previous error
Ce mesaj de eroare copios! Să ne concentrăm pe informația crucială: `Rc<Mutex<i32>>` cannot be sent between threads safely (Rc<Mutex<i32>> nu se poate transmite în siguranță între fire). Compilatorul ne explică și de ce: the trait `Send` is not implemented for `Rc<Mutex<i32>>` (trăsătura Send nu este implementată pentru Rc<Mutex<i32>>). Vom discuta despre Send în secțiunea viitoare; este una din trăsăturile esențiale care se asigură că tipurile pe care le utilizăm împreună cu firele de execuție sunt pregătite pentru scenarii de concurență.
Din nefericire, Rc<T> nu este proiectat să fie distribuit în siguranță între fire. Când Rc<T> este responsabil de contorizarea referințelor, el adaugă la contor pentru fiecare apel la clone și scade din contor când o clonă este descărcată. Însă nu apelează la nicio structură de concurență care să garanteze că modificările contorului nu sunt susceptibile de a fi întrerupte de un alt fir. Acest aspect poate conduce la erori de contorizare care, pe neobservate, pot cauza scurgeri de memorie sau pot determina distrugerea unei valori înainte de finalizarea folosinței sale. Avem nevoie de un tip similar cu Rc<T>, dar care să actualizeze contorul de referințe într-o manieră compatibilă cu utilizarea în fire de execuție.
Numărarea atomară a referințelor cu Arc<T>
Din fericire, Arc<T> este un tip la fel ca Rc<T> care este sigur pentru utilizare în contexte concurente. Litera a reprezintă atomară, adică este un tip cu numărare atomară a referințelor. Atomicele sunt o altă categorie de primitive pentru concurență pe care nu o vom discuta în detaliu aici: vezi documentația pentru std::sync::atomic din biblioteca standard pentru mai multe informații. Deocamdată e suficient să știi că atomicele funcționează similare cu tipurile primitive și sunt sigure pentru a fi partajate între fire de execuție.
Poate te întrebi de ce toate tipurile primitive nu sunt atomice și de ce tipurile din biblioteca standard nu sunt construite să folosească implicit Arc<T>. Motivul este că siguranța pe mai multe fire de execuție aduce cu sine un cost de performanță pe care dorești să-l accepți numai când ai cu adevărat nevoie. Dacă operațiunile tale se desfășoară în cadrul unui singur fir de execuție atunci codul tău poate fi mai rapid dacă nu e nevoit să aplice garanțiile pe care atomicele le oferă.
Revenind la exemplul nostru: Arc<T> și Rc<T> partajează aceeași interfață API, deci putem ajusta programul nostru modificând linia use, apelul la new și apelul la clone. Codul din Listarea 16-15 va fi în final capabil să compileze și să ruleze:
Numele fișierului: src/main.rs
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let counter = Arc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
Listarea 16-15: Utilizarea lui Arc<T> pentru a incapsula Mutex<T> astfel încât să permită partajarea posesiunii pe mai multe fire de execuție
Iată ce va afișa codul:
Result: 10
Am reușit! Am contorizat de la 0 la 10, lucru care s-ar putea să nu pară impresionant, dar ne-a învățat o mulțime despre Mutex<T> și despre siguranța firelor de execuție. De asemenea, ai putea utiliza structura acestui program pentru a realiza operațiuni mai complexe decât simpla incrementare a unui contor. Cu această metodologie, poți descompune un calcul în segmente independente, repartiza aceste segmente între fire de execuție diferite, și folosi Mutex<T> pentru ca fiecare fir să își contribuie partea la rezultatul final.
Ia în considerare că, pentru operațiuni numerice simple, există tipuri mai accesibile decât Mutex<T> oferite de modulul [std::sync::atomic] din biblioteca standardatomic. Aceste tipuri permit un acces sigur, concurent și atomic la tipurile de bază. Am ales utilizarea Mutex<T> cu un tip simplu în acest exemplu pentru a nu ne distrage atenția de la funcționarea lui Mutex<T>.
Asemănările dintre RefCell<T>/Rc<T> și Mutex<T>/Arc<T>
Probabil ai remarcat că variabila counter este imutabilă, dar am reușit să obținem o referință mutabilă la valoarea dinăuntrul ei; acest lucru înseamnă că Mutex<T> asigură mutabilitate internă, așa cum o face familia Cell. Astfel cum am utilizat RefCell<T> în Capitolul 15 pentru a ne permite să modificăm conținutul unui Rc<T>, utilizăm Mutex<T> pentru a modifica conținutul unui Arc<T>.
Un alt detaliu important de menționat este că Rust nu poate să te protejeze de toate tipurile de erori de logică când folosești Mutex<T>. Reamintește-ți din Capitolul 15 că utilizarea lui Rc<T> prezenta riscul de a crea cicluri de referințe, în care două valori Rc<T> făceau referire reciprocă, provocând scurgeri de memorie. În mod asemănător, Mutex<T> prezintă riscul creării interblocajelor (deadlocks). Acestea se întâmplă când o operație necesită blocarea a două resurse și două fire de execuție au blocat fiecare câte una dintre acestea, determinându-le să aștepte reciproc la nesfârșit. Dacă te interesează interblocajele, încearcă să scrii un program în Rust care să genereze un interblocaj; apoi cercetează strategiile de evitare a interblocajelor pentru mutexuri in orice limbaj și încearcă să le aplici în Rust. Documentația API a bibliotecii standard pentru Mutex<T> și MutexGuard furnizează informații de valoare.
În încheierea acestui capitol, vom discuta despre trăsăturile Send și Sync și cum pot fi ele utilizate cu tipuri definite de utilizator.
Extinderea concurenței cu trăsăturile Sync și Send
Interesant este că limbajul Rust include foarte puține funcții native de concurență. Majoritatea caracteristicilor de concurență menționate până acum în acest capitol sunt parte a bibliotecii standard, nu a limbajului în sine. Modalitățile de gestionare a concurenței nu se limitează doar la limbaj sau biblioteca standard; poți dezvolta funcții de concurență proprii sau să utilizezi cele dezvoltate de alții.
Cu toate acestea, două concepte fundamentale de concurență sunt integrante în limbaj: trăsăturile std::marker Sync și Send.
Permiterea transferului posesiunii între fire cu Send
Trăsătura de marcaj Send indică faptul că posesiunea valorilor ce implementează Send poate fi transferată între diferite fire de execuție. Aproape toate tipurile din Rust sunt Send, cu unele excepții, printre care se numără Rc<T>: acesta nu este Send deoarece, după clonarea unei valori Rc<T> și încercarea de a transfera clona către un alt fir, există riscul ca ambele fire să actualizeze în același timp contorul de referințe. Așadar, Rc<T> este proiectat pentru utilizare în scenarii cu un singur fir de execuție, când vrei să eviți penalitățile de performanță legate de siguranța utilizării firelor multiple.
Deci, sistemul de tipuri din Rust și delimitările de trăsături garantează că nu poți transmite accidental o valoare Rc<T> între fire de execuție în mod nesigur. De exemplu, în Listarea 16-14, când am încercat acest lucru, am întâmpinat eroarea the trait Send is not implemented for Rc<Mutex<i32>>. Schimbarea la Arc<T>, care este Send, a făcut ca programul să compileze cu succes.
Orice tip alcătuit doar din elemente de tip Send este automat etichetat ca fiind Send. Cu excepția câtorva cazuri specifice, ca pointerii raw care vor fi analizați în Capitolul 19, majoritatea tipurilor primitive sunt Send.
Permiterea accesului din multiple fire de execuție cu Sync
Trăsătura de marcaj Sync semnalează că tipul ce o implementează e sigur pentru a fi referit din multiple fire de execuție. Adică, un tip T este Sync dacă &T (o referință imutabilă spre T) poate fi Send, sugerând că referința poate fi transferată în siguranță spre un alt fir. La fel ca Send, tipurile primitive sunt Sync și, similare lor, tipurile formate exclusiv din elemente Sync sunt de asemenea Sync.
Pointerul inteligent Rc<T> nu este Sync, din aceleași motive că nu este nici Send. Tipul RefCell<T> (discutat în Capitolul 15) și familia sa de tipuri Cell<T> nu sunt Sync. Modul în care RefCell<T> implementează verificarea împrumuturilor în timpul execuției nu este compatibil cu firele. Pe de altă parte, pointerul inteligent Mutex<T> este Sync și pot fi utilizate pentru a oferi acces partajat între mai multe fire, așa cum am văzut în secțiunea „Partajarea unui Mutex<T> între fire multiple”.
Implementarea manuală a Send și Sync implică riscuri
Fiindcă tipurile compuse din trăsături Send și Sync devin automat și ele Send și Sync, nu e necesară implementarea manuală a acestor trăsături. În calitate de trăsătură de marcaj, acestea nici nu necesită implementarea de metode. Ele sunt importante pentru menținerea invarianților legați de concurență.
Implementarea manuală a acestor trăsături presupune folosirea codului Rust nesigur. Vom discuta despre codul Rust nesigur în Capitolul 19; deocamdată, informația cheie este că dezvoltarea de noi tipuri orientate spre concurență care nu sunt formate din componentele Send și Sync necesită o analiză riguroasă pentru a respecta garanțiile de siguranță. Mai multe detalii despre aceste garanții și cum pot fi respectate se găsesc în „Rustonomicon”.
Sumar
Nu este ultima data când vom vedea concurența în această carte: proiectul din Capitolul 20 va aplica conceptele prezentate în acest capitol într-un context mai realist decât cel restrâns discutat aici.
După cum am menționat mai devreme, deoarece o mică parte din felul în care Rust abordează concurența este inclusă direct în limbaj, multe soluții pentru concurență sunt oferite sub formă de crate-uri. Acestea avansează mai agil decât biblioteca standard, așa că este esențial să căutați online crate-urile moderne și sofisticate pe care să le utilizați în scenarii cu fire de execuție multiple.
Biblioteca standard Rust pune la dispoziție canale pentru schimbul de mesaje și tipuri de pointere inteligente, cum ar fi Mutex<T> și Arc<T>, ce pot fi folosite în siguranță în contexte concurente. Sistemul de tipuri și verificatorul de împrumut garantează că orice cod care încorporează aceste soluții nu va suferi de curse de date sau de referințe nevalide. Odată ce codul tău compilează cu succes, poți fi liniștit știind că acesta va rula fiabil pe fire multiple de execuție, fără a provoca genul acelor erori dificil de localizat, frecvente în alte limbaje. Programarea concurentă nu mai este un concept intimidant: avansează cu încredere și implementează concurența în programele tale!
În capitolul următor, vom aborda metode idiomatice de a conceptualiza problemele și de a structura soluțiile pe măsură ce aplicațiile tale Rust se măresc. De asemenea, vom discuta cum se compară idiomele Rust cu cele la care ai putea fi obișnuit din paradigma programării orientate pe obiecte.
Caracteristicile programării orientate pe obiecte în Rust
Programarea orientată pe obiecte (OOP) reprezintă o metodologie de structurare a programelor. Conceptul de obiect în programare a fost inițiat de limbajul de programare Simula în anii '60. Aceste obiecte l-au influențat pe Alan Kay în dezvoltarea unei arhitecturi de programare în care obiectele comunica între ele prin mesaje. Pentru a descrie această arhitectură, el a formulat termenul programare orientată pe obiecte în 1967. Există mai multe definiții care concurează în a defini OOP, și după unele dintre ele Rust este considerat un limbaj orientat pe obiecte, iar după altele nu este. În acest capitol, vom examina anumite caracteristici care sunt în mod comun asociate cu programarea orientată pe obiecte și cum acestea se aplică în Rust idiomatic. Apoi, vom demonstra cum să implementezi un pattern de design orientat pe obiecte în Rust și vom dezbate compromisurile dintre alegerea acestei abordări și utilizarea unor atuuri specifice Rust.
Caracteristicile limbajelor orientate pe obiecte
Nu există un consens în comunitatea de programatori referitor la ce caracteristici ar trebui să aibă un limbaj de programare pentru a fi considerat orientat pe obiecte. Rust este influențat de numeroase paradigme de programare, inclusiv OOP; de exemplu, în Capitolul 13 am examinat caracteristicile împrumutate din programarea funcțională. Se poate argumenta că limbajele OOP se caracterizează prin anumite trăsături comune, cum ar fi obiecte, încapsulare și moștenire. Să analizăm ce înseamnă aceste caracteristici și dacă Rust le implementează.
Obiectele conțin date și comportamente
Cartea Design Patterns: Elements of Reusable Object-Oriented Software de Erich Gamma, Richard Helm, Ralph Johnson și John Vlissides (Addison-Wesley Professional, 1994), cunoscută informal ca și cartea Gang of Four (Banda celor patru), prezintă un catalog de pattern-uri de design orientate pe obiecte. Aceasta definește OOP astfel:
Programele orientate-obiect sunt alcătuite din obiecte. Un obiect include atât date cât și procedurile care lucrează cu aceste date. Procedurile sunt în mod uzual numite metode sau operații.
Conform acestei definiții, Rust este un limbaj orientat pe obiecte: structurile și enum-urile conțin date, iar blocurile impl oferă metode pentru aceste structuri și enum-uri. Chiar dacă structurile și enum-urile cu metode nu sunt etichetate explcit ca obiecte, ele oferă aceeași funcționalitate din punct de vedere al definiției oferite de The Gang of Four.
Încapsularea care ascunde detalii de implementare
Un alt aspect adesea asociat cu OOP este ideea de încapsulare, care presupune că detaliile de implementare ale unui obiect nu sunt accesibile codului ce utilizează acel obiect. Prin urmare, singura cale de a interacționa cu un obiect este prin API-ul său public; codul care îl folosește nu ar trebui să fie capabil să acceseze internul obiectului și să modifice direct datele sau comportamentul acestuia. Acest lucru îi permite programatorului să schimbe și să refacă structura internă a obiectului fără a avea nevoie să modifice codul ce utilizează obiectul.
Am discutat despre cum se poate controla încapsularea în Capitolul 7: putem folosi cuvântul cheie pub pentru a hotărî ce module, tipuri, funcții și metode din codul nostru ar trebui să fie accesibile public, iar în mod implicit, tot restul este privat. De exemplu, noi putem defini o structură AveragedCollection care are un câmp ce conține un vector cu valori de tip i32. Structura mai poate să aibă și un câmp ce reține media valorilor din vector, semnificând că media nu trebuie calculată de fiecare dată când este necesară. Altfel spus, AveragedCollection va memora pentru noi media calculată. Listarea 17-1 prezintă definiția structurii AveragedCollection:
Numele fișierului: src/lib.rs
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}Listarea 17-1: O structură AveragedCollection care păstrează o listă de valori întregi și media acestor valori
Structura este marcată cu pub, astfel încât să poată fi folosită de alte coduri, însă câmpurile din cadrul structurii rămân private. Acest aspect este important întrucât dorim să ne asigurăm că atunci când o valoare este adăugată sau ștearsă din listă, media este de asemenea actualizată. Realizăm acest lucru implementând metodele add, remove și average pe structura respectivă, așa cum este arătat în Listarea 17-2:
Numele fișierului: src/lib.rs
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}Listarea 17-2: Implementarea metodelor publice add, remove și average pe AveragedCollection
Metodele publice add, remove și average sunt singurele căi de interacțiune sau modificare a datelor într-o instanță a AveragedCollection. Când un element este adăugat în list prin metoda add sau eliminat utilizând remove, implementările acestora invocă metoda privată update_average, responsabilă de actualizarea câmpului average.
Am păstrat câmpurile list și average ca fiind private pentru a împiedica codul extern să adauge sau să elimine itemi direct din câmpul list; altfel, câmpul average ar putea deveni desincronizat atunci când lista se modifică. Metoda average returnează valoarea din câmpul average, permițând codului extern să acceseze valoarea medie, însă nu și să o modifice.
Întrucât am încapsulat detaliile de implementare ale structurii AveragedCollection, în viitor putem schimba cu ușurință diverse aspecte, cum ar fi structura datelor. De pildă, am putea folosi un HashSet<i32> în loc de un Vec<i32> pentru câmpul list. Dacă semnăturile metodelor publice add, remove și average rămân neschimbate, codul care folosește AveragedCollection nu va necesita nicio modificare. Dacă list ar fi fost public, situația ar fi putut fi diferită: HashSet<i32> și Vec<i32> au metode diferite pentru adăugarea și eliminarea elementelor, ceea ce ar implica probabil schimbări în codul extern dacă acesta ar modifica list direct.
Dacă încapsularea este un criteriu esențial pentru ca un limbaj să fie considerat orientat pe obiecte, atunci Rust satisface și această condiție. Posibilitatea de a utiliza pub sau nu pentru diverse secțiuni ale codului facilitează încapsularea detaliilor implementării.
Moștenirea ca sistem de tipuri și de partajare a codului
Moștenirea este un mecanism prin care un obiect poate moșteni elemente definitorii ale altui obiect, câștigând, astfel, datele și comportamentul obiectului părinte fără a necesita o redefinire.
În cazul în care prezența moștenirii este o condiție obligatorie pentru ca un limbaj de programare să fie considerat orientat pe obiecte, Rust nu se încadrează în această categorie. Nu există un mod prin care să definești un struct ce moștenește câmpurile și implementările de metode ale structurii părinte fără utilizarea unui macro.
Totuși, dacă ești obișnuit să utilizezi moștenirea în setul tău de instrumente de programare, Rust îți oferă alte opțiuni, în funcție de motivul pentru care alegi să folosești moștenirea inițial.
Moștenirea este selectată din două motive principale. Primul este reutilizarea codului: poți implementa un anumit comportament pentru un tip și, prin moștenire, ai posibilitatea de a aplica aceiași implementare unui tip diferit. În Rust, acest lucru se poate realiza într-un mod restrâns folosind implementările implicite ale metodelor unei trăsături, aspect observat în Listarea 10-14, când am inclus o implementare implicită a metodei summarize pentru trăsătura Summary. Orice tip ce implementează trăsătura Summary va beneficia de metoda summarize fără a fi necesar cod adițional. Aceast aspect se aseamănă cu o clasă părinte care deține o implementare a unei metode și cu o clasă derivată care moștenește implementarea dată. Mai mult, putem suprascrie implementarea implicită a metodei summarize în momentul în care implementăm trăsătura Summary, fiind analog cu o clasă derivată care suprascrie o metodă primită prin moștenire de la o clasă părinte.
Al doilea motiv pentru a recurge la moștenire este legat de sistemul de tipuri: permite unui tip derivat să fie utilizat în toate contextele în care ar putea fi utilizat tipul părinte. Așa utilizare este cunoscută și sub numele de polimorfism, sugerând că, în timpul execuției, poți substitui mai multe obiecte între ele dacă partajează anumite trăsături.
Polimorfism
Pentru mulți, polimorfismul este văzut ca fiind sinonim cu moștenirea. Însă, este de fapt un concept mult mai general, care face referire la cod capabil să interacționeze cu date de diverse tipuri. Pentru moștenire, aceste tipuri sunt, în general, subclase.
Rust preferă să utilizeze generici pentru a generaliza peste diferite tipuri posibile și delimitări de trăsătură pentru a impune constrângeri legate de funcționalitățile pe care aceste tipuri trebuie să le furnizeze. Așa metodă este uneori denumită polimorfism parametric limitat.
Recent, moștenirea a devenit o soluție de design mai puțin favorizată în multe limbaje de programare, deoarece adesea există riscul de a partaja mai mult cod decât este necesar. Subclasele nu ar trebui neapărat să moștenească toate caracteristicile clasei părinte, ce exact se întâmplă în cazul moștenirii. Astfel poate reduce flexibilitatea designului unui program. De asemenea, generează posibilitatea de a invoca metode pe subclase care nu sunt adecvate sau care provoacă erori deoarece metodele nu întotdeauna sunt aplicabile la subclasa dată. În plus, unele limbaje permit doar moștenire simplă (o subclasă poate moșteni numai de la o singură clasă), limitând și mai mult flexibilitatea designului de program.
Din aceste motive, Rust alege o altă cale, utilizând obiecte-trăsătură în loc de moștenire. Să analizăm cum obiectele-trăsătură facilitează polimorfismul în Rust.
Utilizarea obiectelor-trăsătură pentru valori de diferite tipuri
Am discutat în Capitolul 8 faptul că vectorii au limitarea de a putea stoca elemente de un singur tip. O soluție de compromis a fost prezentată în Listarea 8-9, unde am definit o enumerare SpreadsheetCell cu variante pentru a suporta întregi, numere în virgulă mobilă și text. Acest lucru ne permitea să depozităm date de diverse tipuri în fiecare celulă, păstrând în același timp un vector ce reprezenta un rând de celule. Această modalitate este ideală când elementele interschimbabile din setul nostru sunt de tipuri fixe ce sunt cunoscute la momentul compilării codului.
Totuși, în anumite cazuri dorim ca utilizatorii bibliotecii noastre să aibă posibilitatea de a extinde setul de tipuri permise într-un context dat. Pentru a exemplifica cum s-ar realiza asta, vom construi un exemplu de unealtă GUI (interfață grafică cu utilizatorul) care parcurge o listă de elemente, invocând metoda draw pe fiecare pentru a le reda pe ecran, o abordare obișnuită în cadrul uneltelor GUI. Vom constitui un crate de tip bibliotecă denumit gui, care va conține structura de bază a unei astfel de biblioteci. Acest crate ar include tipuri de bază pentru folosire, precum Button sau TextField. În plus, utilizatorii gui vor dori să introducă tipuri proprii ce pot fi redate: de pildă, un programator poate adăuga o Image, iar altul un SelectBox.
Deși nu vom dezvolta o bibliotecă GUI completă în acest exemplu, vom ilustra modul în care componentele ar interacționa. La momentul creării bibliotecii, nu putem anticipa toate tipurile pe care alți programatori le-ar putea defini. Ceea ce știm este că gui trebuie să gestioneze diverse valori de tipuri diferite și să invoce metoda draw pentru fiecare dintre acestea. Nu trebuie să cunoaștem detaliile specifice ale acțiunii metodei draw, ci doar sa fim siguri că această metodă va fi disponibilă pentru a fi apelată.
Pentru a realiza aceasta într-un limbaj cu moștenire, am defini o clasă denumită Component care ar include o metodă numită draw. Alte clase, cum ar fi Button, Image și SelectBox, ar moșteni din Component și, astfel, ar moșteni metoda draw. Ele ar putea să realizeze o supraîncărcare a metodei draw pentru a defini comportamentul lor specific, dar biblioteca noastră ar putea considera toate aceste instanțe ca fiind de tip Component și ar putea apela draw. Cu toate acestea, fiindcă Rust nu suportă moștenirea, avem nevoie de o altă metodă de structurare a bibliotecii gui astfel încât utilizatorii să poată să o extindă cu noi tipuri.
Definirea unei trăsături pentru comportament comun
Pentru a implementa comportamentul dorit pentru gui, definim o trăsătură denumită Draw ce conține o metodă numită draw. Vom putea apoi defini un vector care primește un obiect-trăsătură. Un astfel de obiect-trăsătură se referă la o instanță a unui tip care implementează o trăsătură specificată și la un tabel folosit pentru a identifica metodele trăsăturii pe respectivul tip în timpul rulării. Creăm un obiect-trăsătură prin indicarea unui tip de pointer - de exemplu, o referență & sau un pointer inteligent Box<T> - urmat de cuvântul cheie dyn, și apoi trăsătura relevantă. (Cauza pentru care obiectele-trăsătură necesită un pointer este discutată în Capitolul 19, în secțiunea „Tipuri cu dimensiune dinamică și trăsătura Sized.”) Obiectele-trăsătură pot fi folosite în loc de tipuri generice sau concrete. Oriunde sunt utilizate, sistemul de tipuri din Rust garantează la momentul compilării că orice valoare din acel context va implementa trăsătura specificată de obiectul-trăsătură. Astfel, nu este nevoie să cunoaștem toate tipurile posibile la momentul compilării.
Am menționat anterior că, în Rust, evităm să numim structurile și enumerările "obiecte" pentru a sublinia diferența față de conceptul de obiect din alte limbaje de programare. Diferența constă în faptul că, în Rust, datele din câmpurile structurii și comportamentul definit în blocurile impl sunt separate, în timp ce în alte limbaje combinația de date și comportament formează adesea ceea ce se numește obiect. Cu toate acestea, obiectele-trăsătură sunt asemănătoare cu obiectele din alte limbaje prin fuziunea dintre date și comportament. Totuși, ele se disting de obiectele tradiționale prin faptul că nu permit adăugarea de date suplimentare la un obiect-trăsătură. Obiectele-trăsătură nu prezintă aceeași utilitate generală ca obiectele din alte limbaje, fiind special concepute pentru abstractizarea unui comportament comun.
Listarea 17-3 ilustrează modul de definire a unei trăsături numite Draw cu o metodă draw:
Filename: src/lib.rs
pub trait Draw {
fn draw(&self);
}Listarea 17-3: Definiția trăsăturii Draw
Această sintaxă ar trebui să fie deja cunoscută datorită explicațiilor noastre din Capitolul 10 despre cum se definesc trăsăturile. Acum urmează o nouă sintaxă: Listarea 17-4 introduce o structură numită Screen care posedă un vector denumit components. Acest vector este de tip Box<dyn Draw>, fiind un obiect-trăsătură; serving ca substitut pentru orice tip dintr-un Box ce implementează trăsătura Draw.
Numele fișierului: src/lib.rs
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}Listarea 17-4: Definirea structurii Screen cu un câmp components ce deține un vector de obiecte-trăsătură implementând trăsătura Draw
În structura Screen, vom defini o metodă numită run care va invoca metoda draw pentru fiecare dintre componente, așa cum este demonstrat în Listarea 17-5:
Numele fișierului: src/lib.rs
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Listarea 17-5: Metoda run pentru Screen ce apelează metoda draw pe fiecare component în parte
Aceasta metodă se comportă diferit de cazul în care am defini o structură care utilizează un parametru de tip generic cu delimitări de trăsătură. Un parametru de tip generic poate fi înlocuit numai cu un singur tip concret o singură dată, în timp ce obiectele-trăsătură permit folosirea mai multor tipuri concrete ca substituenți pentru obiectul-trăsătură în timpul execuției. Spre exemplu, am fi putut defini structura Screen utilizând un tip generic și o delimitare de trăsătură, după cum se vede în Listarea 17-6:
Numele fișierului: src/lib.rs
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Listarea 17-6: O versiune alternativă de implementare a structurii Screen și a metodei sale run folosind generici și delimitări de trăsături
Acest lucru ne limitează la o instanță Screen care ar deține o listă de componente de același tip, fie ele Button sau TextField. Dacă vei avea mereu colecții omogene, utilizarea tipurilor generice și a delimitărilor de trăsături este mai avantajoasă deoarece definițiile sunt monomorfizate în timpul compilării pentru a utiliza tipurile concrete.
Pe de altă parte, utilizând metoda cu obiectele-trăsătură, o instanță Screen poate conține un Vec<T> care include atât Box<Button> cât și Box<TextField>. Să analizăm cum funcționează acest mecanism și apoi vom discuta despre performanța lui în timpul execuției.
Implementarea trăsăturii
Acum, vom introduce câteva tipuri care implementează trăsătura Draw. Să oferim tipul Button. Deoarece implementarea unei biblioteci GUI complete nu este acoperită de această carte, metoda draw va avea un corp fără o implementare concret utilă. Pentru a ne imagina cum ar arăta o posibilă implementare, un struct Button ar putea include câmpuri precum width (lățime), height (înălțime) și label (etichetă), așa cum este ilustrat în Listarea 17-7:
Numele fișierului: src/lib.rs
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// code to actually draw a button
}
}Listarea 17-7: Structura Button care implementează trăsătura Draw
Câmpurile width, height și label ale lui Button vor diferi față de cele ale altor componente. De exemplu, tipul TextField ar putea include aceste câmpuri plus unul suplimentar placeholder. Fiecare dintre tipurile pe care intenționăm să le afișăm pe ecran va implementa trăsătura Draw folosind cod diferit în metoda draw pentru a defini modul specific de desenare, așa cum demonstrează Button aici (lipsind, desigur, codul GUI real, așa cum am menționat). De exemplu, pentru Button ar putea exista un bloc impl separat, conținând metode specifice acțiunilor declanșate de click-ul utilizatorului pe buton, metode ce nu ar fi relevante pentru TextField.
Dacă un utilizator al bibliotecii noastre optează să implementeze o structură SelectBox cu câmpurile width, height și options, va trebui să implementeze și acesta trăsătura Draw pentru tipul SelectBox, conform Listării 17-8:
Numele fișierului: src/main.rs
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}Listarea 17-8: Un alt crate care utilizează gui și implementează trăsătura Draw pe structura SelectBox
Utilizatorii bibliotecii noastre pot acum să-și construiască funcția main pentru a genera o instanță Screen. Acesteia i se pot adăuga un SelectBox și un Button, situați fiecare într-un Box<T> pentru a-i transforma în obiecte-trăsătură. În continuare, pot invoca metoda run pe instanța de Screen, metoda care va apela funcția draw pentru fiecare dintre componente. Listarea 17-9 prezintă această implementare:
Filename: src/main.rs
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}Listarea 17-9: Folosirea obiectelor-trăsătură pentru a stoca valori de diferite tipuri ce implementează aceeași trăsătură
Când am dezvoltat biblioteca, nu cunoșteam nimic despre adăugarea tipului SelectBox, dar implementarea noastră pentru Screen a reușit să opereze asupra noului tip și să-l redea, pentru că SelectBox implementează trăsătura Draw, și în consecință metoda draw.
Conceptul acesta — de a fi preocupat exclusiv de mesajele la care o valoare răspunde, nu de tipul său concret — este asemănător cu cel de duck typing în limbajele cu tip dinamic: dacă se mișcă ca o rață și măcăie ca o rață, atunci chiar este o rață! În implementarea metodei run de la Screen, prezentată în Listarea 17-5, run nu are nevoie să cunoască tipul concret al fiecărui component. Acesta nu verifică dacă componentul este un Button sau un SelectBox, ci pur și simplu invocă metoda draw asupra lui. Definind Box<dyn Draw> ca tip pentru valorile din vectorul components, am specificat că Screen necesită valori asupra cărora putem apela metoda draw.
Beneficiul utilizării obiectelor-trăsătură și al sistemului de tipizare din Rust, pentru a scrie cod într-o manieră similară cu duck typing, este că nu este nevoie să verificăm la execuție dacă o valoare implementează o metodă particulară, nici să ne îngrijorăm de posibile erori în cazul în care o valoare nu implementează metoda și totuși se face apel la ea. Rust nu va compila codul nostru dacă valorile nu respectă trăsăturile cerute de obiectele-trăsătură.
De exemplu, Listarea 17-10 ne ilustrează ce se întâmplă dacă încercăm să construim un Screen cu un String ca component:
Numele fișierului: src/main.rs
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
screen.run();
}Listarea 17-10: Tentativa de a folosi un tip ce nu implementează trăsătura cerută de obiectul-trăsătură
Următoarea eroare apare pentru că String nu implementează trăsătura Draw:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `String` to the object type `dyn Draw`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` due to previous error
Această eroare ne indică faptul că fie am introdus în Screen un element neintenționat, ceea ce înseamnă că ar trebui să folosim un alt tip, fie că trebuie să implementăm trăsătura Draw pe String, astfel încât Screen să poată apela metoda draw asupra lui.
Obiectele-trăsătură folosesc apelare dinamică
Să ne amintim în secțiunea „Performanța Codului Utilizând Generici” din Capitolul 10 despre discuția privind procesul de monomorfizare efectuat de compilator când utilizăm limite de trăsătură pe generici: compilatorul creează implementări non-generice ale funcțiilor și metodelor pentru fiecare tip concret folosit în locul unui parametru generic de tip. Codul rezultat din monomorfizare realizează invocare statică, adică atunci când compilatorul cunoaște ce metodă apelezi în timpul compilării. Aceasta se contrastează cu invocare dinamică, atunci când compilatorul nu este capabil să determine în timpul compilării care metodă va fi apelată. În cazurile de apelare dinamică, compilatorul generează cod care va decide în timpul execuției care metodă să invoce.
Utilizând obiectele-trăsătură, Rust este constrâns la utilizarea invocării dinamice. Compilatorul nu cunoaște toate tipurile care pot fi folosite cu codul care utilizează obiectele-trăsătură, astfel nu poate determina ce metodă implementată pentru care tip ar trebui apelată. În schimb, în timpul execuției, Rust se folosește de pointerii din interiorul obiectului-trăsătură pentru a identifica metoda de apelat. Această căutare implică un cost la execuție, care nu există în cazul invocării statice. Mai mult, invocarea dinamică împiedică compilatorul să facă inline la codul unei metode, ceea ce la rândul său inhibă anumite optimizări. Cu toate acestea, am câștigat o flexibilitate suplimentară în codul scris în Listarea 17-5 și am fost în stare să o susținem în Listarea 17-9, deci este un compromis pe care trebuie să-l luăm în considerare.
Implementarea unui pattern de design orientat pe obiecte
Pattern-ul de stare (state pattern) este un concept în designul orientat pe obiecte care implică definirea unui set de stări posibile pentru o anumită valoare, pe care aceasta le poate asuma intern. Aceste stări sunt reprezentate de diverse obiecte de stare, schimbând comportamentul respectivei valori în funcție de starea în care se află. Analizăm aici un exemplu de structură blog post având un câmp destinat stării sale, putând fi una dintre obiectele de stare schiță, la recenzie sau publicată.
În Rust, aceste obiecte de stare dețin funcționalități asemănătoare, pentru care utilizăm structuri și trăsături în loc de obiecte și moșteniri. Fiecare obiect de stare este auto-suficient în ceea ce privește comportamentul său și determină momentele de tranziție către alte stări. Valoarea care găzduiește obiectul de stare nu conține informație referitoare la comportamentele specifice stărilor sau cum să tranziționeze între ele.
Avantajul folosirii pattern-ului de stare se oglindește în flexibilitatea cu care se pot adapta noilor necesități ale aplicațiilor: atunci când apar schimbări, nu este necesară revizuirea codului valorii ce deține starea, nici a celui care o utilizează. Este suficientă modificarea codului aferent unor obiecte de stare pentru a ajusta reguli sau pentru a adăuga noi obiecte de stare, după caz.
Inițiem implementarea pattern-ului de stare cu o abordare tipic orientată obiect, urmând să transitionăm spre o metodologie mai armonioasă cu paradigma Rust. Vom dezvolta gradual un workflow pentru postările de blog, utilizând pattern-ul de stare.
Funcționalitatea obținută în final va cuprinde următoarele aspecte:
- Un articol pe blog începe ca un schiță inițial vidă.
- Odată completată schița, se solicită evaluarea postării.
- Cu aprobarea postării, aceasta este gata de publicare.
- Numai articolele de blog publicate sunt apte de a afișa conținut, facilitând astfel prevenția publicării neintenționate a celor neaprobate.
Orice alte încercări de modificare a unei postări nu ar trebui să aibă efect. De exemplu, dacă încercăm să aprobăm o schiță de articol pe blog înainte de a fi solicitat o recenzie, acest articol ar trebui să rămână în starea de schiță nepublicat.
Listarea 17-11 ilustrează acest flux de lucru sub formă de cod: acesta este un exemplu al utilizării API-ului pe care urmează să îl implementăm într-un crate de bibliotecă numit blog. Momentan, acest cod nu va compila deoarece crate-ul blog nu a fost încă implementat.
Numele fișierului: src/main.rs
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Listarea 17-11: Codul care demonstrează comportamentul dorit pentru crate-ul nostru blog.
Intenționăm să oferim posibilitatea utilizatorului de a crea o nouă postare schiță pe blog cu ajutorul Post::new. Vrem să permitem adăugarea textului la postarea blogului. Dacă încercăm să accesăm conținutul postării imediat, înainte de aprobare, nu ar trebui să primim niciun text, deoarece postarea este încă schiță. Pentru demonstrație, am folosit assert_eq! în cod. Un test unitar excelent ar fi să verificăm că o postare schiță pe blog returnează un șir de caractere gol pentru metoda content, dar nu vom scrie teste pentru acest exemplu.
Mai departe, ne propunem să implementăm cererea de recenzie a articolului și dorim ca content să furnizeze un șir de caractere gol în timpul așteptării recenziei. Când articolul este aprobat, ar trebui să fie publicat, ceea ce înseamnă că textul articolului va fi returnat la apelul lui content.
Este important de observat că singurul tip cu care interacționăm din crate este Post. Acest tip va utiliza pattern-ul de stare și va conține o valoare care va fi una dintre cele trei obiecte de stare, reprezentând stările prin care poate trece o postare: schiță, în așteptarea recenziei sau publicată. Trecerea de la o stare la alta este gestionată intern în tipul Post. Schimbările de stare se produc ca răspuns la metodele apelate de către utilizatorii bibliotecii asupra instanței Post, ei nefiind nevoiți să gestioneze direct aceste schimbări de stare. Totodată, utilizatorii nu pot să greșească stările, de exemplu, nu pot publica o postare înainte să fie recenzată.
Definirea lui Post și crearea unei instanțe noi în starea de schiță
Să începem implementarea bibliotecii! Avem nevoie de o structură Post publică care să conțină conținut, așa că vom începe cu definirea structurii și o funcție asociată publică new pentru a crea o instanță de Post, așa cum este arătat în Listarea 17-12. Vom crea și o trăsătură privată State care va defini comportamentul necesar tuturor obiectelor de stare pentru Post.
În continuare, Post va conține în interior un obiect-trăsătură Box<dyn State> încapsulat într-un Option<T> într-un câmp privat numit state pentru a stoca obiectul de stare. Motivul pentru care este necesar Option<T> va deveni evident în curând.
Numele fișierului: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}Listarea 17-12: Definirea structurii Post și a funcției new care creează o nouă instanță de Post, o trăsătură State, și o structură Draft
Trăsătura State stabilește comportamentul partajat de diferitele stări ale unei postări. Stările obiectelor sunt Draft, PendingReview și Published, toate urmând să implementeze trăsătura State. Deocamdată, trăsătura nu are metode definite, și vom începe prin a defini doar starea Draft, deoarece asta este starea inițială dorită pentru o postare.
La crearea unei noi Post, setăm câmpul state la o valoare Some care conține un Box. Acest Box face referire la o nouă instanță a structurii Draft, asigurând că orice instanță nouă de Post va începe ca o schiță. Fiindcă câmpul state din Post este privat, nu este posibilă crearea unui Post într-o altă stare! În funcția Post::new, inițializăm câmpul content ca fiind un String gol nou.
Stocarea textului din conținutul postării
Am observat în Listarea 17-11 că dorim să fim capabili să apelăm o metodă numită add_text și să-i transmitem un &str care urmează să fie adăugat ca text al conținutului postării pe blog. Implementăm această funcționalitate sub forma unei metode, în loc să expunem câmpul content drept pub, pentru a putea ulterior implementa o metodă ce va controla modul în care se accesează datele câmpului content. Metoda add_text este destul de directă, așadar să adăugăm implementarea sa în Listarea 17-13, în blocul impl Post:
Numele fișierului: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}Listarea 17-13: Implementarea metodei add_text pentru adăugarea de text la content-ul unei postări
Metoda add_text necesită o referință mutabilă la self, întrucât modificăm instanța de Post pe care o folosim pentru a apela add_text. Apoi invocăm push_str pe String din content și transmitem argumentul text pentru a adăuga la conținutul deja salvat. Acest comportament nu este influențat de starea în care se află postarea, deci nu este parte din pattern-ul de stare. Metoda add_text nu interacționează cu câmpul state, dar constituie o parte din comportamentul pe care îl dorim să îl suportăm.
Asigurarea conținutului gol a unei postări schiță
Chiar dacă am invocat add_text și am adăugat anumit conținut postării noastre, vrem totuși ca metoda content să returneze un șir de caractere gol, fiindcă postarea se află încă în starea de schiță, așa cum se vede la linia 7 din Listarea 17-11. Pentru moment, să implementăm metoda content în cel mai simplu mod posibil care să satisfacă această cerință: returnând mereu un șir de caractere gol. Vom modifica acest lucru mai târziu, o dată ce implementăm funcționalitatea de a schimba starea unei postări pentru a permite publicarea acesteia. Până în acest punct, postările pot fi doar în starea de schiță, astfel că conținutul unei postări ar trebui să fie întotdeauna gol. Listarea 17-14 prezintă această implementare temporară:
Numele fișierului: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}Listarea 17-14: Implementarea temporală a metodei content pentru Post, care returnează întotdeauna un șir de caractere gol
Cu această metodă content adăugată, tot ce se găsește în Listarea 17-11 până la linia 7 funcționează exact așa cum dorim.
Solicitarea unei recenzii schimbă starea postării
Următorul pas este să adăugăm funcționalitatea de a solicita o recenzie a unei postări, care ar trebui să-i schimbe starea din Draft în PendingReview. Listarea 17-15 prezintă codul aferent:
Numele fișierului: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}Listarea 17-15: Implementarea metodelor request_review pentru Post și trăsătura State
Îi atribuim clasei Post o metodă publică numită request_review care primește o referință mutabilă la self. Apoi invocăm o metodă internă request_review pe starea actuală a Post, iar această a doua metodă request_review consumă starea curentă și returnează o nouă stare.
Metoda request_review este adăugată trăsăturii State. Toate tipurile care implementează această trăsătură vor trebui acum să implementeze metoda request_review. De observat că metoda nu are ca prim parametru self, &self, sau &mut self, ci self: Box<Self>. Această sintaxă indică faptul că metoda este validă doar când este invocată pe un Box care deține respectivul tip. Sintaxa ia în posesie Box<Self>, invalidând starea veche, permițând astfel ca valoarea stării Post să evolueze către o nouă stare.
Pentru a renunța la vechea stare, metoda request_review trebuie să preia posesiunea valorii stării. Aici intervine rolul Option în câmpul state al Post: apelăm metoda take pentru a extrage valoarea Some din state și a lăsa un None în loc, de vreme ce Rust nu ne lasă să avem câmpuri neinițializate în structuri. Aceasta ne permite să permutăm valoarea stării din Post, în loc de a o împrumuta. Ulterior, stabilim valoarea stării postării la rezultatul acestei operații.
Este necesar să setăm temporar state la None, în loc să setăm direct valoarea cu un cod de genul self.state = self.state.request_review(); pentru a deține valoarea stării. Acest lucru asigură că Post nu poate utiliza vechea valoare state după ce am convertit-o într-o nouă stare.
Metoda request_review de pe Draft returnează o instanță nouă, BoxPendingReview, care simbolizează starea în care o postare așteaptă recenzia. Structura PendingReview implementează, de asemenea, metoda request_review, dar nu are operațiuni de transformare. În schimb, își returnează propria instanță, deoarece atunci când solicităm o recenzie pentru o postare aflată deja în starea PendingReview, ea trebuie să rămână în această stare.
Acum începem să observăm avantajele modelului de stare: metoda request_review a clasei Post este identică, indiferent de valoarea lui state. Fiecare stare își determină propriile sale reguli.
Metoda content a clasei Post este lăsată neschimbată, returnând o secțiune de string goală. Acum putem avea o postare nu doar în starea Draft, dar și în PendingReview, dorind același comportament în ambele stări. Listarea 17-11 este acum aplicabilă până la linia 10!
Adăugarea metodei approve pentru a schimba comportamentul content
Metoda approve va fi similară metodei request_review: va seta state la valoarea indicată de starea curentă ca fiind necesară după ce e aprobată, conform Listării 17-16:
Numele fișierului: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}Listarea 17-16: Implementarea metodei approve pe Post și trăsătura State
Adăugăm metoda approve la trăsătura State și introducem o nouă structură ce implementează State, starea Published.
Similar cu funcționarea lui request_review pe PendingReview, dacă invocăm metoda approve pe un Draft, aceasta nu va avea efect fiindcă approve va returna self. Când invocăm approve pe PendingReview, metoda returnează o nouă instanță a structurii Published încapsulată în Box. Structura Published implementează trăsătura State, iar pentru metodele request_review și approve returnează propria instanță, pentru că articolul ar trebui să rămână în starea Published în acele situații.
Acum trebuie să actualizăm metoda content a lui Post. Vrem ca valoarea întoarsă de content să depindă de starea curentă a lui Post, așadar vom delega responsabilitatea unei metode content definite pe state, așa cum e prezentat în Listarea 17-17:
Numele fișierului: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// --snip--
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}Listarea 17-17: Actualizarea metodei content de pe Post pentru a delega la o metodă content definită pe State
Cu scopul de a menține toate regulile în interiorul structurilor care implementează State, invocăm o metodă content pe valoarea din state și pasăm instanța postului (adică self) ca argument. Apoi, returnăm valoarea primită din aplicarea metodei content asupra valorii state.
Folosim metoda as_ref pe Option pentru că dorim o referință la conținutul Option, nu posesiunea acestei valori. Deoarece state este un Option<Box<dyn State>>, prin apelul lui as_ref, obținem un Option<&Box<dyn State>>. Fără utilizarea lui as_ref, am întâmpina o eroare pentru că nu putem muta state din &self împrumutat, care este parametrul funcției.
Apelăm apoi metoda unwrap, metodă despre care știm că nu va provoca panică, pentru că metodele definite pe Post garantează că state va conține întotdeauna o valoare Some la finalul executării lor. Acesta este unul dintre scenariile menționate în secțiunea „Situatii în care deții mai multe informații decât compilatorul” din Capitolul 9, când suntem siguri că o valoare None nu este niciodată posibilă, chiar dacă compilatorul nu are capacitatea să recunoască acest lucru.
În momentul în care folosim content pe &Box<dyn State>, va interveni coerciția de dereferențiere asupra & și Box astfel încât metoda content va fi apelată, în ultimă instanță, pe tipul ce implementează trăsătura State. Acest lucru ne obligă să adăugăm content în definiția trăsăturii State, unde vom defini logica privind conținutul ce trebuie returnat în funcție de starea curentă, conform Listării 17-18:
Numele fișierului: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --snip--
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}Listarea 17-18: Adăugarea metodei content în definiția trăsăturii State
Introducem o implementare implicită pentru metoda content care oferă un șir gol. Acest lucru înseamnă că nu mai este necesar să implementăm content pentru structurile Draft și PendingReview. Structura Published va înlocui metoda content și va oferi valoarea din post.content.
Să notăm că este nevoie de adnotări de durată de viață pentru această metodă, aspect abordat în Capitolul 10. Primim o referință la post ca argument și returnăm o referință la o parte din acest post, astfel că durata de viață a referinței întoarse este corelată cu durata de viață a argumentului post.
Și astfel am încheiat — întreaga Listare 17-11 este acum funcțională! Am implementat pattern-ul stării conform regulilor pentru publicarea unui articol pe blog. Logica asociată cu aceste reguli este encapsulată în obiectele de stare, în loc să fie dispersată prin Post.
De ce nu o Enumerare?
Probabil te întrebi de ce nu am ales să utilizăm un
enumcu diferite stări posibile ale postării ca și variante. Aceasta ar fi fost sigur o soluție fezabilă; încearcă și compară cu rezultatele finale pentru a vedea care variantă îți convine mai mult! Un neajuns al utilizării unei enumerări este că ar necesita unmatchsau o structură similară pentru a gestiona fiecare posibilă variantă oriunde se verifică valoarea enumerării. Implementare ce ar putea fi mai redundantă decât soluția bazată pe obiect-trăsătură.
Compromisurile pattern-ului de stare
Am demonstrat că Rust poate să implementeze pattern-ul de stare specific orientării obiectuale pentru a încapsula diferite comportamente ale unei postări conform stării în care se află. Metodele pe Post sunt neinformate despre varietatea comportamentelor. Prin modul în care am structurat codul, e destul să privim într-un singur loc pentru a cunoaște comportamentele diverse ale unei postări publicate: implementarea trăsăturii State în structura Published.
Dacă am alege să realizăm o implementare alternativă care nu recurge la pattern-ul de stare, probabil am folosi expresii match fie în metodele pe Post, fie chiar în codul din main, pentru a verifica starea postării și a modifica comportamentul acolo unde este necesar. Asta ar însemna că ar trebui să ne uităm în mai multe locuri pentru a înțelege toate implicațiile unei postări în starea de publicat! Și complexitatea ar crește odată cu adăugarea de noi stări: fiecare expresie match ar necesita o nouă ramură.
Folosind pattern-ul de stare, metodele lui Post și contextele în care este folosit nu necesită expresii match; pentru a adăuga o nouă stare, trebuie doar să introducem o nouă structură și să implementăm metodele respective ale trăsăturii.
O implementare care folosește pattern-ul de stare este simplu de extins pentru a adăuga funcționalități noi. Pentru a aprecia ușurința mentenanței codului ce utilizează acest pattern, încearcă următoarele sugestii:
- Introdu o metodă
rejectce schimbă starea postării de laPendingReviewînapoi laDraft. - Impune necesitatea efectuării a două apeluri la
approvepentru schimbarea stării înPublished. - Permite utilizatorilor să adauge conținut text doar când o postare este în starea
Draft. Indiciu: lasă obiectul de stare să fie responsabil pentru ceea ce ar putea schimba din conținut, dar fără a modificaPost.
Un neajuns al pattern-ului de stare este acela că, având în vedere implementarea transițiilor între stări în interiorul stărilor, anumite stări devin interdependente. Dacă am decide să adăugăm o stare intermediară între PendingReview și Published, ca de exemplu Scheduled, am fi nevoiți să modificăm codul din PendingReview pentru a tranziționa spre Scheduled și nu direct spre Published. Ar fi mai simplu dacă PendingReview nu ar necesita adaptări când se adaugă o nouă stare, dar asta ar implica alegerea unui alt pattern de design.
O altă problemă este duplicarea unor logici: pentru a reduce redundanța, am putea încerca să stabilim implementări implicite ale metodelor request_review și approve în trăsătura State care să returneze self. Cu toate acestea, am încălca siguranța obiectelor, deoarece trăsătura nu poate determina cu precizie ce va fi self. Vrem ca State să poată fi folosit ca un obiect-trăsătură, deci e esențial ca metodele sale să respecte siguranța obiectelor.
Alte forme de duplicare includ implementări asemănătoare ale metodelor request_review și approve din Post, în care ambele metode se bazează pe implementarea aceleiași metode pe valoarea din câmpul state al Option, stabilind noua valoare a câmpului state. Dacă metodele din Post sunt numeroase și urmează acest pattern, am putea lua în considerare crearea unui macro pentru a elimina repetițiile (consultă secțiunea "Macrouri" în Capitolul 19).
Prin adoptarea pattern-ului de stare așa cum este el definit în limbajele cu orientare obiectuală, nu valorificăm toate avantajele lui Rust. Să analizăm unele modificări pe care le-am putea aplica crate-ului blog pentru a transforma stările și tranzițiile invalide în erori de timpul compilării.
Codificarea stării și comportamentului în tipuri de date
Vom arăta cum să reconceptualizăm pattern-ul de stare pentru a accesa un set diferit de compromisuri. În loc să încapsulăm complet stările și tranzițiile astfel încât codul din exterior să nu le cunoască, vom codifica stările în diferite tipuri de date. Ca rezultat, sistemul de verificare a tipurilor din Rust va împiedica încercările de a utiliza schițe de postări acolo unde sunt permise doar postările publicate, generând o eroare de compilare.
Să analizăm prima parte a funcției main din Listarea 17-11:
Numele fișierului: src/main.rs
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Permiterea creării de noi postări în starea de schiță prin intermediul Post::new și abilitatea de a adăuga text conținutului postării rămân neschimbate. Dar, în loc să avem o metodă content pe o postare schiță care să întoarcă un string gol, vom aranja astfel încât schițele de postări pur și simplu să nu dispună de metoda content. În acest mod, dacă încercăm să accesăm conținutul unei postări schițe, vom primi o eroare de compilare care ne indică faptul că metoda nu există. Prin urmare, ne va fi imposibil să afișăm din greșeală conținutul unei schițe de postare în producție, deoarece codul respectiv nu ar trece de compilare. Listarea 17-19 oferă definiția unei structuri Post și a unei structuri DraftPost, împreună cu metodele fiecăreia:
Numele fișierului: src/lib.rs
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}Listarea 17-19: Un Post cu metoda content și un DraftPost fără metoda content
Atât structura Post, cât și DraftPost includ un câmp content privat, care stochează textul postării de pe blog. Structurile nu mai conțin câmpul state, deoarece acțiunea de codificare a stării se mută la nivelul tipurilor de date ale structurilor. Structura Post va reprezenta o postare publicată și are metoda content care returnează content.
Avem încă funcția Post::new, dar în loc să returneze o instanță de Post, ea returnează o instanță de DraftPost. Fiind privat și fără funcții care să returneze un Post, nu este posibilă crearea unei instanțe de Post în acest moment.
Structura DraftPost dispune de metoda add_text, permițându-ne să adăugăm text la content ca și înainte, însă este de remarcat faptul că DraftPost nu are definită metoda content! Așadar, programul garantează că toate postările încep ca schițe, iar conținutul schițelor nu este disponibil pentru afișare. Oricărei încercări de a evita aceste restricții i se va opune o eroare de compilator.
Implementarea tranzițiilor ca transformări în diferite tipuri
Deci, cum obținem un post publicat? Ne dorim să impunem regula că o schiță de post trebuie să fie revizuită și aprobată înainte să poată fi publicată. Un post aflat în stadiul de revizuire în așteptare nu ar trebui să afișeze vreun conținut. Să realizăm aceste constrângeri prin adăugarea unei noi structuri, PendingReviewPost, definind metoda request_review în DraftPost pentru a returna un PendingReviewPost, și creând metoda approve în PendingReviewPost pentru a returna un Post, așa cum este ilustrat în Listarea 17-20:
Numele fișierului: src/lib.rs
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// --snip--
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}Listarea 17-20: Un PendingReviewPost care e creat prin apelarea request_review asupra unui DraftPost și o metodă approve care transformă un PendingReviewPost într-un Post publicat
Metodele request_review și approve preiau controlul asupra variabilei self, consumând astfel instanța de DraftPost, respectiv PendingReviewPost, și transformând-o într-un PendingReviewPost și ulterior într-un Post publicat. Astfel, nu rămânem cu instanțe de DraftPost după ce folosim request_review pe acestea și așa mai departe. Structura PendingReviewPost nu are o metodă content definită, astfel, încercarea de a citi conținutul său duce la o eroare de compilare, similar cu DraftPost. Fiindcă singura cale de a avea o instanță de Post publicat, ce are o metodă content, este prin apelarea approve pe un PendingReviewPost, și singura metodă de a obține un PendingReviewPost este prin request_review aplicată la un DraftPost. Aceste proceduri ne permit să codificăm fluxul de lucru pentru postările de blog în cadrul sistemului de tipuri.
Totuși, sunt necesare unele ajustări în main. Metodele request_review și approve generează noi instanțe, în loc să modifice structurile asupra cărora sunt invocate, astfel avem nevoie să adăugăm noi atribuiri let post = pentru a salva instanțele rezultate. Nu mai este posibil să avem aserțiuni despre conținuturi goale pentru schițe sau posturi aflate în revizuire, și nici nu sunt necesare: codul care încerca să acceseze conținutul posturilor în acele stări nu mai poate fi compilat. Codul actualizat din main este prezentat în Listarea 17-21:
Numele fișierului: src/main.rs
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Listarea 17-21: Modificările necesare în main pentru a folosi noua abordare a procesului de postare pe blog
Modificările pe care le-am făcut în main pentru reatribuirea variabilei post indică faptul că această implementare nu mai respectă cu strictețe modelul de stare orientat pe obiecte: transformările între stări nu sunt complet încapsulate în implementarea lui Post. Cu toate acestea, avantajul obținut este că stările invalide devin imposibile datorită sistemului de tipuri și a verificării tipurilor efectuate la compilare! Aceasta garantează că anumite erori, cum ar fi afișarea conținutului unui post nepublicat, sunt detectate înainte de lansarea în producție.
Aplică sarcinile sugerate la începutul acestei secțiuni pe crate-ul blog după cum arată în urma Listării 17-21 pentru a evalua designul acestei versiuni de cod. Vei vedea că unele sarcini ar putea fi deja îndeplinite de acest design.
Am observat că, deși Rust permite implementarea modelelor de design orientate pe obiecte, sunt și alte pattern-uri disponibile, cum ar fi codificarea stării în sistemul de tipuri, ce pot fi exploatate. Aceste pattern-uri au diverse compromisuri. Deși s-ar putea să fii obișnuit cu pattern-urile orientate obiect, reconsiderarea problemei pentru a valorifica caracteristicile Rust poate aduce beneficii suplimentare, cum ar fi prevenirea anumitor erori chiar în faza de compilare. Nu întotdeauna modelele obiectuale vor reprezenta cea mai optimă soluție în Rust, având în vedere trăsături unice ale limbajului, precum sistemul de posesiune, care nu sunt întâlnite în limbajele obiectuale tradiționale.
Sumar
Indiferent dacă ai concluzionat sau nu că Rust este un limbaj orientat pe obiecte după lectura acestui capitol, acum știi că poți folosi obiecte-trăsătură pentru a accesa unele dintre caracteristicile orientate pe obiecte în Rust. Invocarea dinamică oferă codului flexibilitate, costând însă puțin din performanța la rulare. Această flexibilitate îți permite să implementezi pattern-uri orientate pe obiecte care pot îmbunătăți întreținerea codului. Rust dispune și de alte caracteristici, cum ar fi posesiunea, ce nu sunt prezente în limbajele orientate pe obiecte. Utilizarea unui pattern orientat pe obiecte nu va fi mereu cea mai bună metodă de a valorifica puterea Rust, însă este o alternativă posibilă.
În continuare, ne vom aprofunda în studiul pattern-urilor, care reprezintă o altă facilitate a Rust ce permite o gamă largă de flexibilitate. Am abordat pattern-urile în treacăt pe tot parcursul cărții, dar acum urmează să le vedem întregul potențial. Să avansăm în explorare!
Pattern-urile și potrivirea
Pattern-urile (a nu se confunda cu pattern-urile de design) reprezintă o sintaxă specială în Rust dedicată potrivirii cu structura tipurilor, fie ele complexe sau simple. Folosirea pattern-urilor în conjuncție cu expresiile match și alte construcții îți oferă mai mult control asupra fluxului de execuție al programului. Un pattern este alcătuit dintr-o combinație a următoarelor elemente:
- Literali
- Array-uri, enumerări, struct-uri sau tuple-uri destructurate
- Variabile
- Wildcard-uri
- Placeholder-uri
Printre exemple de pattern-uri se numără x, (a, 3) și Some(Color::Red). În contextele unde pattern-urile sunt aplicabile, aceste componente descriu structura datelor. Programul nostru corelează apoi valorile împotriva pattern-urilor pentru a determina dacă acestea corespund cu structura de date necesară pentru a executa o porțiune de cod.
Pentru a folosi un pattern, îl comparăm cu o valoare. Dacă pattern-ul se potrivește cu valoarea, folosim acele părți ale valorii în codul nostru. Amintește-ți de expresiile match din Capitolul 6 care au utilizat pattern-uri, precum exemplul cu mașina de sortat monede. Dacă valoarea se încadrează în structura pattern-ului, putem folosi piesele cu denumiri specifice. În caz contrar, secțiunea de cod asociată cu acel pattern nu va fi executată.
Acest capitol este un ghid complet despre tot ce este legat de pattern-uri. Vom explora contextele adecvate pentru utilizarea pattern-urilor, diferența între pattern-urile contestabile și incontestabile, precum și diferitele tipuri de sintaxă pattern pe care le vei întâlni. Până la finalul capitolului, vei învăța cum să folosești pattern-urile pentru exprimarea clară a multor concepte.
Toate locurile unde pattern-urile pot fi utilizate
Pattern-urile pot fi întâlnite în mai multe locuri în Rust, fiind utilizate frecvent fără a ne da seama! În această secțiune, vom vedea toate locurile unde aceste pattern-uri sunt valide.
Ramurile match
După cum am explicat în Capitolul 6, pattern-urile sunt utilizate în ramurile expresiilor match. Formal, expresiile match sunt definite prin cuvântul cheie match, o valoare cu care se face potrivirea, și unul sau mai multe ramuri de match care conțin un pattern și o expresie ce va fi executată dacă valoarea se potrivește cu pattern-ul respectivului ram, astfel:
match VALUE {
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
}
De exemplu, aceasta este expresia match din Listarea 6-5 care face potrivirea pe o valoare Option<i32> în variabila x:
match x {
None => None,
Some(i) => Some(i + 1),
}Pattern-urile din această expresie match sunt None și Some(i), care se află în partea stângă a fiecărei săgeți.
O cerință pentru expresiile match este ca acestea să fie exhaustive, adică toate posibilitățile pentru valoarea subiect a expresiei match să fie acoperite. Una dintre metodele de a asigura că toate posibilitățile sunt cuprinse este de a include un pattern universal pentru ultimul ram: de exemplu, folosirea unui nume de variabilă care se potrivește cu orice valoare nu va da greș niciodată, cuprinzând astfel fiecare caz nemenționat anterior.
Pattern-ul specific _ va potrivi orice, însă nu se va lega de vreo variabilă, așa că deseori este utilizat în ultimul ram de match. Pattern-ul _ poate fi folositor atunci când dorim să ignorăm orice valoare care nu a fost specificată anterior, de exemplu. Vom analiza pattern-ul _ în mai multe detalii în secțiunea „Ignorarea valorilor într-un pattern”, mai târziu în acest capitol.
Expresii condiționale if let
În Capitolul 6, am discutat utilizarea expresiilor if let ca o formă mai concisă pentru a scrie echivalentul unei expresii match care se potrivește doar cu un singur caz. Opțional, if let poate include și un bloc else, care conține codul ce va fi executat dacă pattern-ul din if let nu se potrivește.
Listarea 18-1 demonstrează că este posibil să combinăm și să alternăm expresiile if let, else if, și else if let. Aceasta ne oferă o flexibilitate sporită în comparație cu o expresie match, unde putem compara o singură valoare cu pattern-urile. Mai mult, Rust nu solicită ca condițiile dintr-o serie de verificări if let, else if, else if let să fie interconectate.
Codul prezentat în Listarea 18-1 stabilește ce culoare să folosim pentru fond bazat pe o serie de condiții multiple. În acest exemplu, am definit variabile cu valori prestabilite, așa cum într-un program real acestea ar putea fi primite din intrările utilizatorilor.
fn main() { let favorite_color: Option<&str> = None; let is_tuesday = false; let age: Result<u8, _> = "34".parse(); if let Some(color) = favorite_color { println!("Using your favorite color, {color}, as the background"); } else if is_tuesday { println!("Tuesday is green day!"); } else if let Ok(age) = age { if age > 30 { println!("Using purple as the background color"); } else { println!("Using orange as the background color"); } } else { println!("Using blue as the background color"); } }
Listarea 18-1: Alternanța expresiilor if let, else if, else if let, și else
Dacă utilizatorul indică o culoare preferată, aceasta este utilizată ca fond. Dacă nu este specificată nicio culoare preferată și astăzi e marți, culoarea de fond va fi verde. În caz contrar, dacă utilizatorul specifică vârsta sa ca string și putem să o convertim cu succes într-un număr, culoarea va fi ori mov, ori portocaliu, în funcție de valoarea numărului. Dacă niciuna dintre aceste condiții nu este îndeplinită, culoarea de fond va fi albastru.
Structura condițională descrisă ne permite gestionarea unor cerințe complexe. Având în vedere valorile prestabilite din acest exemplu, rezultatul va fi afișarea mesajului Using purple as the background color.
Reiese că expresiile if let pot introduce variabile umbrite în aceeași manieră ca brațele unui match: linia cu if let Ok(age) = age introduce o nouă variabilă umbrită age, care stochează valoarea din varianta Ok. De aceea, condiția if age > 30 trebuie să se afle în blocul respectiv de cod: nu putem combina aceste două condiții în if let Ok(age) = age && age > 30, căci variabila umbrită age pe care dorim să o comparăm cu 30 nu devine validă decât în momentul inițierii noului domeniu de vizibilitate cu acolada.
Un dezavantaj al folosirii if let este că compilatorul nu verifică exhaustivitatea, spre deosebire de expresiile match, care sunt verificate. Dacă am omite blocul else final, ratând astfel tratarea unor cazuri, compilatorul nu ne-ar semnala posibila greșeală de logică.
Bucle condiționale while let
Asemenea construcției if let, bucla condițională while let permite buclei while să fie executată cât timp un pattern continuă să fie potrivit. În Listarea 18-2, implementăm o buclă while let care folosește un vector ca stivă și afișează valorile din vector în ordinea inversă în care au fost introduse.
fn main() { let mut stack = Vec::new(); stack.push(1); stack.push(2); stack.push(3); while let Some(top) = stack.pop() { println!("{}", top); } }
Listarea 18-2: Utilizarea unei bucle while let pentru a afișa valori atâta timp cât stack.pop() returnează Some
Acest exemplu afișează 3, 2 și apoi 1. Metoda pop înlătură ultimul element din vector și returnează Some(value). Dacă vectorul este gol, pop returnează None. Bucala while continuă execuția codului din blocul său cât timp pop returnează Some. Când pop returnează None, bucla se oprește. Utilizăm while let pentru a elimina pe rând fiecare element din stiva noastră.
Buclele for
Într-o buclă for, valoarea care urmează imediat după cuvântul cheie for este un pattern. De exemplu, în for x in y, x este pattern-ul. Listarea 18-3 ne arată cum folosim un pattern într-o buclă for pentru a destructura o tuplă ca parte a execuției buclei for.
fn main() { let v = vec!['a', 'b', 'c']; for (index, value) in v.iter().enumerate() { println!("{} is at index {}", value, index); } }
Listarea 18-3: Utilizarea unui pattern într-o buclă for pentru a destrucura o tuplă
Codul din Listarea 18-3 va afișa următorul output:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished dev [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
Modificăm un iterator cu metoda enumerate pentru ca acesta să ofere o valoare și indicele acelei valori într-o tuplă. Prima valoare generată este tupla (0, 'a'). Când această valoare potrivește cu pattern-ul (index, value), index va fi 0, iar value va fi 'a', ceea ce rezultă în afișarea primei linii a output-ului.
Declarațiile let
Până la acest capitol, am discutat explicit despre utilizarea pattern-urilor doar cu match și if let, dar de fapt, am aplicat pattern-uri și în alte contexte, inclusiv în declarațiile let. De exemplu, să luăm în considerare această atribuire simplă de variabilă cu let:
#![allow(unused)] fn main() { let x = 5; }
De fiecare dată când ai utilizat o declarație let cum este aceasta, ai folosit pattern-uri, chiar dacă poate nu ai realizat acest lucru! Mai formal, o declarație let se prezintă în felul următor:
let PATTERN = EXPRESSION;
În declarații precum let x = 5; cu un nume de variabilă în poziția PATTERN, numele variabilei este de fapt o formă extrem de simplificată de pattern. Rust corespunde expresia cu pattern-ul și atribuie orice nume identifică. Așadar, în exemplul let x = 5;, x este un pattern care înseamnă “asociază ce se potrivește aici variabilei x.” Întrucât x reprezintă întregul pattern, acesta de fapt înseamnă “asociază orice valoare variabilei x, indiferent de aceasta.”
Pentru a înțelege mai clar aspectul de potrivire de pattern într-o declarație let, să ne referim la Listarea 18-4, unde se utilizează un pattern cu let pentru a destructura o tuplă.
fn main() { let (x, y, z) = (1, 2, 3); }
Listarea 18-4: Utilizând un pattern pentru a destrucura o tuplă și a crea trei variabile simultan
În acest caz, se face un match între o tuplă și un pattern. Rust compară valoarea (1, 2, 3) cu pattern-ul (x, y, z) și observă că valoarea se potrivește cu pattern-ul, astfel Rust leagă 1 la x, 2 la y, și 3 la z. Acest pattern de tuplă poate fi văzut ca o compoziție a trei pattern-uri individuale de variabila.
Dacă numărul elementelor din pattern nu se potrivește cu numărul elementelor din tuplă, tipul total nu va corespunde și vom întâlni o eroare de compilare. De exemplu, Listarea 18-5 prezintă o tentativă de a destructura o tuplă cu trei elemente în doar două variabile, ceea ce nu va funcționa.
fn main() {
let (x, y) = (1, 2, 3);
}Listarea 18-5: Crearea incorectă a unui pattern în care variabilele nu corespund cu numărul de elemente din tuplă
Încercarea de a compila acest cod rezultă în următoarea eroare de tip:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` due to previous error
Pentru a rezolva eroarea, putem omite una sau mai multe valori ale tuplei folosind _ sau .., cum vom vedea în secțiunea „Ignorarea valorilor într-un pattern”. Dacă problema este că avem prea multe variabile în pattern, soluția constă în a ajusta tipurile prin eliminarea variabilelor până când numărul de variabile este egal cu numărul elementelor din tuplă.
Parametrii funcțiilor
Parametrii funcțiilor pot de asemenea să fie pattern-uri. Codul din Listarea 18-6, care declară o funcție denumită foo ce primește un parametru numit x de tip i32, ar trebui să ne fie acum cunoscut.
fn foo(x: i32) { // code goes here } fn main() {}
Listarea 18-6: O semnătură de funcție utilizează pattern-uri în parametri
Partea cu x reprezintă un pattern! Așa cum am procedat cu let, se poate potrivi o tuplă cu un pattern în argumentele unei funcții. Listarea 18-7 demonstrează despărțirea valorilor dintr-o tuplă pe când sunt transmise unei funcții.
Numele fișierului: src/main.rs
fn print_coordinates(&(x, y): &(i32, i32)) { println!("Current location: ({}, {})", x, y); } fn main() { let point = (3, 5); print_coordinates(&point); }
Listarea 18-7: O funcție cu parametri ce destructurează o tuplă
Acest fragment de cod afișează Current location: (3, 5). Valorile &(3, 5) se potrivesc cu pattern-ul &(x, y), astfel x devine valoarea 3 iar y, valoarea 5.
Putem folosi de asemenea și pattern-uri în listele de parametri ale închiderilor în mod similar cu listele de parametri ale funcțiilor, având în vedere că închiderile sunt asemănătoare cu funcțiile, așa cum am discutat în Capitolul 13.
Ajuns aici, am avut ocazia să vedem câteva metode de utilizare a pattern-urilor, însă acestea nu funcționează identic în toate locurile în care le putem folosi. În unele situații, pattern-urile trebuie să fie irefutabile, în timp ce în altele pot fi refutabile. Vom explora aceste două concepte în detaliu în continuare.
Refutabilitatea: când un pattern ar putea eșua la potrivire
Există două tipuri de pattern-uri: refutabile și irefutabile. Pattern-urile care se vor potrivi cu orice valoare posibilă sunt irefutabile. De exemplu, x din let x = 5; este irefutabil, deoarece x poate reprezenta orice valoare și astfel nu poate să nu se potrivească. Pattern-urile care ar putea să nu se potrivească pentru anumite valori sunt refutabile. Un astfel de exemplu este Some(x) din if let Some(x) = a_value, unde dacă a_value este None și nu Some, pattern-ul Some(x) va eșua să se potrivească.
Parametrii funcțiilor, instrucțiunile let și buclele for necesită pattern-uri irefutabile, deoarece programul nu are cum să procedeze în mod semnificativ atunci când valorile nu corespund. Expresiile if let și while let permit utilizarea ambelor tipuri de pattern-uri, însă compilatorul va avertiza împotriva folosirii pattern-urilor irefutabile, deoarece acestea sunt proiectate să gestioneze posibilitatea unui eșec.
De regulă, nu ar trebui să ne îngrijorăm despre diferența dintre pattern-urile refutabile și irefutabile; totuși, este important să înțelegem conceptul de refutabilitate pentru a putea răspunde corect atunci când întâmpinăm acești termeni în mesajele de eroare ale compilatorului. În astfel de situații, va trebui să ajustăm fie pattern-ul, fie contextul în care este folosit, în funcție de comportamentul dorit în cod.
Să examinăm un exemplu care ilustrează ce se întâmplă când încercăm să folosim un pattern refutabil în locul unuia irefutabil și invers. Listarea 18-8 ne arată o instrucțiune let unde am utilizat Some(x), un pattern refutabil. După cum putem anticipa, codul acesta nu va fi compilat.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value;
}
<span class="caption">Listarea 18-8: Tentativa de a folosi un pattern refutabil cu `let`</span>
Dacă `some_option_value` ar fi `None`, nu va corespunde cu pattern-ul `Some(x)`, indicând că pattern-ul este refutabil. Totuși, `let` necesită un pattern irefutabil pentru că, altfel, nu poate fi efectuată nici o operațiune validă cu valoarea `None`. La momentul compilării, Rust va indica eroarea de a încerca să folosim un pattern refutabil unde este cerut unul irefutabil:
```console
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding: `None` not covered
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch18-02-refutability.html
note: `Option<i32>` defined here
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/option.rs:518:1
|
= note:
/rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/option.rs:522:5: not covered
= note: the matched value is of type `Option<i32>`
help: you might want to use `if let` to ignore the variant that isn't matched
|
3 | let x = if let Some(x) = some_option_value { x } else { todo!() };
| ++++++++++ ++++++++++++++++++++++
help: alternatively, you might want to use let else to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` due to previous errorNe găsim în situația de a nu acoperi prin pattern-ul Some(x) toate valorile posibile, ceea ce conduce corect la o eroare de compilare în Rust.
Dacă avem un pattern refutabil unde se cere unul irefutabil, putem remedia situația modificând codul care îl folosește: în loc de let, putem opta pentru if let. Dacă pattern-ul nu se potrivește, codul va omite pur și simplu secțiunea din acolade, permițând continuarea executării în mod valid. Listarea 18-9 prezintă cum putem corecta codul din Listarea 18-8.
fn main() { let some_option_value: Option<i32> = None; if let Some(x) = some_option_value { println!("{}", x); } }
Listarea 18-9: Utilizarea if let și a unui bloc cu pattern-uri refutabile în loc de let
Acum codul are o cale de ieșire! Această variantă este complet validă, chiar dacă înseamnă că nu putem folosi un pattern irefutabil fără a avea parte de o eroare. În cazul în care if let primește un pattern care va coincide mereu, cum ar fi x din Listarea 18-10, compilatorul va semnala un avertisment.
fn main() { if let x = 5 { println!("{}", x); }; }
Listarea 18-10: Încercarea de folosire a unui pattern irrefutabil cu if let
Rust sugerează că nu este logic să utilizăm if let cu un pattern care nu poate eșua:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `if let` pattern
--> src/main.rs:2:8
|
2 | if let x = 5 {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `if let` is useless
= help: consider replacing the `if let` with a `let`
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
5
Din acest motiv, în instrucțiunea match, trebuie să folosim pattern-uri refutabile, cu excepția ultimului caz, care ar trebui să acopere orice valori rămase cu un pattern irefutabil. Deși Rust permite utilizarea unui pattern irefutabil într-un match cu un singur caz, această sintaxă nu este foarte practică și ar putea fi simplificată prin folosirea unei instrucțiuni let mai directe.
Înțelegând unde și cum să folosim pattern-urile, cât și distincția dintre cele refutabile și irefutabile, să explorăm acum toată sintaxa disponibilă pentru crearea pattern-urilor.
Sintaxa pattern-urilor
În această secțiune colectăm toată sintaxa validă în pattern-uri și discutăm de ce și când ar putea fi dorită utilizarea fiecărui tip.
Potrivirea literalilor
După cum am văzut în Capitolul 6, este posibil să potrivim pattern-uri direct cu literali. Următorul cod oferă câteva exemple:
fn main() { let x = 1; match x { 1 => println!("one"), 2 => println!("two"), 3 => println!("three"), _ => println!("anything"), } }
Acest cod afișează one deoarece valoarea în x este 1. Această sintaxă este folositoare atunci când dorim ca codul nostru să efectueze o acțiune dacă primește o valoare concretă specifică.
Potrivirea variabilelor denumite
Variabilele denumite sunt pattern-uri irefutabile, care se potrivesc cu orice valoare, și le-am folosit deja de mai multe ori în această carte. Totuși, apare o complicație atunci când folosim variabile denumite în expresiile match. Deoarece match declanșează începutul unui nou domeniu de vizibilitate, variabilele declarate ca parte a unui pattern în interiorul expresiei match vor "umbri" acele variabile cu același nume aflate în afara construcției match, la fel ca în cazul tuturor variabilelor. În Listarea 18-11, declarăm o variabilă x cu valoarea Some(5) și o altă variabilă y cu valoarea 10. Apoi, construim o expresie match bazată pe valoarea lui x. Observăm pattern-urile din ramurile match și println! de la final, și încercăm să prevedem ce va afișa codul înainte de a-l rula sau de a citi în continuare.
Numele fișierului: src/main.rs
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(y) => println!("Matched, y = {y}"), _ => println!("Default case, x = {:?}", x), } println!("at the end: x = {:?}, y = {y}", x); }
Listarea 18-11: O expresie match care include un braț ce introduce o variabilă y umbrită
Să vedem ce se întâmplă atunci când se execută expresia match. Pattern-ul din primul braț al match-ului nu corespunde cu valoarea definită a lui x, astfel că execuția codului continuă.
Pattern-ul din al doilea braț al match-ului prezintă o nouă variabilă, y, care va potrivi orice valoare încapsulată într-un Some. Deoarece acesta se află într-un domeniu de vizibilitate nou în interiorul expresiei match, reprezintă un nou y, diferit de y-ul pe care l-am declarat inițial cu valoarea 10. Acest y recent se va potrivi cu orice valoare dintr-un Some, exact ceea ce avem în x. Astfel, noul y se leagă de valoarea interioară a Some din x, care este 5, iar brațul respectiv execută și afișează Matched, y = 5.
Dacă x ar fi fost None în loc de Some(5), pattern-urile din primele două brațe nu s-ar fi potrivit, iar valoarea ar fi corespuns cu caracterul underscore. În această repetiție, nu am introdus variabila x în pattern-ul brațului cu underscore, deci x din expresie este în continuare x-ul extern care nu a fost umbrit. În acest scenariu ipotetic, match-ul ar fi afișat Default case, x = None.
După finalizarea expresiei match, domeniul de vizibilitate a acesteia se încheie, iar y-ul intern nu mai este accesibil. Ultimul println! rezultă în at the end: x = Some(5), y = 10.
Pentru a forma o expresie match care să compare valorile lui x și y externe, în loc să introducem o variabilă umbrită, ar trebui să folosim o condiție suplimentară cu gardă de match. Vom discuta despre gărzile de match într-o secțiune ulterioară numită „Condiții suplimentare cu gărzi de match”.
Pattern-uri multiple
În expresiile de tip match, putem să corelăm mai multe pattern-uri utilizând operatorul |, care reprezintă pattern-ul sau. De exemplu, în codul de mai jos, comparăm valoarea lui x cu ramurile de match, iar prima dintre ele, având o opțiune sau, va rula codul aferent dacă x se potrivește cu oricare dintre valorile specificate în acea ramură:
fn main() { let x = 1; match x { 1 | 2 => println!("one or two"), 3 => println!("three"), _ => println!("anything"), } }
Acest cod va genera afișajul one or two.
Potrivirea diapazoanelor de valori cu ..=
Prin utilizarea sintaxei ..=, putem potrivi o secvență întreagă de valori. În exemplul următor, dacă un pattern corespunde cu oricare dintre valorile din diapazon, ramura respectivă va fi activată:
fn main() { let x = 5; match x { 1..=5 => println!("one through five"), _ => println!("something else"), } }
Dacă x este unul dintre numerele 1, 2, 3, 4 sau 5, prima ramură va fi selectată. Această metodă de specificare a unui diapazon este mai eficientă decât utilizarea repetată a operatorului |, evitând astfel o construcție de tipul 1 | 2 | 3 | 4 | 5. Acest mod de exprimare este deosebit de util când dorim să potrivim un interval extins, precum între 1 și 1,000!
Compilatorul verifică în timpul compilării că diapazonul selectat nu este gol, iar Rust permite folosirea diapazoanelor doar pentru tipurile char și numeric, unde este posibil să se constate dacă intervalul este sau nu populat.
Iată cum arată utilizarea diapazoanelor pentru valori de tip char:
fn main() { let x = 'c'; match x { 'a'..='j' => println!("early ASCII letter"), 'k'..='z' => println!("late ASCII letter"), _ => println!("something else"), } }
Rust detectează că 'c' se află în domeniul primei ramuri și afișează early ASCII letter.
Destructurarea structurilor, enum-urilor și tuplelor
Pattern-urile sunt de asemenea utile în destructurarea structurilor, enumerărilor și tuplelor, oferindu-ne posibilitatea de a accesa diferite secțiuni ale acestor tipuri de valori. Analizăm fiecare tip în parte.
Destructurarea structurilor
Listarea 18-12 prezintă o structură Point cu două câmpuri, x și y, pe care le putem separa folosind un pattern într-o instrucțiune let.
Numele fișierului: src/main.rs
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x: a, y: b } = p; assert_eq!(0, a); assert_eq!(7, b); }
Listarea 18-12: Separarea câmpurilor unei structuri în variabile diferite
Acest cod generează variabilele a și b care preiau valorile câmpurilor x și y ale structurii p. Acest exemplu ne arată că numele variabilelor din pattern nu trebuie să corespundă cu numele câmpurilor structurii. Cu toate acestea, este comun să aliniem numele variabilelor cu numele câmpurilor pentru a facilita reținerea sursei variabilelor. Din acest motiv, și pentru că expresia let Point { x: x, y: y } = p; include repetiții inutile, Rust oferă o formă prescurtată pentru pattern-uri care se potrivesc cu câmpurile structurilor: e suficient să enumerăm numele câmpului structurii și variabilele rezultate din pattern vor purta aceleași nume. Listarea 18-13 funcționează la fel ca și codul din Listarea 18-12, însă variabilele create în pattern-ul let sunt x și y, nu a și b.
Numele fișierului: src/main.rs
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x, y } = p; assert_eq!(0, x); assert_eq!(7, y); }
Listarea 18-13: Destructurarea câmpurilor unei structuri folosind o formă prescurtată pentru câmpuri
Acest cod creează variabilele x și y care se potrivesc cu câmpurile x și y ale variabilei p. Rezultatul este că variabilele x și y conțin valorile din structura p.
De asemenea, putem folosi valori literale în cadrul pattern-ului unei structuri, în loc să generăm variabile pentru fiecare câmp. Aceasta ne permite să verificăm anumite câmpuri pentru valori specifice dar tot creând variabile pentru extragerea valorilor celorlalte câmpuri.
În Listarea 18-14, avem o expresie match care categorizează valorile Point în trei situații: puncte care se regăsesc exact pe axa x (când y = 0), pe axa y (x = 0) sau niciuna dintre acestea.
Numele fișierului: src/main.rs
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; match p { Point { x, y: 0 } => println!("On the x axis at {x}"), Point { x: 0, y } => println!("On the y axis at {y}"), Point { x, y } => { println!("On neither axis: ({x}, {y})"); } } }
Listarea 18-14: Destructurarea și potrivirea valorilor literale în același pattern
Prima ramură va corespunde oricărui punct de pe axa x prin faptul că specifică pentru câmpul y să se potrivească cu valoarea literală 0. Pattern-ul în continuare generează o variabilă x care poate fi folosită în cod pentru această ramură.
Similar, a doua ramură corespunde oricărui punct de pe axa y prin specificarea că câmpul x se potrivește atunci când valoarea este 0 și astfel se generează o variabilă y pentru valoarea câmpului y. A treia ramură nu definește nicio valoare literală, deci potrivește orice alt Point și generează variabile pentru ambele câmpuri x și y.
În acest exemplu, valoarea p se aliniază cu a doua ramură datorită faptului că x conține un 0, deci codul va afișa „On the y axis at 7“.
Amintim că o expresie match încetează să evalueze ramurile după ce găsește primul pattern corespunzător, astfel încât chiar și pentru Point { x: 0, y: 0} care se află și pe axa x și pe axa y, codul va afișa doar „On the x axis at 0“.
Destructurarea enumerărilor
Am destructurat enumerări în această carte (de exemplu, Listarea 6-5 din Capitolul 6), dar nu am discutat explicit faptul că pattern-ul folosit pentru a destructura un enum corespunde cu modul în care sunt definite datele stocate în acel enum. De exemplu, în Listarea 18-15 utilizăm enum-ul Message din Listarea 6-2 și compunem un match cu pattern-uri ce vor destructura fiecare valoare internă.
Filename: src/main.rs
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() { let msg = Message::ChangeColor(0, 160, 255); match msg { Message::Quit => { println!("The Quit variant has no data to destructure."); } Message::Move { x, y } => { println!("Move in the x direction {x} and in the y direction {y}"); } Message::Write(text) => { println!("Text message: {text}"); } Message::ChangeColor(r, g, b) => { println!("Change the color to red {r}, green {g}, and blue {b}",) } } }
Listarea 18-15: Destructurarea variantelor de enum care stochează diferite tipuri de valori
Acest cod va genera afișajul Change the color to red 0, green 160, and blue 255. Modificați valoarea lui msg pentru a observa execuția codului din celelalte brațe ale match-ului.
Pentru variantele de enum care nu conțin date, precum Message::Quit, nu putem să continuăm destructurarea. Putem doar să facem match pe valoarea literală Message::Quit, fără variabile în acel pattern.
Pentru variantele de enum similare cu structurile, precum Message::Move, putem utiliza un pattern asemănător cu cel folosit pentru match pe structuri. După denumirea variantei, introducem acolade și apoi specificăm câmpurile cu variabile, permițându-ne să desfacem componentele pentru a le utiliza în codul acestui braț. Aici aplicăm forma prescurtată, așa cum am procedat în Listarea 18-13.
În cazul variantelor de enum similare cu tuple, ca Message::Write ce conține o tuplă cu un singur element și Message::ChangeColor ce conține o tuplă cu trei elemente, pattern-ul este similar cu cel utilizat pentru match pe tuple. Numărul variabilelor din pattern trebuie să coincidă cu numărul de elemente din varianta cu care facem match.
Destructurarea structurilor și enumerărilor imbricate
Până acum, în exemplele noastre s-a făcut potrivirea structurilor sau enumerărilor la un singur nivel de adâncime, însă potrivirea poate fi folosită și pentru elemente imbricate! De exemplu, codul din Listarea 18-15 poate fi refactorizat pentru a accepta culorile RGB și HSV în mesajul ChangeColor, așa cum este prezentat în Listarea 18-16.
enum Color { Rgb(i32, i32, i32), Hsv(i32, i32, i32), } enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(Color), } fn main() { let msg = Message::ChangeColor(Color::Hsv(0, 160, 255)); match msg { Message::ChangeColor(Color::Rgb(r, g, b)) => { println!("Change color to red {r}, green {g}, and blue {b}"); } Message::ChangeColor(Color::Hsv(h, s, v)) => { println!("Change color to hue {h}, saturation {s}, value {v}") } _ => (), } }
Listarea 18-16: Potrivire pe enum-uri imbricate
Pattern-ul primei ramuri în expresia match se potrivește cu varianta Message::ChangeColor a enumerării, care conține varianta Color::Rgb; apoi pattern-ul face legătura cu cele trei valori interne i32. Pattern-ul celei de-a doua ramuri se potrivește de asemenea cu varianta Message::ChangeColor a enumerării, dar enumerarea internă se potrivește cu Color::Hsv. Putem specifica aceste condiții complexe într-o singură expresie match, chiar dacă sunt implicate două enumerări.
Destructurarea structurilor și tuplelor
Putem combina, potrivi și imbrica pattern-uri de destructurare în moduri chiar mai complexe. Următorul exemplu ilustrează o destructurare avansată în care structurile și tupletele sunt imbricate într-o tuplă și, apoi, extragem toate valorile primitive:
fn main() { struct Point { x: i32, y: i32, } let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 }); }
Această tehnică ne permite să destructurăm tipuri complexe în componente individuale pentru a putea folosi valorile necesare în mod separat.
Destructurarea cu ajutorul pattern-urilor este un mod convenabil de a accesa părți din valori, cum ar fi valorile din fiecare câmp al unei structuri, în mod separat.
Ignorarea valorilor într-un pattern
Am observat că este uneori util să ignorăm anumite valori într-un pattern, cum ar fi în cazul ultimei ramuri a unui match, pentru a avea un caz general care, deși nu efectuează nicio acțiune concretă, acoperă toate celelalte valori posibile. Există diferite metode pentru a ignora valori întregi sau părți ale valorilor într-un pattern: utilizând pattern-ul _ (cu care suntem deja familiari), folosind pattern-ul _ în cadrul unui alt pattern, utilizând un nume care începe cu un underscore _ sau folosind .. pentru a omite părțile rămase ale unei valori. Vom explora cum și de ce să utilizăm fiecare dintre aceste tehnici de pattern-uri.
Ignorarea completă a valorii cu _
Am folosit simbolul _ (underscore) ca un pattern wildcard care se potrivește cu orice valoare, fără a se lega de ea. Aceast pattern este util în special ca ultima ramură a unei expresii match, dar _ poate fi folosit și în orice alt tip de pattern, inclusiv în parametrii funcțiilor, cum este ilustrat în Listarea 18-17.
Numele fișierului: src/main.rs
fn foo(_: i32, y: i32) { println!("This code only uses the y parameter: {}", y); } fn main() { foo(3, 4); }
Listarea 18-17: Utilizarea _ în semnătura unei funcții
Codul de mai sus va ignora în totalitate valoarea 3 transmisă ca prim argument și va afișa This code only uses the y parameter: 4.
De obicei, atunci când nu mai este nevoie de un parametru specific într-o funcție, semnătura acesteia se modifică pentru a nu include parametrul respectiv. Totuși, ignorarea unui parametru al funcției este deosebit de utilă în situații când, de exemplu, implementezi o trăsătură care necesită o semnătură tipică, însă corpul funcției din implementarea ta nu are nevoie de unul dintre parametri. Acest lucru te ajută să eviți avertismentele de la compilator despre parametrii nefolosiți, care ar apărea dacă ai folosi un nume pentru parametru.
Ignorarea părților specifice ale unei Valori cu _ imbricat
Putem utiliza _ și în interiorul altor pattern-uri pentru a ignora anumite părți ale unei valori, de exemplu, când dorim să ne concentrăm doar pe o componentă specifică a valorii și nu avem nevoie de restul ei în codul pe care dorim să-l executăm. Listarea 18-18 prezintă un cod responsabil de gestionarea valorii unei setări. Cerințele funcționale impun ca un utilizator să nu poată rescrie o personalizare existentă a setării, dar îi permite să reseteze setarea și să-i atribuie o valoare dacă în prezent este neconfigurată.
fn main() { let mut setting_value = Some(5); let new_setting_value = Some(10); match (setting_value, new_setting_value) { (Some(_), Some(_)) => { println!("Can't overwrite an existing customized value"); } _ => { setting_value = new_setting_value; } } println!("setting is {:?}", setting_value); }
Listarea 18-18: Utilizarea _ în cadrul pattern-urilor care potrivesc variantele Some și când nu este necesar să folosim valoarea conținută în Some
Codul va afișa mesajele Can't overwrite an existing customized value și după aceea setting is Some(5). În prima ramură a expresiei match, nu avem nevoie de potrivirea sau utilizarea valorilor din variantele Some, însă trebuie să detectăm cazul în care setting_value și new_setting_value sunt de tip Some. În această situație, explicăm de ce nu se schimbă valoarea setting_value, care rămâne neschimbată.
În toate celelalte cazuri (când setting_value sau new_setting_value sunt None), exprimate prin pattern-ul _ din cea de-a doua ramură, intenționăm să permitem ca new_setting_value să înlocuiască setting_value.
De asemenea, putem folosi _ în diferite părți ale unui singur pattern pentru a ignora valori specifice. Listarea 18-19 demonstrează cum se ignoră valorile de pe poziția a doua și a patra într-o tuplă de cinci elemente.
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, _, third, _, fifth) => { println!("Some numbers: {first}, {third}, {fifth}") } } }
Listarea 18-19: Ignorarea mai multor componente ale unei tuple
Codul va afișa Some numbers: 2, 8, 32, ignorând valorile 4 și 16.
Ignorarea unei variabile neutilizate prin începerea numelui acesteia cu _
Dacă definim o variabilă dar nu o folosim, Rust va emite de obicei un avertisment, pentru că o variabilă neutilizată poate indica prezența unui bug. Totuși, există momente când este util să definim o variabilă care nu va fi utilizată imediat, cum ar fi în timpul dezvoltării unui prototip sau la începutul unui proiect. În aceste cazuri, avem posibilitatea de a instrui Rust să nu emită avertismentul pentru variabila neutilizată dând variabilei un nume care începe cu un underscore. În Listarea 18-20, introducem două variabile neutilizate, dar când compilăm codul, ar trebui să primim avertisment doar pentru una dintre ele.
Numele fișierului: src/main.rs
fn main() { let _x = 5; let y = 10; }
Listarea 18-20: Începerea numelui unei variabile cu underscore pentru a evita avertismentele pentru variabile neutilizate
Primim un avertisment legat de neutilizarea variabilei y, dar nu primim niciun avertisment pentru neutilizarea variabilei _x.
Este crucial să înțelegem că există o diferență fină între utilizarea doar a _ și a unui nume care începe cu un underscore. Sintaxa _x încă asociază valoarea cu variabila, pe când _ nu face nici o asociere. Pentru exemplificare, în Listarea 18-21 vom vedea că acest aspect face o diferență semnificativă.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{:?}", s);
}Listarea 18-21: O variabilă neutilizată începând cu un underscore tot asociază valoarea, ceea ce poate duce la transferul posesiunii valorii
Vom întâlni o eroare deoarece valoarea s va fi transferată în variabila _s, preîntâmpinând astfel reutilizarea lui s. Pe de altă parte, utilizarea unui simplu underscore (_) nu va realiza nicio asociere. Conform Listării 18-22, codul va compila fără erori deoarece s nu este permutat.
fn main() { let s = Some(String::from("Hello!")); if let Some(_) = s { println!("found a string"); } println!("{:?}", s); }
Listarea 18-22: Folosirea underscore-ului nu asociază valoarea
Acest cod este funcțional pentru că s nu este legat de o altă entitate și, prin urmare, nu este permutat.
Ignorarea părților neutilizate ale unei valori cu ..
Atunci când lucrăm cu structuri sau tuple care includ multiple elemente, este posibil să folosim sintaxa .. pentru a selecta anumite componente și pentru a execluda restul, evitând astfel necesitatea de a insera underscore pentru fiecare element ignorat. Pattern-ul .. ignoră acele părți ale unei valori care nu au fost explicit potrivite în restul pattern-ului. De exemplu, în listarea 18-23, avem o structură numită Point care conține o coordonată în spațiul tridimensional. În expresia match, ne dorim să acționăm doar asupra coordonatei x, ignorând valorile din y și z.
fn main() { struct Point { x: i32, y: i32, z: i32, } let origin = Point { x: 0, y: 0, z: 0 }; match origin { Point { x, .. } => println!("x is {}", x), } }
Listarea 18-23: Ignorarea tuturor câmpurilor unui Point, în afara de x, utilizând ..
Pentru a face acest lucru, listăm valoarea pentru x și apoi includem pattern-ul ... Acest lucru este mult mai eficient decât să fie necesar să specificăm y: _ și z: _, și este deosebit de util în cazul structurilor cu multiple câmpuri, când doar unul sau două sunt relevante într-un anumit context.
Sintaxa .. se extinde automat pentru a acoperi numărul necesar de valori. Listarea 18-24 ilustrează cum .. poate fi folosit în cazul unui tuple.
Numele fișierului: src/main.rs
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, .., last) => { println!("Some numbers: {first}, {last}"); } } }
Listarea 18-24: Potrivirea primei și ultimei valori dintr-o tuplă și ignorarea tuturor celorlalte valori intermediare
În codul respectiv, valorile pentru first și last sunt potrivite, în timp ce .. se ocupă de ignorarea celorlalte valori intermediare.
Totuși, aplicarea lui .. trebuie să fie clară și lipsită de ambiguitate. Dacă nu este evident care valori sunt destinate potrivirii și care sunt de omis, compilatorul Rust va raporta o eroare. Listarea 18-25 ne arată un caz de utilizare ambiguă a lui .., care nu va permite compilarea codului respectiv.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {}", second)
},
}
}Listarea 18-25: Tentativa de utilizare ambiguă a sintaxei ..
Atunci când încercăm să compilăm acest exemplu, ne vom confrunta cu următoarea eroare:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` due to previous error
Este imposibil pentru Rust să determine câte valori să ignore în tuplă înainte de potrivirea cu variabila second și cât de multe să fie neglijate după aceea. Codul ar putea indica dorința de a ignora valorile 2, de a asocia variabila second cu 4 și apoi de a ignora valorile 8, 16 și 32; sau de a ignora valorile 2 și 4, apoi de a asocia second cu 8 și a ignora 16 și 32; și alte interpretări similare. Numele de variabilă second nu conferă nicio indicație specială pentru Rust, motiv pentru care ne confruntăm cu eroarea de compilare - folosirea lui .. în mai multe locuri crează ambiguitate.
Condiții adiționale cu gărzi match
Un gardă match (match guard) este o condiție suplimentară de tip if, specificată după pattern-ul dintr-un braț al instrucțiunii match, care de asemenea trebuie să corespundă pentru selecția acelui braț. Gărzile match sunt deosebit de utile pentru a exprima concepte mai complexe decât permite un simplu pattern.
Condiția poate accesa variabilele definite în pattern. Listarea 18-26 ilustrează o instrucțiune match unde primul braț are pattern-ul Some(x) și încorporează o gardă match if x % 2 == 0 (sentința va fi adevărată dacă numărul este par).
fn main() { let num = Some(4); match num { Some(x) if x % 2 == 0 => println!("The number {} is even", x), Some(x) => println!("The number {} is odd", x), None => (), } }
Listarea 18-26: Adăugarea unei gărzi match la un pattern
De exemplu, acest cod va afișa Numărul 4 este par. Atunci când num este comparat cu pattern-ul din primul braț, potrivirea este confirmată, deoarece Some(4) corespunde cu Some(x). Ulterior, garda evaluează dacă restul împărțirii lui x la 2 este zero, și fiind așa, primul braț este ales.
În situația în care num ar fi fost Some(5), garda match din primul braț nu ar fi fost îndeplinită, întrucât restul împărțirii lui 5 la 2 este 1, diferit de zero. Rust ar continua cu evaluarea brațului secund, care ar fi corespondent deoarece nu prezintă o gardă match și astfel potrivește orice variantă Some.
Expresia condițională if x % 2 == 0 nu poate fi integrată într-un pattern, așa că garda match ne permite să articulăm această logica. Partea negativă a acestei capacitați suplimentare de exprimare este că, atunci când sunt folosite expresiile că gărzi match, compilatorul nu mai verifică exhaustivitatea.
În Listarea 18-11, am menționat că putem folosi o gardă match pentru a soluționa problema umbririi pattern-urilor. Reamintim că am creat o variabilă nouă în cadrul pattern-ului din expresia match, în loc să utilizăm variabila din afara match-ului. Această variabilă nouă a făcut imposibilă testarea valorii variabilei externe. Listarea 18-27 ne arată cum se poate folosi o gardă match pentru a corecta această problemă.
Numele fișierului: src/main.rs
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(n) if n == y => println!("Matched, n = {n}"), _ => println!("Default case, x = {:?}", x), } println!("at the end: x = {:?}, y = {y}", x); }
Listarea 18-27: Utilizarea unei gărzi match pentru a verifica egalitatea cu o variabilă externă
Acum, codul va afișa Cazul implicit, x = Some(5). Pattern-ul în a doua ramură a match-ului nu introduce o nouă variabilă y, care ar umbri y-ul extern, ce ne permite să folosim y-ul extern în garda match. În loc de Some(y) formulăm Some(n). Aceasta inițializează o nouă variabilă n care nu creează umbrire, deoarece nu există o variabilă n în afara contextului match.
Garda match if n == y nu constituie un pattern, așadar nu introduce variabile noi. Acest y este chiar y-ul extern, nu un nou y umbrit, iar noi putem căuta o valoare care să fie egală cu y-ul extern simplu comparând n cu y.
De asemenea, putem utiliza operatorul sau | în garda match pentru a defini mai multe pattern-uri; condițiile gărzii match se vor aplica tuturor pattern-urilor. Listarea 18-28 demonstrează cum se aplică precedența atunci când combinăm un pattern ce folosește | cu o gardă match. Aspectul important din acest exemplu este că garda match if y este aplicabilă atât la 4, 5, cât și la 6, chiar dacă ar părea că if y este relevant doar pentru 6.
fn main() { let x = 4; let y = false; match x { 4 | 5 | 6 if y => println!("yes"), _ => println!("no"), } }
Listarea 18-28: Combinarea mai multor pattern-uri cu o gardă match
Condiția de match arată că ramura se potrivește doar dacă valoarea lui x este egală cu 4, 5, sau 6 și numai dacă y este true. Când codul este executat, pattern-ul din prima ramură corespunde deoarece x este 4, dar garda match if y este falsă, astfel prima ramură nu este selectată. Codul avansează la a doua ramură, care este potrivită, iar programul afișează no. Acest lucru se întâmplă pentru că condiția if se aplică întregului pattern 4 | 5 | 6, nu exclusiv ultimei valori 6. Astfel, precedența unei gărzi match față de un pattern este următoarea:
(4 | 5 | 6) if y => ...
nu:
4 | 5 | (6 if y) => ...
După execuția codului comportamentul precedenței devine evident: dacă garda match s-ar fi aplicat doar la ultima valoare din secvența valorilor specificate prin operatorul |, ramura s-ar fi potrivit și programul ar fi afișat yes.
Legătura cu @
Operatorul at @ ne permite să inițializăm o variabilă care păstrează o valoare în același timp când verificăm acea valoare pentru o potrivire de pattern. În Listarea 18-29, intenționăm să testăm dacă un câmp id din Message::Hello se încadrează în diapazonul 3..=7. Vrem și să legăm valoarea la variabila id_variable pentru a o putea folosi în codul asociat acestei ramuri a pattern-ului. Am putea să-i dăm acestei variabile numele id, ca și câmpul, dar pentru acest exemplu am ales un nume diferit.
fn main() { enum Message { Hello { id: i32 }, } let msg = Message::Hello { id: 5 }; match msg { Message::Hello { id: id_variable @ 3..=7, } => println!("Found an id in range: {}", id_variable), Message::Hello { id: 10..=12 } => { println!("Found an id in another range") } Message::Hello { id } => println!("Found some other id: {}", id), } }
Listarea 18-29: Utilizând @ pentru a lega o valoare de un pattern în timp ce de asemenea o verificăm
Acest exemplu va afișa Found an id in range: 5. Prin specificarea id_variable @ înainte de diapazonul 3..=7, capturăm orice valoare care se potrivește cu diapazonul, dar o verificăm și că se încadrează în pattern-ul diapazonului.
În cea de-a doua ramură, unde pattern-ul conține doar un diapazon, codul asociat cu ramura nu are la dispoziție o variabilă ce conține valoarea efectivă a câmpului id. Valoarea câmpului id ar fi putut fi 10, 11 sau 12, însă codul corespunzător nu cunoaște care anume este. Astfel, codul pattern-ului nu poate folosi valoarea din câmpul id, deoarece nu am stocat valoarea id într-o variabilă.
În ultima ramură, unde avem definită o variabilă fără diapazon, valoarea ne este disponibilă pentru utilizare în codul ramurii, stocată într-o variabilă numită id. Acest lucru se datorează utilizării sintaxei prescurtate a câmpurilor structurii. Totuși, nu am efectuat nicio verificare a valorii câmpului id în această ramură, spre deosebire de primele două: orice valoare se potrivește cu acest pattern.
Utilizarea @ ne oferă posibilitatea de a testa o valoare și de a o stoca într-o variabilă în cadrul aceluiași pattern.
Sumar
Pattern-urile din Rust sunt extrem de utile în distingerea între diferitele tipuri de date. Atunci când sunt aplicate în contextul expresiilor match, Rust asigură că pattern-urile acoperă fiecare valoare posibilă - în caz contrar, programul nu va fi compilat. Implementarea pattern-urilor în instrucțiunile let și în parametrii funcțiilor rezultă în construcții mai eficiente, facilitând astfel destructurarea valorilor în componente mai mici concomitent asignându-le variabilelor. Putem crea pattern-uri de la cele mai simple la cele mai complexe, conform necesităților specifice.
În capitolul care urmează, penultimul al acestei cărți, ne vom aprofunda cunoștințele despre unele dintre aspectele avansate ce caracterizează diversele funcționalități Rust.
Caracteristici avansate
Până la acest moment, ai învățat secțiunile cel mai des utilizate ale limbajului de programare Rust. Înainte de a începe un nou proiect în Capitolul 20, ne vom familiariza cu unele concepte ale limbajului pe care s-ar putea să le întâlnești ocazional, dar care nu sunt de uz cotidian. Acest capitol poate fi utilizat ca o referință atunci când întâmpini elemente necunoscute. Funcționalitățile descrise sunt deosebit de utile în situații specifice. Chiar dacă s-ar putea să nu le folosești frecvent, este esențial să ai cunoștințe despre întreaga paletă de capabilități pe care Rust le pune la dispoziție.
În acest capitol, ne concentrăm asupra:
- Unsafe Rust: cum poți opta pentru a nu beneficia de anumite garanții Rust și cum să preiei manual asigurarea acestor garanții
- Trăsături avansate: tipuri asociate, parametri definiți implicit de tip, sintaxă calificată complet, super-trăsături și utilizarea pattern-ului newtype în contextul trăsăturilor
- Tipuri avansate: mai multe detalii despre pattern-ul newtype, pseudonime pentru tipuri, tipul never și tipurile cu dimensiuni dinamice
- Funcții și închideri avansate: pointeri funcționali și cum să returnezi închideri
- Macrouri: strategii pentru a crea cod care generează mai mult cod în timpul compilării
Acest capitol oferă un arsenal complet de funcționalități Rust, garantând că există ceva interesant pentru tine! Să explorăm împreună aceste concepte!
Rust unsafe
Am discutat până acum despre codul Rust care vine cu garanții de securitate a memoriei impuse în timpul compilării. Cu toate acestea, există în Rust și o altă lume ascunsă, cunoscută sub numele de Rust unsafe (Rust nesigur), aceasta funcționează similar cu varianta obișnuită, dar cu avantajul unor capabilități suplimentare.
Motivul pentru care există Rust unsafe este că analiza statică, prin natura sa, tinde să fie conservatoare. Când compilatorul încearcă să verifice conformitatea codului cu anumite garanții, e preferabil să respingă programe valide decât să accepte programe invalide. În cazuri în care codul ar putea fi sigur, dar Rust nu poate fi sigur din cauza lipsei de informații, codul va fi respins. În astfel de situații, putem folosi codul unsafe pentru a-i spune compilatorului, „Crede-mă, cunosc consecințele acțiunilor mele”. Cu toate acestea, să fii conștient că utilizarea lui Rust unsafe vine cu propriile riscuri: dacă este folosit greșit, pot apărea probleme legate de siguranța memoriei, precum dereferențierea pointerilor null.
În plus, Rust are un aspect unsafe pentru că hardware-ul calculatorului în sine nu este sigur prin natura sa. Fără posibilitatea de a efectua operații unsafe, anumite programe nu ar putea fi realizate. Rust trebuie să permită programarea la nivel de sistem, ca de exemplu interacțiunea directă cu sistemul de operare sau crearea unui sistem de operare de la zero. Aceste posibilități de programare la nivel scăzut reprezintă unul dintre scopurile principale ale limbajului Rust. Să examinăm ce putem face cu Rust unsafe și cum anume o facem.
Superputeri unsafe
Pentru a activa modul unsafe Rust, folosește cuvântul cheie unsafe și începe un nou bloc care include codul unsafe. În Rust unsafe ai posibilitatea de a efectua cinci acțiuni care nu sunt permise în Rust obișnuit, acțiuni pe care le denumim superputeri unsafe. Aceste superputeri sunt:
- Dereferențierea unui pointer raw
- Apelarea unei funcții sau metode unsafe
- Accesarea sau modificarea unei variabile statice mutabile
- Implementarea unei trăsături unsafe
- Accesarea câmpurilor unui
union
Este esențial să înțelegi că utilizarea unsafe nu dezactivează verificatorul de împrumut sau vreo altă verificare de siguranță implementată de Rust: dacă folosești o referință în cadrul codului unsafe, aceasta oricum va fi supusă verificărilor. Cuvântul cheie unsafe îți permite doar să accesezi aceste cinci caracteristici care nu sunt verificate de către compilator în ceea ce privește siguranța memoriei, dar totuși vei păstra un anumit nivel de siguranță în interiorul blocurilor unsafe.
Mai mult, unsafe nu înseamnă că, în mod necesar, codul din blocul respectiv este periculos sau că va genera probleme de siguranță a memoriei; intenția este că, în calitate de programator, deja tu te vei asigura că codul din blocul unsafe va accesa memoria într-un mod corect.
Fiindcă omul este supus erorilor și greșelile sunt inevitabile, insistența ca aceste cinci operațiuni unsafe să fie plasate în interiorul blocurilor marcate cu unsafe te ajută să conștientizezi că eventualele erori legate de siguranța memoriei le vei găsi anume în cadrul unui bloc unsafe. Încearcă să menții blocurile unsafe cât mai compacte; îți vei mulțumi ție însuți mai târziu, când vei fi nevoit să investighezi probleme legate de memorie.
Pentru a limita cât mai mult codul unsafe, este indicat să încapsulezi acest tip de cod în cadrul unei abstracțiuni sigure și să oferi o interfață API care să fie de asemenea sigură, aspecte pe care le vom discuta mai târziu în acest capitol când voi aborda funcțiile și metodele unsafe. Unele părți din biblioteca standard sunt implementate ca abstracțiuni sigure peste codul unsafe care a fost verificat. Împachetarea codului unsafe într-o abstracție sigură împiedică propagarea utilizării unsafe la toți cei care doresc să folosească funcționalitatea realizată cu ajutorul codului unsafe, deoarece folosirea unei abstracțiuni sigure este, prin definiție, sigură.
Să examinăm pe rând fiecare dintre cele cinci superputeri unsafe. Voi analiza și unele abstracțiuni care oferă o interfață sigură la codul unsafe.
Dereferențierea Unui Pointer Brut
În Capitolul 4, la secțiunea [“Referințe suspendate”][dangling-references], am evidențiat că compilatorul asigură întotdeauna că referințele sunt valide. Unsafe Rust introduce două tipuri noi denumite pointeri bruți care sunt asemănători cu referințele. La fel ca referințele, pointerii bruți pot fi imutabili sau mutabili și sunt reprezentați ca *const T respectiv *mut T. Asteriscul nu este operatorul de dereferențiere; este parte integrantă a denumirii tipului. În contextul pointerilor bruți, imutabil semnifică faptul că pointerul nu poate fi atribuit direct după ce a fost dereferențiat.
Diferența față de referințe și pointerii inteligenți, pointerii bruți:
- Au permisiunea de a ignora regulile de împrumut prin existența simultană a pointerilor imutabili și mutabili, sau a multiplelor pointere mutabile către aceeași adresă de memorie
- Nu este garantat că indică spre memorie valida
- Pot fi null
- Nu beneficiază de curățare automată
Renunțând la aceste siguranțe asigurate de Rust, puteți opta pentru performanță mai bună sau capacitatea de a interacționa cu alt limbaj sau hardware unde garanțiile Rust nu se aplică.
Listarea 19-1 demonstrează cum se pot crea un pointer brut imutabil și unul mutabil din referințe.
fn main() { let mut num = 5; let r1 = &num as *const i32; let r2 = &mut num as *mut i32; }
Listarea 19-1: Crearea pointerilor bruți din referințe
Remarcați faptul că nu am folosit cuvântul cheie unsafe în acest cod. Este posibil să creăm pointeri bruți în codul sigur; nu putem însă dereferenția pointeri bruți decât într-un bloc unsafe, aspect pe care îl veți observa în continuare.
Am generat pointeri bruți utilizând as pentru a converti o referință imutabilă și una mutabilă în tipurile lor corespunzătoare de pointeri bruți. Fiind creați direct din referințe care sunt garantate a fi valide, știm că acești pointeri bruți particulari sunt valizi, însă nu putem extinde această premisă asupra oricărui pointer brut.
Pentru a ilustra acest lucru, vom crea un pointer brut al cărui validitate nu poate fi garantată. Listarea 19-2 arată cum să creezi un pointer brut spre o locație arbitrară de memorie. Tentativa de utilizare a memoriei arbitrară este nedefinită: ar putea exista date la acea adresă sau nu, compilatorul ar putea optimiza codul astfel încât să nu existe acces la memorie, sau programul ar putea se încheie cu o eroare de tip segmentation fault. De obicei, nu există motive întemeiate pentru a scrie cod în acest mod, dar este posibil.
fn main() { let address = 0x012345usize; let r = address as *const i32; }
Listarea 19-2: Crearea unui pointer brut către o adresă de memorie arbitrară
Să ne reamintim că putem crea pointeri bruți în codurile sigure, dar nu îi putem dereferenția pentru a citi datele la care acesta indică. În Listarea 19-3, utilizăm operatorul de dereferențiere * pe un pointer brut, acțiune care necesită un bloc unsafe.
fn main() { let mut num = 5; let r1 = &num as *const i32; let r2 = &mut num as *mut i32; unsafe { println!("r1 is: {}", *r1); println!("r2 is: {}", *r2); } }
Listarea 19-3: Dereferențierea pointerilor bruți într-un bloc unsafe
Simpla creare a unui pointer nu produce daune; pericolele apar atunci când încercăm să accesăm valoarea indicată de acesta, situație în care ne-am putea confrunta cu o valoare invalidă.
De asemenea, notăm că în Listarea 19-1 și 19-3 am creat pointeri bruți *const i32 și *mut i32, ambii indicând aceeași locație de memorie unde este stocat num. Dacă am încerca în schimb să creăm o referință imutabilă și una mutabilă la num, codul nu ar compila, deoarece regulile de posesiune din Rust nu permit existența unei referințe mutabile în același timp cu referințe imutabile. Cu pointerii bruți, avem posibilitatea de a crea un pointer mutabil și unul imutabil spre aceeași locație și de a modifica datele prin intermediul pointerului mutabil, putând astfel crea o posibilă cursă a datelor. Fii prudent!
Cu toate aceste riscuri, de ce am folosi vreodată pointerii bruți? Un caz de folosire principal este atunci când lucrăm cu cod C, cum vom vedea în secțiunea următoare, „Apelarea unei funcții sau metode unsafe.” Un alt motiv este crearea de abstracțiuni sigure ce nu sunt înțelese de verificatorul de împrumut. Vom aborda funcții nesigure și apoi vom analiza un exemplu de abstracție sigură bazată pe cod nesigur.
Apelarea unei funcții sau metode unsafe
Cel de-al doilea tip de operațiune ce poate fi efectuată într-un bloc unsafe este invocarea funcțiilor unsafe. Aspectul funcțiilor și metodelor unsafe este identic cu al funcțiilor și metodelor regulare, doar că includ cuvântul cheie unsafe înainte de definiția propriu-zisă. Prezența unsafe semnalează că funcția impune anumite obligații de respectat atunci când o invocăm, deoarece Rust nu poate asigura că am îndeplinit aceste condiții. Invocând o funcție unsafe într-un bloc unsafe, transmitem că am citit documentația acesteia și ne asumăm responsabilitatea de a onora obligațiile impuse de funcție.
Iată cum arată o funcție unsafe denumită dangerous, care nu execută nicio operațiune în corpul ei:
fn main() { unsafe fn dangerous() {} unsafe { dangerous(); } }
Trebuie să invocăm funcția dangerous în interiorul unui bloc unsafe separat. Încercarea de a invoca dangerous fără utilizarea unui bloc unsafe va rezulta într-o eroare:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function is unsafe and requires unsafe function or block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` due to previous error
Prin folosirea blocului unsafe, declarăm că am consultat documentația funcției, că înțelegem modul corect de utilizare și că am verificat îndeplinirea obligațiilor impuse de funcție.
Corpurile funcțiilor unsafe sunt echivalentul unui bloc unsafe, așadar, pentru a executa alte acțiuni unsafe în cadrul unei astfel de funcții, nu este nevoie să includem un alt bloc unsafe.
Crearea unei abstracții sigure peste cod nesigur
Prezența codului nesigur într-o funcție nu impune ca întreaga funcție să fie marcată drept nesigură. De fapt, este o practică obișnuită să încapsulăm codul nesigur într-o funcție sigură. Ca exemplu, să analizăm funcția split_at_mut din biblioteca standard, care implică utilizarea unui cod nesigur. Vom explora cum am putea să implementăm aceasta. Această metodă sigură este definită pentru secțiuni mutabile și presupune divizarea unei secțiuni în două la indexul specificat ca argument. Listarea 19-4 ne ilustrează modul în care utilizăm funcția sigură split_at_mut.
fn main() { let mut v = vec![1, 2, 3, 4, 5, 6]; let r = &mut v[..]; let (a, b) = r.split_at_mut(3); assert_eq!(a, &mut [1, 2, 3]); assert_eq!(b, &mut [4, 5, 6]); }
Listarea 19-4: Utilizarea funcției sigure split_at_mut
Implementarea acestei funcții exclusiv prin intermediul Rust-ului sigur nu este posibilă. O încercare de implementare ar putea arăta așa cum este în Listarea 19-5, care însă nu va compila. Pentru simplificare, vom implementa split_at_mut ca și funcție și nu ca metodă, și doar pentru secțiuni de valori i32 în loc de un tip generic T.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}Listarea 19-5: O tentativă eșuată de implementare a split_at_mut folosind doar Rust sigur
Funcția calculează inițial lungimea totală a secțiunii. Apoi confirmă că indexul oferit ca parametru este în interiorul limitelor secțiunii, verificând dacă acesta este mai mic sau egal cu lungimea. Această verificare va determina ca, în cazul în care transmitem un index care este mai mare decât lungimea la care dorim să divizăm secțiunea, funcția va genera panică înainte de a încerca să utilizeze acel index.
Apoi funcția returnează două secțiuni mutabile ca elemente ale unei tuple: prima de la începutul secțiunii originale până la indexul mid și cel de-al doilea de la mid până la sfârșitul secțiunii.
Încercând să compilăm codul prezentat în Listarea 19-5, vom întâmpina o eroare.
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` due to previous error
Verificatorul de împrumut din Rust nu poate înțelege că împrumutăm părți diferite ale secțiunii; el recunoaște doar că se face împrumutul din aceeași secțiune de două ori. De fapt, împrumutarea diferitelor segmente ale unei secțiuni este acceptabilă din moment ce cele două secțiuni nu se suprapun, însă Rust nu este destul de evoluat pentru a detecta acest lucru. În momentul în care știm că un cod este corect, dar Rust nu, este vremea să apelăm la utilizarea codului unsafe.
Listarea 19-6 prezintă modul în care putem folosi un bloc unsafe, un pointer brut și câteva apeluri la funcții nesigure pentru a implementa funcția split_at_mut.
use std::slice; fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = values.len(); let ptr = values.as_mut_ptr(); assert!(mid <= len); unsafe { ( slice::from_raw_parts_mut(ptr, mid), slice::from_raw_parts_mut(ptr.add(mid), len - mid), ) } } fn main() { let mut vector = vec![1, 2, 3, 4, 5, 6]; let (left, right) = split_at_mut(&mut vector, 3); }
Listarea 19-6: Utilizarea codului nesigur în cadrul implementării funcției split_at_mut
Reamintim din Capitolul 4 [„Tipul secțiune”][the-slice-type] că secțiunile reprezintă un pointer către anumite date și lungimea respectivei secțiuni. Apelăm metoda len pentru a afla lungimea unei secțiuni și metoda as_mut_ptr pentru a accesa pointerul brut al secțiunii. În cazul nostru, având o secțiune mutabilă de valori i32, as_mut_ptr ne asigură un pointer brut cu tipul *mut i32, pe care l-am salvat în variabila ptr.
Păstrăm afirmația că indexul mid se găsește în interiorul secțiunii. Apoi trecem la codul nesigur: funcția slice::from_raw_parts_mut primește un pointer brut și o lungime pentru a genera o nouă secțiune. Această funcție este folosită pentru a crea o secțiune începând de la ptr și care se întinde pe mid elemente. Ulterior invocăm metoda add pe ptr cu argumentul mid pentru a câștiga un pointer brut ce debutează de la mid, realizând o nouă secțiune utilizând acel pointer și numărul de elemente rămase după mid drept lungime.
Funcția slice::from_raw_parts_mut este considerată nesigură deoarece presupune utilizarea unui pointer brut și necesită încrederea că acest pointer este valid. De asemenea, metoda add aplicată pointerilor bruți este nesigură, având în vedere că presupune ca și locația de decalare să fie un pointer valid. Așadar, am înconjurat folosirea slice::from_raw_parts_mut și add cu un bloc unsafe, ceea ce ne permite apelarea lor. Analizând codul și asigurându-ne prin cerința că mid este mai mic sau egal cu len, putem concluziona că toți pointerii bruți folosiți în blocul unsafe sunt pointeri valizi către date din secțiune. Aceasta constituie o aplicare corespunzătoare a conceptului unsafe.
Este important de notat că funcția split_at_mut rezultată nu necesită marcarea ca unsafe, iar apelarea acesteia se poate face din Rust sigur. Prin urmare, am elaborat o abstractizare sigură pentru codul unsafe prin implementarea funcției ce utilizează cod nesigur într-o manieră sigură, formând astfel doar pointeri validați din datele disponibile funcției.
În contrast, folosirea funcției slice::from_raw_parts_mut prezentată în Listarea 19-7 ar putea duce la prăbușirea aplicației atunci când secțiunea este accesată. Codul specificat generează o secțiune de 10.000 de elemente începând de la o locație arbitrar aleasă în memorie.
fn main() { use std::slice; let address = 0x01234usize; let r = address as *mut i32; let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) }; }
Listarea 19-7: Generarea unei secțiuni de la o locație arbitrară în memorie
Nu deținem control asupra memoriei din această locație aleatoare, și nu există niciun fel de garanție că secțiunea generată conține valori i32 valide. Încercarea de a utiliza values de parcă ar fi o secțiune adevărată duce la comportament nedefinit.
Folosirea funcțiilor extern pentru apelarea codului extern
Câteodată, codul Rust pe care îl scriem ar putea avea nevoie să interacționeze cu cod scris într-un alt limbaj. În acest scop, Rust oferă cuvântul cheie extern, care facilitează crearea și utilizarea unei Interfețe Funcționale Externe (Foreign Function Interface, FFI). Un FFI constituie o modalitate prin care un limbaj de programare poate defini funcții, permițând ca un alt limbaj de programare (străin) să cheme acele funcții.
Listarea 19-8 ilustrează cum se realizează o integrare cu funcția abs din biblioteca standard a limbajului C. Funcțiile declarate în interiorul blocurilor extern sunt întotdeauna considerate nesigure când sunt chemate din codul Rust. Acest lucru se datorează faptului că alte limbaje nu impun regulile și garanțiile specifice lui Rust și, deoarece Rust nu le poate verifica, responsabilitatea asigurării siguranței revine programatorului.
Numele fișierului: src/main.rs
extern "C" { fn abs(input: i32) -> i32; } fn main() { unsafe { println!("Absolute value of -3 according to C: {}", abs(-3)); } }
Listarea 19-8: Declararea și apelarea unei funcții extern definită într-un alt limbaj
În cadrul blocului extern "C", enumerăm numele și semnăturile funcțiilor externe din alt limbaj pe care dorim să le folosim. Secțiunea "C" specifică ce interfață binară a aplicației (application binary interface, ABI) este folosită de funcția respectivă: ABI definește cum se realizează apelul funcției la nivelul limbajului de asamblare. ABI-ul de tip "C" este cel mai frecvent utilizat și este în concordanță cu ABI-ul limbajului de programare C.
Invocarea funcțiilor Rust din alte limbaje
Putem de asemenea să utilizăm
externpentru a crea o interfață care permite altor limbaje să invoce funcții Rust. În loc să generăm un blocexterncomplet, adăugăm cuvântul cheieexternși specificăm ABI-ul de utilizat exact înaintea cuvântului cheiefnpentru funcția în cauză. Trebuie să includem și adnotarea#[no_mangle]pentru a împiedica compilatorul Rust să modifice numele acestei funcții. Mangling înseamnă modificarea de către un compilator a numelui dat de noi unei funcții într-un nume diferit care include mai multe informații pentru diversele părți ale procesului de compilare, dar care este mai puțin lizibil pentru oameni. Deoarece fiecare compilator al unui limbaj de programare mâzgălește numele într-o manieră ușor diferită, pentru ca o funcție Rust să fie identificabilă de alte limbaje, trebuie să dezactivăm această mâzgăleală a numelui efectuată de compilatorul Rust.În exemplul de mai jos, facem funcția
call_from_caccesibilă din cod C, după ce aceasta a fost compilată într-o bibliotecă dinamică și link-uită din C:#![allow(unused)] fn main() { #[no_mangle] pub extern "C" fn call_from_c() { println!("Just called a Rust function from C!"); } }Utilizarea
externîn acest context nu implică utilizareaunsafe.
Accesarea sau modificarea unei variabile statice mutabile
Nu am discutat încă despre variabile globale în această carte, care sunt suportate de Rust, dar pot contraveni regulilor de posesiune Rust atunci când sunt modificate. Acest lucru poate duce la curse de date dacă două fire de execuție accesează simultan aceeași variabilă globală mutabilă.
În Rust, variabilele globale se numesc variabile statice. Listarea 19-9 ilustrează cum să declari și să utilizezi o variabilă statică cu o valoare de tip secțiune de string.
Numele fișierului: src/main.rs
#![allow(unused)] fn main() { ... }
Listarea 19-9: Definirea și utilizarea unei variabile statice imutabile
Variabilele statice sunt similare constantelor, discutate în secțiunea [“Diferențele între variabile și constante”][differences-between-variables-and-constants] din Capitolul 3. Numele variabilelor statice sunt, prin convenție, în SCREAMING_SNAKE_CASE. Variabilele statice pot deține doar referințe cu durata de viață 'static, ceea ce înseamnă că compilatorul Rust poate rezolva durata de viață fără să fie nevoie de adnotarea explicită a acesteia. Accesul la o variabilă statică imutabilă este sigur.
O diferență subtilă între constante și variabilele statice imutabile este că valorile unei variabile statice sunt alocate la o adresă fixă în memorie. Fiecare utilizare a valorii va accesa mereu datele din aceeași locație. Pe de altă parte, constantele pot duplica valorile ori de câte ori sunt utilizate. Variabilele statice pot fi, de asemenea, mutabile, dar accesarea și modificarea lor este considerată nesigură. Listarea 19-10 arată cum să declari, să accesezi și să modifici o variabilă statică mutabilă numită COUNTER.
Numele fișierului: src/main.rs
static mut COUNTER: u32 = 0; fn add_to_count(inc: u32) { unsafe { COUNTER += inc; } } fn main() { add_to_count(3); unsafe { println!("COUNTER: {}", COUNTER); } }
Listarea 19-10: Citirea sau scrierea într-o variabilă statică mutabilă este nesigură
Similar cu variabilele obișnuite, folosim cuvântul cheie mut pentru a indica mutabilitatea. Orice cod care interacționează cu COUNTER trebuie să fie înconjurat de un bloc unsafe. Acest cod se compilează și va afișa COUNTER: 3 cum ne-am aștepta, întrucât rulează pe un singur fir de execuție. Folosirea COUNTER în scenarii cu mai multe fire de execuție ar putea cauza cu ușurință curse de date.
Este dificil să garantăm evitarea curselor de date când lucrăm cu date mutable accesibile global, ceea ce face Rust să considere variabilele statice mutabile ca fiind nesigure. Acolo unde e posibil, este de dorit să utilizăm tehnicile de concurență și pointerii inteligenți thread-safe descrise în Capitolul 16, astfel încât compilatorul să confirme că accesul la date din diferite fire de execuție este realizat în condiții de siguranță.
Implementarea unei trăsături nesigure
Este posibil să utilizăm unsafe pentru a implementa o trăsătură nesigură. O trăsătură este considerată nesigură când are cel puțin una dintre metodele sale cu anumite invariante ce nu pot fi verificate de către compilator. O trăsătură se declară unsafe adăugând cuvântul cheie unsafe înainte de trait și marcând totodată implementarea trăsăturii ca unsafe, așa cum se arată în Listarea 19-11.
unsafe trait Foo { // methods go here } unsafe impl Foo for i32 { // method implementations go here } fn main() {}
Listarea 19-11: Definirea și implementarea unei trăsături nesigure
Prin utilizarea unsafe impl, ne asumăm responsabilitatea de a respecta invariantele pe care compilatorul nu le poate confirma.
De exemplu, să ne aducem aminte de trăsăturile de marcaj Sync și Send discutate în secțiunea [“Concurență extensibilă cu trăsăturile Sync și Send”][extensible-concurrency-with-the-sync-and-send-traits] din Capitolul 16: compilatorul implementează automat aceste trăsături dacă tipurile noastre sunt alcătuite exclusiv din tipuri Send și Sync. În cazul în care creăm un tip ce include un tip care nu este Send sau Sync, cum ar fi pointerii bruți, și dorim să considerăm acel tip ca fiind Send sau Sync, trebuie să recurgem la unsafe. Rust nu poate asigura că tipul nostru respectă garanțiile de a fi transmis în siguranță între fire de execuție sau de a fi accesat concomitent de mai multe fire de execuție; prin urmare, este necesar să verificăm manual aceste garanții și să indicăm aceasta prin utilizarea unsafe.
Accesarea câmpurilor unei uniuni
Ultima operațiune care necesită folosirea unsafe este accesarea câmpurilor unei uniuni. Un union este similar cu un struct, dar doar un singur câmp declarat este utilizat într-o anumită instanță, la un moment dat. Uniunile sunt folosite în principal pentru interoperarea cu uniunile din codul C. Accesul la câmpurile unei uniuni este nesigur pentru că Rust nu poate asigura tipul datelor care sunt stocate curent în instanța uniunii. Poți învăța mai multe despre uniuni în [Referința Rust][reference].
Când utilizăm cod nesigur
Utilizarea unsafe pentru a lua una dintre cele cinci acțiuni (superputeri) menționate mai sus nu este greșită sau văzută cu reticență. Totuși, este mai dificil să scrii cod unsafe corect, deoarece compilatorul nu poate contribui la asigurarea securității memoriei. Dacă ai un motiv întemeiat să folosești cod unsafe, ai posibilitatea de a face asta, iar utilizarea explicită a adnotării unsafe ușurează identificarea sursei problemelor atunci când acestea apar.
[dangling-references]: ch04-02-references-and-borrowing.html#dangling-references [differences-between-variables-and-constants]: ch03-01-variables-and-mutability.html#constants [extensible-concurrency-with-the-sync-and-send-traits]: ch16-04-extensible-concurrency-sync-and-send.html#extensible-concurrency-with-the-sync-and-send-traits [the-slice-type]: ch04-03-slices.html#the-slice-type [reference]: ../reference/items/unions.html
Trăsături avansate
Am abordat inițial trăsăturile în secțiunea [„Trăsături: Definirea comportamentului partajat”][traits-defining-shared-behavior] din Capitolul 10, fără să intrăm în complexitățile mai avansate ale acestora. Având acum o înțelegere mai profundă despre Rust, putem explora aceste detalii mai sofisticate.
Specificarea tipurilor placeholder în definițiile de trăsături prin utilizarea tipurilor asociate
Tipurile asociate sunt folosite pentru a lega un placeholder de tip de o anume trăsătură, permițând astfel definițiilor de metode ale trăsăturii să utilizeze aceste tipuri placeholder în semnăturile lor. Cine implementează o trăsătură va specifica tipul concret care urmează să fie utilizat în locul tipului placeholder pentru implementarea specifică. În acest fel, putem defini o trăsătură care folosește anumite tipuri fără a fi nevoie să cunoaștem exact care sunt aceste tipuri până când trăsătura este implementată.
Deși majoritatea caracteristicilor avansate prezentate în acest capitol sunt necesare doar ocazional, tipurile asociate sunt cam de mojloc: se folosesc mai rar decât funcționalitățile explicate în restul cărții, dar totuși mai frecvent decât alte caracteristici discutate aici.
Un exemplu de trăsătură ce folosește un tip asociat este trăsătura Iterator oferită de biblioteca standard a limbajului Rust. Acest tip asociat este denumit Item și înlocuiește tipul valorilor pe care structura ce implementează trăsătura Iterator intenționează să le parcurgă. Definiția trăsăturii Iterator este ilustrată în Listarea 19-12.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Listarea 19-12: Definiția trăsăturii Iterator cu un tip asociat Item
Tipul Item funcționează ca un înlocuitor, iar metoda next este definită astfel încât să returneze valori de tip Option<Self::Item>. Implementatorii trăsăturii Iterator vor alege un tip specific pentru Item, iar next va returna un Option care contine o valoare de acest tip specific.
Deși tipurile asociate pot pare să fie similare cu genericii, care ne permit să definim o funcție fără a indica tipurile cu care poate lucra, există diferențe importante. Analizăm diferențele prin exemplificarea unei implementări a trăsăturii Iterator pe tipul Counter, care indică faptul că tipul Item este u32:
Numele fișierului: src/lib.rs
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}Această formă de exprimare pare similară cu cea utilizată pentru generici. Astfel, de ce nu definim pur și simplu trăsătura Iterator utilizând generici, cum este ilustrat în Listarea 19-13?
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}Listarea 19-13: O variantă ipotetică a trăsăturii Iterator folosind generici
Folosirea genericiilor, ca în Listarea 19-13, ne obligă să adnotăm tipurile în fiecare implementare, pentru că putem, de exemplu, să implementăm Iterator<String> pentru Counter sau pentru alte tipuri. Acest lucru înseamnă că Iterator poate avea mai multe implementări pentru Counter, cu tipuri concrete diferite ale parametrilor generici la fiecare implementare. Atunci când folosim metoda next pentru Counter, este necesar să furnizăm adnotări de tip pentru a specifica ce implementare a Iterator dorim să utilizăm.
Când lucrăm cu tipuri asociate, nu este necesar să adnotăm tipuri, deoarece o trăsătură nu poate fi implementată de mai multe ori pentru un același tip. În listarea 19-12, unde se folosește definiția cu tipuri asociate, putem alege o singură dată care va fi tipul pentru Item, deoarece există doar una singură impl Iterator for Counter. Nu trebuie să indicăm că dorim un iterator ce produce valori u32 de câte ori apelăm next pentru Counter.
Tipurile asociate reprezintă de asemenea o componentă centrală a contractului trăsăturii: implementatorii trăsăturii trebuie să furnizeze un tip care să servească drept înlocuitor pentru tipul asociat. Numele tipurilor asociate sunt de obicei alese pentru a reflecta modul în care vor fi folosite și este o practică bună să includem documentarea acestora în documentația API.
Parametrii generici de tip implicit şi supraîncărcarea operatorilor
Atunci când folosim parametri generici de tip, putem specifica un tip concret implicit pentru tipul generic. Aceasta elimină necesitatea ca cei care implementează trăsătura să aleagă un tip concret dacă tipul implicit este corespunzător. Un tip implicit este specificat în momentul declarării unui tip generic cu sintaxa <PlaceholderType=ConcreteType>.
Un exemplu foarte bun unde această tehnică este benefică este cu supraîncărcarea operatorilor, unde poți personaliza comportamentul unui operator (precum +) în scenarii specifice.
Rust nu permite crearea unor operatori noi sau supraîncărcarea unor operatori arbitrari. Însă, poți supraîncărca operațiile și trăsăturile aferente listate în std::ops implementând trăsăturile asociate acelui operator. De exemplu, în Listarea 19-14 supraîncărcăm operatorul + pentru a aduna două instanțe ale clasei Point. Aceasta se realizează prin implementarea trăsăturii Add pentru struct-ul Point:
Numele fișierului: src/main.rs
use std::ops::Add; #[derive(Debug, Copy, Clone, PartialEq)] struct Point { x: i32, y: i32, } impl Add for Point { type Output = Point; fn add(self, other: Point) -> Point { Point { x: self.x + other.x, y: self.y + other.y, } } } fn main() { assert_eq!( Point { x: 1, y: 0 } + Point { x: 2, y: 3 }, Point { x: 3, y: 3 } ); }
Listarea 19-14: Implementarea trăsăturii Add pentru a realiza supraîncărcarea operatorului + pentru instanțele clasei Point
Metoda add adună valorile x și y din două instanțe de Point pentru a crea o nouă instanță Point. Trăsătura Add include un tip asociat denumit Output care determină tipul returnat de metoda add.
Tipul generic implicit din acest cod este definit în interiorul trăsăturii Add. Iată definiția acesteia:
#![allow(unused)] fn main() { trait Add<Rhs=Self> { type Output; fn add(self, rhs: Rhs) -> Self::Output; } }
Acest cod ar trebui să ne fie relativ familiar: o trăsătură cu o metodă unică și un tip asociat. Noutatea este Rhs=Self: această sintaxă este cunoscută sub numele de parametri de tip implicit. Parametrul de tip generic Rhs (abreviere pentru "right hand side", sau "partea dreaptă") definește tipul parametrului rhs în metoda add. Dacă nu specificăm un tip concret pentru Rhs când implementăm trăsătura Add, tipul lui Rhs va fi implicit Self, care este tipul la care aplicăm implementarea trăsăturii Add.
Când am realizat implementarea lui Add pentru Point, am optat pentru tipul implicit Rhs pentru că vroiam să adunăm două instanțe Point. Să examinăm un caz în care implementăm trăsătura Add personalizând tipul Rhs în loc să utilizăm tipul implicit.
Avem două structuri, Millimeters și Meters, care reprezintă valori în unități de măsură diferite. Această metodă de încapsulare a unui tip existent într-o altă structură este cunoscută drept newtype pattern, concept pe care îl explicăm mai amănunțit în secțiunea [“Utilizarea pattern-ului newtype pentru implementarea trăsăturilor externe pe tipuri externe”][newtype] . Intenționăm să adunăm valori măsurate în milimetri cu cele în metri, iar implementarea Add trebuie să efectueze conversia corect. Avem posibilitatea de a implementa Add pentru Millimeters cu Meters ca tip Rhs, după cum este prezentat în Listarea 19-15.
Numele fișierului: src/lib.rs
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}Listarea 19-15: Implementarea trăsăturii Add pentru Millimeters astfel încât să putem adăuga Millimeters la Meters
Pentru a aduna Millimeters cu Meters, specificăm impl Add<Meters> pentru a defini valoarea pentru parametrul de tip Rhs, în loc să folosim valoarea implicită Self.
Vei utiliza parametri de tip implicit în două situații:
- Pentru a extinde un tip fără a afecta codul existent
- Pentru a permite personalizări în anumite cazuri pe care majoritatea utilizatorilor nu le vor necesita
Trăsătura Add din biblioteca standard ilustrează acest al doilea scop: de cele mai multe ori, dorim adunarea a două tipuri identice, însă trăsătura Add oferă flexibilitatea de a merge dincolo de acest caz standard. Utilizarea unui parametru de tip implicit în definiția trăsăturii Add înseamnă că, de obicei, nu este necesar să specificăm acest parametru suplimentar. Prin urmare, nu este nevoie de scrierea unor porțiuni de cod standard pentru implementare, facilitând folosirea trăsăturii.
Primul scop este asemănător cu cel de-al doilea, dar aplicat în sens invers: dacă dorim să adăugăm un parametru de tip unei trăsături existente, acordându-i o valoare implicită va permite extinderea funcționalității acelei trăsături fără a compromite codul implementat anterior.
Dezambiguizarea metodelor cu același nume prin sintaxa complet calificată
În Rust, nu există nicio restricție care să prevină o trăsătură să aibă o metodă cu același nume ca și o metoda din altă trăsătură, nici nu se interzice implementarea ambelor trăsături pe un singur tip. Este posibil, de asemenea, să implementăm direct pe tip o metodă cu același nume ca metodele din alte trăsături.
Când dorim să apelăm metode ce poartă același nume, trebuie să informăm Rust despre care dintre acestea intenționăm să o folosim. Considerăm codul prezentat în Listarea 19-16, unde am definit două trăsături, Pilot și Wizard, fiecare având o metodă denumită fly. Implementăm ambele trăsături pe tipul Human, care are deja implementată propria sa metodă fly. Fiecare metoda fly realizează o acțiune diferită.
Filename: src/main.rs
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() {}
Listarea 19-16: Definirea a două trăsături cu o metodă fly și implementarea lor pe tipul Human, plus o metodă fly implementată direct pe Human
Atunci când apelăm metoda fly pe o instanță de Human, compilatorul alege în mod standard metoda implementată direct pe tip, după cum arată Listarea 19-17.
Filename: src/main.rs
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() { let person = Human; person.fly(); }
Listarea 19-17: Apelarea metodei fly pe o instanță de Human
Execuția acestui cod va produce afișajul *waving arms furiously*, ceea ce indică faptul că Rust a apelat metoda fly implementată direct pe Human.
Dacă vrem să apelăm metodele fly din trăsăturile Pilot sau Wizard, trebuie să utilizăm o sintaxă diferită pentru a specifica exact metoda fly dorită. Listarea 19-18 ilustrează utilizarea acestei sintaxe.
Filename: src/main.rs
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() { let person = Human; Pilot::fly(&person); Wizard::fly(&person); person.fly(); }
Listarea 19-18: Specificarea trăsăturii din care dorim să apelăm metoda fly
Indicând numele trăsăturii înaintea numelui metodei, facem clar pentru Rust care implementare a fly dorim să o apelăm. Am putea de asemenea folosi Human::fly(&person), care are aceeași semnificație cu person.fly() utilizat în Listarea 19-18, dar aceasta sintaxă este puțin mai lungă și nu este necesară dacă nu e nevoie de dezambiguizare.
Executarea acestui cod generează următorul afișaj:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
Deoarece metoda fly folosește un parametru self, dacă am avea două tipuri care implementează o trăsătură, Rust ar putea determina ce implementare a unei trăsături să aleagă pe baza tipului parametrului self.
Însă, funcțiile asociate care nu sunt metode nu au un parametru self. Când avem mai multe tipuri sau trăsături care definesc funcții asociate non-metode cu același nume, Rust nu poate determina întotdeauna tipul pe care îl vizăm fără utilizarea sintaxei complet calificate. De exemplu, în Listarea 19-19 cream o trăsătură pentru un adăpost de animale care vrea să numească toți cățelușii Spot. Introducem trăsătura Animal cu o funcție asociată non-metodă baby_name. Structura Dog, care de asemenea implementează trăsătura Animal, definește propria funcție asociată non-metodă baby_name.
Filename: src/main.rs
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", Dog::baby_name()); }
Listarea 19-19: O trăsătură cu o funcție asociată și un tip cu o funcție asociată cu același nume care mai și implementează trăsătura
Implementăm codul pentru numirea tuturor cățelușilor în funcția baby_name asociată structurii Dog. Tipul Dog implementează, de asemenea, trăsătura Animal, care descrie caracteristici comune tuturor animalelor. Termenul pentru cățel este puppy, și acest lucru este exprimat în implementarea trăsăturii Animal pentru Dog în funcția baby_name ce aparține trăsăturii Animal.
În funcția main, invocăm funcția Dog::baby_name, care apelează funcția asociată definită direct în cadrul Dog. Acest cod produce următorul afișaj:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
Rezultatul nu corespunde așteptărilor noastre. Dorim să apelăm funcția baby_name care face parte din trăsătura Animal pe care am implementat-o pentru Dog, pentru ca astfel codul să afișeze A baby dog is called a puppy. Metoda de specificare a numelui trăsăturii utilizată în Listarea 19-18 nu ajută în acest caz; dacă modificăm main conform codului din Listarea 19-20, vom întâmpina o eroare de compilare.
Filename: src/main.rs
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Animal::baby_name());
}Listarea 19-20: Încercarea de a invoca funcția baby_name din trăsătura Animal, însă Rust nu poate determina care implementare să o aleagă
Pentru că Animal::baby_name nu primește un parametru self și ar fi posibil să existe alte tipuri care implementează trăsătura Animal, Rust nu poate decide care implementare a Animal::baby_name dorim să o utilizăm. Vom primi următoarea eroare de compilare:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` due to previous error
Pentru a preciza și a informa Rust că vrem să folosim implementarea Animal specifică pentru Dog în detrimentul implementării pentru alt tip, trebuie să ne folosim de sintaxa complet calificată. Listarea 19-21 arată cum să utilizăm sintaxa complet calificată.
Filename: src/main.rs
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", <Dog as Animal>::baby_name()); }
Listarea 19-21: Utilizarea sintaxei complet calificate pentru a indica intenția de a apela funcția baby_name din trăsătura Animal așa cum este implementată pentru Dog
Îi oferim lui Rust o adnotație de tip între parantezele unghiulare, semnalând că intenționăm să apelăm metoda baby_name din trăsătura Animal, așa cum este implementată pentru Dog. Specificăm că dorim să considerăm tipul Dog ca fiind un Animal când efectuăm acest apel de funcție. Urmată această metodă, codul nostru va afișa ceea ce intenționăm:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
În general, sintaxa complet calificată se definește astfel:
<Type as Trait>::function(receiver_if_method, next_arg, ...);Pentru funcțiile asociate care nu sunt metode, nu vom avea un receiver, ci doar lista celorlalte argumente. Poți folosi sintaxa complet calificată oriunde apelezi funcții sau metode. Totuși, poți să omiți orice parte a acestei sintaxe pe care Rust o poate infera din restul informațiilor din program. Această sintaxă mai detaliată este necesară numai în situațiile în care există mai multe implementări care utilizează același nume și Rust are nevoie de ajutor pentru a identifica care implementare vrei să o apelezi.
Utilizarea super-trăsăturilor pentru a solicita funcționalitatea unei trăsături în cadrul alte trăsături
Există cazuri când vom scrie o definiție pentru o trăsătură ce depinde de o altă trăsătură: pentru ca un tip să implementeze prima trăsătură, dorim ca acel tip să implementeze și a doua trăsătură. Acest lucru este necesar pentru ca definiția trăsăturii noastre să poată utiliza elementele asociate ale celei de-a doua trăsături. Trăsătura de care depinde trăsătura noastră se numește o super-trăsătură.
Să considerăm, de exemplu, că dorim să creăm o trăsătură OutlinePrint care include metoda outline_print. Aceasta va tipări o valoare astfel încât să fie încadrată în asteriscuri. De pildă, pentru un struct Point ce implementează trăsătura Display din biblioteca standard și care returnează (x, y), dacă invocăm outline_print pe o instanță Point cu x egal cu 1 și y egal cu 3, ar trebui să obținem:
**********
* *
* (1, 3) *
* *
**********
Când implementăm metoda outline_print, dorim să facem uz de funcționalitatea oferită de trăsătura Display. De aceea, trebuie să specificăm că trăsătura OutlinePrint va funcționa numai cu tipurile ce implementează și Display, și care furnizează funcționalitatea necesară pentru OutlinePrint. Putem indica acest lucru în definiția trăsăturii, folosind notația OutlinePrint: Display. Această metodă este asemănătoare cu adăugarea unei delimitări de trăsătură. Listarea 19-22 ne demonstrează implementarea trăsăturii OutlinePrint.
Filename: src/main.rs
use std::fmt; trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {} *", output); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } fn main() {}
Listarea 19-22: Implementarea trăsăturii OutlinePrint care necesită funcționalitatea trăsăturii Display
Având în vedere că am stipulat ca OutlinePrint să necesite trăsătura Display, putem folosi funcția to_string, care se implementează automat pentru orice tip ce respectă trăsătura Display. Dacă am încerca să utilizăm to_string fără a adăuga două puncte : și fără a menționa trăsătura Display după numele trăsăturii, am întâmpina o eroare specificând că nu se găsește nicio metodă denumită to_string pentru tipul &Self în contextul actual.
Să examinăm ce se întâmplă atunci când încercăm să aplicăm trăsătura OutlinePrint unui tip care nu implementează Display, cum ar fi structura Point:
Filename: src/main.rs
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {} *", output);
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Vom primi o eroare care indică necesitatea implementării trăsăturii Display, neîndeplinită în cazul de față:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:6
|
20 | impl OutlinePrint for Point {}
| ^^^^^^^^^^^^ `Point` cannot be formatted with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `Point`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` due to previous error
Pentru a rezolva problema, vom implementa Display pe Point și astfel vom îndeplini cerința impusă de OutlinePrint, în felul următor:
Filename: src/main.rs
trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {} *", output); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } struct Point { x: i32, y: i32, } impl OutlinePrint for Point {} use std::fmt; impl fmt::Display for Point { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) } } fn main() { let p = Point { x: 1, y: 3 }; p.outline_print(); }
Astfel, implementarea trăsăturii OutlinePrint pe Point va compila cu succes, permițându-ne să apelăm outline_print pe o instanță de Point pentru a o afișa într-un contur de asteriscuri.
Aplicarea pattern-ului newtype pentru implementarea trăsăturilor externe pe tipuri externe
În capitolul 10, secțiunea [„Implementarea unei trăsături pe un tip”][implementing-a-trait-on-a-type] ne referim la regula orfanilor conform căreia putem implementa o trăsătură pe un tip doar dacă trăsătura sau tipul sunt locale crate-ului nostru. Poate fi ocolită această restricție utilizând pattern-ul newtype, ce presupune crearea unui nou tip în cadrul unui tuplă struct. (Această temă a fost abordată în secțiunea [„Utilizarea structurilor tuplă fără câmpuri denumite pentru a genera tipuri diferite”][tuple-structs] din capitolul 5.) Tuple struct-ul în cauză va avea un singur câmp și va fi un înveliș subțire peste tipul căruia dorim să-i aplicăm o trăsătură. Astfel, tipul înveliș devine local crate-ului nostru, permițându-ne să implementăm trăsătura pe acesta.
Termenul Newtype provine din limbajul de programare Haskell. Nu există penalități de performanță la rulare când se utilizează acest pattern, tipul înveliș fiind eliminat în timpul compilării.
Spre exemplu, dacă dorim să implementăm Display pentru Vec<T>, regula orfanilor ne împiedică să o facem direct deoarece trăsătura Display și tipul Vec<T> sunt definite în afara crate-ului nostru. Putem defini un struct Wrapper ce encapsulează o instanță Vec<T>; apoi putem implementa Display pe Wrapper și să utilizăm valoarea Vec<T>, conform Listării 19-23.
use std::fmt; struct Wrapper(Vec<String>); impl fmt::Display for Wrapper { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "[{}]", self.0.join(", ")) } } fn main() { let w = Wrapper(vec![String::from("hello"), String::from("world")]); println!("w = {}", w); }
Listarea 19-23: Crearea unui tip Wrapper peste Vec<String> pentru a implementa Display
Implementarea Display accesează Vec<T> intern utilizând self.0, dat fiind că Wrapper este un tuple struct și Vec<T> este elementul de la indexul 0 în tuplă. În continuare, putem folosi funcționalitatea Display pentru Wrapper.
Principalul dezavantaj al acestei tehnici este că Wrapper reprezintă un tip nou și nu deține metodele valorii pe care o conține. Ar trebui să implementăm toate metodele lui Vec<T> pe Wrapper, astfel încât acestea să fie delegate către self.0, permițându-ne să lucrăm cu Wrapper ca și cum ar fi un Vec<T>. Pentru ca noul tip să aibă toate metodele tipului intern, o soluție ar fi implementarea trăsăturii Deref (discutată în capitolul 15 în secțiunea [„Utilizarea pointerilor inteligenți la fel ca referințele obișnuite cu trăsătura Deref”][smart-pointer-deref]) pe Wrapper pentru a returna tipul intern. Dacă nu dorim ca tipul Wrapper să dispună de toate metodele tipului intern - de exemplu, pentru a-i restricționa comportamentul - atunci trebuie să implementăm manual doar acele metode pe care le dorim.
Pattern-ul newtype este folositor chiar și în situații care nu implică trăsături. Să ne schimbăm acum perspectiva și să explorăm modalități avansate de a interacționa cu sistemul de tipuri Rust.
[newtype]: ch19-03-advanced-traits.html#using-the-newtype-pattern-to-implement-external-traits-on-external-types [implementing-a-trait-on-a-type]: ch10-02-traits.html#implementing-a-trait-on-a-type [traits-defining-shared-behavior]: ch10-02-traits.html#traits-defining-shared-behavior [smart-pointer-deref]: ch15-02-deref.html#treating-smart-pointers-like-regular-references-with-the-deref-trait [tuple-structs]: ch05-01-defining-structs.html#using-tuple-structs-without-named-fields-to-create-different-types
Tipuri avansate
Sistemul de tipuri din Rust include unele caracteristici care ne-au fost deja prezentate, dar nu le-am explorat în profunzime până acum. Vom începe prin a discuta despre pattern-ul newtype în general, analizând motivul pentru care tipurile newtype sunt utile. Apoi vom aborda pseudonimele de tip, o funcționalitate similară cu newtype, dar cu semantici ușor diferite. De asemenea, vom discuta despre tipul ! și despre tipurile cu dimensiune dinamică.
Utilizarea pattern-ului newtype pentru siguranța și abstractizarea tipului
Notă: Această secțiune presupune că ai citit secțiunea anterioară „Utilizarea pattern-ului newtype pentru implementarea trăsăturilor externe pe tipuri externe”
Pattern-ul newtype este de asemenea util în alte situații decât cele pe care le-am tratat până acum, servind atât pentru a ne asigura că valorile nu sunt confundate între ele în mod static, cât și pentru a indica unitățile unei valori. Am văzut un exemplu în care tipurile newtype sunt folosite pentru a indica unitățile în Listarea 19-15: să ne amintim că structurile Millimeters și Meters conțineau valori u32 învelite în newtype. Dacă am compune o funcție cu un parametru de tip Millimeters, programul nostru nu ar compila dacă am încerca să apelăm acea funcție cu o valoare de tip Meters sau un u32 simplu.
În plus, putem folosi pattern-ul newtype pentru a abstractiza anumite detalii de implementare ale unui tip: noul tip poate expune o interfață API publică diferită de cea a tipului intern privat.
Newtype este folositor și pentru a masca implementarea internă. De exemplu, am putea crea un tip People pentru a împacheta un HashMap<i32, String> care păstrează ID-ul unei persoane asociat cu numele acesteia. Codul care interacționează cu People s-ar limita doar la interfața API publică pe care o furnizăm, cum ar fi o metodă pentru adăugarea unui șir de caractere reprezentând numele în colecția People; acest cod nu ar avea nevoie să cunoască faptul că intern folosim un ID de tip i32 pentru nume. Pattern-ul newtype este o cale eficientă de a atinge încapsularea pentru a masca detalii de implementare, un aspect pe care l-am discutat în secțiunea „Încapsularea care ascunde detaliile implementării” din Capitolul 17.
Crearea sinonimelor de tip prin aliasuri de tip
Rust ne permite să declarăm un alias de tip pentru a oferi unui tip existent un nume alternativ. Facem acest lucru utilizând cuvântul cheie type. De exemplu, putem crea aliasul Kilometers pentru i32 astfel:
fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
Aliasul Kilometers acum funcționează ca un sinonim pentru i32; în contrast cu tipurile Millimeters și Meters pe care le-am creat anterior, în Listarea 19-15, Kilometers nu constituie un tip nou și separat. Valorile de tipul Kilometers vor fi tratate identic cu valorile de tip i32:
fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
Fiindcă Kilometers și i32 sunt de fapt același tip, putem adăuga împreună valori de ambele tipuri și putem transmite valori de tip Kilometers către funcții care acceptă parametrii de tip i32. Cu toate acestea, această metodă nu ne conferă avantajele verificării de tipuri pe care le avem cu modelul newtype, despre care am discutat anterior. Adică, dacă am confunda valorile Kilometers cu cele i32 într-un anumit loc, compilatorul nu va genera eroare.
Utilizarea principală a sinonimelor de tip este de a diminua repetiția. De pildă, putem să ne confruntăm cu un tip complicat ca acesta:
Box<dyn Fn() + Send + 'static>Scriind acest tip extins în semnăturile funcțiilor și ca adnotări de tip de-a lungul codului poate fi anevoios și susceptibil de erori. Imaginează-ți un proiect plin cu cod similar acelui din Listarea 19-24.
fn main() { let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi")); fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) { // --snip-- } fn returns_long_type() -> Box<dyn Fn() + Send + 'static> { // --snip-- Box::new(|| ()) } }
Listarea 19-24: Folosirea unui tip lung în numeroase locuri
Un alias de tip simplifică gestionarea acestui cod prin reducerea frecvenței repetării. În Listarea 19-25, am introdus aliasul Thunk pentru tipul lung și acum putem înlocui toate aparițiile acelui tip cu aliasul mai concis Thunk.
fn main() { type Thunk = Box<dyn Fn() + Send + 'static>; let f: Thunk = Box::new(|| println!("hi")); fn takes_long_type(f: Thunk) { // --snip-- } fn returns_long_type() -> Thunk { // --snip-- Box::new(|| ()) } }
Listarea 19-25: Introducerea unui alias de tip Thunk pentru diminuarea repetiției
Acest cod este mult mai simplu de citit și scris! Selectarea unui nume sugestiv pentru un alias de tip poate contribui și la transmiterea intenției noastre (termenul thunk se referă la codul care va fi evaluat ulterior, deci este un nume adecvat pentru o închidere care este păstrată încă neevaluată).
Aliasurile de tip sunt frecvent utilizate și împreună cu tipul Result<T, E> pentru a diminua repetiția. Să luăm ca exemplu modulul std::io din biblioteca standard. Operațiile de I/O returnează de obicei un Result<T, E> pentru a aborda cazurile când aceste operații eșuează. Biblioteca conține structura std::io::Error, care reprezintă toate erorile de I/O posibile. Multe dintre funcțiile din std::io vor returna un Result<T, E> unde E este std::io::Error, cum ar fi funcțiile din trăsătura Write:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}Expresia Result<..., Error> se repetă deseori. Drept urmare, std::io declară acest alias de tip:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Fiindcă această declarație se află în modulul std::io, putem utiliza aliasul complet specificat std::io::Result<T>; adică, un Result<T, E> unde E este specificat drept std::io::Error. Funcțiile din semnăturile trăsăturii Write capătă în cele din urmă următoarea înfățișare:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Aliasul de tip ne ajută în două feluri: îmbunătățește concizia codului și oferă o interfață coerentă întregului modul std::io. Deoarece este un alias, rămâne pur și simplu un alt Result<T, E>, ceea ce înseamnă că putem aplica asupra lui orice metodă compatibilă cu Result<T, E>, inclusiv folosirea de sintaxă specială, cum ar fi operatorul ?.
Tipul `never`` care nu returnează niciodată
Rust dispune de un tip special numit !, cunoscut în terminologia teoriei tipurilor ca tipul gol deoarece nu posedă nicio valoare. Totuși, preferăm să-l numim tipul never deoarece este utilizat în locul tipului de retur când o funcție nu va returna niciodată. Iată un exemplu:
fn bar() -> ! {
// --snip--
panic!();
}Acest cod se citește ca „funcția bar returnează never.” Funcțiile care returnează never sunt numite funcții divergente. Imposibilitatea creării de valori de tipul ! implică faptul că bar nu va putea returna niciodată.
Dar care este utilitatea unui tip pentru care nu putem crea valori? Vom reaminti codul din Listarea 2-5, care face parte din jocul de ghicit numerele; iată o reproducere parțială în Listarea 19-26:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Listarea 19-26: Un match cu o ramură care se încheie cu continue
Pe atunci, am omis detalii importante ale acestui cod. În Capitolul 6, secțiunea „Operatorul de control al fluxului match”, am explicat că toate ramurile match trebuie să returneze același tip. Astfel, codul următor nu este funcțional:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}Tipul lui guess de aici ar trebui să fie atât integer cât și string, dar Rust afirmă că guess trebuie să aibă un singur tip definit. Atunci, ce returnează continue? Cum a fost posibil să returnăm u32 dintr-o ramură și o altă ramură să se încheie cu continue în Listarea 19-26?
După cum probabil ai dedus, continue are valoarea !. Adică, când Rust determină tipul lui guess, analizează ambele ramuri ale match-ului, prima cu o valoare u32 și a doua cu valoarea !. Din moment ce ! nu poate avea vreo valoare, Rust decide că tipul lui guess este u32.
Descrierea formală a acestui comportament este că expresiile de tip ! pot fi transformate în orice alt tip. Este permis să finalizăm această ramură de match cu continue deoarece continue nu produce o valoare; în schimb, redirecționează controlul la începutul buclei, așadar în cazul Err, guess nu primește nicio valoare.
Tipul never este de asemenea valoros în contextul macro-ului panic!. Să ne amintim de funcția unwrap pe care o utilizăm pe valori de tip Option<T> pentru a obține o valoare sau a genera panică; iată definiția ei:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}Aici, se întâmplă exact ca în cazul match-ului din Listarea 19-26: Rust observă că val are tipul T și panic! are tipul !, astfel rezultatul întregii expresii match este T. Acest cod este valid pentru că panic! nu generează o valoare; el încheie execuția programului. În cazul None, nu vom returna o valoare din unwrap, deci acest fragment de cod este corect.
O ultimă expresie care are valoarea ! este loop:
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}În acest caz, bucla nu se finalizează niciodată, prin urmare ! este valoarea expresiei. Totuși, aceasta nu ar fi adevărat dacă am adăuga un break, întrucât bucla s-ar opri odată ce s-ar ajunge la break.
Tipuri dinamic dimensionate și trăsătura Sized
Rust trebuie să cunoască detalii specifice despre tipurile sale, cum ar fi cantitatea de spațiu necesară alocării pentru o valoare de un anumit tip. Acest lucru crează o anumită confuzie în sistemul de tipuri, la prima vedere: conceptul de tipuri dinamic dimensionate (dynamically sized types, DST) sau tipuri fără mărime fixă. Aceste tipuri ne permit să scriem cod folosind valori a căror mărime o putem determina doar în timpul execuției.
Să explorăm în detaliu un tip dinamic dimensionat numit str, pe care l-am utilizat constant în această carte. Da, nu &str, ci str în sine este un DST. Nu putem determina lungimea string-ului decât în timpul execuției, ceea ce înseamnă că nu putem crea o variabilă de tip str, nici nu putem accepta un argument de acest tip. Să explorăm următorul exemplu de cod, care nu va compila:
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}Rust necesită să știe de câtă memorie are nevoie fiecare valoare a unui tip specific, și fiecare valoare a acelui tip trebuie să folosească aceeași cantitate de memorie. Dacă Rust ar permite acest cod să fie scris, cele două valori str ar trebui să ocupe același spațiu. Dar ele au lungimi diferite: s1 necesită 12 octeți de stocare, s2 - 15. Acest motiv face imposibilă crearea unei variabile de tip dinamic dimensionat.
Deci, ce putem face? Deja știi soluția: tipizăm s1 și s2 ca &str în loc de str. Așa cum am discutat în secțiunea “Secțiuni de string” din Capitolul 4, o structură de tip secțiune stochează doar poziția de start și lungimea secțiunii. De aceea, în timp ce un &T este o valoare care menține adresa de memorie unde T se află, un &str este format din două valori: adresa 'str'-ului și lungimea acestuia. Astfel, noi putem cunoaște mărimea unei valori &str în momentul compilării: este de două ori mărimea unui usize. Asta înseamnă că știm întotdeauna mărimea unui &str, indiferent cât de lung este string-ul referențiat. În mod obișnuit, în Rust, DST-urile se folosesc astfel: conțin o porțiune suplimentară de metadate care stochează mărimea informației dinamice. Regula fundamentală a tipurilor dinamic dimensionate este aceea că valorile lor trebuie să fie întotdeauna plasate în spatele unui tip de pointer.
Putem să combinăm str cu diverse tipuri de pointeri, cum ar fi Box<str> sau Rc<str>. De fapt, te-ai întâlnit deja cu acest concept, dar în cazul unui alt tip dinamic dimensionat: trăsăturile. Fiecare trăsătură este un DST la care ne putem referi folosind numele trăsăturii. În Capitolul 17, în secțiunea “Utilizând obiecte trăsătură care termit valori de diferite tipuri”, am menționat că pentru a folosi trăsăturile ca obiecte trăsătură, trebuie să le punem în spatele unui pointer, cum ar fi &dyn Trait sau Box<dyn Trait>; varianta Rc<dyn Trait> este, de asemenea, validă.
Pentru a lucra cu DST-uri, Rust folosește trăsătura Sized, care ne spune dacă mărimea unui tip este cunoscută la momentul compilării. Această trăsătură este automat implementată pentru toate elementele ale căror dimensiuni pot fi determinate la compilare. Mai mult, Rust adaugă implicit o constrângere Sized la orice funcție generică. Astfel, definiția unei funcții generice precum:
fn generic<T>(t: T) {
// --snip--
}este tratată de parcă am fi scris de fapt așa:
fn generic<T: Sized>(t: T) {
// --snip--
}Implicit, funcțiile generice vor funcționa doar cu tipuri a căror mărime este cunoscută la momentul compilării. Cu toate acestea, putem folosi următoarea sintaxă specială pentru a slăbi această restricție:
fn generic<T: ?Sized>(t: &T) {
// --snip--
}O constrângere pe ?Sized înseamnă că "T poate sau nu poate fi Sized", și această notație anulează implicitul conform căruia tipurile generice trebuie să aibă o dimensiune cunoscută la momentul compilării. Sintaxa ?Trait cu acest înțeles este disponibilă numai pentru Sized, nu și pentru alte trăsături.
Notăm, de asemenea, că am schimbat tipul parametrului t din T în &T, deoarece tipul poate să nu fie Sized, și astfel, trebuie să lucrăm cu el prin intermediul unui anumit tip de pointer. În acest caz, am optat pentru o referință.
În următoare secțiune, vom aborda subiectul funcțiilor și închiderilor!
Funcții și închideri avansate
Această secțiune abordează unele funcționalități avansate legate de funcții și închideri, incluzând pointeri de funcții și returnarea închiderilor.
Pointeri de funcții
Am discutat despre cum să pasăm închideri funcțiilor; de asemenea, poți pasa și funcții obișnuite funcțiilor! Această tehnică este utilă atunci când vrei să pasezi o funcție pe care deja ai definit-o în loc să definești o nouă închidere. Funcțiile se pot transforma în tip fn (cu 'f' mic), pentru a nu se confunda cu trăsătura închiderii Fn. Tipul fn este numit pointer de funcție. Utilizarea pointerilor de funcție pentru pasarea funcțiilor ne permite să folosim funcții ca argumente ale altor funcții.
Sintaxa pentru specificarea că un parametru este un pointer de funcție este similară cu cea a închiderilor, așa cum este ilustrat în Listarea 19-27, unde am definit funcția add_one care adaugă unitate la parametrul său. Funcția do_twice acceptă doi parametri: un pointer de funcție către orice funcție care acceptă un parametru i32 și returnează un i32, și o valoare i32. Funcția do_twice invocă funcția f de două ori, pasându-i valoarea arg, apoi sumează rezultatele celor două apeluri de funcție. Funcția main invocă do_twice cu argumentele add_one și 5.
Numele fișierului: src/main.rs
fn add_one(x: i32) -> i32 { x + 1 } fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 { f(arg) + f(arg) } fn main() { let answer = do_twice(add_one, 5); println!("The answer is: {}", answer); }
Listarea 19-27: Utilizarea tipului fn pentru a accepta un pointer de funcție ca argument
Această porțiune de cod afișează The answer is: 12. Am specificat că parametrul f în funcția do_twice este de tip fn care acceptă un parametru de tip i32 și returnează i32. Apoi putem invoca f în corpul funcției do_twice. În funcția main putem trece numele funcției add_one ca prim argument pentru do_twice.
Spre deosebire de închideri, fn este un tip și nu o trăsătură, prin urmare specificăm direct fn ca tip de parametru, în loc să declarăm un parametru de tip generic cu una dintre trăsăturile Fn ca o delimitare de trăsătură.
Pointerii de funcție implementează toate cele trei trăsături ale închiderilor (Fn, FnMut, FnOnce), ceea ce înseamnă că poți mereu să utilizezi un pointer de funcție ca argument pentru o funcție care așteaptă o închidere. Este mai recomandat să scriem funcții folosind un tip generic și una dintre trăsăturile închiderii, astfel încât funcțiile noastre să poată accepta atât funcții cât și închideri.
Totuși, un exemplu când ai prefera să accepți doar fn și nu închideri este când interacționezi cu cod extern care nu dispune de închideri: de exemplu, funcțiile în limbajul C pot primi funcții ca argumente, însă C nu suportă închideri.
Pentru a ilustra o situație unde ai putea folosi fie o închidere definită direct în cod, fie o funcție cu nume, să examinăm utilizarea metodei map oferită de trăsătura Iterator din biblioteca standard. Pentru a aplica funcția map pentru a converti un vector de numere într-un vector de string-uri, putem folosi o închidere, astfel:
fn main() { let list_of_numbers = vec![1, 2, 3]; let list_of_strings: Vec<String> = list_of_numbers.iter().map(|i| i.to_string()).collect(); }
Alternativ, am putea folosi o funcție definită cu nume drept argument pentru map în locul unei închideri, în felul următor:
fn main() { let list_of_numbers = vec![1, 2, 3]; let list_of_strings: Vec<String> = list_of_numbers.iter().map(ToString::to_string).collect(); }
Este important de reținut că trebuie să utilizăm sintaxa complet calificată despre care am discutat anterior în secțiunea „Trăsături avansate”, deoarece există multiple funcții disponibile sub numele to_string. Aici, utilizăm funcția to_string definită în trăsătura ToString, pe care biblioteca standard o implementează pentru orice tip ce implementează Display.
Reamintește-ți din secțiunea „Valori ale enum-urilor” a Capitolului 6 că denumirea fiecărei variante a enum-ului pe care o definim devine de asemenea o funcție de inițializare. Aceste funcții de inițializare pot fi folosite ca pointeri către funcții care implementează trăsăturile închiderii, ceea ce înseamnă că putem specifica funcțiile de inițializare ca argumente pentru metodele ce acceptă închideri, astfel:
fn main() { enum Status { Value(u32), Stop, } let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect(); }
Aici, creăm instanțe de tip Status::Value folosind fiecare valoare u32 situată în diapazonul pe care map este invocat, utilizând funcția de inițializare pentru Status::Value. Unii preferă acest stil, în timp ce alții optează pentru utilizarea de închideri. Fiindcă acestea compilează la același cod, alege stilul care îți pare mai clar.
Returnarea închiderilor
Închiderile sunt reprezentate de trăsături, ceea ce înseamnă că nu se pot returna direct închideri. De cele mai multe ori, când ai vrea să returnezi o trăsătură, poti folosi tipul concret care implementează trăsătura ca valoare de retur pentru funcție. Totuși, acest lucru nu este posibil cu închiderile, întrucât nu au un tip concret care să fie returnabil; nu este permis, de exemplu, să folosiți pointerul de funcție fn ca tip de retur.
Următorul cod încearcă să returneze direct o închidere, însă nu va reuși să compileze:
fn returns_closure() -> dyn Fn(i32) -> i32 {
|x| x + 1
}Eroarea raportată de compilator este următoarea:
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0746]: return type cannot have an unboxed trait object
--> src/lib.rs:1:25
|
1 | fn returns_closure() -> dyn Fn(i32) -> i32 {
| ^^^^^^^^^^^^^^^^^^ doesn't have a size known at compile-time
|
= note: for information on `impl Trait`, see <https://doc.rust-lang.org/book/ch10-02-traits.html#returning-types-that-implement-traits>
help: use `impl Fn(i32) -> i32` as the return type, as all return paths are of type `[closure@src/lib.rs:2:5: 2:8]`, which implements `Fn(i32) -> i32`
|
1 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ~~~~~~~~~~~~~~~~~~~
For more information about this error, try `rustc --explain E0746`.
error: could not compile `functions-example` due to previous error
Eroarea invocă din nou trăsătura Sized! Rust nu poate determina cât spațiu va fi necesar pentru stocarea închiderii. Am întâlnit o soluție pentru această problemă anterior. Putem utiliza un obiect de tip trăsătură:
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}Acest cod va compila fără probleme. Pentru mai multe detalii despre obiectele de tip trăsătură, vedem secțiunea “Using Trait Objects That Allow for Values of Different Types” din Capitolul 17.
Acum, să ne îndreptăm atenția către macrouri!
Macrocomenzi
Pe parcursul acestei cărți, am utilizat macrocomenzi precum println!, dar nu am examinat îndeaproape ce reprezintă o macrocomandă și cum funcționează. Termenul macrocomandă se referă la o clasă de caracteristici în Rust: macrocomenzi declarative cu macro_rules! și trei tipuri de macrocomenzi procedurale:
- Macrocomenzi
#[derive]personalizate care specifică cod adăugat cu atributulderiveutilizat la structuri și enumerări - Macrocomenzi similare atributelor ce definesc atribute personalizate aplicabile pe orice element
- Macrocomenzi ce semănă cu funcțiile, care par a fi apeluri de funcții, dar operează pe token-uri specificate ca argumente
Vom discuta despre fiecare în parte, dar înainte de asta, să explorăm motivul pentru care avem nevoie de macrocomenzi, chiar dacă dispunem deja de funcții.
Diferența dintre macrocomenzi și funcții
La baza lor, macrocomenzile sunt un mod de a scrie cod ce generează alt cod, proces cunoscut ca metaprogramare. În Anexa C, discutăm atributul derive, care produce implementări automatizate pentru diferite trăsături. De asemenea, am folosit macrocomenzile println! și vec! prin întreaga carte. Toate aceste macrocomenzi se desfășoară pentru a crea mai mult cod decât cel scris de tine manual.
Metaprogramarea este eficientă în reducerea cantității de cod pe care trebuie să o scrii și să o menții, un rol pe care îl joacă și funcțiile. Totuși, macrocomenzile au anumite capabilități suplimentare față de funcții.
Semnătura unei funcții trebuie să indice numărul și tipurile de parametrii pe care funcția îi acceptă. Macrocomenzile, în schimb, pot accepta un număr variabil de parametri: putem invoca println!("hello") cu un singur argument sau println!("hello {}", name) cu două argumente. Mai mult, macrocomenzile sunt desfășurate înaintea interpretării codului de către compilator, așa că o macrocomandă poate să implementeze o trăsătură pentru un anumit tip, spre deosebire de funcții, care sunt apelate în timpul execuției și nu pot implementa trăsături, ce trebuie definite în timpul compilării.
Un dezavantaj al utilizării macrocomenzilor în locul funcțiilor este că definițiile de macrocomenzi pot fi mai complexe decât cele ale funcțiilor, deoarece scrim cod Rust care generează cod Rust. Acest nivel suplimentar de abstractizare face ca definițiile de macrocomenzi să fie mai greu de citit, de înțeles și de întreținut decât cele ale funcțiilor.
O altă diferență semnificativă între macrocomenzi și funcții este că macrocomenzile trebuie definite sau aduse în domeniul de vizibilitate înaintea utilizării lor într-un fișier, spre deosebire de funcții, care pot fi definite oriunde și apelate în orice loc din cod.
Macrocomenzi declarative cu macro_rules! pentru metaprogramare generală
Forma de macrocomandă cea mai des utilizată în Rust este macrocomanda declarativă. Acestea sunt cunoscute și ca „macrocomenzi prin exemplu”, „macrocomenzi macro_rules!”, sau simplu, „macrocomenzi”. La baza lor, macrocomenzile declarative ne permit să scrim ceva similar unei expresii Rust match. După cum am discutat în Capitolul 6, expresiile match sunt structuri de control care evaluează o expresie, compară valoarea rezultată cu pattern-uri, și execută codul asociat cu pattern-ul corespunzător. Macrocomenzile compară, de asemenea, o valoare cu pattern-uri ce sunt asociate cu anumite secțiuni de cod: în această situație, valoarea este codul sursă Rust literal transmis macrocomenzii; pattern-urile sunt comparate cu structura acelui cod sursă, iar codul asociat fiecărui pattern corespunzător înlocuiește codul inițial transmis macrocomenzii. Tot acest proces are loc în timpul compilării.
Pentru a defini o macrocomandă, folosim construcția macro_rules!. Să explorăm cum se utilizează macro_rules!, prin a examina cum este definită macrocomanda vec!. Capitolul 8 a discutat cum putem folosi macrocomanda vec! pentru a inițializa un vector nou cu valori specifice. Spre exemplu, macrocomanda următoare creează un vector nou ce conține trei numere întregi de tip u32:
#![allow(unused)] fn main() { let v: Vec<u32> = vec![1, 2, 3]; }
Macrocomanda vec! poate fi folosită de asemenea pentru a crea un vector cu două numere întregi sau un vector cu cinci secțiuni de string. Nu am putea realiza aceeași funcționalitate folosind o funcție, deoarece nu am ști numărul sau tipurile valorilor dinainte.
Listarea 19-28 prezintă o variantă simplificată a definiției macrocomenzii vec!.
Filename: src/lib.rs
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}Listarea 19-28: O versiune simplificată a definiției macrocomenzii vec!
Adnotarea #[macro_export] indică faptul că această macrocomandă trebuie să fie disponibilă de îndată ce crate-ul în care a fost definită este adus în domeniul de vizibilitate. În lipsa acestei adnotări, macrocomanda nu ar putea fi adusă în domeniul de vizibilitate.
Inițiem definiția de macrocomandă cu macro_rules! și numele macrocomenzii care se definește fără semnul de exclamare. În exemplul nostru, numele este vec, și este urmat de acolade care trasează granițele corpului definiției macrocomenzii.
Structura din corpul vec! seamănă cu cea a unei expresii match. În acest caz, avem o singură ramură cu pattern-ul ( $( $x:expr ),* ), urmat de => și blocul de cod asociat acestui pattern. Când pattern-ul corespunde, blocul de cod corespondent este generat. Deoarece acesta este singurul pattern din macrocomandă, aceasta este singura formă de pattern acceptată; orice altă formă va cauza o eroare. Macrocomenzile mai complexe pot avea mai multe ramuri.
Sintaxa pattern-urilor valide în definiţiile macrocomenzilor este diferită de sintaxa pattern-urilor discutate în Capitolul 18, deoarece pattern-urile macro se potrivesc cu structura codului Rust, nu cu valorile. Să explorăm semnificația componentelor pattern-ului din Listarea 19-28; pentru ințelegerea completa a sintaxei pattern-urilor de macrocomandă, consultați Referința Rust.
Mai întâi, folosim un set de paranteze pentru a înconjura întreg pattern-ul. Utilizăm un semn dolar ($) pentru a declara o variabilă în sistemul de macrocomenzi care va conține codul Rust ce corespunde pattern-ului. Semnul dolar face clară distincția că aceasta este o variabilă de macrocomandă și nu una Rust obișnuită. Apoi vine un set de paranteze care captează valorile ce se potrivesc cu pattern-ul din interiorul parantezelor pentru utilizare în codul substituit. În cadrul $() este $x:expr, care se potrivește cu orice expresie Rust și îi atribuie expresiei numele $x.
Virgula de după $() indică faptul că un caracter separator literal de virgulă poate apărea opțional după codul care se potrivește în $(). Simbolul * indică că pattern-ul se aplică de zero sau mai multe ori pentru orice precede *.
Când apelăm această macrocomandă folosind vec![1, 2, 3];, pattern-ul $x se aplică de trei ori pentru cele trei expresii 1, 2 și 3.
Acum să analizăm pattern-ul din corpul codului asociat cu acest segment: temp_vec.push() generat în $()* se produce pentru fiecare element care corespunde cu $() în pattern, de zero ori sau mai multe, în funcție de numărul de potriviri ale pattern-ului. Variabila $x este înlocuită cu fiecare expresie potrivită. Apelarea acestei macrocomenzi cu vec![1, 2, 3];, generează următorul cod care substituie apelul macrocomenzii:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}Am definit o macrocomandă care poate accepta orice număr de argumente de orice tip și poate genera cod pentru crearea unui vector care conține elementele indicate.
Pentru a învăța mai multe despre cum se scriu macrocomenzile, consultă documentația online sau alte resurse, precum „The Little Book of Rust Macros” inițiat de Daniel Keep și continuat de Lukas Wirth.
Macrocomenzi procedurale pentru generarea de cod din atribute
A doua categorie de macrocomenzi este macrocomanda procedurală, care funcționează mai mult ca o funcție (fiind un tip de procedură). Macrocomenzile procedurale primesc un cod ca intrare, îl prelucrează și generează cod ca ieșire, spre deosebire de macrocomenzile declarative, care se bazează pe potrivirea de pattern-uri și înlocuirea codului cu altul. Există trei tipuri de macrocomenzi procedurale: "custom derive", "attribute-like" și "function-like", toate având o modalitate de operare asemănătoare.
Când dezvoltăm macrocomenzi procedurale, acestea trebuie să fie plasate în propriul lor crate, de un tip special. Acest lucru se datorează unor motive tehnice complexe care sperăm să fie rezolvate în viitor. În Exemplul 19-29, putem vedea cum se definește o macrocomandă procedurală, unde some_attribute servește drept loc pentru un anumit tip de macrocomandă.
Numele fișierului: src/lib.rs
use proc_macro;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}Exemplu 19-29: Definirea unei macrocomenzi procedurale
Funcția care definește o macrocomandă procedurală primește un TokenStream ca intrare și returnează un TokenStream. Tipul TokenStream este definit de crate-ul proc_macro, inclus în Rust, și reprezintă o secvență de token-uri. Acesta este nucleul macrocomenzii: codul sursă asupra căruia operează macrocomanda constituie TokenStream-ul de intrare, iar codul generat de macrocomandă este TokenStream-ul de ieșire. Funcția are, de asemenea, un atribut atașat care specifică ce fel de macrocomandă procedurală este creată. Putem defini mai multiple varietăți de macrocomenzi procedurale în același crate.
Să explorăm diferitele feluri de macrocomenzi procedurale. Începem cu macrocomanda de tip "custom derive" și apoi vom clarifica subtilele diferențe care disting celelalte forme.
Cum să scrii o macrocomandă derive personalizată
Să creăm un crate numit hello_macro care definește o trăsătură numită HelloMacro cu o funcție asociată numită hello_macro. În loc să-i cerem fiecărui utilizator să implementeze trăsătura HelloMacro pentru tipurile lor, vom furniza o macrocomandă procedurală care permite utilizatorilor să adnoteze tipurile lor cu #[derive(HelloMacro)] și astfel să obțină o implementare implicită a funcției hello_macro. Această implementare implicită va afișa Hello, Macro! Numele meu este TypeName!, unde TypeName este numele tipului pentru care a fost definită trăsătura. Cu alte cuvinte, scriem un crate care permite unui alt programator să scrie codul prezentat în Listarea 19-30 folosind crate-ul nostru.
Numele fișierului: src/main.rs
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}
...Listarea 19-30: Codul pe care un utilizator al crate-ului nostru îl poate scrie utilizând macrocomanda noastră procedurală
Acest cod va afișa Hello, Macro! My name is Pancakes! când încheiem. Primul pas este să creăm un nou crate de tip bibliotecă, așa:
$ cargo new hello_macro --lib
Apoi, vom defini trăsătura HelloMacro și funcția sa asociată:
Numele fișierului: src/lib.rs
pub trait HelloMacro {
fn hello_macro();
}Avem o trăsătură și funcția ei. În acest moment, utilizatorul nostru ar putea să implementeze trăsătura pentru a obține funcționalitatea dorită, în următorul mod:
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}Însă, ar trebui să redacteze blocul de implementare pentru fiecare tip pe care doresc să-l utilizeze împreună cu hello_macro; scopul nostru este să-i scutim de acest efort.
În plus, în momentul de față nu putem oferi funcției hello_macro o implementare implicită care să afișeze numele tipului pe care este implementată trăsătura: Rust nu dispune de facilități de reflecție, deci nu poate determina numele tipului în timpul rulării. Avem nevoie de o macrocomandă care să genereze cod în timpul compilării.
Următorul pas este să definim macrocomanda procedurală. La momentul redactării acestei cărți, macrocomenzile procedurale trebuie să fie în propriul lor crate. Este posibil ca în viitor această restricție să fie eliminată. Convenția pentru crate-urile structurale și crate-urile de macrocomenzi este următoarea: pentru un crate denumit foo, un crate de macrocomandă procedurală custom derive este denumit foo_derive. Să începem un nou crate numit hello_macro_derive în interiorul proiectului nostru hello_macro:
$ cargo new hello_macro_derive --lib
Cele două crate-uri sunt strâns legate, așadar creăm crate-ul de macrocomandă procedurală în directoriul crate-ului nostru hello_macro. Dacă modificăm definiția trăsăturii în hello_macro, va trebui să ajustăm și implementarea macrocomenzii procedurale în hello_macro_derive. Cele două crate-uri trebuie publicate separat, iar programatorii care utilizează aceste crate-uri trebuie să le adauge pe amândouă ca dependențe și să le includă în domeniul de vizibilitate. Totuși, am putea face ca hello_macro să folosească hello_macro_derive ca dependență și să reexporte codul macrocomenzii procedurale. Cu toate acestea, modul în care am structurat proiectul permite programatorilor să folosească hello_macro chiar și dacă nu doresc funcționalitatea derive.
Este necesar să declarăm crate-ul hello_macro_derive drept un crate de macrocomandă procedurală. De asemenea, avem nevoie de funcționalități din crate-urile syn și quote, așa cum vom vedea în curând, deci trebuie să le aducem ca dependențe. Adăugăm următoarele în fișierul Cargo.toml pentru hello_macro_derive:
Numele fișierului: hello_macro_derive/Cargo.toml
[lib]
proc-macro = true
[dependencies]
syn = "1.0"
quote = "1.0"
Pentru a începe definirea macrocomenzii procedurale, introducem codul din Listarea 19-31 în fișierul nostru src/lib.rs pentru crate-ul hello_macro_derive. Acest cod nu va compila până când nu adăugăm o definiție pentru funcția impl_hello_macro.
Filename: hello_macro_derive/src/lib.rs
use proc_macro::TokenStream;
use quote::quote;
use syn;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}Listarea 19-31: Codul necesar majorității crate-urilor de macrocomenzi procedurale pentru a prelucra cod Rust
Am observat că am divizat codul în funcția hello_macro_derive, care este responsabilă cu analiza TokenStream, și în funcția impl_hello_macro, care gestionează transformarea arborelui sintactic: aceasta ușurează procesul de scriere a unei macrocomenzi procedurale. Codul din funcția exterioară (hello_macro_derive, în acest caz) va fi același pentru majoritatea crate-urilor de macrocomenzi procedurale întâlnite sau create. Însă, codul din interiorul funcției interne (impl_hello_macro, în acest caz) se va modifica în funcție de scopul final al macrocomenzii procedurale respective.
Am aflat de trei crate-uri noi: proc_macro, syn și quote. Crate-ul proc_macro este furnizat odată cu Rust, așadar nu a fost necesar să îl adăugăm în Cargo.toml la dependențe. Crate-ul proc_macro constituie API-ul compilatorului care ne permite să citim și să modificăm codul Rust din cadrul codului nostru.
Crate-ul syn transformă codul Rust dintr-un string într-o structură de date pe care putem aplica operațiuni. Crate-ul quote reconstruiește structuri de date syn în cod Rust. Utilizarea acestor crate-uri simplifică semnificativ procesul de parsare a diferitelor tipuri de cod Rust pe care dorim să le gestionăm: construirea unui parser complet pentru Rust reprezintă o provocare considerabilă.
Funcția hello_macro_derive este activată când un utilizator al bibliotecii noastre adaugă #[derive(HelloMacro)] la un tip. Posibilitatea aceasta se datorează faptului că am marcat funcția hello_macro_derive cu proc_macro_derive și i-am atribuit numele HelloMacro, concordând cu numele trăsăturii noastre, urmând astfel convenția adoptată de majoritatea macrocomenzilor procedurale.
Funcția hello_macro_derive începe prin a converti input-ul dintr-un TokenStream într-o structură de date care ulterior poate fi interpretată și manipulată. Acest proces implică biblioteca syn. Metoda parse de la syn primește un TokenStream și generează o structură DeriveInput, care reprezintă codul Rust parsat. Listarea 19-32 ne arată părțile relevante ale structurii DeriveInput pe care o primim atunci când analizăm șirul struct Pancakes;:
DeriveInput {
// --snip--
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}Listarea 19-32: Instanța DeriveInput pe care o primim în urma parsării codului ce conține atributul macrocomenzii din Listarea 19-30
Câmpurile acestei structuri ne indică faptul că codul Rust analizat este un struct de tip unitar cu identificatorul ident având numele Pancakes. Structura include mai multe câmpuri pentru descrierea diverselor tipuri de coduri Rust; pentru informații suplimentare consultă documentația syn referitoare la DeriveInput.
În curând, vom defini funcția impl_hello_macro, acolo unde vom crea noul cod Rust pe care dorim să-l integram. Însă înainte de acest pas, este important de reținut că ieșirea macrocomenzii noastre derivate este, de asemenea, un TokenStream. Acest TokenStream returnat este inclus în codul scris de utilizatorii crate-ului nostru, astfel încât, atunci când compilează crate-ul, acesta va include funcționalitățile suplimentare pe care le furnizăm noi prin intermediul TokenStream modificat.
Poate ai observat că utilizăm unwrap care va declanșa o panică în funcția hello_macro_derive dacă apelul la funcția syn::parse nu reușește. Această abordare este necesară deoarece macrocomenzile procedurale trebuie să genereze panică în caz de erori, având în vedere că funcțiile proc_macro_derive trebuie să returneze TokenStream în loc de Result pentru a fi conforme cu interfața API de macrocomenzi procedurale. Acest exemplu a fost simplificat prin utilizarea lui unwrap; într-un cod destinat producției, ar trebui să oferim mesaje de eroare mai detaliate cu privire la natura problemei folosind panic! sau expect.
Acum că avem codul pentru conversia codului Rust adnotat de la un TokenStream la o instanță de tip DeriveInput, să trecem la generarea codului care implementează trăsătura HelloMacro pe tipul adnotat, conform exemplului din Listarea 19-33.
Numele fișierului: hello_macro_derive/src/lib.rs
use proc_macro::TokenStream;
use quote::quote;
use syn;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let gen = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
gen.into()
}Listarea 19-33: Implementarea trăsăturii HelloMacro utilizând codul Rust parsat
Prin intermediul ast.ident obținem o instanță de tip Ident care include numele (identificatorul) tipului adnotat. Structura prezentată în Listarea 19-32 ne demonstrează că, atunci când executăm funcția impl_hello_macro asupra codului din Listarea 19-30, ident-ul obținut va avea câmpul ident cu valoarea "Pancakes". Deci, variabila name din Listarea 19-33 va conține o structură de tip Ident care, când va fi afișată, va rezulta în string-ul "Pancakes", numele structurii din Listarea 19-30.
Macrocomanda quote! ne facilitează definirea codului Rust pe care dorim să îl returnăm. Compilatorul așteaptă o formă diferită în comparație cu rezultatul direct al executării macrocomenzii quote!, astfel că este necesar să o convertim în TokenStream. Acest lucru se realizează apelând metoda into, care transformă această reprezentare intermediară într-o valoare de tipul necesar TokenStream.
Macrocomanda quote! oferă, de asemenea, mecanisme de șabloane extrem de utile: dacă inserăm #name, quote! va substitui acesta cu valoarea din variabila name. Se pot realiza chiar repetiții similare cu cea a macrocomenzilor obișnuite. Pentru o înțelegere detaliată, vezi documentația crate-ului quote.
Dorim ca macrocomanda noastră procedurală să creeze o implementare a trăsăturii HelloMacro pentru tipul adnotat de utilizator, lucru pe care îl obținem utilizând #name. Implementarea respectivei trăsături conține funcția hello_macro, al cărei corp include funcționalitatea pe care dorim să o oferim: afișarea mesajului Hello, Macro! My name is urmat de numele tipului adnotat.
Macrocomanda stringify!, ce este utilizată aici, este integrată direct în Rust. Ea preia o expresie Rust, cum ar fi 1 + 2, și o transformă într-un string literal la timpul de compilare, precum "1 + 2". Aceasta diferă de macrocomenzile format! sau println!, care evaluează expresia și apoi convertesc rezultatul în String. Având în vedere că intrarea #name ar putea fi o expresie ce trebuie tipărită literal, folosim stringify!. Folosirea stringify! economisește de asemenea o alocare, convertind #name într-un string literal încă din timpul compilării.
În acest stadiu, comanda cargo build ar trebui să se execute cu succes pe crate-urile hello_macro și hello_macro_derive. Să integăm aceste crate-uri cu codul din Listarea 19-30 pentru a vedea macrocomanda procedurală în acțiune! Creează un nou proiect binar în directoriul tău projects folosind comanda cargo new pancakes. Este necesar să adăugăm hello_macro și hello_macro_derive ca dependențe în fișierul Cargo.toml al crate-ului pancakes. Dacă vei publica versiunile tale de hello_macro și hello_macro_derive pe crates.io, acestea vor fi dependențe obișnuite; în caz contrar, poți să le specifici ca dependențe de tip path în modul următor:
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Adaugă codul din Listarea 19-30 în fișierul src/main.rs și execută comanda cargo run: ar trebui să afișeze mesajul Hello, Macro! My name is Pancakes! Implementarea trăsăturii HelloMacro, provenită din macrocomanda procedurală, a fost inclusă fără ca librăria pancakes să fie nevoită să o implementeze manual; atributul #[derive(HelloMacro)] a adăugat automat implementarea trăsăturii.
În pasul următor, vom descoperi în ce mod se diferențiază celelalte tipuri de macrocomenzi procedurale față de macrocomenzile custom derive.
Macrocomenzile de tip atribut
Macrocomenzile tip atribut sunt similare cu macrocomenzile personalizate de derive, însă spre deosebire de generarea de cod pentru atributul derive, ele permit crearea de atribute noi. Acestea sunt și mai versatile: derive funcționează exclusiv pentru structuri și enum-uri; atributele pot fi utilizate și pentru alte elemente, cum ar fi funcții. De exemplu, să presupunem că deții un atribut denumit route, care adnotează funcțiile atunci când lucrezi cu un framework pentru aplicații web:
#[route(GET, "/")]
fn index() {Atributul #[route] ar fi definit de către framework sub formă de o macrocomandă procedurală. Semnătura funcției care definește macrocomanda va arăta astfel:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {Aici avem doi parametri de tipul TokenStream. Primul este pentru conținutul atributului, adică partea cu GET, "/". Cel de-al doilea este corpul entității căreia i s-a atașat atributul: în acest caz, fn index() {} și restul corpului funcției.
În rest, macrocomenzile tip atribut funcționează în aceeași manieră ca și macrocomenzile de derive personalizate: creezi un crate de tip proc-macro și implementezi o funcție care generează codul dorit!
Macrocomenzi de tip funcție
Macrocomenzile de tip funcție definesc macrocomenzi care seamănă cu apelurile de funcții. Asemenea macrocomenzilor macro_rules!, sunt mai flexibile decât funcțiile; spre exemplu, pot accepta un număr variabil de argumente. Însă, macrocomenzile macro_rules! pot fi definite doar folosind sintaxa asemănătoare match-ului despre care am discutat în secțiunea „Macrocomenzi declarative cu macro_rules! pentru metaprogramare generală”. Macrocomenzile de tip funcție primesc un parametru TokenStream și manipulează acest TokenStream folosind cod Rust, asemenea celorlalte două tipuri de macrocomenzi procedurale. Un exemplu de macrocomandă de tip funcție ar fi macrocomanda sql!, care ar putea fi folosită în felul următor:
let sql = sql!(SELECT * FROM posts WHERE id=1);Această macrocomandă ar analiza instrucțiunea SQL conținută și ar verifica dacă este sintactic corectă, o complexitate de prelucrare ce depășește posibilitățile unei macrocomenzi macro_rules!. Macrocomanda sql! ar fi definită în felul următor:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {Această definiție prezintă similarități cu semnătura unei macrocomenzi pentru derive personalizat: primim tokenii care sunt între paranteze și returnăm codul pe care dorim să-l generăm.
Sumar
Ei bine! Acum în trusa ta de unelte ai câteva funcționalități Rust pe care nu le vei utiliza des, însă, în situații foarte specifice, vei ști că-ți sunt la dispoziție. Am abordat câteva subiecte complexe astfel încât, atunci când te vei întâlni cu ele în sugestiile de eroare ale mesajelor sau în codul altor persoane, să poți recunoaște aceste concepte și sintaxa aferentă. Utilizează acest capitol ca un ghid de referință care să te ajute să găsești soluții.
Următorul pas este să punem în aplicare tot ceea ce am învățat de-a lungul cărții și să lucrăm la un nou proiect!
Proiect final: Dezvoltarea unui server web multi-thread
Drumul parcurs a fost lung, dar în final, am ajuns la ultimul capitol al cărții. În acest capitol, ne vom uni forțele pentru a construi încă un proiect, prin care să demonstrăm câteva din conceptele pe care le-am abordat în capitolele anterioare și să recapitulăm lecțiile învățate.
Pentru proiectul nostru de final, vom dezvolta un server web care va afișa un simplu “hello” și va arăta precum Figura 20-1 în browser-ul web.
Figura 20-1: Proiectul nostru final comun
Iată pașii pe care îi vom urma pentru a construi serverul web:
- O scurtă introducere în TCP și HTTP.
- Interceptarea conexiunilor TCP printr-un socket.
- Analiza unui set redus de cereri HTTP.
- Generarea unui răspuns HTTP adecvat.
- Creșterea capacității de procesare a serverului nostru printr-un pool de thread-uri.
Înainte de a începe, este important să punctăm un aspect: calea pe care o vom urma în acest proiect nu reprezintă cea mai eficace metodă de a construi un server web cu Rust. Membri ai comunității au publicat o varietate de crate-uri gata pentru producție, disponibile pe crates.io, care prezintă implementări mai avansate pentru servere web și thread pools decât varianta pe care o vom dezvolta noi. Totuși, intenția noastră în acest capitol este de a facilita procesul de învățare, și nu de a urma soluția cea mai simplă. Fiind un limbaj de programare de sistem, Rust ne oferă libertatea de a alege nivelul de abstractizare la care dorim să lucrăm, ceea ce ne permite să ne aplecăm către detalii de nivel mai jos decât ne-ar permite alte limbaje. Așadar, vom construi de la zero serverul HTTP de bază și pool-ul de thread-uri, pentru ca tu să asimilezi conceptele fundamentale și tehnicile din spatele crate-urilor pe care le poți eventual utiliza în viitor.
Construirea unui server web cu un singur fir de execuție
Vom începe prin a pune în funcțiune un server web care rulează pe un singur fir de execuție (sau thread). Înainte de a ne apuca de treabă, să aruncăm o privire sumară asupra protocoalelor implicate în construcția serverelor web. Detaliile profunde ale acestor protocoale depășesc scopul acestei cărți, dar o înțelegere elementară ne va furniza cunoștințele necesare.
Principalele două protocoale folosite în serverele web sunt Hypertext Transfer Protocol (HTTP) și Transmission Control Protocol (TCP). Acestea sunt protocoale de tip request-response, prin care un client inițiază solicitări iar un server le recepționează și furnizează un răspuns corespunzător clientului. Conținutul specific al cererilor și răspunsurilor este stipulat de către aceste protocoale.
TCP este protocolul de fundament, ce explică mecanismele de transfer al informațiilor între servere, fără a detalia natura acestor informații. Pe de altă parte, HTTP se suprapune peste TCP, stabilind conținutul specific al solicitărilor și răspunsurilor. Deși este posibilă utilizarea HTTP în conjuncție cu alte protocoale, în majoritatea covârșitoare a situațiilor, HTTP își expediază datele prin TCP. Vom lucra direct cu octeții nealterați ai cererilor și răspunsurilor oferite de TCP și HTTP.
Ascultarea unei conexiuni TCP
Serverul nostru web trebuie să fie capabil să asculte o conexiune TCP, iar aceasta este prima parte la care ne vom concentra. Biblioteca standard ne oferă un modul std::net prin care putem realiza acest lucru. Să creăm un nou proiect în modul obișnuit:
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
Introdu acum codul din Listarea 20-1 în fișierul src/main.rs ca punct de pornire. Acest cod va asculta la adresa locală 127.0.0.1:7878 pentru fluxurile TCP care sosesc. Când un astfel de flux e detectat, programul va afișa mesajul Connection established!.
use std::net::TcpListener; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); println!("Connection established!"); } }...
Listarea 20-1: Ascultarea fluxurilor TCP și afișarea unui mesaj la primirea unui flux
Utilizând TcpListener, putem asculta conexiuni TCP la adresa 127.0.0.1:7878. În această adresă, partea dinaintea celor două puncte : este o adresă IP ce reprezintă computerul tău (fiind același IP pe toate computerele, el nu reprezintă un IP specific autorilor cărții), iar 7878 este portul utilizat. Am ales acest port din două motive: în mod normal HTTP nu operează pe acest port, așadar este improbabil ca serverul nostru să între în conflict cu alte servere web care ar putea fi active pe computerul tău, și 7878 reprezintă cuvântul rust pe tastatura unui telefon.
Funcția bind, în acest context, funcționează similar cu funcția new în sensul că va returna o nouă instanță TcpListener. Se numește bind (engl. a lega) pentru că în terminologia de rețea, procesul de a asculta un port este cunoscut ca „asocierea cu un port” ("binding to a port").
Funcția bind returnează un Result<T, E>, sugerând că există posibilitatea ca asocierile să fie nereușite. De exemplu, pentru a asculta pe portul 80 sunt necesare privilegii de administrator (non-administratorii pot asculta doar pe porturi mai mari de 1023), deci dacă am încerca să ascultăm pe portul 80 fără a fi administratori, asocierea nu ar reuși. Asocierea ar eșua de asemenea dacă am rula două instanțe ale programului nostru și astfel două programe ar asculta același port. Întrucât construim un server simplu doar în scop educațional, nu ne vom preocupa de gestionarea acestor tipuri de erori; în schimb, vom folosi unwrap pentru a opri programul dacă ele apar.
Metoda incoming de pe TcpListener ne întoarce un iterator care ne oferă o secvență de fluxuri (mai exact, fluxuri de tip TcpStream). Un singur flux constituie o conexiune deschisă între client și server. O conexiune este denumirea pentru tot procesul de cerere și răspuns, în care clientul se conectează la server, serverul generează un răspuns și apoi serverul închide conexiunea. Astfel, vom citi din TcpStream pentru a afla ce a trimis clientul și vom scrie răspunsul nostru în flux pentru a transmite datele înapoi clientului. Per total, acest ciclu for va procesa fiecare conexiune pe rând, producând o serie de fluxuri pe care trebuie să le gestionăm.
Pentru moment, gestionarea fluxului se rezumă la utilizarea funcției unwrap pentru a opri programul nostru dacă fluxul întâmpină erori; dacă nu există erori, programul va afișa un mesaj. Vom extinde funcționalitatea pentru situația de succes în următoarea listare. Motivul pentru care s-ar putea să primim erori de la metoda incoming atunci când un client încearcă să se conecteze la server este faptul că nu iterăm propriu-zis peste conexiuni, ci peste încercări de conectare. Conexiunea poate eșua din diverse motive, multe fiind specifice sistemului de operare. De exemplu, multe sisteme de operare limitează numărul de conexiuni deschise simultan pe care le pot suporta; încercările de a stabili noi conexiuni peste acest număr vor rezulta într-o eroare până când anumite conexiuni deschise sunt închise.
Să încercăm să executăm acest cod! Rulează cargo run în terminal, apoi deschide 127.0.0.1:7878 într-un browser web. Browserul ar trebui să afișeze un mesaj de eroare cum ar fi "Conexiunea s-a resetat", deoarece serverul, în acest moment, nu trimite niciun fel de date înapoi. Dar, privind în terminal, ar trebui să observi mai multe mesaje care s-au afișat când browserul s-a conectat la server!
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
Uneori, ai putea observa că sunt afișate mai multe mesaje pentru o singură cerere făcută de browser; cauza ar putea fi aceea că browserul solicită atât pagina, cât și alte resurse, precum iconița favicon.ico care apare în tab-ul browserului.
De asemenea, este posibil ca browserul să încerce să se conecteze de mai multe ori la server deoarece serverul nu transmite nicio dată. Atunci când stream iese din domeniul de vizibilitate și este abandonat la sfârșitul buclei, conexiunea se închide automat, acesta fiind parte a comportamentului metodei drop. Browserul poate gestiona astfel de conexiuni închise prin efectuarea de noi încercări, presupunând că problema ar putea fi una temporară. Elementul cheie este că am obținut cu succes un descriptor pentru o conexiune TCP!
Nu uita să oprești programul apăsând ctrl-c când ai finalizat rularea unei versiuni particulare de cod. Ulterior, repornește programul utilizând comanda cargo run după aplicarea fiecărui set de schimbări în cod, pentru a te asigura că rulezi versiunea actualizată a codului.
Citirea cererii
Să implementăm funcționalitatea pentru citirea cererii din partea browserului! Pentru a separa responsabilitățile de a obține mai întâi o conexiune și apoi a face o acțiune cu acea conexiune, vom iniția o nouă funcție de procesare a conexiunilor. În această nouă funcție handle_connection, vom citi date din fluxul TCP și le vom afișa pentru a vedea informațiile trimise de browser. Actualizează codul să corespundă cu Listarea 20-2.
Numele fișierului: src/main.rs
use std::{ io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); println!("Request: {:#?}", http_request); }
Listarea 20-2: Citirea datelor din TcpStream și afișarea lor
Introducem în context std::io::prelude și std::io::BufReader pentru a obține acces la trăsăturile și tipurile care ne permit să citim și să scriem pe flux. În bucla for din funcția main, în loc să afișăm un mesaj care să confirme că s-a realizat o conexiune, acum invocăm noua funcție handle_connection și îi pasăm stream-ul.
În interiorul funcției handle_connection, creăm o nouă instanță de BufReader care cuprinde o referință mutabilă către stream. BufReader adaugă un buffer prin gestionarea apelurilor la metodologiile trăsăturii std::io::Read.
Definim o variabilă numită http_request pentru a acumula liniile cererii pe care browserul le trimite către serverul nostru. Specificăm că dorim să adunăm aceste linii într-un vector prin adăugarea adnotării de tip Vec<_>.
BufReader implementează trăsătura std::io::BufRead, care pune la dispoziție metoda lines. Metoda lines furnizează un iterator de Result<String, std::io::Error>, despărțind fluxul de date la fiecare întâlnire a unui octet de sfârșit de linie. Pentru a extrage fiecare String, aplicăm map și unwrap la fiecare Result. Result poate fi o eroare dacă datele nu sunt UTF-8 valide sau dacă a apărut o problemă în timpul citirii de pe flux. Într-un context de producție, ar trebui abordate aceste erori mai elegant, dar optăm pentru simplificare prin oprirea programului în cazul unei erori.
Browserul indică sfârșitul unei cereri HTTP trimițând două caractere de tip newline în succesiune, așadar pentru a extrage o cerere din flux, citim liniile până când întâlnim o linie care este un string gol. După ce am adunat liniile în vector, le afișăm utilizând formatarea de debug, astfel încât să putem analiza instrucțiunile pe care browserul web le trimite serverului nostru.
Să încercăm acest cod! Pornim programul și facem o cerere în browserul web din nou. Observă că în browser vom întâlni în continuare o pagină de eroare, dar ieșirea programului nostru în terminal va arăta acum similar cu acesta:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
În funcție de browserul tău, este posibil să obții un output ușor diferit. Acum că afișăm datele cererii, putem determina motivele pentru care primim multiple conexiuni dintr-o singură cerere de browser analizând calea după GET din prima linie a cererii. Dacă conexiunile repetate sunt toate pentru calea */*, înseamnă că browserul încearcă să acceseze */* de mai multe ori deoarece nu primește un răspuns de la programul nostru.
În continuare să analizăm aceste date pentru a înțelege mai bine ce solicită browserul de la programul nostru.
Examinăm mai detaliat o cerere HTTP
HTTP este un protocol bazat pe text și o cerere are formatul următor:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
Prima linie reprezintă linia de cerere și conține informații despre ce solicită clientul. Prima parte a liniei de cerere precizează metoda utilizată, precum GET sau POST, ce descrie cum clientul efectuează această cerere. Clientul nostru a folosit o cerere de tip GET, ceea ce semnifică că el solicită informații.
Următorul segment al liniei de cerere este /, care indică Uniform Resource Identifier (URI) pe care clientul dorește să-l acceseze. Un URI este similar, dar nu identic cu un Uniform Resource Locator (URL). Distincția dintre URI și URL nu este semnificativă în contextul acestui capitol, însă specificația HTTP utilizează termenul URI, astfel putem înlocui mental termenul URL pentru URI.
Ultimul segment este versiunea HTTP folosită de client și apoi linia de cerere se încheie cu o secvență CRLF. (CRLF înseamnă carriage return și line feed, termeni din epoca mașinilor de scris!) Secvența CRLF poate fi, de asemenea, reprezentată prin \r\n, unde \r este carriage return și \n este line feed. Secvența CRLF separă linia de cerere de restul datelor cererii. De remarcat că atunci când CRLF este afișat, începe o linie nouă în loc să vedem \r\n.
Analizând datele liniei de cerere pe care le-am obținut până în acest moment prin rularea programului nostru, observăm că GET este metoda, / este URI-ul solicitat și HTTP/1.1 este versiunea utilizată.
După linia de cerere, următoarele linii începând cu Host: și continuând sunt anteturile, sau header-ele. Cererile de tip GET nu includ un corp.
Încearcă să faci o cerere folosind un alt browser sau solicitând o adresă diferită, de exemplu, 127.0.0.1:7878/test, pentru a vedea cum se modifică datele cererii.
Acum că înțelegem ce solicită browser-ul, să-i răspundem cu unele date!
Scrierea unui răspuns
Pornim să implementăm transmiterea de date ca răspuns la o solicitare din partea clientului. Răspunsurile urmează acest format:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
Prima linie, cunoscută ca linie de status, include versiunea HTTP utilizată în răspuns, un cod de status numeric ce sumarizează rezultatul solicitării și o frază explicativă ce oferă o descriere în text a codului de status. După secvența CRLF, urmează anteturile, încă o secvență CRLF și corpul răspunsului.
Avem aici un exemplu de răspuns folosind versiunea HTTP 1.1, cu un cod de status 200, o frază OK explicativă, fără anteturi și fără corp:
HTTP/1.1 200 OK\r\n\r\n
Status code 200 reprezintă răspunsul standard pentru o operațiune de succes. Acest text este un mic exemplu de răspuns HTTP reușit. Să trimitem acest răspuns în fluxul nostru ca reacție la o solicitare îndeplinită cu succes! În funcția handle_connection, eliminăm comanda println! care afișa datele solicitării și o înlocuim cu codul din Listarea 20-3.
Filename: src/main.rs
use std::{ io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let response = "HTTP/1.1 200 OK\r\n\r\n"; stream.write_all(response.as_bytes()).unwrap(); }
Listarea 20-3: Crearea unui răspuns HTTP succint și eficient în fluxul de date
Prima linie nouă stabilește variabila response care conține datele mesajului nostru de succes. În continuare, folosim as_bytes pe response pentru a converti string-ul în octeți. Metoda write_all de pe stream acceptă un &[u8] și trimite acești octeți direct prin conexiune. Folosim unwrap pentru a gestiona eventualele erori ce pot apărea în timpul operației write_all, ca și în cazurile anterioare. Desigur, într-o aplicație reală ar fi necesară implementarea unei gestionări adecvate a erorilor.
Cu aceste modificări implementate, să rulăm codul și să inițiem o solicitare. Cum nu vom mai afișa date în terminal, singura ieșire vizibilă va fi cea de la Cargo. Accesând într-un browser adresa 127.0.0.1:7878, ar trebui să apară o pagină albă, semn că nu mai există nicio eroare. Felicitări, tocmai ai realizat manual o solicitare HTTP și ai trimis un răspuns corespunzător!
Returnarea de HTML real
Să dezvoltăm funcționalitatea de a returna mai mult decât o simplă pagină goală. Creează noul fișier hello.html în rădăcina directoriului tău de proiect, nu în directorul src. Poți introduce orice cod HTML dorești; în Listarea 20-4 este prezentată o variantă.
Numele fișierului: hello.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
Listarea 20-4: Un exemplu de fișier HTML pentru a fi returnat ca răspuns
Acesta este un document minimal HTML5 cu un titlu și ceva text. Pentru a-l returna de pe server atunci când se primește o cerere, vom modifica handle_connection conform celor prezentate în Listarea 20-5 pentru a citi fișierul HTML, adăugându-l la răspuns în calitate de corp, apoi trimițându-l.
Numele fișierului: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; // --snip-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listarea 20-5: Trimiterea conținutului fișierului hello.html ca parte a corpului răspunsului
Am introdus fs în instrucțiunea use pentru a aduce modulul de sistem de fișiere din biblioteca standard în sfera noastră de aplicabilitate. Codul pentru citirea conținuturilor unui fișier într-un string ți-ar putea fi cunoscut; l-am utilizat în Capitolul 12 când am citit conținuturile unui fișier pentru proiectul nostru I/O, prezentate în Listarea 12-4.
Apoi, utilizăm format! pentru a include conținutul fișierului ca parte a corpului răspunsului de succes. Pentru a asigura un răspuns HTTP valid, includeem antetul Content-Length, care este stabilit la dimensiunea corpului nostru de răspuns, în acest caz dimensiunea lui hello.html.
Execută acest cod folosind cargo run și accesează 127.0.0.1:7878 în browser; ar trebui să îți vezi codul HTML afișat!
În momentul de față, ignorăm datele din cererea http_request și pur și simplu returnăm conținutul fișierului HTML indiferent de alți parametri. Acest lucru înseamnă că dacă încerci să accesezi 127.0.0.1:7878/ceva-altceva în browserul tău, vei primi același răspuns HTML. În stadiul actual, serverul nostru este destul de limitat și nu efectuează operațiunile pe care le realizează majoritatea serverelor web. Vrem să personalizăm răspunsurile noastre în funcție de cereri și să returnăm fișierul HTML doar pentru cereri corect formulate spre /.
Validarea cererii și răspuns selectiv
Deocamdată, serverul nostru web va returna codul HTML din fișier indiferent de solicitarea clientului. Să introducem o funcționalitate care să verifice dacă navigatorul web solicită / înainte de a oferi fișierul HTML și să trimitem o eroare dacă se solicită altceva. Pentru acest lucru, este necesar să modificăm handle_connection, așa cum e ilustrat în Listarea 20-6. Acest cod nou compară conținutul cererii primite cu formatul unei cereri pentru / și utilizează construcții if și else pentru a gestiona diferit cererile.
Numele fișierului: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } // --snip-- fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } else { // some other request } }
Listarea 20-6: Gestionarea diferită a cererilor la / în comparație cu alte cereri
Ne vom concentra doar asupra primei linii din cererea HTTP, astfel, în loc să citim întreaga cerere într-un vector, folosim next pentru a accesa primul element din iterator. Primul unwrap tratează Option și oprește execuția programului dacă iteratorul nu conține niciun element. Al doilea unwrap se ocupă de Result, având același rol ca unwrap-ul adăugat în map din Listarea 20-2.
În continuare, verificăm dacă request_line corespunde cu linia specifică unei cereri GET către calea /. Dacă este așa, blocul if furnizează conținutul fișierului nostru HTML.
Dacă request_line nu corespunde cu cererea GET către calea /, atunci e clar că am primit o solicitare diferită. Vom adăuga cod blocului else în curând, pentru a răspunde la orice altă cerere.
Execută acest cod acum și accesează 127.0.0.1:7878; ar trebui să primești codul HTML din hello.html. Dacă inițiezi o cerere diferită, de exemplu la 127.0.0.1:7878/ceva-altceva, te vei confrunta cu o eroare de conexiune similară cu cea întâlnită atunci când codul din Listarea 20-1 și Listarea 20-2 era executat.
Acum să includem codul din Listarea 20-7 în blocul else pentru a emite un răspuns cu codul de status 404, semnalând astfel că nu a fost găsit conținutul solicitat. De asemenea, vom returna un HTML pentru o pagină ce va fi afișată în browser, indicând utilizatorului final acest răspuns.
Numele fișierului: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); // --snip-- } else { let status_line = "HTTP/1.1 404 NOT FOUND"; let contents = fs::read_to_string("404.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } }
Listarea 20-7: Emiterea unui răspuns cu codul de status 404 și o pagină de eroare când se solicită altceva în loc de /
Aici, linia de status a răspunsului nostru include codul de status 404 și fraza NOT FOUND. Corpul răspunsului va reprezenta HTML-ul conținut în fișierul 404.html. Trebuie să creezi un fișier 404.html în directoriul fișierului hello.html pentru pagina de eroare; ești liber să folosești orice cod HTML vrei sau să preiei exemplul de HTML din Listarea 20-8.
Numele fișierului: 404.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
Listarea 20-8: Conținut exemplu pentru pagina returnată odată cu răspunsul de 404
După aceste actualizări, rulează din nou serverul tău. Accesarea 127.0.0.1:7878 ar trebui să îți prezinte conținutul din hello.html, iar orice altă solicitare, precum 127.0.0.1:7878/foo, va genera răspunsul HTML de eroare din 404.html.
Un strop de refactorizare
La momentul actual, blocurile if și else conțin mult cod repetitiv: amândouă citesc fișiere și scriu conținutul în flux. Diferențele sunt doar linia de status și numele fișierului. Vom simplifica codul, extrăgând aceste diferențe în linii de if și else separate, care vor atribui valorile pentru linia de status și numele fișierului la variabile; apoi vom utiliza variabilele pentru a citi fișierul și a scrie răspunsul în mod necondiționat. Listarea 20-9 prezintă codul rezultat după înlocuirea blocurilor mari de if și else.
Numele fișierului: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } // --snip-- fn handle_connection(mut stream: TcpStream) { // --snip-- let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = if request_line == "GET / HTTP/1.1" { ("HTTP/1.1 200 OK", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listarea 20-9: Refactorizarea blocurilor if și else pentru a conține numai codul care diferă între cele două cazuri
În prezent, blocurile if și else returnează valorile potrivite pentru linia de status și numele fișierului sub formă de tuplă; apoi folosim destructurarea pentru a atribui aceste valori variabilelor status_line și filename, utilizând un pattern în instrucțiunea let, după cum a fost discutat în Capitolul 18.
Codul care era duplicat anterior este acum plasat în afara blocurilor if și else și utilizează variabilele status_line și filename. Aceasta ne facilitează observarea diferențelor dintre cele două cazuri și înseamnă că avem acum un singur punct unde trebuie să facem modificări dacă dorim să schimbăm modul de citire a fișierelor și de redactare a răspunsurilor. Comportamentul codului din Listarea 20-9 este identic cu cel din Listarea 20-8.
Extraordinar! Deținem acum un server web simplu în aproximativ 40 de linii de cod Rust, care răspunde la o cerere cu o pagină de conținut și la toate celelalte cereri cu un răspuns 404.
Serverul nostru operează momentan într-un singur fir de execuție, ceea ce implică faptul că poate procesa o singură solicitare consecutiv. Să explorăm cum acest aspect poate deveni o problemă simulând câteva cereri lente. Pe urmă, vom îmbunătăți serverul astfel încât să poată gestiona multiple cereri în paralel.
Transformarea serverului nostru single-threaded într-unul multithreaded
În starea actuală, serverul nostru procesează fiecare cerere succesiv, ceea ce înseamnă că nu va gestiona o altă conexiune până când nu termină de procesat prima. Dacă serverul se confruntă cu un număr mare de cereri, această metodă de execuție secvențială devine tot mai puțin eficientă. Mai mult, dacă serverul întâmpină o cerere ce necesită timp îndelungat pentru procesare, cererile ulterioare trebuie să aștepte finalizarea acesteia, chiar dacă ar putea fi procesate rapid. Acesta este un aspect pe care trebuie să-l îmbunătățim, dar înainte de asta, să analizăm problema în detaliu.
Simularea unei solicitări lente în implementarea actuală a serverului
Să examinăm cum o solicitare care se procesează lent poate influența alte solicitări transmise serverului nostru actual. Listarea 20-10 ilustrează gestionarea unei solicitări către adresa /sleep cu un răspuns lent simulat, care va cauza serverului să execute un somn de 5 secunde înainte de a răspunde.
Numele fișierului: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, thread, time::Duration, }; // --snip-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { // --snip-- let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; // --snip-- let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listarea 20-10: Simularea unei solicitări lente prin dormit timp de 5 secunde
Am trecut de la utilizarea if la match, deoarece acum avem de-a face cu trei scenarii diferite. Este necesar să realizăm potriviri explicite asupra unei secțiuni din request_line pentru a se potrivi cu valorile literale string; match nu realizează referențierea și dereferențierea automată, cum o face metoda de egalitate.
Primul caz este la fel ca blocul if din Listarea 20-9. Al doilea caz corespunde unei solicitări către /sleep. Când se primește aceasta, serverul va aștepta 5 secunde înainte de a reda pagina HTML de succes. Cazul al treilea este identic cu blocul else din Listarea 20-9.
Putem vedea natura simplistică a serverului nostru: biblioteci reale ar trata recunoașterea multiplelor solicitări într-un mod mult mai eficient și concis!
Pentru a iniția serverul, folosește cargo run. Apoi, deschide două ferestre de browser: una pentru http://127.0.0.1:7878/ și cealaltă pentru http://127.0.0.1:7878/sleep. Dacă accesezi URI-ul / de mai multe ori, la fel ca anterior, va răspunde rapid. Dar dacă accesezi /sleep și apoi încarci /, observi că / va aștepta finalizarea celor 5 secunde de somn a funcției sleep înainte să se încarce.
Există mai multe tehnici pe care le-ar putea folosi pentru a evita întârzierea solicitărilor din cauza unei alte solicitări lente; vom alege să implementăm un pool de fire de execuție.
Lărgirea capacității de bandă cu un pool de fire de execuție
Un thread pool este un ansamblu de fire de execuție inițializate și în așteptare de sarcini. Când programul detectează o nouă sarcină, alocă un fir din pool pentru gestionarea acesteia, care o va prelucra. Celelalte fire rămân disponibile pentru orice alte sarcini care apar în timp ce primul fir este ocupat. După finalizarea sarcinii, firul revine în pool-ul de fire inactive, pregătit pentru o nouă provocare. Astfel, thread pool-ul facilitează procesarea concurentă a conexiunilor, sporind capacitatea de bandă a serverului.
Vom limita numărul de fire de execuție din pool pentru a ne proteja împotriva atacurilor de tipul Denial of Service (DoS); altfel, creând un fir nou pentru fiecare cerere, un atacator care trimite milioane de cereri ar putea să epuizeze resursele serverului, blocând procesarea acestora.
Deci, în loc de a avea un număr nelimitat de fire, vom menține un număr fix de fire în așteptare în pool. Sosirea unei cereri conduce la direcționarea acesteia spre pool pentru prelucrare, unde există o coadă de cereri în așteptarea gestiunii. Fiecare fir din pool preia o cerere din coadă, o gestionează și apoi solicită o altă cerere. Prin această abordare, putem procesa concurent până la N cereri, unde N este numărul de fire. Aceasta crește numărul de cereri de lungă durată pe care le putem prelucra înainte de a se forma o coadă de așteptare.
Metoda dată este una dintre multele strategii de îmbunătățire a capacității unui server web. Alte opțiuni demne de luat în considerare sunt modelul fork/join, modelul single-threaded async I/O, sau modelul multi-threaded async I/O. Dacă domeniul te pasionează, e bine de știut că Rust, ca limbaj de nivel scăzut, face posibilă explorarea și implementarea acestor alternative.
Înainte să trecem la construirea unui thread pool, să examinăm cum ar trebui să arate interacțiunea cu acesta. În etapa de proiectare a codului, construirea în prealabil a interfeței cu utilizatorul poate servi ca un bun ghid pentru design. Concepe API-ul astfel încât să se potrivească cu modul în care vrei să-l utilizezi; apoi dezvoltă funcționalitatea în acest cadru, în loc să creezi funcționalitățile și pe urmă să te ocupi de API.
Similar cu dezvoltarea ghidată de teste din proiectul Capitolului 12, vom folosi aici dezvoltarea ghidată de compilator. Vom scrie cod ce cheamă funcțiile dorite și vom corecta erorile indicate de compilator pentru a avansa spre o implementare funcțională. Dar înainte de asta, să explorăm o tehnică pe care nu o vom adopta în calitate de punct de plecare.
Crearea unui fir de execuție pentru fiecare cerere
Să explorăm cum ar arăta codul nostru dacă ar genera un nou fir de execuție pentru fiecare conexiune. După cum am explicat anterior, aceasta nu este soluția finală datorită complicațiilor care ar apărea prin crearea unui număr nelimitat de fire de execuție, însă este un punct de start pentru a realiza mai întâi un server funcțional multithreaded. Apoi, vom adăuga un thread pool ca o îmbunătățire, iar compararea celor două abordări va fi mai simplă. Listarea 20-11 ilustrează modificările necesare în main pentru a crea un nou fir de execuție care să proceseze fiecare stream în cadrul buclei for.
Numele fișierului: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, thread, time::Duration, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); thread::spawn(|| { handle_connection(stream); }); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listarea 20-11: Crearea unui nou fir de execuție pentru fiecare stream
După cum ai învățat în Capitolul 16, thread::spawn va crea un nou fir de execuție și va executa codul din încheiere în acest nou fir. Dacă rulezi acest cod și accesezi
/sleep în browser-ul tău, apoi / în alte două tab-uri, vei vedea că cererile către / nu trebuie să aștepte finalizarea cererii către /sleep. Cu toate acestea, așa cum am menționat, această metodă poate în cele din urmă să suprasolicite sistemul prin crearea continuă de noi fire de execuție fără niciun fel de limită.
Crearea unui număr finit de fire de execuție
Scopul nostru este ca pool-ul de fire să fie intuitiv și să funcționeze în mod similar cu firele de execuție individuale, astfel încât să nu fie necesare ajustări majore în codul sursă care interacționează cu API-ul creat de noi. Listarea 20-12 ilustrează interfața ideală pentru structura ThreadPool pe care dorim să o adoptăm în locul folosirii thread::spawn.
Numele fișierului: src/main.rs
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Listarea 20-12: Interfața vizată pentru ThreadPool
Utilizăm ThreadPool::new pentru a pune la punct un pool nou de fire de execuție cu un număr de fire pe care îl putem configura, aici exemplificând cu patru. Mai departe, în bucla for, pool.execute propune o interfață similară cu cea a lui thread::spawn, primind o închidere care urmează a fi executată de pool individual pentru fiecare flux. Este necesar să definim pool.execute astfel încât să preia închiderea și să o repartizeze către un fir din pool pentru execuție. Deocamdată codul nu este compilabil, însă o vom încerca pentru ca compilatorul să ne poată îndruma spre soluționarea problemelor.
Construirea unui ThreadPool prin dezvoltare ghidată de compilator
Aplică modificările din Listarea 20-12 în src/main.rs, după care să utilizăm erorile de compilator de la cargo check ca ghid în procesul nostru de dezvoltare. Iată prima eroare care ne apare:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` due to previous error
Minunat! Această eroare ne indică faptul că avem nevoie de un tip sau modul denumit ThreadPool, deci e momentul să construim unul. Implementarea ThreadPool va fi realizată independent de tipul de muncă pe care serverul nostru web îl execută. Astfel, să convertim crate-ul hello dintr-un crate tip binar într-unul de tip bibliotecă, pentru a include implementarea ThreadPool. Odată ce am trecut la un crate de tip bibliotecă, am putea folosi biblioteca de pool de fire de execuție și pentru alte munci la care am avea nevoie de un pool de fire de execuție, nu doar pentru prelucrarea cererilor web.
Creează un fișier src/lib.rs care să conțină următoarea definiție, care este cel mai simplu exemplu al structurii ThreadPool pe care îl putem avea în acest moment:
Numele fișierului: src/lib.rs
pub struct ThreadPool;Acum, editează fișierul main.rs pentru a aduce ThreadPool în domeniul de vizibilitate din crate-ul de tip bibliotecă adăugând următorul cod la partea de sus a src/main.rs:
use hello::ThreadPool;
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Acest cod nu va funcționa încă, dar să facem încă o verificare pentru a primi următoarea eroare ce trebuie abordată:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` due to previous error
Această eroare ne arată că trebuie să creăm în continuare o funcție asociată numită new pentru ThreadPool. De asemenea, înțelegem că funcția new trebuie să aibă un parametru ce acceptă 4 ca argument și care să returneze o instanță de ThreadPool. Să implementăm cea mai simplă versiune a funcției new, care să corespundă acestor cerințe:
Filename: src/lib.rs
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}Am ales tipul usize pentru parametrul size, deoarece este clar că un număr negativ de fire de execuție nu ar avea sens. În plus, știm că acest număr 4 va fi folosit pentru a reprezenta cantitatea de elemente într-o colecție de fire de execuție, acesta fiind rolul tipului usize, după cum am discutat în secțiunea [“Tipurile de întregi”][integer-types] din Capitolul 3.
Să examinăm din nou codul:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| ^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` due to previous error
Eroarea apare acum deoarece ThreadPool nu are o metodă execute. Reamintim din secțiunea „Crearea unui număr finit de fire de execuție” că am stabilit ca pool-ul nostru de fire de execuție să aibă o interfață asemănătoare cu thread::spawn. În plus, intenționăm să implementăm funcția execute într-o manieră care să preia o închidere furnizată și să o aloce unui fir inactiv din pool pentru executare.
Definirea metodei execute pe ThreadPool se va face astfel încât aceasta să primească o închidere ca parametru. Reflectând asupra secțiunii [„Permutarea valorilor capturate din închideri și trăsături Fn”][fn-traits] din Capitolul 13, ținem minte că putem accepta închideri ca parametri utilizând trei trăsături distincte: Fn, FnMut și FnOnce. Acum trebuie să hotărâm care dintre acestea este potrivită în contextul nostru. Având în vedere că vom urma o abordare similară cu cea a implementării thread::spawn din librăria standard, putem examina restricțiile aplicate de semnătura lui thread::spawn asupra parametrului său. Documentația ne evidențiază următoarea formă:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Aici, parametrul de tip F este cel la care ne vom concentra; parametrul de tip T se raportează la valoarea de retur, ce nu constituie un punct de interes în acest context. Observăm că spawn recurge la trăsătura FnOnce ca delimitare pe F. Probabil că aceasta este alegerea corectă pentru noi, întrucât argumentul primit în execute va fi transferat către spawn. Convicția că FnOnce este trăsătura adecvată se întărește de faptul că un fir de execuție destinat procesării unei cereri va rula închiderea respectivă doar o singură dată, conform implicării termenului Once în FnOnce.
Parametrul de tip F are acum și delimitarea de trăsătură Send și delimitarea de durata de viață 'static, esențiale în cazul nostru: Send este necesar pentru a transfera închiderea de la un fir de execuție la altul și 'static este necesar deoarece nu putem determina durata execuției firului. În continuare să implementăm o metodă execute pe ThreadPool care să primească un parametru generic de tip F cu aceste constrângeri:
Numele fișierului: src/lib.rs
pub struct ThreadPool;
impl ThreadPool {
// --snip--
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Continuăm să utilizăm () după FnOnce pentru că acest FnOnce definește o închidere fără parametri și care returnează tipul unit (). Ca și în cazul definițiilor funcțiilor, putem omite tipul de retur din semnătură, dar chiar și în absența parametrilor, avem totuși nevoie de paranteze.
Revenind, aceasta este implementarea cea mai simplificată a metodei execute: nu realizează nimic, însă obiectivul nostru este numai de a verifica compilarea codului. Să verificăm din nou:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.24s
Compilarea reușește! Totuși, vei vedea că dacă rulezi cargo run și inițiezi o cerere în browser, vei întâmpina erorile din browser pe care le-am observat la începutul capitolului. Biblioteca noastră încă nu execută închiderea transmisă metodei execute!
Notă: O expresie pe care o poți auzi în legătură cu limbaje de programare cu compilatoare stricte, cum sunt Haskell și Rust, este „dacă codul compilează, înseamnă că funcționează.” Totuși, acest adagiu nu este valabil universal. Proiectul nostru compilează, însă nu realizează efectiv nimic! Dacă am dezvolta un proiect real și complet, acum ar fi momentul oportun pentru a compune teste unitare pentru a confirma că codul nu doar că compilează, dar și că se comportă așa cum anticipăm.
Validarea numărului de fire de execuție în new
Încă nu am folosit parametrii metodei new și execute. Să realizăm acum implementările acestora conform comportamentului dorit. Începând cu new, mai devreme am optat pentru un tip de date fără semn pentru parametrul size, deoarece ideea unui pool cu un număr negativ de fire de execuție e lipsită de sens. Totuși, un pool cu zero fire este de asemenea ilogic, chiar dacă zero este o valoare perfect validă pentru usize. Vom include un cod care să asigure că size este mai mare ca zero înainte să returnăm o instanță ThreadPool, forțând programul să genereze panică dacă primește zero folosind macrocomanda assert!, conform prezentării din Listarea 20-13.
Numele fișierului: src/lib.rs
pub struct ThreadPool;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Listarea 20-13: Implementarea lui ThreadPool::new astfel încât să genereze panică dacă size este zero
Am integrat de asemenea comentarii doc pentru documentarea ThreadPool. Observi că am respectat practicile recomandate pentru documentație, incluzând o secțiune care subliniază situațiile în care funcția noastră poate intra în panică, aspect abordat în Capitolul 14. Încearcă să executați comanda cargo doc --open și să selectezi structura ThreadPool pentru a vedea cum arată documentația generată pentru new!
În loc să folosim macrocomanda assert!, am putea transforma new în build și să returnăm un Result așa cum am procedat cu Config::build în proiectul legat de intrare/ieșire (I/O) din Listarea 12-9. Cu toate acestea, am decis că în acest caz încercarea de a crea un pool de fire de execuție fără fire este o eroare irecuperabilă. Dacă ești în căutarea unei provocări, încearcă să scrii o metodă denumită build cu următoarea semnătură pentru a o compara cu metoda new:
pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> {Crearea spațiului pentru stocarea firelor de execuție
Acum, că avem o metodă de a verifica dacă avem un număr valid de fire de execuție pentru a le stoca în pool, putem crea aceste fire și să le stocăm în structura ThreadPool înainte de a o returna. Dar cum „stocăm” un fir de execuție? Să aruncăm din nou o privire la semnătura thread::spawn:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Funcția spawn returnează un JoinHandle<T>, unde T este tipul returnat de închidere. Să încercăm să folosim și JoinHandle și să vedem ce se întâmplă. În cazul nostru, închiderile pe care le pasăm pool-ului de fire sunt responsabile pentru gestionarea conexiunii și nu returnează nimic, astfel T va fi de tipul unit ().
Codul din Listarea 20-14 va compila, dar nu va crea niciun fir de execuție până în acest punct. Am modificat definiția ThreadPool pentru a include un vector de thread::JoinHandle<()>, am inițializat vectorul cu o capacitate de size, am configurat o buclă for pentru a executa un cod ce va crea firele și am returnat o instanță ThreadPool care le include.
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// create some threads and store them in the vector
}
ThreadPool { threads }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Listarea 20-14: Crearea unui vector pentru ThreadPool pentru stocarea firelor de execuție
Am importat std::thread în domeniul de vizibilitate al crate-ului de bibliotecă, deoarece utilizăm thread::JoinHandle ca tip al elementelor din vectorul ThreadPool.
Odată ce se confirmă primirea unei dimensiuni valide, ThreadPool-ul nostru generează un nou vector capabil să conțină size elemente. Funcția with_capacity îndeplinește aceeași sarcină ca şi Vec::new, dar cu un avantaj considerabil: ea alocă spațiul în vector în prealabil. Având în vedere că știm că trebuie să stocăm size de elemente în vector, această alocare inițială este mai eficientă decât utilizarea Vec::new, ce își ajustează mărimea pe măsură ce se adaugă elemente.
Când rulezi din nou cargo check, procesul ar trebui să fie realizat cu succes.
Structura Worker responsabilă de transmiterea codului din ThreadPool către un fir de execuție
În listarea 20-14, în secțiunea buclei for, am deschis subiectul creării firelor de execuție. Vom detalia acum modalitatea efectivă de creare a acestora. Biblioteca standard ne oferă funcționalitatea thread::spawn pentru a genera fire de execuție, prin care thread::spawn anticipează recepționarea unui fragment de cod ce trebuie executat imediat după pornirea firului. Cu toate acestea, cazul nostru este de a inițializa firele de execuție pentru ca acestea să rămână în așteptare, în vederea primirii codului pe care îl vom furniza la un moment ulterior. Abordarea standard a firelor de execuție nu include o astfel de capacitate, ceea ce ne obligă să implementăm manual acest comportament.
Vom obține acest comportament prin integrarea unei noi structuri de date între ThreadPool și firele de execuție, destinată gestionării acestei funcționalități noi. Această structură va purta denumirea de Worker (lucrător), termen des întâlnit în schemele de pooling. Worker-ul preia codul așteptând execuția și îl procesează folosind firul de execuție alocat lui. Gândește-te la bucătarii dintr-un restaurant: aceștia așteaptă comenzi de la clienți și, la sosirea acestora, sunt responsabili pentru prelucrarea și finalizarea lor.
În ThreadPool, în locul unui vector conținând instanțe de JoinHandle<()>, vom include mai degrabă instanțe ale structurii Worker. Fiecare Worker va deține o singură instanță JoinHandle<()>. Vom dezvolta o metodă pe structura Worker ce va accepta o închidere cu cod spre a fi executat, pe care o va expedia firului de execuție activ pentru procesare. În plus, vom atribui fiecărei instanțe de Worker un id, astfel încât să putem distinge cu ușurință între diferiții lucrători ai pool-ului, în contexte de logging sau depanare.
Iată procedura nouă care are loc atunci când inițiem un ThreadPool. Vom implementa codul care expediază închiderea la firul de execuție odată ce avem Worker configurat în această manieră:
- Definește o structură
Workercare posedă unidși unJoinHandle<()>. - Modifică
ThreadPoolpentru a păstra un vector de instanțeWorker. - Creează o funcție
Worker::newcare acceptă un număridși înapoiază o instanțăWorkercare conțineid-ul și un fir de execuție generat cu o închidere goală. - În
ThreadPool::new, utilizează contorul din buclaforpentru a produce unid, creează un nouWorkercu acestidși îl stochează în vector.
Dacă ești dispus de o provocare, încearcă să realizezi aceste modificări de unul singur înainte de a consulta codul din Listarea 20-15.
Ești gata? Aici este Listarea 20-15 care prezintă una dintre modalitățile de a efectua modificările discutate.
Numele fișierului: src/lib.rs
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}Listarea 20-15: Modificarea ThreadPool pentru a include instanțe Worker în loc de a păstra direct fire de execuție
Am modificat numele câmpului din ThreadPool de la threads la workers, deoarece acum include instanțe Worker în loc de instanțe JoinHandle<()>. Utilizăm numărătorul din bucla for ca argument pentru Worker::new și stocăm fiecare Worker nou în vectorul numit workers.
Codul exterior (precum serverul nostru din src/main.rs) nu trebuie să fie conștient de detalii de implementare legate de utilizarea structurii Worker în ThreadPool, de aceea structura Worker și funcția sa new sunt marcate ca private. Funcția Worker::new folosește id-ul primit și reține o instanță JoinHandle<()> care este creată generând un fir de execuție nou cu o închidere goală.
Notă: Dacă sistemul de operare nu reușește să creeze un fir de execuție din cauza lipsei resurselor de sistem,
thread::spawnva genera panică. Asta va provoca generația de panică a întregului server, chiar dacă crearea altor fire de execuție ar putea avea succes. Din motive de simplitate, acest comportament este accpetabil, însă într-o implementare ThreadPool destinată producției, ar fi de preferat să utilizăm [std::thread::Builder][builder] și metoda sa [spawn][builder-spawn], care returneazăResult, în schimb.
Codul se va compila și va reține numărul de instanțe Worker pe care le-am definit ca argument pentru ThreadPool::new. Totuși, încă nu gestionăm închiderea pe care o primim în execute. Să vedem cum putem proceda în continuare.
Trimiterea cererilor către fire de execuție utilizând canale
Problema pe care o abordăm acum este că închiderile oferite lui thread::spawn în acest moment sunt nefuncționale. Obținem închiderea dorită pentru execuție în metoda execute, dar trebuie să furnizăm lui thread::spawn o închidere pentru a o executa atunci când constituim fiecare Worker la inițierea ThreadPool.
Ne dorim ca structurile Worker să recupereze codul ce trebuie rulat dintr-o coadă menținută în ThreadPool și să îl transmită propriului fir pentru execuție.
Canalele care au fost analizate în Capitolul 16, o cale simplă de comunicare între două fire de execuție, se potrivesc excelent pentru necesitatea noastră. Vom utiliza un canal ca și coadă a sarcinilor, iar execute va trimite sarcinile de la ThreadPool spre instanțele de Worker, care la rândul lor vor trimite sarcina către firul de execuție. Iată strategia:
ThreadPoolva iniția un canal și va menține transmițătorul.- Fiecare
Workerva deține receptorul. - Vom crea o structură de tip
Jobcare va conține închiderile pe care intenționăm să le expediem prin canal. - Metoda
executeva livra sarcina preconizată pentru execuție printr-un transmițător. - În cadrul firului său de execuție,
Workerva parcurge receptorul implementând închiderile oricărui sarcini recepționate.
Începem prin a constitui un canal în ThreadPool::new și reținem transmițătorul în instanța ThreadPool, așa cum este ilustrat în Listarea 20-16. Deocamdată, structura Job nu înmagazinează nimic, dar va constitui tipul elementelor ce vor fi transmise prin canal.
Numele fișierului: src/lib.rs
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}Listarea 20-16: Modificarea ThreadPool pentru stocarea transmițătorului unui canal care expediază instanțe de sarcini
În ThreadPool::new, concepem noul nostru canal și alocăm pool-ului păstrarea transmițătorului, care va asigura o compilare de succes.
Să transmitem un receptor al canalului fiecărui lucrător în momentul în care pool-ul de fire de execuție inițiază canalul. Ne propunem să folosim receptorul în firul pe care lucrătorii îl vor genera, așadar vom referi receiver în închidere. Codul prezentat în Listarea 20-17, însă, nu va compila încă.
...Listarea 20-17: Transmiterea receptorului lucrătorilor
Am implementat câteva schimbări mici și simple: pasăm receptorul către Worker::new, după care îl utilizăm în cadrul închiderii.
La verificarea acestui cod, apare următoarea eroare:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` due to previous error
Se încearcă transmiterea receiver către multiple instanțe Worker. Aceasta nu va avea succes, deoarece, așa cum ne amintim din Capitolul 16, implementarea canalului în Rust este configurată pentru mai mulți producători și un singur consumator. Astfel, nu putem duplica simplu partea ce consumă din canal pentru a remedia codul. Nu intenționăm nici să expediem același mesaj la diverși consumatori; intenționăm să avem o listă unică de mesaje procesate de mai mulți lucrători, fiecare mesaj fiind procesat individual.
Mai mult, preluarea unei sarcini din coada canalului presupune modificarea lui receiver, motiv pentru care firele de execuție necesită o cale sigură de a împărți și de a modifica receiver. Altminteri, am putea întâlni situații de concurență, așa cum am discutat în Capitolul 16.
Adusu-ți aminte de conceptul de pointeri inteligenți siguri de fir de execuție abordat în Capitolul 16: pentru a distribui posesiunea între mai multe fire și pentru a permite modificări ale valorii, trebuie să utilizăm Arc<Mutex<T>>. Arc le va permite lucrătorilor să posede receptorul împreună, iar Mutex va garanta că un singur lucrător va prelua o sarcină de la receptor la un moment dat. Listarea 20-18 prezintă ajustările necesare.
...Listarea 20-18: Partajarea receptorului între lucrători, utilizând Arc și Mutex
În funcția ThreadPool::new, așezăm receptorul într-un Arc și un Mutex. Pentru fiecare lucrător nou, replicăm Arc pentru a spori contorul de referințe, permițând lucrătorilor să dețină receptorul comun.
Odată cu aceste modificări, codul se compilează cu succes! Suntem pe calea cea bună!
Implementarea metodei execute
Acum să ne apucăm de implementarea metodei execute pentru ThreadPool. Totodată, transformăm Job dintr-o structură într-un alias de tip pentru un obiect-trăsătură care înglobează tipul închiderii pe care execute o primește. După cum am discutat în secțiunea [„Crearea sinonimelor de tip cu aliasuri de tip”][creating-type-synonyms-with-type-aliases] din Capitolul 19, aliasurile de tip ne sunt de ajutor pentru a abrevia tipuri lungi și a le folosi mai ușor. Să privim Listarea 20-19.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Listarea 20-19: Crearea unui alias de tip Job sub forma unui Box care încapsulează fiecare închidere și ulterior trimiterea sarcinii printr-un canal
După ce generăm o instanță nouă de Job utilizând închiderea primită în execute, expediem această sarcină către capătul transmițător al canalului. Se apelează unwrap pe send în cazul în care transmisia dă greș. Acest lucru s-ar putea întâmpla dacă, spre exemplu, am înceta execuția tuturor firelor noastre, caz în care capătul receptor nu mai primește mesaje noi. Momentan, firele noastre de execuție nu pot fi oprite: acestea vor rula atât timp cât pool-ul este activ. Folosim unwrap deoarece suntem siguri că situația de eșec nu se va produce, deși compilatorul nu poate avea această certitudine.
Totuși, ne mai rămâne un pas de efectuat! În cadrul firului de execuție, închiderea trimisă către thread::spawn se limitează în continuare la utilizarea capătului receptor al canalului. Trebuie ca această închidere să intre într-o buclă care să solicite în mod repetat de la receptorul canalului o nouă sarcină și să o execute odată ce a fost primită. Implementăm schimbarea indicată în Listarea 20-20 în Worker::new.
Numele fișierului: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}Listarea 20-20: Recepția și executarea sarcinilor în firul de execuție
Aici, inițial facem un apel la lock pe receiver pentru a obține mutex-ul, urmând să apelăm unwrap pentru a provoca panică în caz de erori. Procesul de a dobândi un lock poate eșua dacă mutex-ul se află într-o stare otrăvită, o situație ce poate apărea dacă un alt fir de execuție a intrat în panică în timp ce avea lock-ul, în loc să-l elibereze. În această circumstanță, utilizarea unwrap pentru ca acest fir să intre în panică este acțiunea corectă. Ai libertatea de a înlocui acest unwrap cu un expect care să conțină un mesaj de eroare care îți este familiar.
Dacă reușim să obținem lock-ul pe mutex, apelăm recv pentru a recepționa un Job din canal. Un alt unwrap ne ajută să depășim orice alte erori aici, care ar putea surveni dacă firul care deține sender-ul s-a terminat, într-o manieră similară cu modul în care metoda send returnează Err dacă receiver-ul este oprit.
Apelul la recv blochează execuția, deci dacă nu există încă o sarcină, firul curent va aștepta până când una devine disponibil. Mutex<T> asigură că numai un fir Worker încearcă la un moment dat să solicite o sarcină.
Acum, pool-ul nostru de firuri este operațional! Încearcă să-l rulezi cu cargo run și trimite câteva solicitări.
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field is never read: `workers`
--> src/lib.rs:7:5
|
7 | workers: Vec<Worker>,
| ^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: field is never read: `id`
--> src/lib.rs:48:5
|
48 | id: usize,
| ^^^^^^^^^
warning: field is never read: `thread`
--> src/lib.rs:49:5
|
49 | thread: thread::JoinHandle<()>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
warning: `hello` (lib) generated 3 warnings
Finished dev [unoptimized + debuginfo] target(s) in 1.40s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Success! Acum avem un pool de fire de execuție care procesează conexiunile în mod asincron. Suntem limitați la crearea a maximum patru thread-uri, prin urmare sistemul nostru nu va fi copleșit dacă serverul va primi un număr mare de cereri. Dacă trimitem o cerere către /sleep, serverul va fi capabil să gestioneze alte cereri utilizând un alt thread pentru executarea lor.
Notă: dacă deschizi /sleep în multiple ferestre de browser în același timp, este posibil ca paginile să fie încărcate una după alta, în interval de 5 secunde fiecare. Unele browsere web procesează multiple instanțe ale aceleiași cereri în mod secvențial din cauza strategiilor de caching. Această limitare nu este un efect al serverului nostru web.
După ce am explorat bucla while let în Capitolul 18, ai putea fi curios de ce nu am implementat codul firului Worker așa cum este prezentat în Listarea 20-21.
Numele fișierului: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Listarea 20-21: O versiune alternativă de implementare a Worker::new utilizând while let
Codul se compilează și funcționează, dar nuduce la comportamentul dorit al thread-urilor: o cerere lentă va încetini procesarea altor cereri. Explicația este destul de subtilă: structura Mutex nu oferă o metodă unlock accesibilă publicului deoarece dreptul asupra blocării se stabilește prin durata de viață a MutexGuard<T> în rezultatul LockResult<MutexGuard<T>> returnat de metoda lock. Acest fapt permite verificatorului de împrumut să impună reguli la compilare care asigură că o resursă protejată de un Mutex nu poate fi accesată decât dacă deținem blocarea. Totodată, această implementare poate conduce la menținerea blocării pentru un timp mai îndelungat decât este necesar dacă nu suntem atenți la durata de viață a MutexGuard<T>.
În Listarea 20-20, codul care conține let job = receiver.lock().unwrap().recv().unwrap(); se execută corect datorită faptului că, prin utilizarea let, valorile temporare implicate în expresia de la partea dreaptă a semnului egal sunt imediat eliberate odată ce instrucțiunea let se finalizează. În contrast, while let (la fel ca if let și match) nu eliberează valorile temporare decât după terminarea blocului de cod corespunzător. Conform Listării 20-21, lock-ul este păstrat activ pe întreaga durată a executării lui job(). Acesta împiedică ceilalți lucrători să preia joburi noi.
[creating-type-synonyms-with-type-aliases]: ch19-04-advanced-types.html#creating-type-synonyms-with-type-aliases [integer-types]: ch03-02-data-types.html#integer-types [fn-traits]: ch13-01-closures.html#moving-captured-values-out-of-the-closure-and-the-fn-traits [builder]: ../std/thread/struct.Builder.html [builder-spawn]: ../std/thread/struct.Builder.html#method.spawn
Închiderea ordonată și curățarea
Codul din Listarea 20-20 gestionează cererile asincron folosind un pool de fire, conform intenției noastre. Apar câteva atenționări referitoare la câmpurile workers, id și thread pe care nu le utilizăm în mod direct, ceea ce ne aduce aminte că nu facem nicio curățare. Utilizând metoda mai puțin rafinată ctrl-c pentru a opri firul principal, toate celelalte fire sunt întrerupte brusc de asemenea, chiar și atunci când sunt pe punctul de a servi o cerere.
În pasul următor, vom implementa trăsătura Drop pentru a invoca join pe fiecare din fire din pool, astfel încât să își finalizeze cererile în curs de procesare înainte de a se închide. După aceea, vom crea un mecanism prin care firele de execuție să fie informate că trebuie să se oprească din a accepta cereri noi și să se închidă. Pentru a vedea acest cod în practică, vom ajusta serverul nostru să accepte doar două cereri înainte de a-și închide în mod ordonat pool-ul de fire.
Implementarea trăsăturii Drop pe ThreadPool
Să începem prin implementarea trăsăturii Drop pentru pool-ul nostru de fire de execuție. Când acesta este eliminat, este esențial ca toate firele să fie reunite pentru a asigura finalizarea muncii lor. Listarea 20-22 ilustrează o primă tentativă de implementare pentru Drop; Codul prezentat încă nu va funcționa cum trebuie.
Numele fișierului: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}Listarea 20-22: Procedura de unire a fiecărui fir odată cu ieșirea pool-ului de fire din domeniul de vizibilitate
În primul rând, iterăm prin fiecare worker din pool-ul de thread-uri. Utilizăm &mut deoarece self este o referință mutabilă și avem nevoie să modificăm worker. Pentru fiecare worker, vom afișa un mesaj care anunță că acel worker specific este pe cale de a se opri, după care apelăm metoda join pe firul respectivului worker. Dacă apelul la join eșuează, utilizăm unwrap pentru a forța Rust să genereze panică și să realizeze o închidere forțată.
Acesta este mesajul de eroare pe care îl obținem la compilarea codului:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: this function takes ownership of the receiver `self`, which moves `worker.thread`
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/std/src/thread/mod.rs:1581:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` due to previous error
Eroarea indică faptul că nu putem apela join deoarece avem doar un împrumut mutabil pentru fiecare worker și join își asumă posesiunea argumentului pe care îl primește. Pentru a depăși această problemă, este necesar să mutăm firul din interiorul instanței Worker ce deține thread, permițând astfel join să consume firul. Acest lucru a fost implementat în Listarea 17-15: dacă Worker are un Option<thread::JoinHandle<()>>, putem folosi metoda take pe Option pentru a extrage valoarea din varianta Some și a lăsa locul ocupat de None. Pe scurt, un Worker activ va avea o variantă Some în thread, iar când dorim să curățăm un Worker, schimbăm Some cu None, făcând astfel ca Worker să nu mai aibă un fir activ.
Prin urmare, știm că dorim să actualizăm definiția lui Worker în felul următor:
Numele fișierului: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}Să ne sprijinim pe compilator pentru a identifica și alte segmente care necesită schimbări. Examinând acest cod, ne confruntăm cu două erori:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `join` found for enum `Option` in the current scope
--> src/lib.rs:52:27
|
52 | worker.thread.join().unwrap();
| ^^^^ method not found in `Option<JoinHandle<()>>`
|
note: the method `join` exists on the type `JoinHandle<()>`
--> /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/std/src/thread/mod.rs:1581:5
help: consider using `Option::expect` to unwrap the `JoinHandle<()>` value, panicking if the value is an `Option::None`
|
52 | worker.thread.expect("REASON").join().unwrap();
| +++++++++++++++++
error[E0308]: mismatched types
--> src/lib.rs:72:22
|
72 | Worker { id, thread }
| ^^^^^^ expected enum `Option`, found struct `JoinHandle`
|
= note: expected enum `Option<JoinHandle<()>>`
found struct `JoinHandle<_>`
help: try wrapping the expression in `Some`
|
72 | Worker { id, thread: Some(thread) }
| +++++++++++++ +
Some errors have detailed explanations: E0308, E0599.
For more information about an error, try `rustc --explain E0308`.
error: could not compile `hello` due to 2 previous errors
Să ne ocupăm de a doua eroare, care ne îndreaptă atenția către codul de la sfârșitul lui Worker::new; trebuie să plasăm valoarea thread în Some atunci când construim un nou Worker. Efectuați următoarele ajustări pentru a remedia această eroare:
Numele fișierului: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker {
id,
thread: Some(thread),
}
}
}Prima eroare se regăsește în implementarea noastră Drop. Anterior, am indicat intenția de a folosi take pe valoarea Option pentru a muta thread din worker. Modificările următoare sunt necesare pentru a realiza aceasta:
Numele fișierului: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker {
id,
thread: Some(thread),
}
}
}Așa cum am explicat în Capitolul 17, metoda take pe Option scoate varianta Some și lasă None în locul ei. Utilizăm if let pentru a destructura Some și a accesa firul; după care invocăm join pe acel thread. Dacă valoarea lui thread a unui worker este deja None, asta înseamnă că firul respectiv a fost deja curățat și atunci nu se întâmplă nimic în acea situație.
Semnalizarea firelor pentru a înceta acceptarea sarcinilor
După toate modificările efectuate, codul nostru se compilează fără avertismente. Totuși, partea negativă este că acest cod nu funcționează încă așa cum ne-am propus. Elementul cheie este logica din închiderea executată de firele de execuție ale instanțelor Worker: acum când apelăm join, acest lucru nu va opri firele deoarece acestea execută o buclă loop interminabilă în căutarea de sarcini. Dacă încercăm să distrugem ThreadPool cu implementarea curentă a metodei drop, firul principal va aștepta la nesfârșit ca primul fir să finalizeze procesarea.
Pentru a corecta această problemă, trebuie să modificăm implementarea metodei drop în ThreadPool și apoi să ajustăm bucla din Worker.
În primul rând, vom schimba implementarea drop pentru ThreadPool pentru a scăpa explicit de sender înainte de a aștepta finalizarea firelor. Listarea 20-23 ne arată schimbările aduse ThreadPool pentru a renunța explicit la sender. Utilizăm aceeași tehnică Option și take cum am făcut în cazul firului, pentru a putea muta sender în afara obiectului ThreadPool:
Numele fișierului: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
// --snip--
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker {
id,
thread: Some(thread),
}
}
}Listarea 20-23: Ștergerea explicită a sender înainte de a face join la firele din instanțele worker
Renunțarea la sender conduce la închiderea canalului, ceea ce semnalează faptul că nu se vor mai trimite alte mesaje. Atunci când se întâmplă asta, toate apelurile la recv efectuate de instanțele worker în bucla infinită vor rezultat într-o eroare. În Listarea 20-24, modificăm bucla Worker astfel încât să iasă elegant din buclă în acest caz, ceea ce înseamnă că firele de execuție se vor încheia odată ce implementarea drop pentru ThreadPool inițiază join pe acestea.
Numele fișierului: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}Listarea 20-24: Ieșirea explicită din buclă când recv returnează o eroare
Pentru a ilustra acest cod în practică, să modificăm funcția main pentru a accepta doar două cereri înainte de a încheia activitatea serverului într-un mod ordonat, așa cum arată Listarea 20-25.
Numele fișierului: src/main.rs
use hello::ThreadPool;
use std::fs;
use std::io::prelude::*;
use std::net::TcpListener;
use std::net::TcpStream;
use std::thread;
use std::time::Duration;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let get = b"GET / HTTP/1.1\r\n";
let sleep = b"GET /sleep HTTP/1.1\r\n";
let (status_line, filename) = if buffer.starts_with(get) {
("HTTP/1.1 200 OK", "hello.html")
} else if buffer.starts_with(sleep) {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let response = format!(
"{}\r\nContent-Length: {}\r\n\r\n{}",
status_line,
contents.len(),
contents
);
stream.write_all(response.as_bytes()).unwrap();
stream.flush().unwrap();
}Listarea 20-25: Încheierea activității serverului după procesarea a două cereri, ieșind din buclă
În practică, nu ar fi ideal ca un server web să se oprească după procesarea a doar două cereri. Acest exemplu are scopul de a arăta că procedura de închidere și curățare funcționează corespunzător.
Metoda take este definită în trăsătura Iterator și limitează iterarea la primele două elemente, cel mult. ThreadPool va ieși din domeniul de aplicare la sfârșitul funcției main, ceea ce va declanșa executarea implementării drop.
Pornește serverul cu comanda cargo run și efectuează trei cereri. La cea de-a treia cerere, ar trebui să se întâmpine o eroare și în terminal ar trebui să ai o ieșire similară cu următoarea:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 1.0s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
S-ar putea să vezi o ordonare diferită a instanțelor de worker și a mesajelor afișate. Vedem cum funcționează acest cod prin intermediul mesajelor: instanțele 0 și 3 au procesat primele două cereri. Serverul a încetat de a mai accepta conexiuni după al doilea client, și implementarea Drop a ThreadPool a început să se activeze chiar înainte ca worker-ul 3 să își înceapă sarcina. Eliminând sender-ul, se deconectează toți worker-ii și li se transmite să se oprească. Fiecare worker afișează un mesaj în momentul deconectării, după care pool-ul de fire invocă join pentru a aștepta finalizarea fiecărui fir de execuție de worker.
Putem observa un detaliu interesant în această execuție: după ce ThreadPool a eliminat sender-ul, înainte ca vreun worker să întâmpine o eroare, am încercat să facem join pe worker-ul 0. Instanța 0 nu primise încă vreo eroare de la recv, deci firul principal a fost blocat așteptând ca worker-ul 0 să-și termine sarcina. Între timp, worker-ul 3 a primit o sarcină și apoi toate firele de execuție au întâmpinat o eroare. Odată ce worker-ul 0 și-a încheiat treaba, firul principal a așteptat finalizarea celorlalte fire de execuție ale worker-ilor. Toți ieșiră deja din buclele lor și s-au oprit.
Felicitări! Am completat proiectul nostru; acum avem la dispoziție un server web de bază care utilizează un pool de fire de execuție pentru a răspunde asincron. Suntem capabili să realizăm o închidere ordonată a serverului, care finalizează toate firele din pool.
Iată codul complet pentru referință:
Numele fișierului: src/main.rs
use hello::ThreadPool;
use std::fs;
use std::io::prelude::*;
use std::net::TcpListener;
use std::net::TcpStream;
use std::thread;
use std::time::Duration;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let get = b"GET / HTTP/1.1\r\n";
let sleep = b"GET /sleep HTTP/1.1\r\n";
let (status_line, filename) = if buffer.starts_with(get) {
("HTTP/1.1 200 OK", "hello.html")
} else if buffer.starts_with(sleep) {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let response = format!(
"{}\r\nContent-Length: {}\r\n\r\n{}",
status_line,
contents.len(),
contents
);
stream.write_all(response.as_bytes()).unwrap();
stream.flush().unwrap();
}Numele fișierului: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}Putem adăuga și mai multe îmbunătățiri acestui proiect! Dacă dorești să continui dezvoltarea lui, iată câteva sugestii:
- Completează documentația pentru
ThreadPoolși metodele sale publice. - Creează teste pentru a verifica funcționalitățile bibliotecii.
- Înlocuiește apelurile la
unwrapcu mecanisme de gestionare a eroarelor mai solide. - Folosește
ThreadPoolpentru a executa o sarcină diferită de procesarea cererilor web. - Explorează un crate pentru thread pool de pe crates.io și construiește un server web similar folosind acel crate. Compară apoi API-ul și nivelul de robustețe cu thread pool-ul pe care l-am creat noi.
Sumar
Bravo! Ai parcurs cartea până la capăt! Îți mulțumim că ai acceptat să ni te alături în acest periplu al limbajului Rust. Acum ești pregătit să demarezi propriile proiecte Rust și să contribui la proiectele altora. Reține că avem o comunitate disponibilă de Rustaceani care te așteaptă cu brațele deschise să te ajute în fața oricăror provocări pe care le poți întâlni în drumul tău cu Rust.
Anexă
Următoarele secțiuni conțin material de referință care s-ar putea să îți fie util în călătoria ta prin Rust.
Anexa A: Cuvinte cheie
Următoarea listă conține cuvinte cheie care sunt rezervate pentru uzul curent sau viitor de către limbajul Rust. Ca atare, acestea nu pot fi utilizate ca identificatori (cu excepția ca identificatori "raw", așa cum vom discuta în secțiunea "Identificatori Raw"). Identificatorii sunt nume de funcții, variabile, parametri, câmpuri struct, module, crate-uri, constante, macro-uri, valori statice, atribute, tipuri, traits, sau lifetimes.
Cuvinte cheie actualmente în uz
Următoarea este o listă de cuvinte cheie actualmente în uz, cu funcționalitatea lor prezentată.
as- efectuează tip casting primitiv, disambiguează trait-ul specific care conține un item sau redenumeste items în instrucțiuneauseasync- întoarce unFutureîn loc de a bloca firul curent de execuțieawait- suspendă execuția până când rezultatul unuiFutureeste gatabreak- iese imediat dintr-o buclăconst- definește constante sau pointeri raw constanțicontinue- continuă la următoarea iterație de buclăcrate- în calea unui modul, se referă la rădăcina crate-uluidyn- expediază dinamic către un obiect traitelse- fallback pentru construcții de controlifșiif letenum- definește o enumerațieextern- leagă o funcție sau o variabilă externăfalse- literal Boolean falsfn- definește o funcție sau tipul unui pointer de funcțiefor- trece prin elementele unui iterator, implementează un trait sau specifică un durată de viață de rang superiorif- alege în funcție de rezultatul unei expresii condiționaleimpl- implementează funcționalitatea inherentă sau a unei trăsăturiin- face parte din sintaxa bucleiforlet- leagă o variabilăloop- buclă necondiționatămatch- potrivește o valoare cu modelemod- definește un modulmove- face ca o închidere să preia posesiunea tuturor capturilor salemut- denotă mutabilitate în referințe, pointeri raw, sau legături de patternpub- denotă vizibilitate publică în câmpuri struct, blocuriimplsau moduleref- leagă prin referințăreturn- întoarce din funcțieSelf- un alias pentru tipul pe care îl definim sau implementămself- subiectul metodei sau modulul curentstatic- variabilă globală sau timp de viață pe întreaga durată de execuție a programuluistruct- definește o structurăsuper- modulul părinte al modulului curenttrait- definește o trăsăturătrue- literal Boolean adevărattype- definește un alias de tip sau un tip asociatunion- definește o uniune; este un cuvânt cheie doar când este folosit într-o declarație de uniuneunsafe- denotă cod, funcții, traits, sau implementări nesigureuse- aduce simboluri în domeniul de vizibilitatewhere- denotă clauze care constrâng un tipwhile- buclă condiționată bazată pe rezultatul unei expresii
Cuvinte cheie rezervate pentru utilizare viitoare
Următoarele cuvinte cheie nu au încă nicio funcționalitate, dar sunt rezervate de Rust pentru o potențială utilizare în viitor.
abstractbecomeboxdofinalmacrooverrideprivtrytypeofunsizedvirtualyield
Identificatori bruți
Identificatorii bruți sunt sintaxa care îți permite să folosești cuvinte cheie acolo unde în mod normal nu ar fi permise. Folosești un identificator brut prin prefixarea unui cuvânt cheie cu r#.
De exemplu, match este un cuvânt cheie. Dacă încerci să compilezi următoarea funcție care folosește match ca nume al său:
Numele fișierului: src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}vei primi această eroare:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
Eroarea arată că nu poți folosi cuvântul cheie match ca identificator al funcției. Pentru a folosi match ca nume de funcție, trebuie să folosești sintaxa pentru identificatori bruți, în felul următor:
Numele fișierului: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool { haystack.contains(needle) } fn main() { assert!(r#match("foo", "foobar")); }
Acest cod se va compila fără nicio eroare. Observă prefixul r# în numele funcției la definirea acesteia, cât și atunci când funcția este apelată în main.
Identificatorii bruți îți permit să folosești orice cuvânt alegi ca identificator, chiar dacă acel cuvânt se întâmplă să fie un cuvânt cheie rezervat. Acest lucru ne oferă mai multă libertate în alegerea numelor de identificatori, precum și ne permite să ne integrăm cu programe scrise într-un limbaj unde aceste cuvinte nu sunt cuvinte cheie. În plus, identificatorii bruți îți permit să folosești librării scrise într-o ediție Rust diferită față de crate-ul tău. De exemplu, try nu este un cuvânt cheie în ediția 2015, dar este în ediția 2018. Dacă depinzi de o librărie care este scrisă folosind ediția 2015 și are o funcție try, va trebui să folosești sintaxa pentru identificatori bruți, r#try în acest caz, pentru a apela acea funcție din codul tău din ediția 2018. Vezi Anexa E pentru mai multe informații despre ediții.
Anexa B: Operatori si simboluri
Această anexă conține un glosar al sintaxei Rust, inclusiv operatori și alte simboluri care apar singure sau în contextul căilor, genericelor, limitelor de trăsături, macrocomenzilor, atributelor, comentariilor, tuplelor și parantezelor.
Operatori
Tabelul B-1 conține operatorii din Rust, un exemplu de cum ar apărea operatorul în context, o scurtă explicație și dacă acel operator este supraîncarcabil. Dacă un operator este supraîncarcabil, trăsătura relevantă de utilizat pentru a supraîncarca acel operator este listată.
Tabelul B-1: Operatori
| Operator | Exemplu | Explicație | Supraîncarcabil? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Expansiune de macrocomandă | |
! | !expr | Complement logic sau pe biți | Not |
!= | expr != expr | Comparare de non-egalitate | PartialEq |
% | expr % expr | Rest aritmetic | Rem |
%= | var %= expr | Rest aritmetic și atribuire | RemAssign |
& | &expr, &mut expr | Referință | |
& | &type, &mut type, &'a type, &'a mut type | Tip pointer împrumutat | |
& | expr & expr | AND pe biți | BitAnd |
&= | var &= expr | AND pe biți și atribuire | BitAndAssign |
&& | expr && expr | AND logic scurtcircuitat (care abandonează evaluarea la prima expresie evaluată ca fals) | |
* | expr * expr | Înmulțire aritmetică | Mul |
*= | var *= expr | Înmulțire aritmetică și atribuire | MulAssign |
* | *expr | Dereferențiere | Deref |
* | *const type, *mut type | Pointer brut | |
+ | trait + trait, 'a + trait | Constrângere de tip compus | |
+ | expr + expr | Adunare aritmetică | Add |
+= | var += expr | Adunare aritmetică și atribuire | AddAssign |
, | expr, expr | Separator de argumente și elemente | |
- | - expr | Negare aritmetică | Neg |
- | expr - expr | Scădere aritmetică | Sub |
-= | var -= expr | Scădere aritmetică și atribuire | SubAssign |
-> | fn(...) -> type, |...| -> type | Tipul de returnare pentru funcție și închidere | |
. | expr.ident | Acces la membru | |
.. | .., expr.., ..expr, expr..expr | Literal pentru rang exclus la dreapta | PartialOrd |
..= | ..=expr, expr..=expr | Literal pentru rang inclusiv la dreapta | PartialOrd |
.. | ..expr | Sintaxă pentru actualizare literală structură | |
.. | variant(x, ..), struct_type { x, .. } | Legare de pattern „Și restul” | |
... | expr...expr | (Depreciat, în schimb folosiți ..=) Într-un pattern: pattern pentru diapazon inclusiv | |
/ | expr / expr | Diviziune aritmetică | Div |
/= | var /= expr | Diviziune aritmetică și atribuire | DivAssign |
: | pat: type, ident: type | Constrângeri | |
: | ident: expr | Inițializator de câmp de structură | |
: | 'a: loop {...} | Etichetă de buclă | |
; | expr; | Terminare de instrucțiune și element | |
; | [...; len] | Parte din sintaxă de array cu dimensiune fixă | |
<< | expr << expr | Deplasare la stânga | Shl |
<<= | var <<= expr | Deplasare la stânga și atribuire | ShlAssign |
< | expr < expr | Comparare mai mică decât | PartialOrd |
<= | expr <= expr | Comparare mai mic sau egal | PartialOrd |
= | var = expr, ident = type | Atribuire/echivalență | |
== | expr == expr | Comparare de egalitate | PartialEq |
=> | pat => expr | Parte din sintaxa pentru ramura match | |
> | expr > expr | Comparare mai mare decât | PartialOrd |
>= | expr >= expr | Comparare mai mare sau egal | PartialOrd |
>> | expr >> expr | Deplasare la dreapta | Shr |
>>= | var >>= expr | Deplasare la dreapta și atribuire | ShrAssign |
@ | ident @ pat | Legare de pattern | |
^ | expr ^ expr | OR exclusiv pe biți | BitXor |
^= | var ^= expr | OR exclusiv pe biți și atribuire | BitXorAssign |
| | pat | pat | Alternative de pattern | |
| | expr | expr | OR pe biți | BitOr |
|= | var |= expr | OR pe biți și atribuire | BitOrAssign |
|| | expr || expr | OR logic care abandonează execuția la prima expresie evaluată ca adevărat | |
? | expr? | Propagarea erorilor |
Simboluri non-operator
Următoarea listă conține toate simbolurile care nu funcționează ca operatori; adică, ele nu se comportă ca o funcție sau o apelare de metodă.
Tabelul B-2 arată simbolurile care apar singure și sunt valabile într-o varietate de locuri.
Tabelul B-2: Sintaxa Stand-Alone
| Simbol | Explicație |
|---|---|
'ident | Durata de viață numită sau eticheta loop-ului |
...u8, ...i32, ...f64, ...usize, etc. | Literal numeric de un anumit tip |
"..." | Literal de șir de caractere |
r"...", r#"..."#, r##"..."##, etc. | Literal de șir de caractere brut, caracterele de evadare nu sunt procesate |
b"..." | Literal de șir de byte-uri; construiește un array de byte-uri în loc de un șir |
br"...", br#"..."#, br##"..."##, etc. | Literal de șir de byte-uri brut, combinația dintre șirul brut de caractere și șirul de byte-uri |
'...' | Literal de caracter |
b'...' | Literal de byte ASCII |
|...| expr | Închidere (Closure) |
! | Tipul de fundal întotdeauna gol pentru funcțiile divergente |
_ | Legare a modelului "Ignorat"; de asemenea, este utilizat pentru a face literalele întregi lizibile |
Tabelul B-3 arată simbolurile care apar în contextul unei cale prin modulul ierarhia către un element.
Tabelul B-3: Sintaxa legată de Path
| Simbol | Explicație |
|---|---|
ident::ident | Calea Namespace-ului |
::path | Cale relativă la rădăcina crate-ului (adică, o cale absolută explicită) |
self::path | Cale relativă la modulul curent (adică, o cale relativă explicită) |
super::path | Cale relativă la părintele modulului curent |
type::ident, <type as trait>::ident | Constante asociate, funcții, și tipuri |
<type>::... | Element asociat pentru un tip care nu poate fi numit direct (de exemplu, <&T>::..., <[T]>::..., etc.) |
trait::method(...) | Dezambiguizarea unui apel de metoda prin numirea tipului care o definește |
type::method(...) | Dezambiguizarea unui apel de metoda prin numirea tipului pentru care este definit |
<type as trait>::method(...) | Dezambiguizarea unui apel de metoda prin numirea trăsăturii și tipului |
Tabelul B-4 arată simboluri care apar în contextul utilizării parametrilor de tip generic.
Tabelul B-4: Generics
| Simbol | Explicație |
|---|---|
path<...> | Specifică parametrii către tipul generic într-un tip (de exemplu, Vec<u8>) |
path::<...>, method::<...> | Specifică parametrii către tipul generic, funcție, sau metodă într-o expresie; de multe ori se referă la acesta ca la turbofish (de exemplu, "42".parse::<i32>()) |
fn ident<...> ... | Definește funcție generică |
struct ident<...> ... | Definește structura generică |
enum ident<...> ... | Definește enumerația generică |
impl<...> ... | Definește implementarea generică |
for<...> type | Limitele de durată de viață cu rang superior (Higher-ranked lifetime bounds) |
type<ident=type> | Un tip generic în care unul sau mai multe tipuri asociate au atribuiri specifice (de exemplu, Iterator<Item=T>) |
Tabelul B-5 arată simboluri care apar în contextul constrângerii parametrilor de tip generic cu limite de trăsături (Trait bounds).
Tabelul B-5: Limitările Trăsăturilor
| Simbol | Explicație |
|---|---|
T: U | Parametrul generic T limitat la tipurile care implementează U |
T: 'a | Tipul generic T trebuie să supraviețuiască duratei de viață 'a (asta înseamnă că tipul nu poate să conțină în mod tranzitiv orice referințe cu duratele de viață mai scurte decât 'a) |
T: 'static | Tipul generic T nu conține alte referințe împrumutate decât cele 'static |
'b: 'a | Durata de viață generică 'b trebuie să supraviețuiască duratei de viață 'a |
T: ?Sized | Permite parametrului de tip generic să fie un tip dinamic de dimensiune |
'a + trait, trait + trait | Constrângere de tip compusă |
Tabelul B-6 arată simbolurile care apar în contextul apelării sau definirii de macrouri și specificarea atributelor pe un element.
Tabelul B-6: Macrouri și Atribute
| Simbol | Explicatie |
|---|---|
#[meta] | Atribut outer |
#![meta] | Atribut inner |
$ident | Substituție macro |
$ident:kind | Captură macro |
$(…)… | Repetitie macro |
ident!(...), ident!{...}, ident![...] | Invocare macro |
Tabelul B-7 arată simbolurile care creează comentarii.
Tabelul B-7: Comentarii
| Simbol | Explicatie |
|---|---|
// | Comentariu de linie |
//! | Comentariu de linie doc intern |
/// | Comentariu de linie doc extern |
/*...*/ | Comentariu de bloc |
/*!...*/ | Comentariu de bloc doc intern |
/**...*/ | Comentariu de bloc doc extern |
Tabelul B-6 arată simboluri care apar în contextul apelării sau definirii macrourilor și specificarea atributelor unui element.
Tabelul B-6: Macrouri și Atribute
| Simbol | Explicație |
|---|---|
#[meta] | Atribut extern |
#![meta] | Atribut intern |
$ident | Substituție macro |
$ident:kind | Captură macro |
$(…)… | Repetare macro |
ident!(...), ident!{...}, ident![...] | Invocare macro |
Tabelul B-7 arată simbolurile care creează comentarii.
Tabelul B-7: Comentarii
| Simbol | Explicație |
|---|---|
// | Comentariu linie |
//! | Comentariu intern documentație linie |
/// | Comentariu extern documentație linie |
/*...*/ | Comentariu bloc |
/*!...*/ | Comentariu intern documentație bloc |
/**...*/ | Comentariu extern documentație bloc |
Tabelul B-8 arată simbolurile care apar în contextul folosirii tuplurilor.
Tabelul B-8: Tuple
| Simbol | Explicație |
|---|---|
() | Tuplă goală (cunoscută ca unit), atât literal cât și tip |
(expr) | Expresie între paranteze |
(expr,) | Expresie tuplă cu un singur element |
(type,) | Tip de tuplă cu un singur element |
(expr, ...) | Expresie tuplă |
(type, ...) | Tip de tuplă |
expr(expr, ...) | Expresie de apel de funcție; de asemenea utilizată pentru a inițializa structuri de tuplă și variante enum de tuplă |
expr.0, expr.1, etc. | Indexare de tuplă |
Tabelul B-9 arată contextele în care sunt utilizate acoladele.
Tabelul B-9: Acolade
| Context | Explicație |
|---|---|
{...} | Expresie bloc |
Type {...} | Literal struct |
Tabelul B-10 arată contextele în care sunt utilizate parantezele pătrate.
Tabelul B-10: Paranteze pătrate
| Context | Explicație |
|---|---|
[...] | Literal de array |
[expr; len] | Literal de array conținând len copii ale expr |
[type; len] | Tip de array conținând len instanțe ale type |
expr[expr] | Indexare în colecție. Poate fi supraîncărcată (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Indexare în colecție care pretinde a fi secțiune de colecție, folosind Range, RangeFrom, RangeTo, sau RangeFull ca „index” |
Anexa C: Trăsături derivabile
În diverse părți din carte, am discutat despre atributul derive, pe care poți să-l aplici la o definiție de structură sau enumerare. Atributul derive generează codul care va implementa o trăsătură cu propria implementare implicită pe tipul pe care l-ai adnotat cu sintaxa derive.
În această anexă, oferim o referință a tuturor trăsăturilor din biblioteca standard pe care le poți utiliza cu derive. Fiecare secțiune acoperă:
- Ce operatori și metode activează derivarea acestei trăsături
- Ce face implementarea trăsăturii furnizată prin
derive - Ce semnifică implementarea trăsăturii despre tipul
- Condițiile în care ți se permite sau nu implementezi trăsătura
- Exemple de operații care necesită trăsătura
Dacă dorești un comportament diferit de cel oferit de atributul derive, consultă documentația bibliotecii standard pentru fiecare trăsătură, pentru detalii despre cum să le implementezi manual.
Trăsăturile enumerate aici sunt singurele definite de biblioteca standard care pot fi implementate pe tipurile tale folosind derive. Alte trăsături definite în biblioteca standard nu au un comportament implicit bine definit, așa că este de datoria ta să le implementezi în modul care are sens pentru ceea ce încerci să realizezi.
Un exemplu de trăsătură care nu poate fi derivată este Display, care se ocupă de formatarea pentru utilizatorii finali. Ar trebui să iei în considerare întotdeauna modalitatea potrivită de a afișa un tip către un utilizator final. Ce părți ale tipului ar trebui să aibă permisiunea utilizatorilor finali de a vedea? Ce părți ar considera acestea relevante? Ce format al datelor ar fi cel mai relevant pentru ei? Compilatorul Rust nu are aceste cunoștințe, așa că nu îți poate oferi un comportament implicit corespunzător.
Lista de trăsături derivabile furnizate în această anexă nu este exhaustivă:
librăriile pot implementa derive pentru propriile lor trăsături,
făcând lista de trăsături cu care poți folosi derive cu adevărat deschisă.
Implementarea derive implică utilizarea unei macrocomenzi procedurale, ce este acoperită în secțiunea „Macrcomenzi” a Capitolului 19.
Debug pentru afișare de depanare
Trăsătura Debug permite formatarea pentru depanare în string-uri formatate, pe care o indicăm prin adăugarea :? în acoladele {}.
Trăsătura Debug îți permite să printezi instanțe ale unui tip pentru scopuri de depanare, astfel încât tu și alți programatori care utilizează tipul tău să puteți inspecta o instanță la un anumit punct în execuția unui program.
Trăsătura Debug este necesară, de exemplu, în utilizarea macrcomenzii assert_eq!. Această macrocomandă afișează valorile instanțelor date ca argumente dacă aserțiunea de egalitate eșuează, astfel încât programatorii să poată vedea de ce cele două instanțe nu au fost egale.
PartialEq și Eq pentru compararea de egalitate
Trăsătura PartialEq îți permite să compari instanțe ale unui tip pentru a verifica egalitatea și permite utilizarea operatorilor == și !=.
Derivarea PartialEq implementează metoda eq. Când PartialEq este derivat pe structuri, două instanțe sunt egale doar dacă toate câmpurile sunt egale, iar instanțele nu sunt egale dacă orice câmpuri nu sunt egale. Când este derivat pe enumerări, fiecare variantă este egală cu ea însăși și nu este egală cu celelalte variante.
Trăsătura PartialEq este necesară, de exemplu, cu utilizarea macrocomenzii assert_eq!, care are nevoie să poată compara două instanțe ale unui tip pentru egalitate.
Trăsătura Eq nu are metode. Scopul său este de a semnala că pentru fiecare valoare a tipului adnotat, valoarea este egală cu ea însăși. Trăsătura Eq poate fi aplicată doar la tipuri care implementează de asemenea PartialEq, deși nu toate tipurile care implementează PartialEq pot implementa Eq. Un exemplu în acest sens este tipurile cu numere cu virgulă mobilă: implementarea numerelor cu virgulă mobilă afirmă că două instanțe ale valorii care nu este un număr (NaN) nu sunt egale între ele.
Un exemplu de când este necesar Eq este pentru cheile într-un HashMap<K, V> astfel încât HashMap<K, V> să poată spune dacă două chei sunt la fel.
PartialOrd și Ord pentru Compararea Ordinelor
Trăsătura PartialOrd îți permite să compari instanțe ale unui tip în vederea sortării. Un tip care implementează PartialOrd poate fi folosit cu operatorii <, >, <=, și >=. Poți aplica trăsătura PartialOrd doar la tipurile care implementează și PartialEq.
Derivarea lui PartialOrd implementează metoda partial_cmp, care returnează un Option<Ordering> ce va fi None când valorile date nu produc o ordonare. Un exemplu de valoare care nu produce o ordonare, chiar dacă majoritatea valorilor de acel tip pot fi comparate, este valoarea numărului în virgulă mobilă care nu este un număr (NaN). Apelarea partial_cmp cu orice număr în virgulă mobilă și valoarea NaN a unui număr în virgulă mobilă va returna None.
Când este derivată la structuri, PartialOrd compară două instanțe prin compararea valorii în fiecare câmp în ordinea în care câmpurile apar în definiția structurii. Când este derivată la enumerări, variantele enumerării declarate mai devreme în definiția enumerării sunt considerate mai mici decât variantele listate mai târziu.
Trăsătura PartialOrd este necesară, de exemplu, pentru metoda gen_range din crate-ul rand care generează o valoare aleatorie în intervalul specificat de o expresie de interval.
Trăsătura Ord îți permite să știi că, pentru oricare două valori ale tipului adnotat, va exista o ordonare validă. Trăsătura Ord implementează metoda cmp, care returnează un Ordering în loc de un Option<Ordering>, deoarece o ordonare validă va fi întotdeauna posibilă. Poți aplica trăsătura Ord doar la tipurile care implementează și PartialOrd și Eq (iar Eq necesită PartialEq). Când este derivată la structuri și enumerări, cmp se comportă în același mod ca și implementarea derivată pentru partial_cmp cu PartialOrd.
Un exemplu de când Ord e necesar este când stochezi valori într-un BTreeSet<T>, o structură care stochează date bazate pe ordinea de sortare a valorilor.
Clone și Copy pentru duplicarea valorilor
Trăsătura Clone îți permite să creezi explicit o copie profundă a unei valori, iar procesul de duplicare ar putea implica rularea unui cod arbitrar și copierea datelor de pe heap. Vezi secțiunea „Modalități prin care variabilele și datele interacționează: Clone” în Capitolul 4 pentru mai multe informații despre Clone.
Derivarea Clone implementează metoda clone, care atunci când este implementată pentru întregul tip, apelează clone pe fiecare parte a tipului. Acest lucru înseamnă că toate câmpurile sau valorile din tip trebuie să implementeze, de asemenea, clone pentru a deriva Clone.
Un exemplu în care este necesară Clone este atunci când apelezi metoda to_vec pe un slicing. Slicing-ul nu deține instanțele tipului pe care îl conține, dar vectorul returnat de to_vec va trebui să își dețină instanțele, așa că to_vec apelează
clone la fiecare element. Astfel, tipul stocat în slicing trebuie să implementeze Clone.
Trăsătura Copy îți permite să dublezi o valoare doar prin copierea biților stocați în stivă; nu este necesar un cod arbitrar. Vezi secțiunea „Date doar pe stivă: Copy” în Capitolul 4 pentru mai multe informații despre Copy.
Trăsătura Copy nu definește nicio metodă pentru a preveni programatorii să supraîncarce acele metode și să încalce presupunerea că nu rulează niciun cod arbitrar. În acest fel, toți programatorii pot presupune că copierea unei valori va fi foarte rapidă.
Puteți deriva Copy pe orice tip ale cărui părți implementează toate Copy. Un tip care implementează Copy trebuie să implementeze, de asemenea, Clone, deoarece un tip care implementează Copy are o implementare trivială a Clone care efectuează aceeași sarcină ca Copy.
Trăsătura Copy este rareori necesară; tipurile care implementează Copy au optimizări disponibile, ceea ce înseamnă că nu trebuie să apelezi clone, făcând astfel codul mai concis.
Orice este posibil cu Copy se poate realiza și cu Clone, dar codul ar putea fi mai lent sau ar putea fi necesar să folosești clone în anumite locuri.
Hash pentru maparea unei valori către o valoare de dimensiune fixă
Trăsătura Hash îți permite să iei o instanță a unui tip de dimensiune arbitrară și să mappezi această instanță la o valoare de dimensiune fixă folosind o funcție de hash. Derivarea Hash implementează metoda hash. Implementarea derivată a metodei hash combină rezultatul apelării hash pe fiecare parte a tipului, adică toate câmpurile sau valorile trebuie să implementeze de asemenea Hash pentru a deriva Hash.
Un exemplu de când Hash este necesară este la păstrarea cheilor într-un HashMap<K, V> pentru a stoca date eficient.
Default pentru valori implicite
Trăsătura Default îți permite să creezi o valoare implicită pentru un tip. Derivarea Default implementează funcția default. Implementarea derivată a funcției
default apelează funcția default pe fiecare parte a tipului, adică toate câmpurile sau valorile din tip trebuie să implementeze de asemenea Default pentru a deriva Default.
Funcția Default::default este folosită în mod obișnuit în combinație cu sintaxa de actualizare a structurilor discutată în “Crearea instanțelor din alte instanțe cu sintaxa de actualizare a structurii” section în Capitolul 5. Poți personaliza câteva câmpuri ale unei struct-uri și apoi setează și utilizează o valoare implicită pentru restul câmpurilor folosind ..Default::default().
Trăsătura Default este necesară când folosești metoda unwrap_or_default pe instanțe Option<T>, de exemplu. Dacă Option<T> este None, metoda unwrap_or_default va returna rezultatul Default::default pentru tipul T stocat în Option<T>.
Anexa D - Unelte utile de dezvoltare
În această anexă, vorbim despre unele unelte utile de dezvoltare pe care proiectul Rust le oferă. Vom analiza formatarea automată, modalități rapide de a aplica corecțiile de avertizare, un linter și integrare cu IDE-urile.
Formatare automată cu rustfmt
Instrumentul rustfmt reformatează codul tău conform stilului de codare al comunității. Multe proiecte colaborative utilizează rustfmt pentru a preveni dispute cu privire la stilul de utilizat atunci când se scrie în Rust: toată lumea formatează codul lor folosind acest instrument.
Pentru a instala rustfmt, introdu următorul text:
$ rustup component add rustfmt
Această comandă îți oferă rustfmt și cargo-fmt, similar cum Rust îți oferă atât rustc cât și cargo. Pentru a formata orice proiect Cargo, introduce următorare comandă:
$ cargo fmt
Rularea acestei comenzi reformatează tot codul Rust din crate-ul curent. Aceasta ar trebui să schimbe doar stilul codului, nu și semantica acestuia. Pentru mai multe informații despre rustfmt, consultați documentația sa.
Corectează-ți codul cu rustfix
Instrumentul rustfix este inclus în instalările Rust și poate corecta în mod automat avertismentele compilatorului care au o modalitate clară de corectare, care și este probabil ceea ce vrei. Este posibil să fi văzut avertismente de compilator înainte. De exemplu, ia în considerare acest cod:
Numele fișierului: src/main.rs
fn do_something() {} fn main() { for i in 0..100 { do_something(); } }
Aici, apelăm funcția do_something de 100 de ori, dar nu folosim niciodată variabila i în corpul buclei for. Rust ne avertizează despre acest lucru:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: unused variable: `i`
--> src/main.rs:4:9
|
4 | for i in 0..100 {
| ^ help: consider using `_i` instead
|
= note: #[warn(unused_variables)] on by default
Finished dev [unoptimized + debuginfo] target(s) in 0.50s
Avertismentul sugerează să folosim _i ca nume în schimb: linia de subliniere indică faptul că intenționăm ca această variabilă să rămână nefolosită. Putem aplica automat această sugestie folosind instrumentul rustfix rulând comanda cargo fix:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
Când ne uităm din nou la src/main.rs, vedem că cargo fix a modificat codul:
Numele fișierului: src/main.rs
fn do_something() {} fn main() { for _i in 0..100 { do_something(); } }
Variabila buclei for se numește acum _i, iar avertismentul nu mai apare.
De asemenea, poți utiliza comanda cargo fix pentru a trece codul tău între diferitele ediții ale Rust. Edițiile sunt descrise în Anexa E.
Mai multe lints cu Clippy
Instrumentul Clippy este o colecție de lints care ajută la analiza codului tău Rust. „Lints” se referă la reguli de verificare statică a codului sursă, folosite pentru a identifica erori, inconsecvențe de stil și posibile probleme de performanță sau securitate. Folosind Clippy, poți depista și remedia eficient aceste probleme comune, sporind astfel calitatea codului tău Rust.
Pentru a instala Clippy, introdu următoarea comandă:
$ rustup component add clippy
Pentru a rula lints de la Clippy pe orice proiect Cargo, introdu următoarea comandă:
$ cargo clippy
De exemplu, presupunem că scrii un program care folosește o aproximare a unei constante matematice, precum pi, așa cum face acest program:
Numele fișierului: src/main.rs
fn main() { let x = 3.1415; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
Rularea cargo clippy pe acest proiect duce la această eroare:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
Aceasta eroare îți arată că Rust are deja o constantă PI mai precisă definită și că programul tău ar fi mai corect dacă ai folosi constanta respectivă. Atunci ai schimba codul tău pentru a utiliza constanta PI. Următorul cod nu duce la nicio eroare sau avertisment de la Clippy:
Numele fișierului: src/main.rs
fn main() { let x = std::f64::consts::PI; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
Pentru mai multe informații despre Clippy, vezi documentația sa.
Integrarea cu IDE folosind rust-analyzer
Pentru a facilita integrarea cu IDE, comunitatea Rust recomandă utilizarea
rust-analyzer. Acest instrument este un set de
utilitare centrate pe compilator care folosesc protocolul Language Server Protocol, care este o specificație pentru ca IDE-urile și limbajele de programare să comunice între ele. Diferiți clienți pot folosi rust-analyzer, cum ar fi
plugin-ul Rust analyzer pentru Visual Studio Code.
Vizitează pagina de acasa a proiectului rust-analyzer
pentru instrucțiuni de instalare, apoi instalează suportul pentru serverul de limbaj în propriul tău IDE. IDE-ul tău va obține abilități precum autocompletare, sări la definiție, și erorile inline.
Anexa E - Edițiile
În Capitolul 1, ai observat că cargo new adaugă un pic de metadate în Cargo.toml referitoare la o anumită ediție. Această anexă te va ajuta să înțelegi ce semnificație are acest aspect.
Limbajul de programare Rust și compilatorul său au un ciclu stabil de lansare o dată la fiecare șase săptămâni, astfel încât utilizatorii primesc constant functionalități noi. În comparație, alte limbaje de programare lansează modificări substanțiale mai rar; Rust, în schimb, preferă actualizări mai mici, dar mai dese. De-a lungul timpului, toate aceste actualizări mici adunate reușesc să schimbe în mod semnificativ limbajul. Fără o repere clare, poate fi dificil să realizezi cât de mult a progresat Rust de-a lungul mai multor versiuni cum ar fi de la Rust 1.10 la Rust 1.31.
La intervale de câte doi sau trei ani, echipa Rust lansează o nouă ediție a limbajului. O ediție înglobează toate funcționalitățile noi într-un format ușor de abordat, împreună cu documentație completă și instrumente actualizate. Aceste noi ediții sunt parte integrantă a ritmului standard de lansare.
Pentru diferite grupuri de utilizatori, edițiile îndeplinesc scopuri distincte:
- Pentru cei ce folosesc Rust activ, o nouă ediție aduce schimbările incrementale într-un mod compact și accesibil.
- Pentru non-utilizatorii de Rust, o nouă ediție indică schimbări de amploare și poate incita la acordarea unei noi șanse limbajului.
- Pentru contribuitorii la Rust, o ediție nouă este un moment de sărbătoare ce evidențiază evoluția proiectului și a comunității acestuia.
În momentul redactării, sunt disponibile trei ediții Rust: Rust 2015, Rust 2018 și Rust 2021. Acest text se conformează idiomurilor ediției Rust 2021.
Cheia edition din Cargo.toml îi spune compilatorului Rust ce ediție să utilizeze pentru codul tău. Dacă această cheie lipsește, Rust va folosi ediția 2015 ca implicită, pentru a păstra compatibilitatea cu versiunile anterioare.
Proiectele Pot opta pentru orice ediție disponibilă, diferită de cea implicită din 2015. O ediție poate introduce schimbări ce nu sunt compatibile în versiuni anterioare, de exemplu noi cuvinte cheie ce ar putea conflicta cu identificatorii din cod. Cu toate acestea, compilatorul va continua să compileze codul existent chiar și după actualizarea versiunii de compilator Rust, atâta timp cât nu alegi să adopți schimbările noi.
Toate versiunile de compilator Rust suportă fiecare ediție apărută înaintea versiunii acelui compilator și pot interacționa cu dependențele indiferent de ediția în care sunt scrise. Modificările aduse de o nouă ediție alterează doar modul în care compilatorul interpretează codul inițial. Astfel, dacă ai un proiect în Rust 2015 și o dependență care utilizează Rust 2018, proiectul va compila și va lucra fără probleme cu respectiva dependență. La fel, dacă proiectul tău este în Rust 2018 și folosește o dependență în Rust 2015, totul va funcționa corespunzător.
Să fim clari: cele mai multe caracteristici sunt disponibile indiferent de ediția Rust folosită. Dezvoltatorii vor continua să beneficieze de îmbunătățiri, indiferent de ediția Rust pe care o utilizează, pe măsură ce sunt lansate noi versiuni stabile. În anumite situații, mai ales atunci când sunt introduse cuvinte cheie noi, anumite funcționalități noi pot fi limitate doar la ediții mai recente. Pentru a accesa aceste caracteristici, va trebui să treci la o ediție mai nouă.
Pentru detalii suplimentare, Ghidul Edițiilor reprezintă o resursă exhaustivă despre ediții, prezentând diferențele dintre ele și detaliind cum poți actualiza codul la o nouă ediție simplu și automat cu cargo fix.
Anexa F: Traduceri ale cărții
Pentru resurse în limbi diferite de engleză. Majoritatea sunt încă în curs de desfășurare; vezi eticheta Traduceri pentru a ajuta sau pentru a ne anunța despre o nouă traducere!
- Português (BR)
- Português (PT)
- 简体中文
- 正體中文
- Українська
- Español, alternate
- Italiano
- Română
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi
- Deutsch
- हिंदी
- ไทย
- Danske
Anexa G - Procesul de dezvoltare al Rust și „Nightly Rust”
Acest apêndice explică modul în care este dezvoltat Rust și impactul acestui proces asupra ta ca dezvoltator Rust.
Stabilitate fără stagnare
Rust acordă o importanță mare stabilității codului tău. Vrem ca Rust să fie o bază solidă de dezvoltare pentru tine și dacă lucrurile ar fi în schimbare continuă, nu ar fi posibil. Totodată, dacă nu putem experimenta cu funcționalități noi, s-ar putea să descoperim defecte semnificative abia după lansarea acestora, când nu ne mai este permis să modificăm ceva.
Soluția noastră la această dilemă se numește "stabilitate fără stagnare", iar principiul călăuzitor este următorul: nu ar trebui să îți fie teamă vreodată să efectuezi un upgrade la o nouă versiune stabilă de Rust. Fiecare upgrade ar trebui să fie simplu și să îți ofere noi funcționalități, un număr mai mic de erori, precum și o viteză mai mare de compilare.
Choo, Choo! Canale de lansare și metoda trenurilor
Dezvoltarea Rust se derulează conform unui program de tren. Adică, întreaga dezvoltare se realizează pe ramura master al depozitului de cod Rust. Lansările sunt efectuate pe baza modelului trenurilor software, folosit de Cisco IOS precum și de alte proiecte. Există trei canale de lansare în cadrul Rust:
- Nightly (Nocturn)
- Beta
- Stable (Stabil)
Majoritatea dezvoltatorilor Rust preferă canalul stabil, dar cei interesați să exploreze funcții noi și experimentale pot opta pentru Nightly Rust sau Beta.
Să examinăm un exemplu specific despre cum se desfășoară procesul de dezvoltare și lansare: să presupunem că echipa Rust lucrează la lansarea versiunii 1.5. Deși lansarea a avut loc în decembrie 2015, ne va oferi exemple adecvate de numere de versiune. O caracteristică nouă este introdusă în Rust: un nou commit este adăugat pe ramura master. Fiecare noapte se creează o nouă versiune Nightly Rust. Fiecare zi înseamnă o lansare, iar aceste lansări sunt generate în mod automat de infrastructura noastră de lansări. Astfel, odată cu trecerea timpului, lansările arată cam așa, noapte de noapte:
nightly: * - - * - - *
La fiecare șase săptămâni, este timpul să pregătim o nouă lansare! Ramura beta a depozitului Rust se ramifică din ramura master utilizată de Nightly. Acum, există două lansări:
nightly: * - - * - - *
|
beta: *
Cei mai mulți utilizatori Rust nu folosesc activ lansările beta, dar testează împotriva beta în sistemul lor de integrare continuă pentru a ajuta Rust să descopere posibile regresii. Între timp, tot apare o lansare Nightly în fiecare noapte:
nightly: * - - * - - * - - * - - *
|
beta: *
Să presupunem că se găsește o regresie. Bine că am avut ceva timp să testăm lansarea beta înainte ca regresia să se strecoare într-o lansare stabilă! Remediul se aplică pe master, astfel încât Nightly este reparat, apoi remedierea este retroportată la ramura beta, și se produce o nouă lansare beta:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
La șase săptămâni după crearea primei beta, este timpul pentru o lansare stable! Ramura stable este produsă din ramura beta:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
Excelent! Rust 1.5 este gata! Totuși, am uitat un lucru: pentru că au trecut șase săptămâni, avem nevoie și de o nouă beta a versiunii următoare de Rust, 1.6. Așadar, după ce stable se ramifică din beta, următoarea versiune de beta se ramifică din nou din nightly:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
Acesta se numește modelul „de tren” pentru că la fiecare șase săptămâni, o lansare „părăsește stația”, dar tot trebuie să parcurgă un drum prin canalul beta înainte de a ajunge ca o lansare stabilă.
Rust se lansează la fiecare șase săptămâni, cu precizia unui ceasornic. Dacă cunoști data unei lansări Rust, poți determina data celei următoare: va fi peste șase săptămâni. Un avantaj al acestei programări la fiecare șase săptămâni este că „următorul tren” va sosi în curând. Dacă o funcționalitate nu reușește să ajungă într-o anumită lansare, nu e cazul să te îngrijorezi: o nouă lansare va fi disponibilă în curând! Asta diminuează presiunea de a adăuga funcționalități poate nefinisate în apropierea datei de lansare.
Datorită acestui proces, mereu poți testa următoarea construcție a Rust și să te convingi că este simplu de trecut la ea: dacă o versiune beta nu funcționează conform așteptărilor, poți să raportezi asta echipei și să obții corectarea înainte de următoarea lansare stabilă! Incidența problemelor într-o versiune beta este relativ rară, dar rustc rămâne o piesă de software, așa că erorile pot apărea.
Caracteristici instabile
Există un aspect suplimentar de luat în seamă în ce privește modelul de lansare menționat: caracteristicile instabile. Rust utilizează o tehnică numită „flag-uri de funcționalitate” pentru a defini ce caracteristici sunt disponibile într-o versiune anume. Când o nouă caracteristică este încă în dezvoltare, aceasta este adăugată în master și, astfel, este disponibilă în Nightly Rust, dar protejată de un flag de funcționalitate. Dacă dorești să testezi o funcționalitate aflată în dezvoltare, ai posibilitatea, însă este necesar să utilizezi versiunea Nightly Rust și să adnotezi codul sursă cu flag-ul potrivit pentru a exprima acordul tău.
În cazul în care folosești o versiune beta sau stabilă Rust, nu ai posibilitatea de a folosi flag-uri de funcționalitate. Acest lucru reprezintă cheia ce ne permite să testăm în mod practic noile caracteristici înainte de a fi declarate stabile pe termen lung. Cei care doresc să fie la curent cu tehnologia de ultimă oră pot adopta variantele instabile, în timp ce cei doritori de o experiență robustă pot să rămână pe versiunea stabilă și să fie siguri că codul lor nu va avea probleme. Stabilitate fără stagnare.
Cartea de față include doar informații despre caracteristicile stabile pentru că cele în curs de elaborare sunt încă în schimbare și cu certitudine vor fi diferite față de cum sunt descrise aici, la momentul când vor fi implementate în versiunile stabile. Poți găsi documentație pentru caracteristicile disponibile doar în versiunea Nightly Rust pe internet.
Rustup și rolul lui Rust Nightly
Rustup facilitează trecerea între diferite canale de release ale Rust, fie la nivel global, fie pentru fiecare proiect în parte.În mod implicit, ai instalat Rust în versiunea stabilă. Pentru a instala Nightly Rust, de exemplu:
$ rustup toolchain install nightly
Poți vedea, de asemenea, toate toolchain-urile (lansările de Rust și componentele asociate) instalate cu rustup. Iată un exemplu de pe computerul cu Windows al unuia dintre autorii cărții:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
Cum poți observa, toolchain-ul stabil este cel selectat implicit. Majoritatea utilizatorilor Rust preferă versiunea stabilă în cele mai multe situații. Este posibil să dorești să folosești în principal versiunea stabilă, dar să alegi Nightly Rust pentru un proiect anume, pentru că ai nevoie de o caracteristică avansată. În acest caz, poți utiliza rustup override în directoriul respectivului proiect pentru a specifica toolchain-ul Nightly ca fiind cel dorit de rustup atunci când lucrezi în acel directoriu:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
Astfel, ori de câte ori rulezi rustc sau cargo în ~/projects/needs-nightly, rustup va asigura că folosești Nightly Rust, în loc de Rust stabil, care este setarea default. Aceasta este o facilitare importantă atunci când lucrezi cu mai multe proiecte Rust.
Procesul RFC și echipele
Cum afli despre aceste noi caracteristici? Dezvoltarea Rust se bazează pe un proces de Request For Comments (RFC). Dacă dorești o îmbunătățire în Rust, poți scrie o propunere, denumită RFC.
Oricine poate redacta RFC-uri pentru a aduce îmbunătățiri limbajului Rust, iar aceste propuneri sunt revizuite și discutate de echipa Rust, alcătuită din multiple subechipe specializate pe diverse teme. O listă completă a acestor echipe este disponibilă pe website-ul Rust, care include echipe pentru fiecare domeniu al proiectului: design de limbaj, implementarea compilatorului, infrastructură, documentație și altele. Echipa relevantă analizează propunerea și comentariile, contribuie cu observații proprii și, în final, se ajunge la un consens pentru acceptarea sau respingerea caracteristicii propuse.
Dacă funcția este acceptată, se deschide un incident în repository-ul Rust, iar cineva poate să o implementeze. Persoana care o implementează nu trebuie neapărat să fie aceea care a propus funcția la început! Când implementarea este terminată, aceasta este adăugată în ramura master sub controlul unui flag de funcționalitate, așa cum am explicat în secțiunea „Caracteristici instabile”.
După ce dezvoltatorii Rust care folosesc versiunea Nightly Rust au avut posibilitatea să experimenteze noua caracteristică, membrii echipei o evaluează, discutând despre performanța ei în cadrul versiunii Nightly, și iau o decizie privind includerea sa în versiunea stabilă de Rust sau nu. Dacă se decide promovarea caracteristicii, flag-ul acesteia este îndepărtat, și astfel devine o funcție stabilă! Astfel, este integrată în următoarea versiune stabilă a Rust.